结构化搜索
指查询有关内在结构的过程。
tg:
sql:
SELECT documentFROM productsWHERE price = 20
es:
通常当查找一个精确值的时候,我们不希望对查询进行评分计算。只希望对文档进行包括或排除的计算,constant_score 查询,它包含一个 term 查询
GET /my_store/products/_search{"query" : {"constant_score" : {"filter" : {"term" : {"price" : 20}}}}}
内部过滤器的操作
在内部,Elasticsearch 会在运行非评分查询的时执行多个操作:
 为了实现以上设想,Elasticsearch 会为每个索引跟踪保留查询使用的历史状态。如果查询在最近的 256 次查询中会被用到,那么它就会被缓存到内存中。当 bitset 被缓存后,缓存会在那些低于 10,000 个文档(或少于 3% 的总索引数)的段(segment)中被忽略。这些小的段即将会消失,所以为它们分配缓存是一种浪费。
为了实现以上设想,Elasticsearch 会为每个索引跟踪保留查询使用的历史状态。如果查询在最近的 256 次查询中会被用到,那么它就会被缓存到内存中。当 bitset 被缓存后,缓存会在那些低于 10,000 个文档(或少于 3% 的总索引数)的段(segment)中被忽略。这些小的段即将会消失,所以为它们分配缓存是一种浪费。
这些 bitsets 缓存是“智能”的:它们以增量方式更新。当我们索引新文档时,只需将那些新文档加入已有 bitset,而不是对整个缓存一遍又一遍的重复计算。和系统其他部分一样,过滤器是实时的,我们无需担心缓存过期问题。
一旦缓存了,非评分计算的 bitset 会一直驻留在缓存中直到它被剔除。剔除规则是基于 LRU 的:一旦缓存满了,最近最少使用的过滤器会被剔除。
组合过滤器
tg:
sql:
SELECT productFROM productsWHERE (price = 20 OR productID = "XHDK-A-1293-#fJ3")AND (price != 30)
es:
GET /my_store/products/_search{"query" : {"filtered" : {"filter" : {"bool" : {"should" : [{ "term" : {"price" : 20}},{ "term" : {"productID" : "XHDK-A-1293-#fJ3"}}],"must_not" : {"term" : {"price" : 30}}}}}}}
布尔过滤器
{"bool" : {"must" : [],"should" : [],"must_not" : [],}}
must
所有的语句都 必须(must) 匹配,与 AND 等价。
must_not
所有的语句都 不能(must not) 匹配,与 NOT 等价。
should
至少有一个语句要匹配,与 OR 等价。
嵌套布尔过滤器
sql
SELECT documentFROM productsWHERE productID = "KDKE-B-9947-#kL5" OR (productID = "JODL-X-1937-#pV7"AND price = 30 )
es:
GET /my_store/products/_search{"query" : {"filtered" : {"filter" : {"bool" : {"should" : [{ "term" : {"productID" : "KDKE-B-9947-#kL5"}},{ "bool" : {"must" : [{ "term" : {"productID" : "JODL-X-1937-#pV7"}},{ "term" : {"price" : 30}}]}}]}}}}}
查找多个精确的值
具体做法
- 将之前的term -> terms
- 将term 的值改为数组。
GET /my_store/products/_search{"query" : {"constant_score" : {"filter" : {"terms" : {"price" : [20, 30]}}}}}
查询范围
sql:
es:SELECT documentFROM productsWHERE price BETWEEN 20 AND 40
range 查询可同时提供包含(inclusive)和不包含(exclusive)这两种范围表达式,可供组合的选项如下:GET /my_store/products/_search{"query" : {"constant_score" : {"filter" : {"range" : {"price" : {"gte" : 20,"lt" : 40}}}}}}
- gt: > 大于(greater than)
- lt: < 小于(less than)
- gte: >= 大于或等于(greater than or equal to)
- lte: <= 小于或等于(less than or equal to)
