索引,文档和 REST API
#查看索引相关信息GET kibana_sample_data_ecommerce#查看索引的文档总数GET kibana_sample_data_ecommerce/_count#查看前10条文档,了解文档格式POST kibana_sample_data_ecommerce/_search{}#_cat indices API#查看indicesGET /_cat/indices/kibana*?v&s=index#查看状态为绿的索引GET /_cat/indices?v&health=green#按照文档个数排序GET /_cat/indices?v&s=docs.count:desc#查看具体的字段GET /_cat/indices/kibana*?pri&v&h=health,index,pri,rep,docs.count,mt#How much memory is used per index?GET /_cat/indices?v&h=i,tm&s=tm:desc
# 查看节点get _cat/nodes?vGET /_nodes/es7_01,es7_02GET /_cat/nodes?vGET /_cat/nodes?v&h=id,ip,port,v,m# 查看健康度GET _cluster/healthGET _cluster/health?level=shardsGET /_cluster/health/kibana_sample_data_ecommerce,kibana_sample_data_flightsGET /_cluster/health/kibana_sample_data_flights?level=shards#### cluster stateThe cluster state API allows access to metadata representing the state of the whole cluster. This includes information such asGET /_cluster/state#cluster get settingsGET /_cluster/settingsGET /_cluster/settings?include_defaults=trueGET _cat/shardsGET _cat/shards?h=index,shard,prirep,state,unassigned.reason
结构化搜索
term 查询数字
不过现在只要记住:请尽可能多的使用过滤式查询。
TF-IDF算法
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
(1)TF是词频(Term Frequency)
词频(TF)表示词条(关键字)在文本中出现的频率。
这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。公式: 即:<br /> **公式:**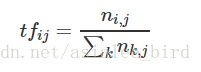 **即:**<br />其中 ni,j 是该词在文件 dj 中出现的次数,分母则是文件 dj 中所有词汇出现的次数总和;
(2) IDF是逆向文件频率(Inverse Document Frequency)
逆向文件频率 (IDF) :某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。
如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。
其中,|D| 是语料库中的文件总数。 |{j:ti∈dj}| 表示包含词语 ti 的文件数目(即 ni,j≠0 的文件数目)。如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用 1+|{j:ti∈dj}|即:
(3)TF-IDF实际上是:TF * IDF
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
注: TF-IDF算法非常容易理解,并且很容易实现,但是其简单结构并没有考虑词语的语义信息,无法处理一词多义与一义多词的情况。
分词器
# 分词器使用POST _analyze{"analyzer": "standard","text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."}

若有收获,就点个赞吧
0 人点赞
