从高级语言诞生之初,追求更好的抽象是语言设计这一直在努力的目标,因此,产生了许多关于代码复用的想法。其中第一个就是函数,函数允许你在某个具名实体中对一系列指令进行分组,这些指令可以在以后调用多次,并且可以根据需要在每次调用时接受任意参数。它们降低了代码的复杂度,并增强了可读性。不过,函数的能力也就仅限于此了。如果你有一个函数,例如avg,它用于计算给定整数列表的平均值,之后你有一个需求,需要计算浮点数列表的平均值,那么通常的解决方案是创建一个可以对浮点数列表计算平均值的新函数。如果你想计算双精度数值列表平均值该怎么办?我们可能需要再次编写另一个函数。而一遍又一遍的编写相同函数只是因为它们的参数不通,这对程序员来说就是在浪费宝贵的时间。为了减少这种重复,语言设计者想提供一种表述代码的方法,以便avg函数能够接受多种类型的数值,从而成为一个通用函数,由此通用编程和泛型就诞生了。具有可以接收多种类型的参数的函数是泛型编程的特征之一,当然还有其他地方会用到泛型。我们将在本节讨论所有这些内容。
泛型编程是一种仅适用于静态类型编程语言的技术。它首次出现在ML语言中,是一种静态类型的函数式语言。像Python这样的动态语言采用的是简单类型(duck typing),其中的API是根据它们可以做什么,而不是它们是什么来处理参数的,因此不依赖于泛型。泛型是语言设计特性的一部分,可以实现代码复用,并遵循不重复自己的原则(Don't Repeat Yourself, DRY)。采用这种技术,你可以使用类型占位符来编写算法、函数、方法及类型,并在这些类型上指定一个类型变量(使用单个字母,通常是T、K或V),告知编译器在任何代码中实力化它们时要填充的实际类型。这些类型被称为泛型或元素。单个字母(例如类型T)被称为泛型参数。当你使用或实例化任何泛型元素时,它们会被替换成诸如u32这样的具体类型。
:::info
注意:
替换,即每次将泛型元素与具体类型一起使用时,都会在编译时用类型变量 T 生成该代码的特定副本,并将其替换为具体类型。这种在编译时生成包含具体类 型的专用函数的过程被称为单态化,这是执行与多态函数相反的过程。
:::
让我们看一下Rust标准库中已经存在的某些泛型。来自标准库的Vec<T>类型是泛型,其定义如下所示:
pub struct Vec<T> {buf: RawVec<T>,len: usize,}
我们可以看到`Vec`的类型签名在其名称后面包含一个类型参数`T`,并由一对尖头括号`(<>)`标识。它的成员字段`buf`也是泛型,因此`Vec`自身也必须是泛型。如果我们的泛型`Vec<T>`中不包含`T`,那么即使我们的`buf`字段中包含`T`,也会收到以下错误信息:
error[E0412]: cannot find typeTin this scope
T需要成为Vec类型定义的一部分。因此,当我们表示Vec时,通常都会使用Vec<T>来表示,或者在知道具体类型时,使用Vect<u64>来表示。接下来,让我们看看如何创建自定义泛型。
创建泛型
Rust允许我们将多种元素声明为泛型,例如结构体、枚举、函数、特征、方法及代码实现块。它们的一个共同特征是泛型的参数是由一对尖头括号分隔,并包含于其中。
可以在其中放置以逗号分隔的任意数量泛型参数。让我们来看看如何创建泛型,首先从泛型函数开始。
泛型函数
为了创建泛型函数,我们需要将泛型参数放在函数名之后和圆括号之前,如下所示:
