- 模块一
- Hadoop简介
- HDFS:分布式文件系统。存储
- MapReduce:分布式离线计算框架。计算
- Yarn:资源调度框架
- Common模块
- 大数据特点(5个)
- 大量
- 高速
- 多样
- 真实
- 低价值
- Hadoop是一个适合大数据的分布式存储和计算平台
- Hadoop特点
- 扩容能力:在集群内完成数据分配和计算任务。
- 低成本:通过服务器组成的集群在分发和处理数据。
- 高效率:可以动态并行的移动数据,速度很快。
- 可靠性:自动维护数据的多份复制,任务失败会自动重新部署计算任务。
- 缺点:不适用于低延迟数据访问;不能高效存储大量小文件;不支持用户写入和任意的修改文件。
- HDFS(NameNode、SecondaryNameNode、DataNode)
- 数据切割、制作副本、分散存储
- 存入过程
- 对于大数据进行拆分,切割得到多个数据块
- 获取过程
- 向nameNode请求获取到之前存入的文件块以及文件块所在的dataNode的信息,分别下载并最终合并,就得到之前的文件了。
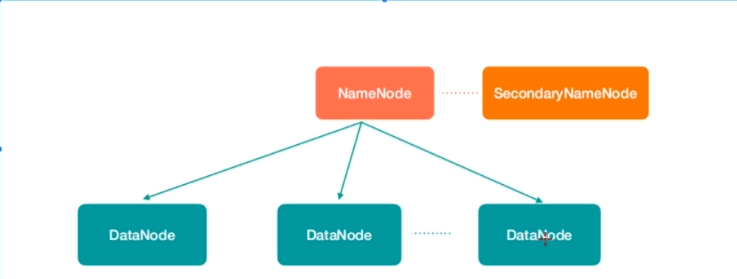
- nameNode:主节点,管理和维护元数据;记录了文件的块列表以及块所在的DataNode节点信息。
- DataNode:从节点,存储数据块。
- secondaryNameNode:辅助nameNode管理和维护元数据。
- 三者:既是角色名称也是进程名称,也代指电脑节点。
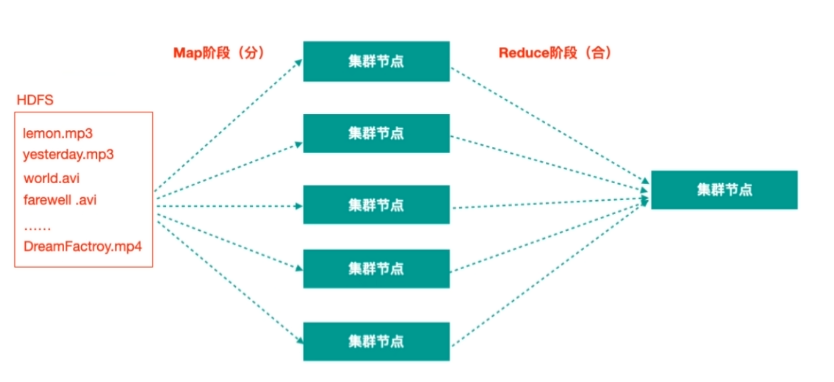
- MapReduce
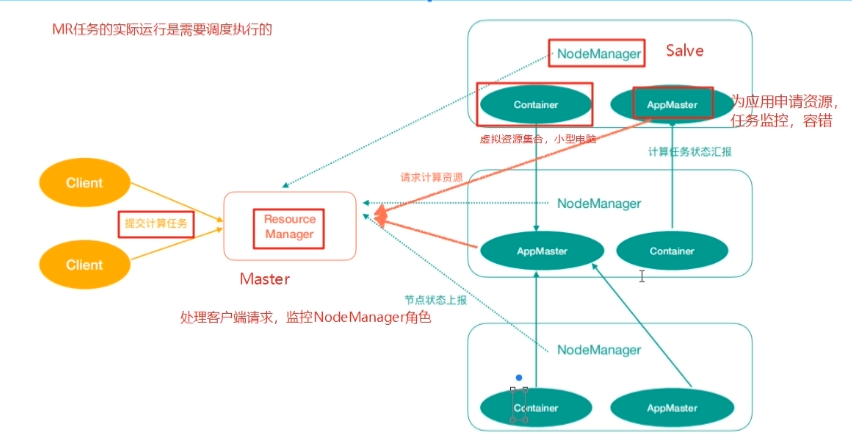
- Yarn
- Common模块
- 支持其他模块的工具模块(Configuration、RPC、序列化机制、日志操作)
- Hadoop简介
Hadoop分布式集群搭建 | 框架 | linuxHadoop | linuxHadoop2 | linuxHadoop3 | | —- | —- | —- | —- | | HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode | | YARN | NodeManager | NodeManager | ResourceManager、NodeManager |

若有收获,就点个赞吧
0 人点赞