日期范围
"range" : {"timestamp" : {"gt" : "2014-01-01 00:00:00","lt" : "2014-01-07 00:00:00"}}
当使用它处理日期字段时, range 查询支持对 日期计算(date math) 进行操作,比方说,如果我们想查找时间戳在过去一小时内的所有文档:
"range" : {"timestamp" : {"gt" : "now-1h"}}
处理null 值
查询不为空的使用exists
sql:
SELECT tagsFROM postsWHERE tags IS NOT NULL
es:
GET /my_index/posts/_search{"query" : {"constant_score" : {"filter" : {"exists" : { "field" : "tags" }}}}}
查询为空的使用missing
sql:
SELECT tagsFROM postsWHERE tags IS NULL
es:
GET /my_index/posts/_search{"query" : {"constant_score" : {"filter": {"missing" : { "field" : "tags" }}}}}
全文搜索
相关性(Relevance)
查询与其结果间的相关程度,并根据这种相关程度对结果排名的一种能力,这种计算方式可以是
- TF/IDF 方法、
- 地理位置邻近、
- 模糊相似,
或其他的某些算法。
分析(Analysis)
它是将文本块——>>>> token 的一个过程
目的是为了(a)创建倒排索引以及(b)查询倒排索引
匹配查询
首先,我们使用 bulkAPI 创建一些新的文档和索引:
DELETE /my_indexPUT /my_index{ "settings": { "number_of_shards": 1 }}POST /my_index/my_type/_bulk{ "index": { "_id": 1 }}{ "title": "The quick brown fox" }{ "index": { "_id": 2 }}{ "title": "The quick brown fox jumps over the lazy dog" }{ "index": { "_id": 3 }}{ "title": "The quick brown fox jumps over the quick dog" }{ "index": { "_id": 4 }}{ "title": "Brown fox brown dog" }
单个词查询
GET /my_index/my_type/_search{"query": {"match": {"title": "QUICK!"}}}
执行上面这个 match 查询的步骤是:
 结果:
结果:
"hits": [{"_id": "1","_score": 0.5, // 分数"_source": {"title": "The quick brown fox"}},{"_id": "3","_score": 0.44194174,"_source": {"title": "The quick brown fox jumps over the quick dog"}},{"_id": "2","_score": 0.3125,"_source": {"title": "The quick brown fox jumps over the lazy dog"}}]
分析:
- 文档 1 最相关,因为它的 title 字段更短,即 quick 占据内容的一大部分
- 文档 3 比 文档 2 更具相关性,因为在文档 3 中 quick 出现了两次
多词查询
GET /my_index/my_type/_search{"query": {"match": {"title": "BROWN DOG!"}}}
即任何文档只要 title 字段里包含 指定词项中的至少一个词 就能匹配,被匹配的词项越多,文档就越相关。
提供精度
GET /my_index/my_type/_search{"query": {"match": {"title": {"query": "BROWN DOG!","operator": "and"}}}}
控制精度
GET /my_index/my_type/_search{"query": {"match": {"title": {"query": "quick brown dog","minimum_should_match": "75%"}}}}
参数 minimum_should_match 的设置非常灵活,可以根据用户输入词项的数目应用不同的规则。完整的信息参考文档 https://www.elastic.co/guide/en/elasticsearch/reference/5.6/query-dsl-minimum-should-match.html#query-dsl-minimum-should-match
组合查询