fn give_me<T>(value: T) {let _ = value;}fn main() {let a = "generics";let b = 1024;give_me(a);give_me(b);}
上述代码中,give_me是一个泛型函数,其名称后面带有<T>,value参数的类型为T。在main函数中,我们可以使用任何参数调用此函数。在编译期,已编译的目标文件将包含此函数的两个专用副本。
可以使用nm命令在生成的二进制文件中确认这一点,如下所示:

nm 是 GNU binutils 软件包中的实用程序,用于查看已编译对象文件的符号。通过对二 进制文件执行 nm 命令,我们可以使用 pipe 和 grep 查找 give_me 函数的前缀。如你所见, 我们有两个函数副本,并附加了随机 ID 用于区分它们。其中一个会接收&str,而另一个会 接收 i32 类型的参数,因为有两个包含不同参数的调用。
统一性
在**<font style="color:rgb(13, 13, 13);">give_me<T></font>** 和 (**<font style="color:rgb(13, 13, 13);">value: T</font>**) 中使用的 **<font style="color:rgb(13, 13, 13);">T</font>** 是统一的,指的是同一个泛型类型。当你调用 **<font style="color:rgb(13, 13, 13);">give_me</font>** 函数时,你需要提供一个特定类型的参数,那个类型就是 **<font style="color:rgb(13, 13, 13);">T</font>** 的具体实现。例如:
give_me(5); // 这里 T 被推断为 i32give_me("Hi"); // 这里 T 被推断为 &str
泛型结构体
可以声明泛型的元组结构体和普通结构体,如下所示:
struct GenericStruct<T>(T);struct Container<T> {item: T}fn main() {//stuff}
上述代码所示,泛型结构体在结构体名称后面包含泛型参数。因此,无论我们在代码中的任何地方表示上述结构体,都需要将<T>作为类型的一部分一起输入。
创建泛型枚举:
enum Transmission<T> {Signal(T),NoSignal}fn main() {//stuff}
枚举Transmission包含一个名为Signal的变体(包含一个泛型值),还有一个名为NoSignal的变体(是一个无值变体)。
泛型实现
我们可以为泛型编写impl代码块,但由于额外的泛型参数,它在这里会变得冗长。让我们在结构体Container<T>上实现一个new()方法:
struct Container<T> {item:T}impl Container<T> {fn new(item: T) -> Self {Container { item }}}fn main(){//stuff}
我们对它进行编译,得到以下错误提示信息:
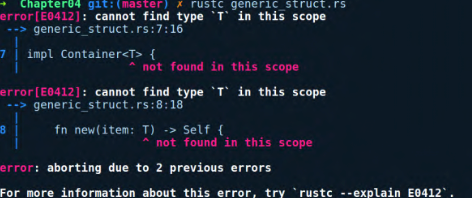
错误提示信息提示我们无法找到泛型T。当为任何泛型编写impl代码块时,都需要在使用它之前声明泛型参数。T就像一个变量,一个类型变量,我们需要先声明它。因此,需要在impl之后添加<T>来稍微改动一下代码,如下所示:
impl<T> Container<T> {fn new(item: T) -> Self {Container { item }}}
