1. Rebalance 简介
Rebalance (再均衡) 机制指的是:将一个 Topic 下的多个队列(或称之为分区),在同一个消费者组(consumer group)下的多个消费者实例(consumer instance)之间进行重新分配。
Rebalance 机制本意是为了提升消息的并行处理能力。例如,一个 Topic 下 5 个队列,在只有 1 个消费者的情况下,那么这个消费者将负责处理这 5 个队列的消息。如果此时我们增加一个消费者,那么可以给其中一个消费者分配 2 个队列,给另一个分配 3 个队列,从而提升消息的并行处理能力。如下图: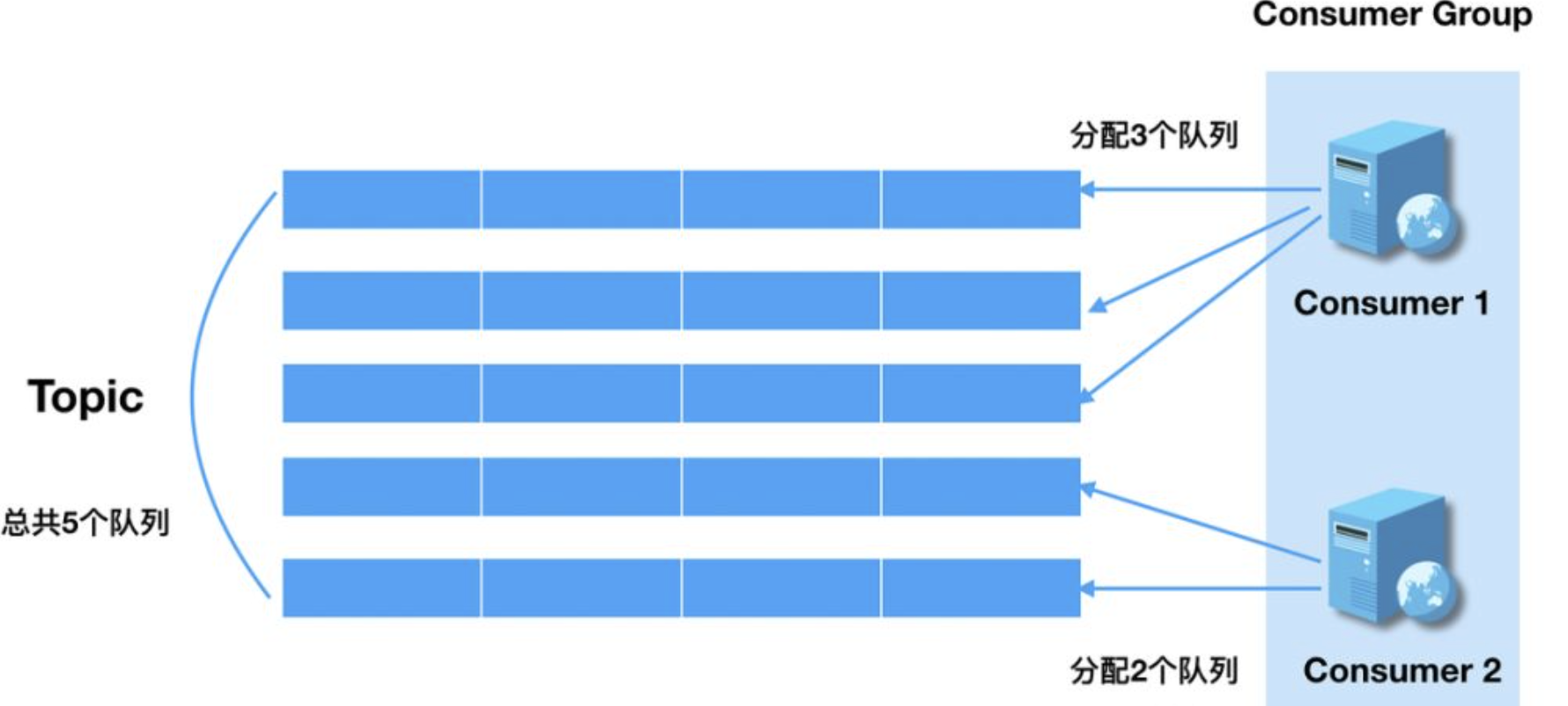
但是 Rebalance 机制也存在明显的限制与危害。
Rebalance 限制:
- 由于一个队列最多分配给一个消费者,因此当某个消费者组下的消费者实例数量大于队列的数量时,多余的消费者实例将分配不到任何队列。
Rebalance 危害:
- 消费暂停:考虑在只有 Consumer 1 的情况下,其负责消费所有 5 个队列;在新增 Consumer 2,触发 Rebalance 时,需要分配 2 个队列给其消费。那么 Consumer 1 就需要暂停这 2 个队列的消费,等到这两个队列分配给 Consumer 2 后,这两个队列才能继续被消费。
- 重复消费:Consumer 2 在消费分配给自己的 2 个队列时,必须接着从 Consumer 1 之前已经消费到的 offset 继续开始消费。然而默认情况下,offset 是异步提交的,如 consumer 1 当前消费到 offset 为10,但是异步提交给 broker 的 offset 为 8;那么如果 consumer 2 从 8 的 offset 开始消费,那么就会有 2 条消息重复。也就是说,Consumer 2 并不会等待 Consumer1 提交完 offset 后,再进行 Rebalance,因此提交间隔越长,可能造成的重复消费就越多。