过滤器做二元判断:文档是否应该出现在结果中?但查询更精妙,它除了决定一个文档是否应该被包括在结果中+计算文档的 相关程度 。
与过滤器一样, bool 查询也可以接受 must 、 must_not 和 should 参数下的多个查询语句。比如:
GET /my_index/my_type/_search{"query": {"bool": {"must": { "match": { "title": "quick" }},"must_not": { "match": { "title": "lazy" }},"should": [{ "match": { "title": "brown" }},{ "match": { "title": "dog" }}]}}}
评分计算
bool 查询会为每个文档计算相关度评分 _score ,再将所有匹配的 must 和 should 语句的分数 _score 求和,最后除以 must 和 should 语句的总数。
must_not 语句不会影响评分;它的作用只是将不相关的文档排除。
控制精度
GET /my_index/my_type/_search{"query": {"bool": {"should": [{ "match": { "title": "brown" }},{ "match": { "title": "fox" }},{ "match": { "title": "dog" }}],"minimum_should_match": 2}}}
查询语句提升权重
假设想要查询关于 “full-text search(全文搜索)” 的文档,但我们希望为提及 “Elasticsearch” 或 “Lucene” 的文档给予更高的 权重 ,这里 更高权重 是指如果文档中出现 “Elasticsearch” 或 “Lucene” ,它们会比没有的出现这些词的文档获得更高的相关度评分 _score ,也就是说,它们会出现在结果集的更上面。
一个简单的 bool 查询 允许我们写出如下这种非常复杂的逻辑:
GET /_search{"query": {"bool": {"must": {"match": {"content": {"query": "full text search","operator": "and"}}},"should": [{ "match": { "content": "Elasticsearch" }},{ "match": { "content": "Lucene" }}]}}}
我们可以通过指定 boost 来控制任何查询语句的相对的权重, boost 的默认值为 1 ,大于 1 会提升一个语句的相对权重。所以下面重写之前的查询:
GET /_search{"query": {"bool": {"must": {"match": {"content": {"query": "full text search","operator": "and"}}},"should": [{ "match": {"content": {"query": "Elasticsearch","boost": 3}}},{ "match": {"content": {"query": "Lucene","boost": 2}}}]}}}
多字段搜索
多字符串搜索
tg: 用标题和作者去搜索对应的文章
GET /_search{"query": {"bool": {"should": [{ "match": { "title": "War and Peace" }},{ "match": { "author": "Leo Tolstoy" }}]}}}
可以用 bool 查询来包裹组合任意其他类型的查询,甚至包括其他的 bool 查询。我们可以在上面的示例中添加一条语句来指定译者版本的偏好:
GET /_search{"query": {"bool": {"should": [{ "match": { "title": "War and Peace" }},{ "match": { "author": "Leo Tolstoy" }},{"bool": {"should": [{ "match": { "translator": "Constance Garnett" }},{ "match": { "translator": "Louise Maude" }}]}}],}}}

语句的优先级
前例中每条语句贡献三分之一评分的这种方式可能并不是我们想要的,我们可能对 title 和 author 两条语句更感兴趣,这样就需要调整查询,使 title 和 author 语句相对来说更重要。
GET /_search{"query": {"bool": {"should": [{ "match": {"title": {"query": "War and Peace","boost": 2}}},{ "match": {"author": {"query": "Leo Tolstoy","boost": 2}}},{ "bool": {"should": [{ "match": { "translator": "Constance Garnett" }},{ "match": { "translator": "Louise Maude" }}]}}]}}}
