当业务需求发生变化,并且你的程序需要更高效地运行时,首先要做的是找出程序中 速度较慢的部分。如何知道程序的瓶颈在哪里?可以通过在各种预期区间或输入量上测试 程序的各个部分来判断。这被称为代码的基准测试。基准测试通常会在开发的最后阶段(但不绝对)进行,以便对代码中存在性能缺陷的部分进行识别和优化。
为程序进行基准测试的方法有多种。最简单的方法是使用 UNIX 操作系统的时间工具 来记录更改后的程序的执行时间,但这样并不能提供精确的微观层面的洞察。Rust 为我们 提供了一个微观基准框架。对于微观基准测试,这个框架可以单独对代码中的各个部分进 行基准测试,而不受外部因素的影响。然而,这也意味着我们不应该仅依赖于微观基准, 因为现实世界的结果可能会有所偏差。因此,微观基准之后通常会进行代码分析和宏观基 准测试。尽管如此,微观基准测试通常是提高代码性能的起点,因为各个部分对程序的整 体运行时间有很大影响。
在本节中,我们将讨论 Rust 内置的微观基准性能测试工具。Rust 降低了在开发初始阶 段编写基准测试代码的门槛,而不是将它作为最后的手段。运行基准测试的方式和运行普 通测试的方式类似,但是使用的是 cargo bench 命令。
内置的微观基准工具
Rust 内置的基准测试框架通过运行多次迭代来评估代码的性能,并报告相关操作的平均时间。这得益于以下两件事。
- 函数上方的
#[bench]注释,这表示该函数是一个基准测试。 - 内部编译器软件包
libtest包含一个Bencher类型,基准函数通过它在多次迭代中运行相同的基准代码,此类型是针对编译器内部的,只适用于测试模式。
现在,我们将编写并运行一个简单的基准测试。让我们通过cargo new -lib bench_example命令创建一个新的项目。不需要对Cargo.toml文件做任何修改。src/lib.rs中的内容如下所示:
#![feature(test)]extern crate test;use test::Bencher;pub fn do_nothing_slowly(){println!(".");for _ in 0..10_000_000 {}}pub fn do_nothing_fast(){}#[bench]fn bench_nothing_slowly(b: &mut Bencher){b.iter(|| do_nothing_slowly());}#[bench]fn bench_nothing_fast(b: &mut Bencher){b.iter(|| do_nothing_fast());}
注意,我们必须在 `test` 前面使用 `extern crate` 来声明内部软件包测试,以及`#[feature(test)]` 属性注释。`extern` 声明对于编译器内部的软件包而言是必须的。在编译器未来的版本中, 可能不需要这样,并且你可以像使用普通的软件包一样使用它们。
如果我们通过 cargo bench 命令运行基准测试代码,将会得到以下输出结果:
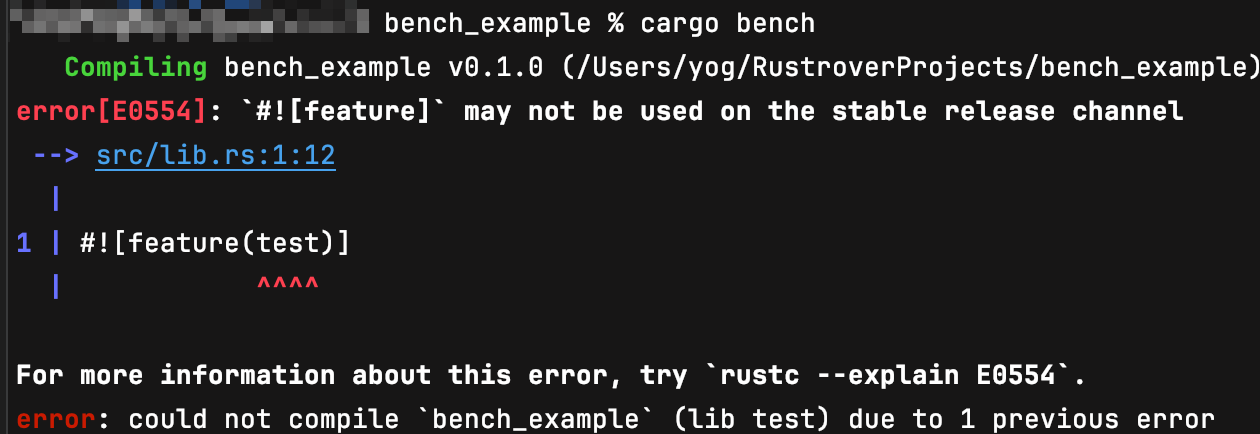
基准测试是一个不稳定的特性,所以我们必须使用夜间版的编译器。但幸运的是,通过 `rustup`,在 `Rust` 编译器的不同发布通道之间切换很容易。首先,我们将通过 运行 `rustup update nightly` 命令确保已经安装了夜间版的编译器。其次,在 `bench_example` 目录中,我们将通过运行 `rustup override set nightly` 命令来覆盖此目录的默认工具链。现在, 运行 `cargo bench` 命令后将得到以下输出结果:
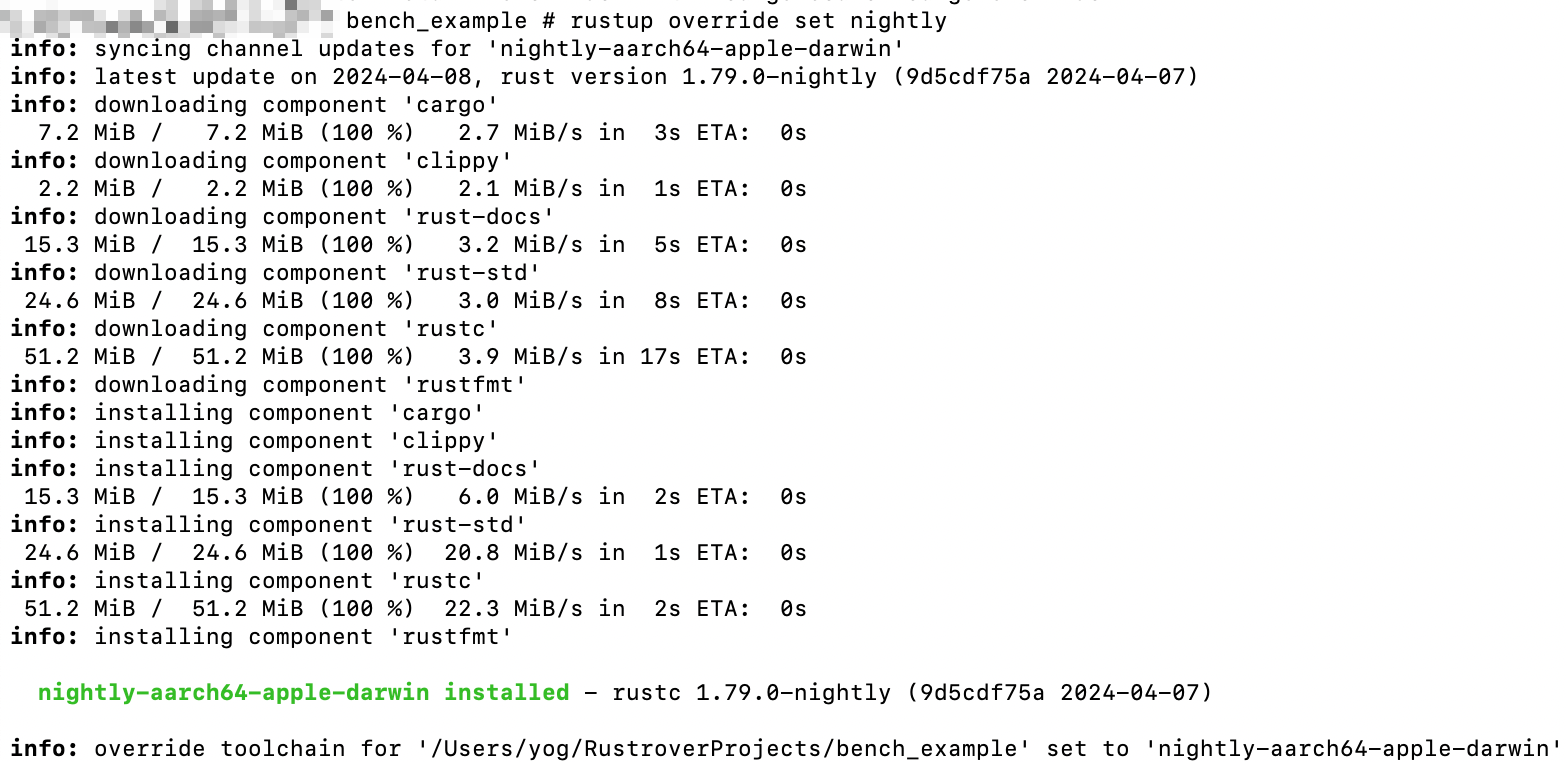

这是以纳秒(ns)为单位的执行每次迭代花费的时间,括号内的数字表示每次运行之 间的差异。性能较差的实现的运行速度非常慢,并且运行时间不固定(用+/−符号所示)。