- 消费突刺:由于 rebalance 可能导致重复消费,如果需要重复消费的消息过多;或者因为 rebalance 暂停时间过长,导致积压了部分消息。那么都有可能导致在 rebalance 结束之后瞬间可能需要消费很多消息。
基于 Rebalance 可能会给业务造成的负面影响,我们有必要对其内部原理进行深入剖析,以便于问题排查。我们将从 Broker 端和 Consumer 端两个角度来进行说明:
- Broker 端主要负责 Rebalance 元数据维护,以及通知机制,在整个消费者组 Rebalance 过程中扮演协调者的作用;
- Consumer 端分析,主要聚焦于单个 Consumer 的 Rebalance 流程。
2. Broker 端 Rebalance 协调机制
从本质上来说,触发 Rebalance 的根本因素无非是两个:
- 订阅 Topic 的队列数量变化
- 消费者组信息变化
导致二者发生变化的典型场景如下所示:
| 两种方式 | 典型场景 |
|---|---|
| 队列信息变化 | - broker 宕机 - broker 升级等运维操作 - 队列扩容/缩容 |
| 消费者组信息变化 | - 日常发布过程中的停止与启动 - 消费者异常宕机 - 网络异常导致消费者与Broker断开连接 - 主动进行消费者数量扩容/缩容 - Topic 订阅信息发生变化 |
在这里,笔者将队列信息和消费者组信息称之为 Rebalance 元数据,Broker 负责维护这些元数据,并在二者信息发生变化时,以某种通知机制告诉消费者组下所有实例,需要进行 Rebalance。从这个角度来说,Broker 在 Rebalance 过程中,是一个协调者的角色。
在 Broker 内部,通过元数据管理器维护了 Rebalance 元数据信息,如下图所示: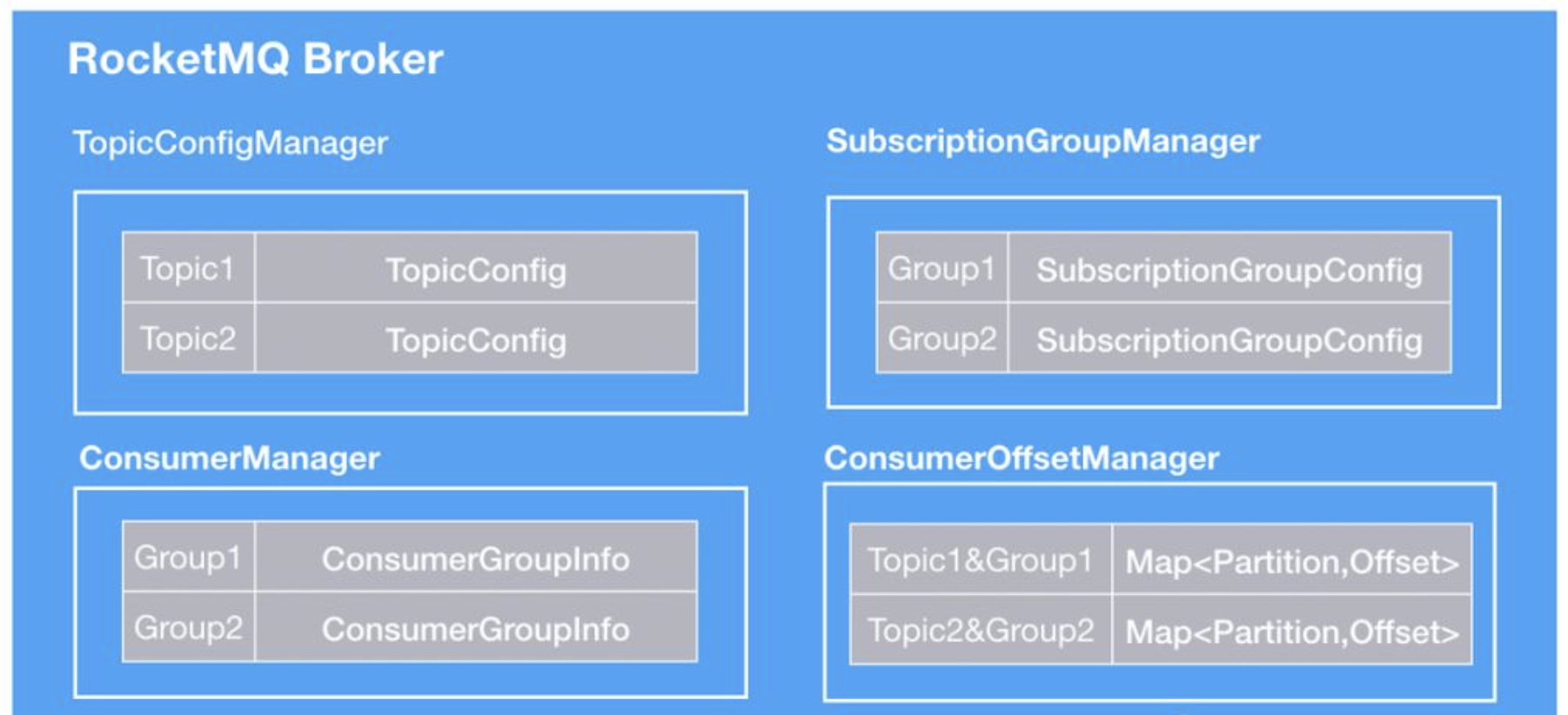
这些管理器,内部实现都是一个 Map。其中:
- 队列信息:由