获取 boost 参数 “最佳” 值,较为简单的方式就是不断尝试。
boost 值比较合理的区间处于 1 到 10 之间
单字符串查询(百度查询原理)
bool 适用场景,多条件,多字段映射查询。
但是,当我们输入单个字符串的时候,后怎么样呢?有以下三种情况
- 最佳字段
- 多数字段
- 混合字段
下面将这几种情况,分别介绍:
最佳字段
假设有个网站允许用户搜索博客的内容,以下面两篇博客内容文档为例:
PUT /my_index/my_type/1{"title": "Quick brown rabbits","body": "Brown rabbits are commonly seen."}PUT /my_index/my_type/2{"title": "Keeping pets healthy","body": "My quick brown fox eats rabbits on a regular basis."}
用户输入词组 “Brown fox” 然后点击搜索按钮, 尝试猜想一下,是不是文档2的评分会更高一些呢?
让我们看下结果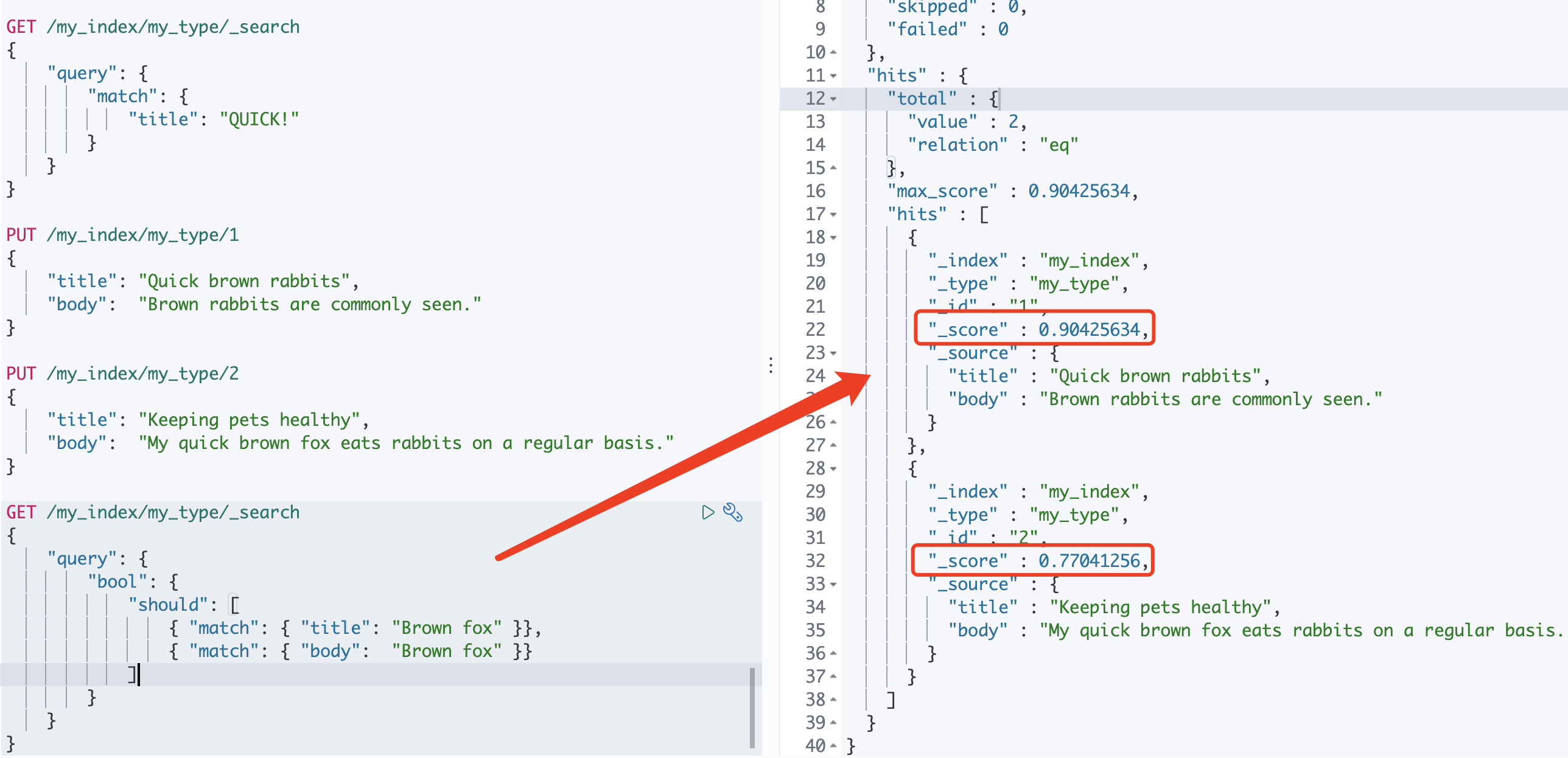
看到上图结果,文档1的评分竟然比文档2高?
下面我们来分析下原因:
先回顾下bool查询的流程:
 文档 1 的两个字段都包含 brown 这个词,所以两个 match 语句都能成功匹配并且有一个评分。文档 2 的 body 字段同时包含 brown 和 fox 这两个词,但 title 字段没有包含任何词。这样, body 查询结果中的高分,加上 title 查询中的 0 分,然后乘以二分之一,就得到比文档 1 更低的整体评分。
文档 1 的两个字段都包含 brown 这个词,所以两个 match 语句都能成功匹配并且有一个评分。文档 2 的 body 字段同时包含 brown 和 fox 这两个词,但 title 字段没有包含任何词。这样, body 查询结果中的高分,加上 title 查询中的 0 分,然后乘以二分之一,就得到比文档 1 更低的整体评分。
在本例中, title 和 body 字段是相互竞争的关系,所以就需要找到单个 最佳匹配 的字段。
那如果要最佳匹配 字段的评分作为查询的整体评分,要怎么做呢
dis_max 查询
全称:分离 最大化查询(Disjunction Max Query)
指将任何与任一查询匹配的文档作为结果返回,但只将最佳匹配的评分作为查询的评分结果返回
{"query": {"dis_max": {"queries": [{ "match": { "title": "Brown fox" }},{ "match": { "body": "Brown fox" }}]}}}
得到我们想要的结果为:
{"hits": [{"_id": "2","_score": 0.21509302,"_source": {"title": "Keeping pets healthy","body": "My quick brown fox eats rabbits on a regular basis."}},{"_id": "1","_score": 0.12713557,"_source": {"title": "Quick brown rabbits","body": "Brown rabbits are commonly seen."}}]}
最佳字段查询调优
一个简单的 dis_max 查询会采用单个最佳匹配字段,而忽略其他的匹配:
{"query": {"dis_max": {"queries": [{ "match": { "title": "Quick pets" }},{ "match": { "body": "Quick pets" }}]}}}
看下结果
{"hits": [{"_id": "1","_score": 0.12713557,"_source": {"title": "Quick brown rabbits","body": "Brown rabbits are commonly seen."}},{"_id": "2","_score": 0.12713557,"_source": {"title": "Keeping pets healthy","body": "My quick brown fox eats rabbits on a regular basis."}}]}
不难发现,他们的评分是一样的
期望同时匹配 title 和 body 字段的文档比只与一个字段匹配的文档的相关度更高,但事实并非如此,因为 dismax 查询只会简单地使用 单个_ 最佳匹配语句的评分 _score 作为整体评分。
tie_breaker 参数
通过tie_breaker 参数也将其他匹配语句的评分也会考虑到
{"query": {"dis_max": {"queries": [{ "match": { "title": "Quick pets" }},{ "match": { "body": "Quick pets" }}],"tie_breaker": 0.3}}}
