我们的数据先写到leader里面来,然后leader再给数据同步到follower,这样的话,leader肯定数据是最多的,因为leader同步到follower是需要时间的,
比如说我往leader写了1000条数据,那么follower不会说立马就能给1000条数据全部同步过来,那么leader的偏移量就是 LEO,也就是整个集群数据最大的偏移量.
消费者消费的时候肯定是消费整个partition副本最小的那个偏移量,假如说一个集群,leader是1000偏移量,follower1偏移量是600,follower2的偏移量是700 ,那么消费者最多只能消费到600偏移量的数据.
这是为了数据安全考虑.假如说不这么做,消费者消费时候消费到800偏移量,此时leader宕机了,剩下两个follower会选leader,但是两个follower中其中一个偏移量是700,另外一个偏移量是600 ,这两个剩下的机器偏移量都没800,这就出现问题了.
所以消费者消费数据是按整个集群最低的那个offset. , 这个offset就叫做 HW.
LEO和HW概念
LEO(Log End Offset):指的是每个副本最大的offset;
HW(High Watermark):指的是消费者能读到的最大的offset,ISR队列中最小的LEO。
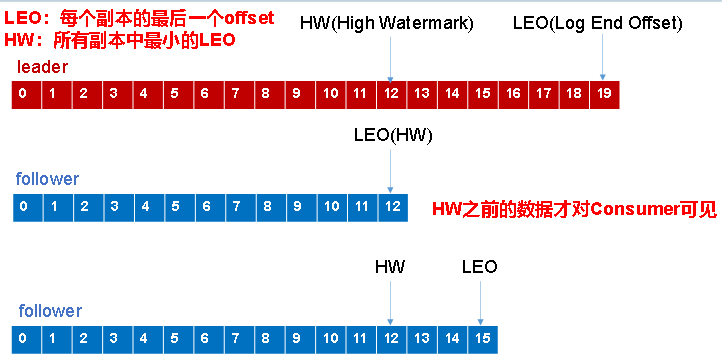
HW:
上图消费者最多能读到12,因为假如说Leader挂掉了,那么消费者读到的话,肯定是读整个集群中offset最小的那个.这个offset最小就意味着所有机器的offset肯定大于等于这个offset , 假如说A机器是 300offset,B机器是350offset ,C机器是400offset,那么消费者能读到的数据就是起始偏移量为300的数据.
LEO就是每个副本最大的Offset值.
Follower故障
follower发生故障后会被临时踢出ISR,待该follower恢复后,follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始向leader进行同步。等该follower的LEO大于等于该Partition的HW,即follower追上leader之后,就可以重新加入ISR了。
Leader故障
leader发生故障之后,会从ISR中选出一个新的leader,之后,为保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于HW的部分截掉,然后从新的leader同步数据。
注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
leader故障之后也会被踢出isr队列,等这台机器重启复活以后, follower会读取本地磁盘记录的上次的HW(注1),并将log文件高于HW的部分截取掉,从HW开始向leader进行同步。等该follower的LEO大于等于该Partition的HW,即follower追上leader之后,就可以重新加入ISR了。 当然重新加入isr队列以后,这个机器就不是leader了, 就是follower了.
注1:leader机器肯定是offset是最高的,比如说leader生前是1000的偏移量,但是宕机了, 此时会有新的leader出现,这个新的leader是900 offset, 假如说老的leader重启复活了,此时 hw是700 ,然后这个老的leader会把700以后的数据截取扔掉,以700为开始,重新往leader机器进行同步.
这么做的目的是为了保证数据安全.因为谁都不能保证你宕机之后你高出别的机器的偏移量的数据是否有问题,也许没问题,但是以防万一,就直接扔掉.

若有收获,就点个赞吧
0 人点赞