TopicConfigManager维护。Map 的 key 是 Topic 名称,Value 是 TopicConfig。Broker 通过实时的或者周期性的上报自己的 Topic 配置信息给 NameServer,在 NameServer 组装成 Topic 的完整路由信息。消费者定时向 NameServer 定时拉取最新路由信息,以实现间接通知,当发现队列信息变化,触发 Rebalance。 - 消费者组信息:由 ConsumerManager、ConsumerOffsetManager、SubscriptionGroupManager 三者共同维护。
ConsumerManager维护了消费者组订阅信息,以及消费者组下当前的消费者实例信息,当消费者组的订阅信息或者实例发生变化,Broker 都会主动给所有消费者实例发送通知,触发 Rebalance。而在 Rebalance 时,消费者需要从ConsumerOffsetManager查询应该从哪个位置继续开始消费。SubscriptionGroupManager主要是维护消费者组的一些附加信息,方便运维。
2.1 队列信息变化
队列信息通过 Broker 内的 TopicConfigManager 来维护,每个 Broker 都会将自己的信息上报给 NameServer,由 NameServer 组装成完整的 Topic 路由信息。
通常情况下,一个 Topic 下的队列数量不会频繁的变化,但是如果遇到,Topic 队列数量扩/缩容,、broker 日常运维时的停止/启动或者 broker 异常宕机,也有可能导致队列数量发生变化。
这里我们重点讲一下为什么 broker 异常停止/宕机会导致数量变化。一些读者可能会认为创建 Topic 时,已经明确指定了队列的数量,那么之后不论怎样,队列的数量信息都不会发生变化,这是一种典型误解。
下图展示了一个 RocketMQ 集群双主部署模式下,某个 broker 宕机后,Topic 路由信息的变化。
可以看到,在宕机前,主题 TopicX 下队列分布在 broker-a 和 broker-b 两个 broker 上,每个 broker 上各有 8个队列。当 broker-a 宕机后,其路由信息会被移除,此时我们就只能看到 TopicX 在 broker-b 上的路由信息。