结果如下:
{"hits": [{"_id": "2","_score": 0.14757764,"_source": {"title": "Keeping pets healthy","body": "My quick brown fox eats rabbits on a regular basis."}},{"_id": "1","_score": 0.124275915,"_source": {"title": "Quick brown rabbits","body": "Brown rabbits are commonly seen."}}]}
终于是我们想要的结果了。
tie_breaker 可以是 0 到 1 之间的浮点数,其中 0 代表使用 dis_max 最佳匹配语句的普通逻辑, 1 表示所有匹配语句同等重要。最佳的精确值需要根据数据与查询调试得出,但是合理值应该与零接近(处于 0.1 - 0.4 之间),这样就不会颠覆 dis_max 最佳匹配性质的根本。
multi_match 查询
multi_match 查询为能在多个字段上反复执行相同查询提供了一种便捷方式。
best_fields 最佳字段
most_fields 多数字段
cross_fields 跨字段
默认情况下,查询的类型是 best_fields ,这表示它会为每个字段生成一个 match 查询,然后将它们组合到 dis_max 查询的内部,如下:
{"dis_max": {"queries": [{"match": {"title": {"query": "Quick brown fox","minimum_should_match": "30%"}}},{"match": {"body": {"query": "Quick brown fox","minimum_should_match": "30%"}}},],"tie_breaker": 0.3}}
用 multi_match 重写成更简洁的形式:
{"multi_match": {"query": "Quick brown fox","type": "best_fields","fields": [ "title", "body" ],"tie_breaker": 0.3,"minimum_should_match": "30%"}}
查询的字段名的模糊匹配
{"multi_match": {"query": "Quick brown fox","fields": "*_title"}}
提升单个字段的权重
可以使用 ^ 字符语法为单个字段提升权重,在字段名称的末尾添加 ^boost ,其中 boost 是一个浮点数:
{"multi_match": {"query": "Quick brown fox","fields": [ "*_title", "chapter_title^2" ]}}
多数字段
全文搜索被称作是 召回率(Recall) 与 精确率(Precision) 的战场:
召回率 ——返回所有的相关文档;
精确率 ——不返回无关文档。
提高全文相关性精度的常用方式是为同一文本建立多种方式的索引,每种方式都提供了一个不同的相关度信号 signal
文档同时又与 signal 信号字段匹配,那么它会获得额外加分
多字段映射
首先要做的事情就是对我们的字段索引两次:一次使用词干模式以及一次非词干模式
DELETE /my_indexPUT /my_index{"settings": { "number_of_shards": 1 },"mappings": {"my_type": {"properties": {"title": {"type": "string","analyzer": "english","fields": {"std": {"type": "string","analyzer": "standard"}}}}}}}PUT /my_index/my_type/1{ "title": "My rabbit jumps" }PUT /my_index/my_type/2{ "title": "Jumping jack rabbits" }
这里用一个简单 match 查询 title 标题字段是否包含 jumping rabbits (跳跃的兔子):
GET /my_index/_search{"query": {"match": {"title": "jumping rabbits"}}}
因为有了 english 分析器,这个查询是在查找以 jump 和 rabbit 这两个被提取词的文档。两个文档的 title 字段都同时包括这两个词,所以两个文档得到的评分也相同:
{"hits": [{"_id": "1","_score": 0.42039964,"_source": {"title": "My rabbit jumps"}},{"_id": "2","_score": 0.42039964,"_source": {"title": "Jumping jack rabbits"}}]}

若有收获,就点个赞吧
0 人点赞
