1.数据发布订阅
类似于消息中间件,dubbo发布者就是把数据存在znode上,订阅者监控到了znode数据发生变化,会读取这个数据,然后根据业务逻辑进行一些相应的业务处理.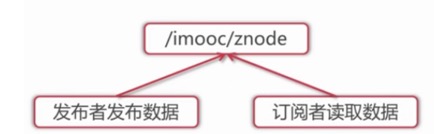
目的
动态获取数据(配置信息)
实现数据(配置信息)的集中式管理和数据的动态更新
设计模式
Push 模式
Pull 模式
数据(配置信息)特性
(1)数据量通常比较小
(2)数据内容在运行时会发生动态更新
(3)集群中各机器共享,配置一致
如:机器列表信息、运行时开关配置、数据库配置信息等
基于 Zookeeper 的实现方式
· 数据存储:将数据(配置信息)存储到 Zookeeper 上的一个数据节点
· 数据获取:应用在启动初始化节点从 Zookeeper 数据节点读取数据,并在该节点上注册一个数据变更 Watcher
· 数据变更:当变更数据时,更新 Zookeeper 对应节点数据,Zookeeper会将数据变更通知发到各客户端,客户端接到通知后重新读取变更后的数据即可。
2.负载均衡
3.命名服务
1、在分布式环境下,经常需要对应用/服务进行统一命名,便于识别不同服务。
a)类似于域名与ip之间对应关系,ip不容易记住,而域名容易记住。
b)通过名称来获取资源或服务的地址,提供者等信息。
比如说,现在我有一个域名www.java3y.com,但我这个域名下有多台机器:
192.168.1.1
192.168.1.2
192.168.1.3
192.168.1.4
别人访问www.java3y.com即可访问到我的机器,而不是通过IP去访问。
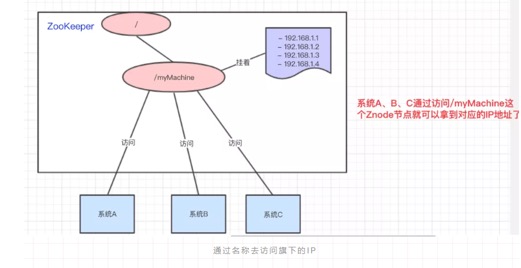
2、按照层次结构组织服务/应用名称。
a)可将服务名称以及地址信息写到ZooKeeper上,客户端通过ZooKeeper获取可用服务列表类。
4.Master选举
就是主从关系,主节点的干重要的事情,几个从节点的干不重要的事情,一旦主挂了,几个从的就争夺选举权,其中一个从的争夺成功就会做主节点要做的事情,并且可以保证这个主节点是唯一的,这也就是所谓的首脑模式,从而保证我们的集群是高可用的.
https://www.cnblogs.com/leeSmall/p/9600959.html
5.集群管理
集群管理,集群中保证数据的强一致性.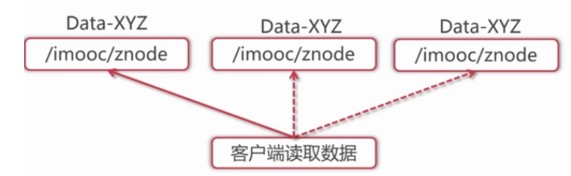
客户端给主节点设计值XYZ之后,基于集群机制,它会把数据进行同步,把主节点里面的数据同步到其它子节点里面,另外两个附和节点也会有主节点一样还数据,如果客户端和主节点切断连接了,客户端也可以从附和节点,附和节点的数据也是有的(实线是主节点,虚线是附和节点),客户端在不管链接在任何的一台机器上的时候,它都可以读到数据的,这就是一致性.