因此,在 RocketMQ 中,Topic 的路由信息实际上是动态变化的。不论是停止/启动/扩容导致的所有变化最终都会上报给 NameServer。客户端可以给 NameServer 发送 **GET_ROUTEINTO_BY_TOPIC** 请求,来获得某个 Topic 的完整路由信息。如果发现队列信息发生变化,则触发 Reabalance。
关于 NameServer 的更多知识,可参考:RocketMQ NameServer深入剖析
2.2 消费者组信息变化
Rebalance 的另外一个条件:消费者组信息,Broker 端通过以下三个组件共同维护:
ConsumerManager:维护消费者实例信息和订阅信息ConsumerOffsetManager:维护 offset 进度信息SubscriptionGroupManager:运维相关操作信息维护
ConsumerManager
ConsumerManager 是最重要的一个消费者组元数据管理器,其维护了某个消费者组的订阅信息,以及所有消费者实例的详细信息,并在发生变化时提供通知机制。
- 数据添加:客户端通过发送
HEART_BEAT请求给 Broker,将自己添加到 ConsumerManager 中维护的某个消费者组中。需要注意的是,每个 Consumer 都会向所有的 Broker 进行心跳,因此每个 Broker 都维护了所有消费者的信息。 - 数据删除:客户端正常停止时,发送 UNREGISTER_CLIENT 请求,将自己从 ConsumerManager 移除;此外在发生网络异常时,Broker 也会主动将消费者从 ConsumerManager 中移除。
- 数据查询:消费者可以向任意一个 Broker 发送 GET_CONSUMER_LIST_BY_GROUP 请求,来获得一个消费者组下的所有消费者实例信息。
我们可以通过 mqadmin 命令行工具的 consumerConnection 子命令,来查看某个消费者的信息,如:
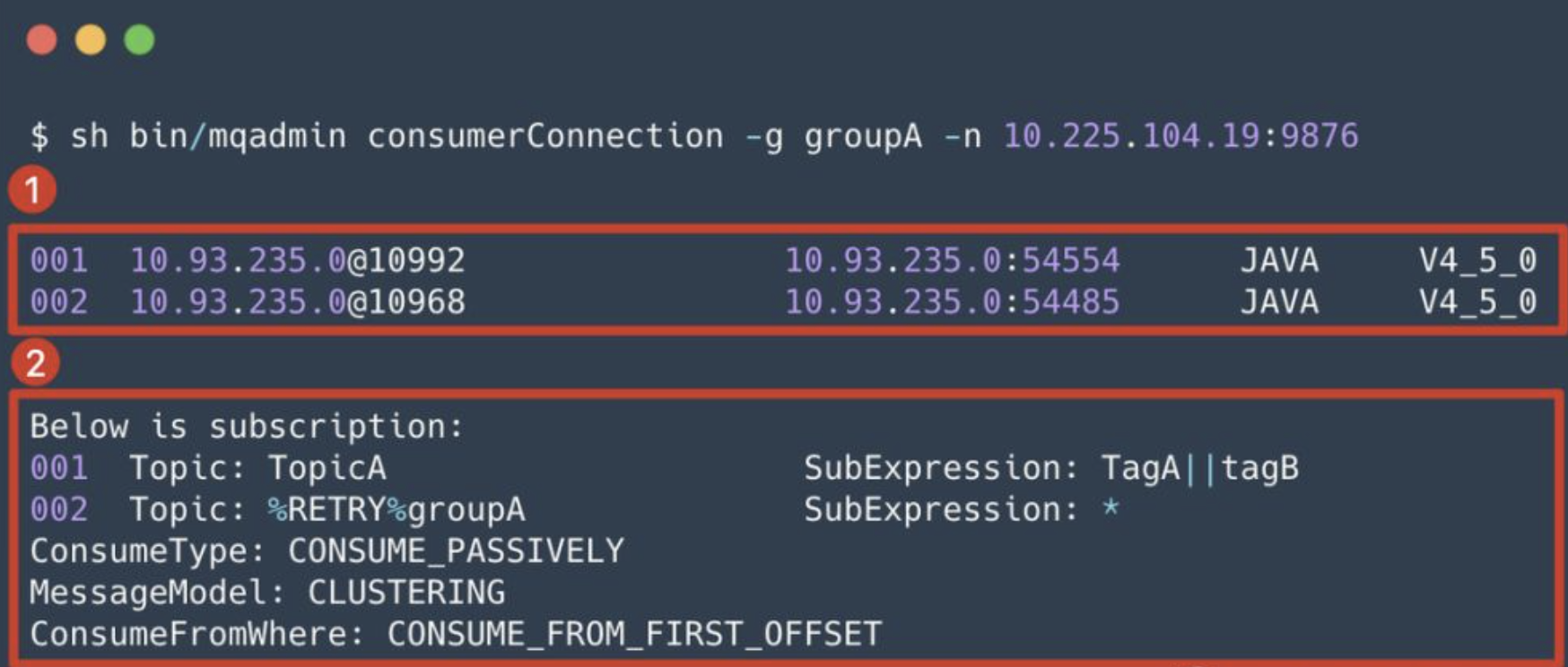