进过修改,上述代码通过了编译。之前的impl代码块实际上意味着我们正在为所有类型T实现这些方法,它们会出现在Container<T>中。这个impl代码块是一个泛型实现。因此,生成的每个具体Container都将有这些方法。现在,我们也可以通过将T替换为任何具体类型来为Container<T>编写更具体的impl代码块。以下就是它的实例:
impl Container<u32> {fn sum(item: u32) -> Self {Container { item }}}
上述代码中,我们实现了一个名为sum的方法,它只会出现在Container<u32>类型中。在这里,由于u32是作为具体类型存在的,因此我们不需要impl之后的<T>,这是impl代码块的另外一个特性,它允许你通过独立实现方法来专门化泛型。
泛型应用
实例化或使用泛型的方式也与非泛型略有不同。每当我们进行实例化时,编译器需要在其类型签名中知道T的具体类型以便替换,这为了其提供了将泛型代码单态化的类型信息。大多数情况下,具体类型是基于类型的实例化推断的,或者对泛型函数调用某些方法来接受具体类型。在极个别情况下,我们需要通过使用turbofish(::<>)运算符输入具体类型来替代泛型以便辅助编译器识别。我们马上会看到该运算符的具体用法。
让我们看一下实例化Vec<T>的情况,这是一种泛型。在没有任何类型特征的情况下。下列代码将无法编译:
fn main() {let a = Vec::new();}
编译上述代码,将会给出如下错误提示信息:
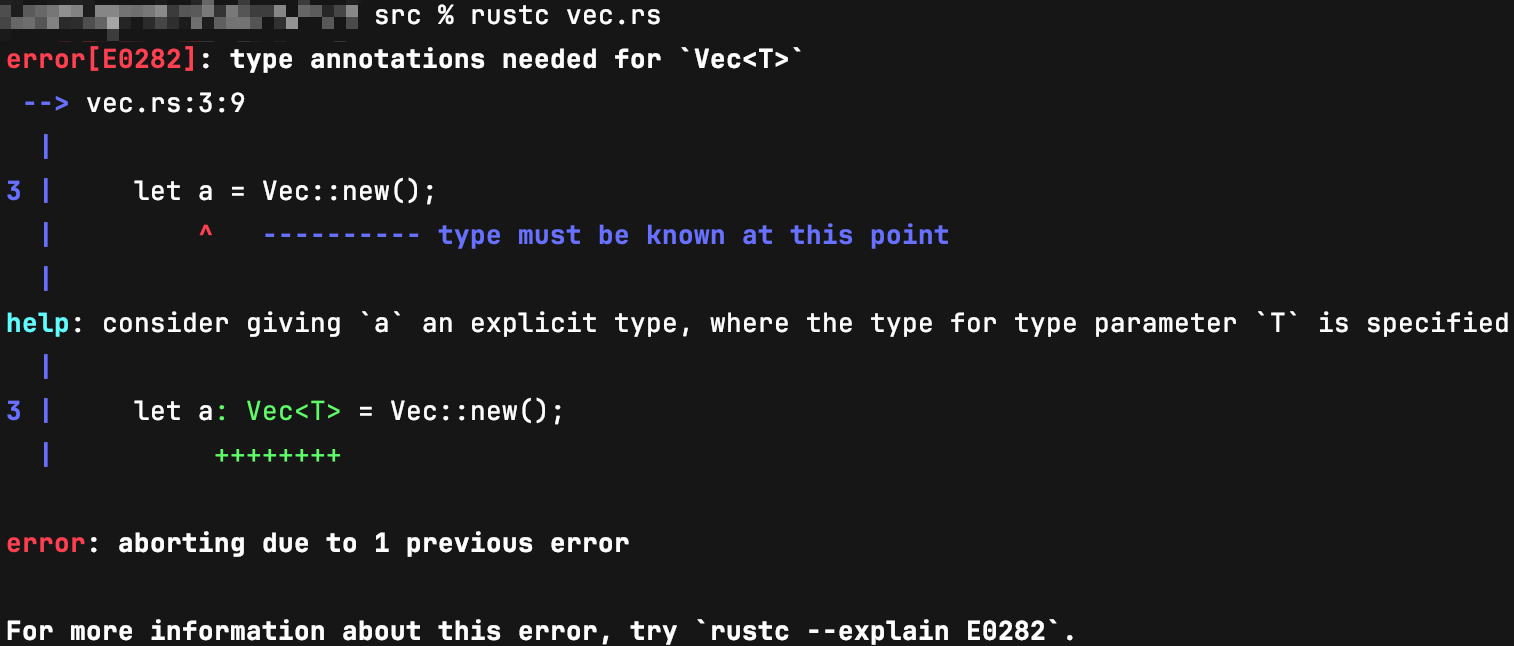
这是因为在我们手动指定它或调用其中某个方法之前,编译器不知道a的类型,不便为其传入一个具体的值。如下的代码片段所示:
fn main() {//提供一种类型let v1: Vec<u8> = Vec::new();//或者调用某个方法let mut v2 = Vec::new();v2.push(2); //现在v2类型是 Vec<i32>//或者使用 turbofish 符号let v3 = Vec::<u8>::new(); //不是那么容易理解}
在第2个代码片段中,我们将v1的类型指定为u8的Vec,它能够通过编译。与v2一样,另一种方法是调用接收任何具体类型的方法。在调用push方法之后,编译器可以推断出v2的类型是Vec<i32>。创建Vec的另一种方法是使用turbofish运算符,就像前面代码中的v3绑定一样。
泛型函数中的turbofish运算符出现在函数吗之后和圆括号之前。另一个示例是std::str模块的泛型解析函数parse。parse可以解析字符串中的值,并且支持多种类型,例如i32、f64及usize等,因此它是一种泛型。在使用parse时,你确定需要使用turbofish运算符,如下代码所示:
use std::str;fn main() {let num_from_str = str::parse::<u8>("34").unwrap();println!("Parsed number {}", num_from_str);}
需要注意的是,只有实现了FromStr接口或特征的类型才能传递给parse函数。u8有一个FromStr的实现,所以我们能够在前面的代码中解析它。parse函数用FromStr特征来限制传递给它的类型。在我们介绍了特征之后,将能够把泛型和特征很好地结合起来使用。

若有收获,就点个赞吧
0 人点赞