在标有#[bench]注释的函数内部,iter 的参数是一个没有参数的闭包函数。如果闭包有 参数,那么它们将位于“||”之内。这实际上意味着 iter 传递的函数可以使基准测试重复运 行。我们在函数中输出一个“.”,这样 Rust 就不至于对空循环进行优化。如果其中不存在 println!()宏调用,编译器将会优化代码不执行该循环,那么会得到错误的结果。有多种办 法来解决此问题,如可以通过使用 tests 模块中的 black_box 函数来完成。不过,即使使用 该函数也不能保证优化器不会优化你的代码。现在,我们还有第三方的解决方案——在稳定版 Rust 上执行基准测试。
稳定版Rust上的基准测试
Rust 内置的基准测试框架不稳定,幸运的是,社区开发的基准测试软件包能够兼容稳 定版的 Rust。这里我们将介绍的一款当前非常流行的软件包是 criterion-rs。该软件包在简 单、易用的同时提供有关基准代码的详细信息。它还能够维护上次运行的状态,报告程序 每次运行时的性能差异(如果有的话)。criterion-rs 会生成比内置基准测试框架更多的统计 报告,并使用 gnuplot 生成实用的图形和报表,使用户更容易理解。
为了演示该软件包的使用,我们将通过 cargo new criterion_demo --lib 命令创建一个 新的软件包。然后在 Cargo.toml 中将 criterion 软件包作为 dev-dependencies 下的依赖项来 引入它:
[dev-dependencies]criterion = "0.5"[[bench]]name = "fibonacci"harness = false
我们还添加了一个名为“[[bench]]”的新属性,它向 Cargo 表明我们有一个名为 fibonacci 的新基准测试,并且它不使用内置的基准测试工具(harness=false)。因为我们正在使用 criterion 软件包的测试工具。
在我们的 scr/lib.rs 文件中,包含计算第 n 个 fibonacci 数函数的一个快速版本和一个慢 速版本(初始值 n0=1,n1=1):