输出主要分为 2 个部分:
- 消费者组实例信息:展示了 groupA 下当前有 2 个消费者,以及对应的详细信息,包括:消费者 id,消费者 ip/port,消费者语言,消费者版本。
- 消费者组订阅信息:包括订阅的 Topic,过滤条件,消费模式,以及从什么位置开始消费等。
这二者不论哪个信息发生变化,Broker 都会主动通知这个消费者组下的所有实例进行 Rebalance。在 ConsumerManager 的 registerConsumer 方法中,我们可以看到这个通知机制。如以下源码片段红色框中所示:
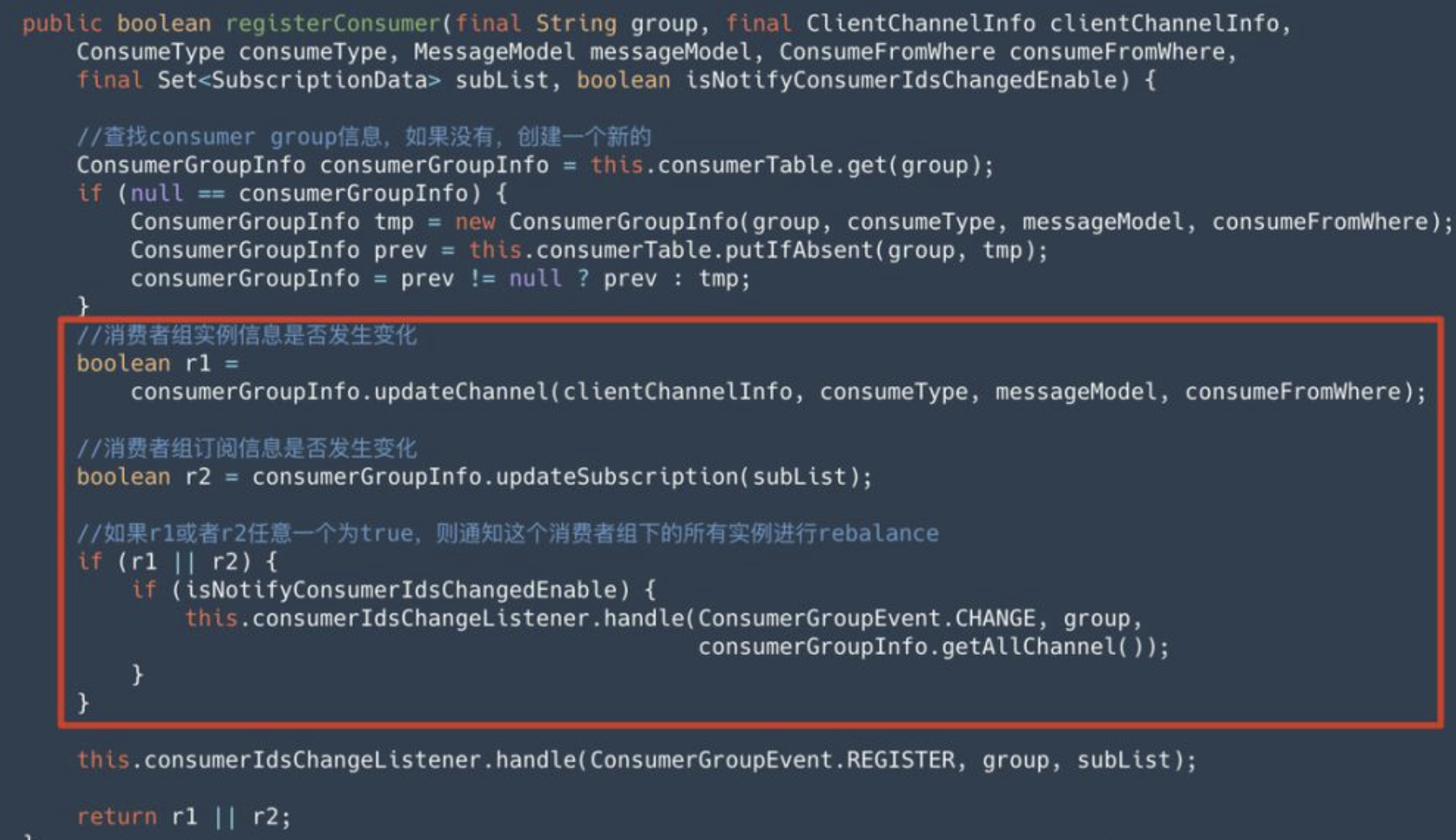
consumerIdsChangeListene 在处理消费者组信息变更事件时,会给每个消费者实例都发送一个通知,各个消费者实例在收到通知后触发 Rebalance,如下图所示: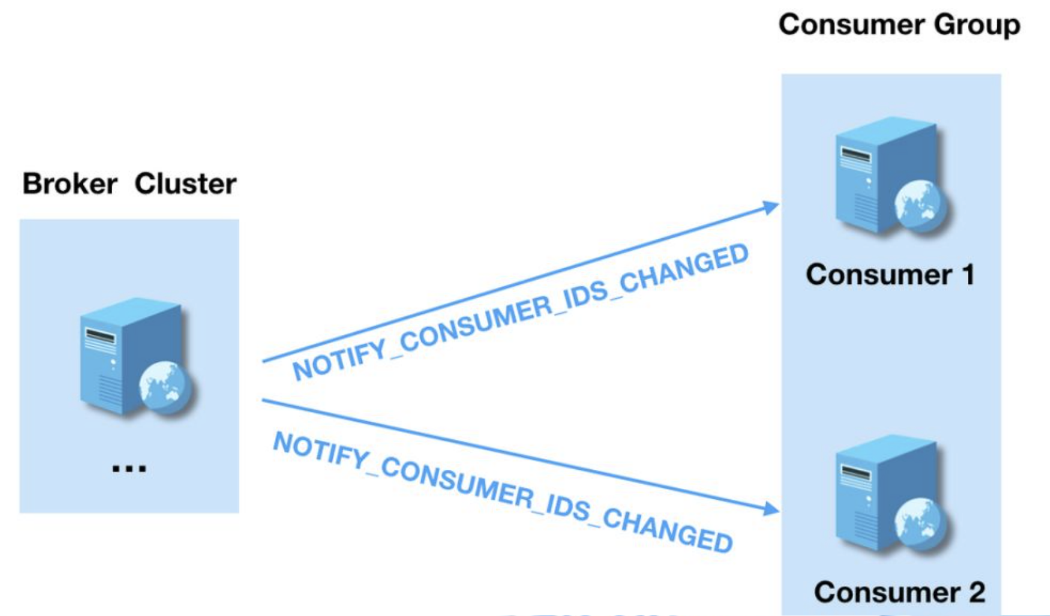
敏锐读者注意到了,Broker 是通知每个消费者各自 Rebalance,即每个消费者自己给自己重新分配队列,而不是 Broker 将分配好的结果告知 Consumer。从这个角度,RocketMQ 与 Kafka Rebalance 机制类似,二者 Rebalance 分配都是在客户端进行,不同的是:
- Kafka:会在消费者组的多个消费者实例中,选出一个作为 Group Leader,由这个 Group Leader 来进行分区分配,分配结果通过 Cordinator (特殊角色的 broker )同步给其他消费者。相当于 Kafka 的分区分配只有一个大脑,就是 Group Leader。
- RocketMQ:每个消费者,自己负责给自己分配队列,相当于每个消费者都是一个大脑。
此时,我们需要思考2个问题:
- 问题1:每个消费者自己给自己分配,如何避免脑裂的问题呢?
- 因为每个消费者都不知道其他消费者分配的结果,会不会出现一个队列分配给了多个消费者,或者有的队列分配给了多个消费者。
- 问题2:如果某个消费者没有收到 Rebalance 通知怎么办?