以我们三个系统A、B、C为例,在ZooKeeper中创建临时节点即可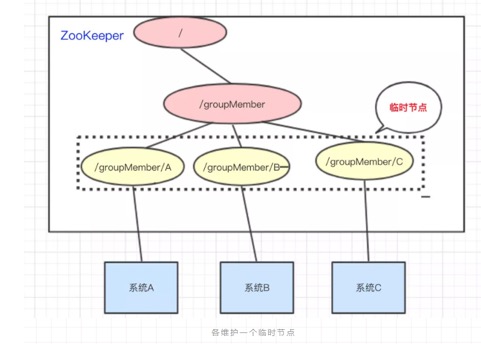
只要系统A挂了,那/groupMember/A这个节点就会删除,通过监听groupMember下的子节点,系统B和C就能够感知到系统A已经挂了。(新增也是同理)
除了能够感知节点的上下线变化,ZooKeeper还可以实现动态选举Master的功能。(如果集群是主从架构模式下)
原理也很简单,如果想要实现动态选举Master的功能,Znode节点的类型是带顺序号的临时节点(EPHEMERAL_SEQUENTIAL)就好了。
Zookeeper会每次选举最小编号的作为Master,如果Master挂了,自然对应的Znode节点就会删除。然后让新的最小编号作为Master,这样就可以实现动态选举的功能了。
6.配置管理
统一配置文件管理,即只需要修改一台服务器的配置文件,则可以把相同的配置文件同步更新到其它所以服务器
(就是把配置信息保存起来,假如多个服务调用数据库的时候,如果数据库改了ip啥的,多个服务都需要修改配置文件,很麻烦,如果把数据库ip啥的保存到配置管理那里,多个服务从配置管理那里读更方便.)
比如我们现在有三个系统A、B、C,他们有三份配置,分别是ASystem.yml、BSystem.yml、CSystem.yml,然后,这三份配置又非常类似,很多的配置项几乎都一样。
此时,如果我们要改变其中一份配置项的信息,很可能其他两份都要改。并且,改变了配置项的信息很可能就要重启系统
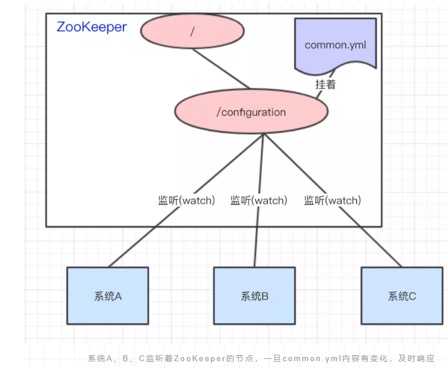
于是,我们希望把ASystem.yml、BSystem.yml、CSystem.yml相同的配置项抽取出来成一份公用的配置common.yml,并且即便common.yml改了,也不需要系统A、B、C重启。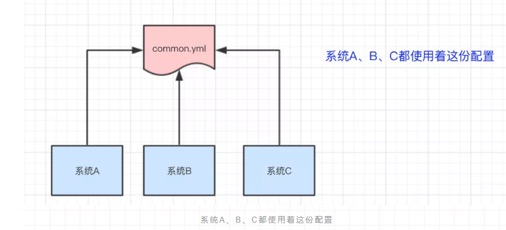
做法:我们可以将common.yml这份配置放在ZooKeeper的Znode节点中,系统A、B、C监听着这个Znode节点有无变更,如果变更了,及时响应。
7.分布式队列
队列是解耦的,分布式队列不只是那些MQ,Zookeeper也会有分布式的队列.
两种类型的队列:
(1)同步队列,当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达。
(2)队列按照 FIFO 方式进行入队和出队操作。
第一类,在约定目录下创建临时目录节点,监听节点数目是否是我们要求的数目。
第二类,和分布式锁服务中的控制时序场景基本原理一致,入列有编号,出列按编号。在特定的目录下创建 PERSISTENT_SEQUENTIAL 节点,创建成功时Watcher 通知等待的队列,队列删除序列号最小的节点用以消费。此场景下Zookeeper 的 znode 用于消息存储,znode 存储的数据就是消息队列中的消息内容,SEQUENTIAL 序列号就是消息的编号,按序取出即可。由于创建的节点是持久化的,所以不必担心队列消息的丢失问题。
8.分布式锁
分布式锁具有以下特性:
1、ZooKeeper是强一致的。比如各个节点上运行一个ZooKeeper客户端,它们同时创建相同的Znode,但是只有一个客户端创建成功。
2、实现锁的独占性。创建Znode成功的那个客户端才能得到锁,其它客户端只能等待。当前客户端用完这个锁后,会删除这个Znode,其它客户端再尝试创建Znode,获取分布式锁。