pub fn slow_fibonacci(nth: usize) -> u64 {if nth <= 1 {return nth as u64;}else {return slow_fibonacci(nth - 1) + slow_fibonacci(nth -2);}}pub fn fast_fibonacci(nth: usize) -> u64 {let mut a = 0;let mut b = 1;let mut c = 0;for _ in 1..nth {c = a + b;a = b;b = c;}c}
函数 fast_fibonacci 是通过自下而上的方式迭代获得第 n 个 fibonacci 数的,而 slow_ fibonacci 是慢速递归版本的函数。现在,criterion-rs 要求我们将基准测试代码放到 benches/ 目录下,该目录一般位于我们创建的项目根目录。在 benches/目录下,我们也创建了一个 名为 fibonacci.rs 的文件,该文件与 Cargo.toml 文件中“[[bench]]”项下的名称匹配,它具有以下内容:
#[macro_use]extern crate criterion;extern crate criterion_demo;use criterion_demo::{fast_fibonacci, slow_fibonacci};use criterion::Criterion;fn fibonacci_benchmark(c: &mut Criterion){c.bench_function("fibonacci 8",|b| b.iter(|| slow_fibonacci(8)));}criterion_group!(fib_bench, fibonacci_benchmark);criterion_main!(fib_bench);
这里完成了很多操作!在上述代码中,我们首先声明需要用到的软件包,并导入希望对 `fibonacci` 函数进行基准测试的函数(`fast_fibonacci` 和 `slow_fibonacci`)。此外,“`extern crate criterion`”上面有一个`#[macro_use]`属性,这意味着要使用来自此软件包的任何宏时,我们需要使用此属性来选择它,因为默认情况下它们是非公开的。它类似于 `use` 语句,用于公开模块中的元素。