- 每个消费者都会定时触发 Rebalance,以避免 Rebalance 通知丢失。
ConsumerOffsetManager
事实上,通过 ConsumerManager 已经可以获得 Rebalance 时需要的消费者所有必要信息。但是还有一点,Rebalance 时,如果某个队列重新分配给了某个消费者,那么必须接着从上一个消费者的位置继续开始消费,这就是 ConsumerOffsetManager 的作用。
消费者发送 UPDATE_CONSUMER_OFFSET 请求给 Broker,来更新消费者组对于某个 Topic 的消费进度。发送 QUERY_CONSUMER_OFFSET 请求,来查询消费进度。
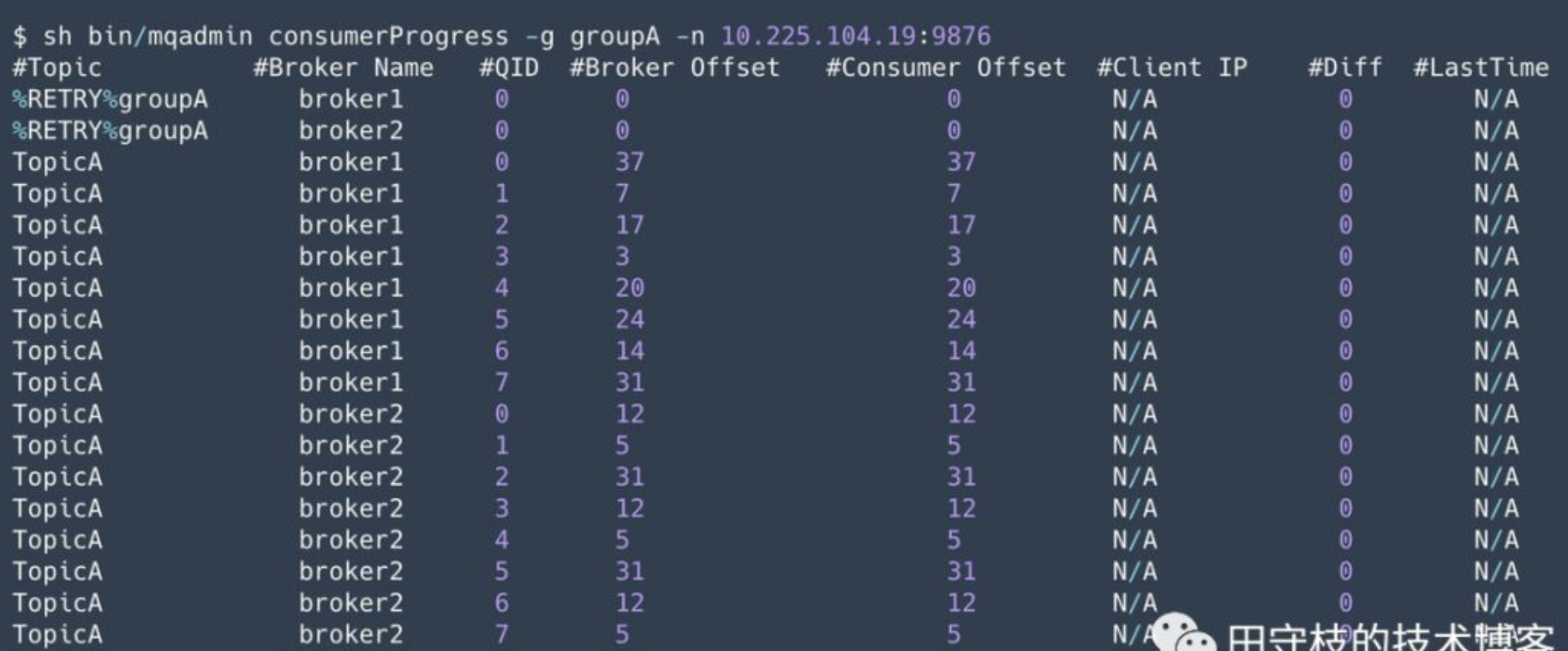
通过 mqadmin 命令行工具的 consumerProgress 子命令,来可以看到 Topic 每个队列的消费进度,如:
SubscriptionGroupManager
订阅组配置管理器,内部针对每个消费者组维护一个 SubscriptionGroupConfig。主要是为了针对消费者组进行一些运维操作,这里不做过多介绍,感兴趣的读者自行查阅源码。
3. Consumer Rebalance 触发时机
前面分析 Broker 在 Rebalance 过程中起的是协调通知的作用,可以帮忙我们从整体对 Rebalance 有个初步的认知。但是 Rebalance 的细节,却是在 Consumer 端完成的。
在本节中,我们将着重讨论单个 consumer 的 Rebalance 流程。
需要说明的是,RocketMQ 的 consumer 分配 pull 和 push 两种模式,二者的工作逻辑并不相同。这里主要以 push 模式的默认实现类 DefaultMQPushConsumer 为例进行讲解。
在前文,我们提到 Broker 会主动通知消费者进行 Rebalance,但是从消费者的角度来看,整个生命过程的各个阶段,都有可能触发 Rebalance,而不仅仅是收到通知后才进行 Rebalance。