3、控制锁的时序。各个客户端在某个Znode下创建临时Znode,这个类型必须为CreateMode.EPHEMERAL_SEQUENTIAL,这样该Znode可掌握全局访问时序。1234512345
系统A、B、C都去访问/locks节点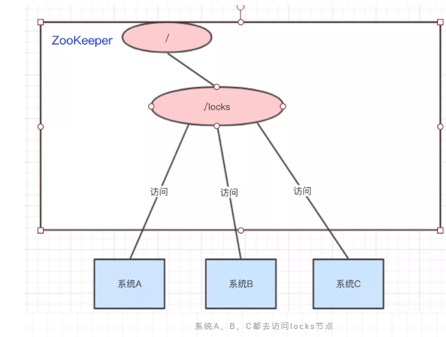
访问的时候会创建带顺序号的临时/短暂(EPHEMERAL_SEQUENTIAL)节点,比如,系统A创建了id_000000节点,系统B创建了id_000002节点,系统C创建了id_000001节点。
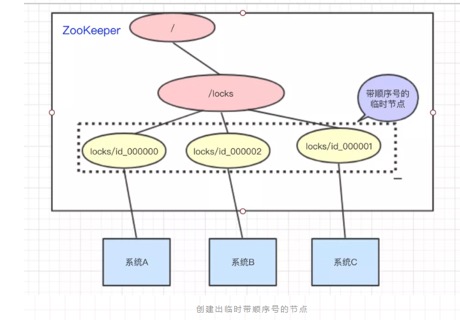
接着,拿到/locks节点下的所有子节点(id_000000,id_000001,id_000002),判断自己创建的是不是最小的那个节点
如果是,则拿到锁。
释放锁:执行完操作后,把创建的节点给删掉
如果不是,则监听比自己要小1的节点变化
举个例子:
系统A拿到/locks节点下的所有子节点,经过比较,发现自己(id_000000),是所有子节点最小的。所以得到锁
系统B拿到/locks节点下的所有子节点,经过比较,发现自己(id_000002),不是所有子节点最小的。所以监听比自己小1的节点id_000001的状态
系统C拿到/locks节点下的所有子节点,经过比较,发现自己(id_000001),不是所有子节点最小的。所以监听比自己小1的节点id_000000的状态
……
等到系统A执行完操作以后,将自己创建的节点删除(id_000000)。通过监听,系统C发现id_000000节点已经删除了,发现自己已经是最小的节点了,于是顺利拿到锁
….系统B如上
9.分布式协调
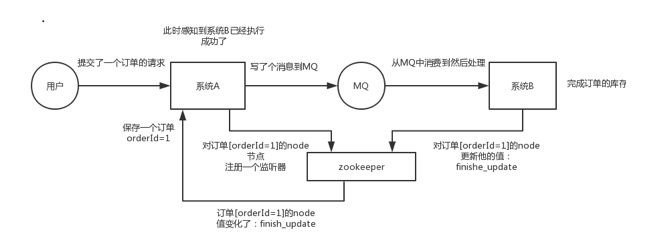
你A系统发送个请求到mq,然后B消息消费之后处理了。那A系统如何知道B系统的处理结果?用zk就可以实现分布式系统之间的协调工作。A系统发送请求之后可以在zk上对某个节点的值注册个监听器,一旦B系统处理完了就修改zk那个节点的值,A立马就可以收到通知,完美解决。
分布式通知和协调
对于系统调度来说:操作人员发送通知实际是通过控制台改变某个节点的状态,然后 zk 将这些变化发送给注册了这个节点的 watcher 的所有客户端。
对于执行情况汇报:每个工作进程都在某个目录下创建一个临时节点。并携带工作的进度数据,这样汇总的进程可以监控目录子节点的变化获得工作进度的实时的全局情况。
10.HA高可用

平时worker01系统在工作,worker02系统(备用系统)不处于工作状态,然后worker01系统往Zookeeper里面写入一个临时node节点为 active为work01,意思说是 worker01系统 这个系统正在好好工作.
然后worker02系统不工作,只是watch机制监听Zookeeper的active节点值.
此时worker01系统挂掉了,那么active这个临时节点就没有了,此时worker2系统立马就可以监听active节点变化,worker02就直接顶上,然后创建active临时节点写入值为worker02.
此时worker01系统恢复了,查看Zookeeper的active节点值变成worker02了,然后worker01机器就什么都不干,专门监听active节点变化,如果发现active节点发生变化了,说明worker02机器挂掉了,然后worker01机器顶上.
以上就是HA高可用主备场景
在很多大型系统核心节点都会选择基于zookeeper开发HA高可用主备机制,如果主进程挂掉了,从进程能立马通过Zookeeper感知到,然后顶上.

若有收获,就点个赞吧
0 人点赞