现在 criterion 已经具有可以保存相关基准测试代码基准组的标记。此外,我们创建了 一个名为 fibonacci_benchmark 的函数,之后会将其传递给宏 criterion_group!。这会将 fib_bench 的基准名称分配给基准组。fibonacci_benchmark 函数会接收一个指向 criterion 对 象的可变引用,它保存了基准代码的运行状态,公开了一个名为 bench_function 的函数, 通过它传递基准代码以在具有给定名称的闭包中运行(在 fibonacci 8 之上)。然后,我们需 要创建主要的基准测试工具,在传入基准测试组 fib_bench 之前,它会生成带有 main 函数 的代码,以便通过宏 criterion_main!运行所有代码。现在闭包中将 cargo bench 命令和第一 个 slow_fibonacci函数一起运行。我们得到以下输出结果:
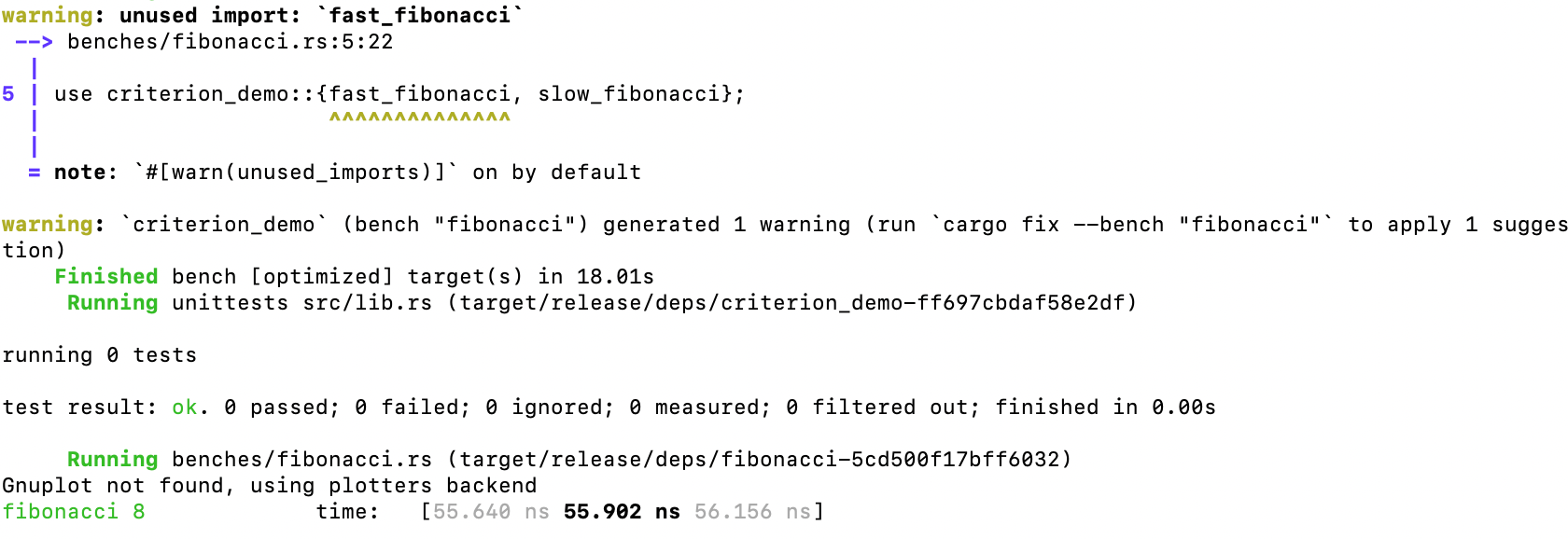
我们可以看到,递归版本的 fibonacci 函数运行时间平均约为 106.95ns。现在,在相同 的基准测试闭包中,如果我们使用 fast_fibonacci函数替换 slow_fibonacci 函数,并再次运 行 cargo bench 命令,将会得到以下输出结果:
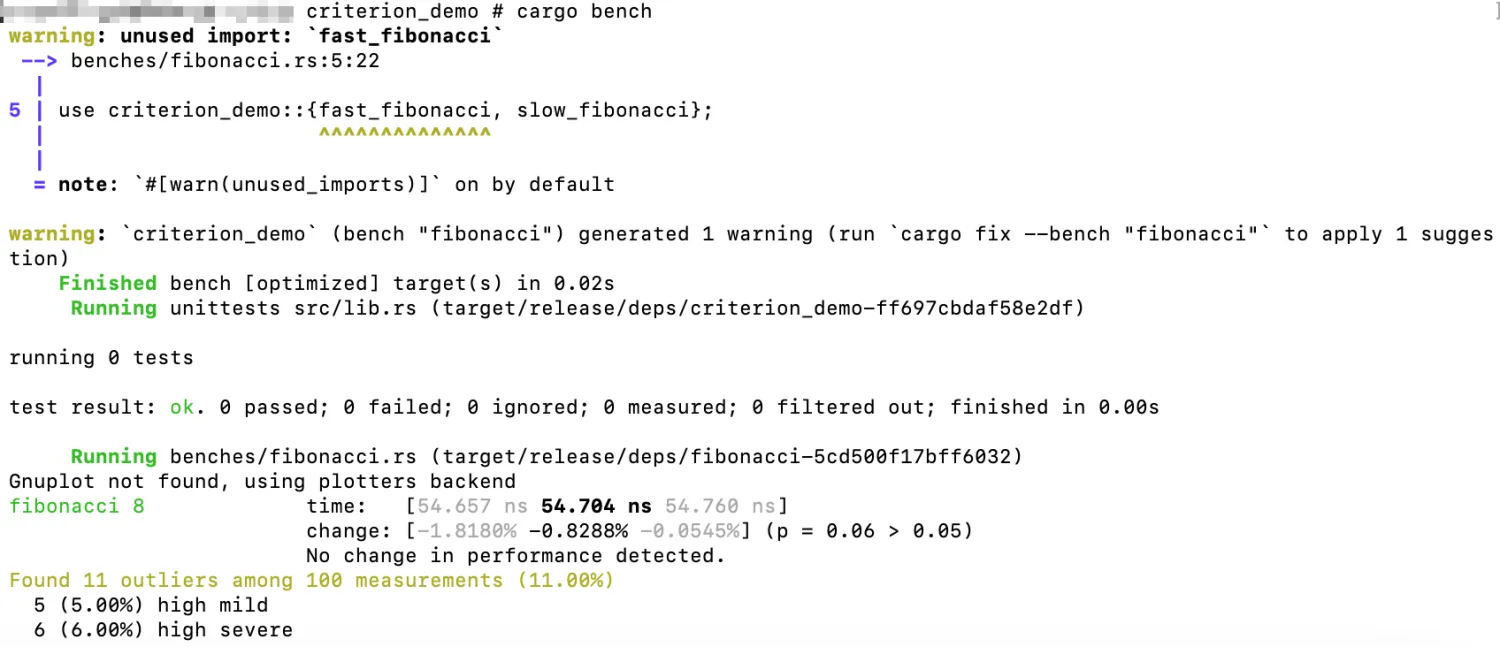
fast_fibonacci 函数运行时间平均约为 7.8460ns。差异非常明显,但更重要的是详细的 基准测试报告,它显示了一条友好的信息:“Performance has improved”(性能得到了改善)。 criterion 能够显示性能差异报告的原因是它会维护基准测试先前的状态,并使用其历史记录 来报告程序的性能变化。

若有收获,就点个赞吧
0 人点赞