具体来说,Consumer 在启动/运行时/停止时,都有可能触发 Rebalance,如下图所示:

- 在启动时,消费者会立即向所有 Broker 发送一次发送心跳( HEART_BEAT )请求,Broker 则会将消费者添加由 ConsumerManager 维护的某个消费者组中。然后这个 Consumer 自己会立即触发一次 Rebalance。
- 在运行时,消费者接收到 Broker 通知会立即触发 Rebalance,同时为了避免通知丢失,会周期性触 发Rebalance;
- 当停止时,消费者向所有 Broker 发送取消注册客户端(UNREGISTER_CLIENT)命令,Broker 将消费者从 ConsumerManager 中移除,并通知其他 Consumer 进行 Rebalance。
下面通过源码分析,分别讲解启动时/运行时/停止时是如何触发 Rebalance 的。
3.1 启动时触发
DefaultMQPushConsumerImpl 的 start 方法显示了一个消费者的启动流程,如下图所示: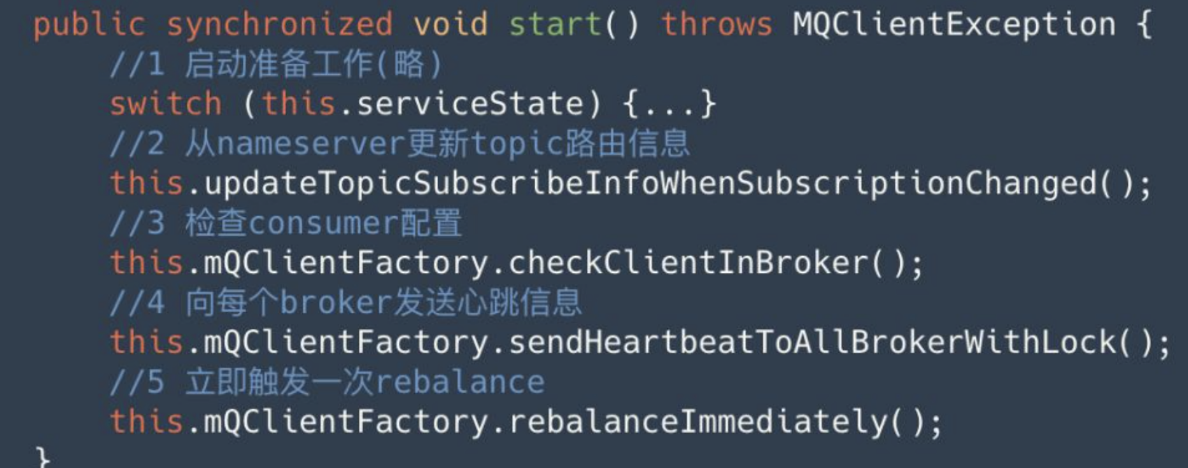
可以看到 Consumer 启动主要分为 5 个步骤,其中步骤 2、4、5 是我们分析的重点。:
步骤 2 :更新订阅的 topic 路由信息
上述代码步骤 2,调用 updateTopicSubscribeInfoWhenSubscriptionChanged() 方法,从 NameServer 更新 topic 路由信息,由于一个消费者可以订阅多个 topic,因此这个 Topic 都需要更新,如下: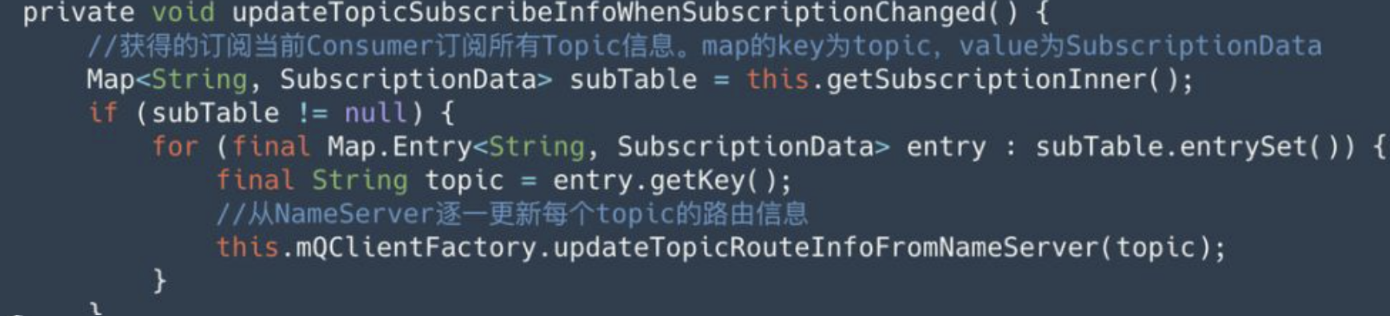
通过这一步,当前 Consumer 就拿到了 Topic 下所有队列信息,具备了 Rebalance 的第一个条件。
步骤4 向 broker 发送心跳信息
在上述启动流程中的第 4 步,调用 sendHeartbeatToAllBrokerWithLock 方法,给每个 Broker 都发送一个心跳请求。
当 Broker 收到心跳请求后,将这个消费者注册到 ConsumerManager 中,前文提到,当 Consumer 数量变化时,Broker 会主动通知其他消费者进行 Rebalance。
而心跳的数据,这些数据是在 MQClientInstance 类的 prepareHeartbeatData 方法来准备的。我们在前文通过 mqadmin 命令行工具的 consumerConnection 自命令查看到的消费者订阅信息,在这里都出现了,如下图红色框所示:
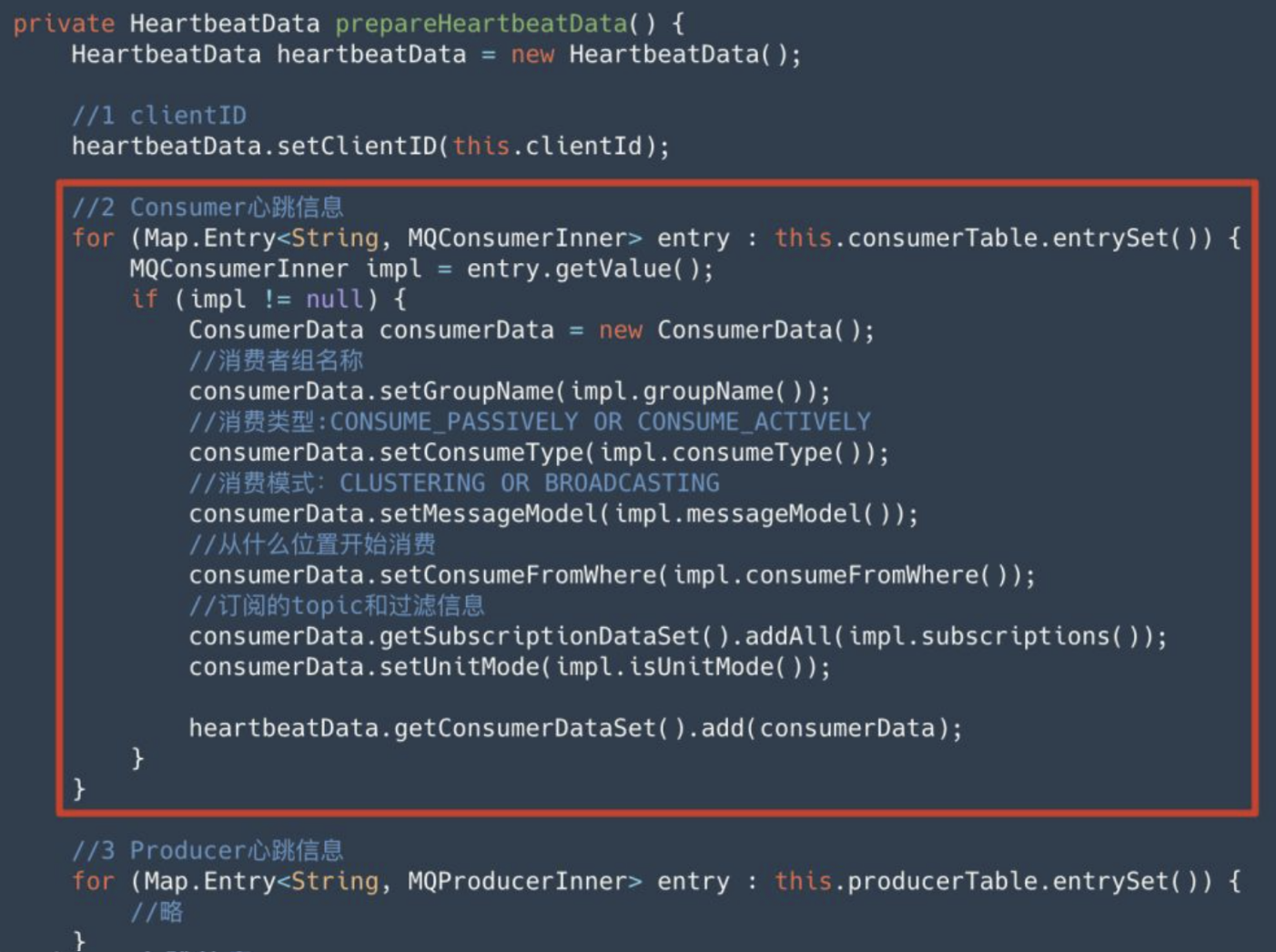
提示:可以看到心跳数据 HeartbeatData 中,既包含 Consumer 信息,也包含 Producer 信息(这里进行了省略)。
步骤5:立即触发一次 Rebalance
this.mQClientFactory.rebalanceImmediately();
这个方法内部实际上,是通过唤醒一个 RebalanceService,来触发 Rebalance:
public void rebalanceImmediately() {this.rebalanceService.wakeup();}
这里我们并不着急分析 RebalanceService 的内部具体实现,因为所有的 Rebalance 触发都是以这个类为入口,我们将在讲解完运行时/停止时的 Rebalance 触发时机后,统一进行说明。
3.2 运行时触发
消费者在运行时,通过两种机制来触发 Rebalance:
- 监听 broker 消费者数量变化通知,触发 rebalance
- 周期性触发 rebalance,避免 Broker 的 Rebalance 通知丢失。
下面分别进行说明:
1. 监听 broker 消费者数量变化通知,触发 rebalance
RocketMQ 支持双向通信机制,在客户端通过 ClientRemotingProcessor 的 processRequest 方法来处理 Broker 发起的通知请求,如下:
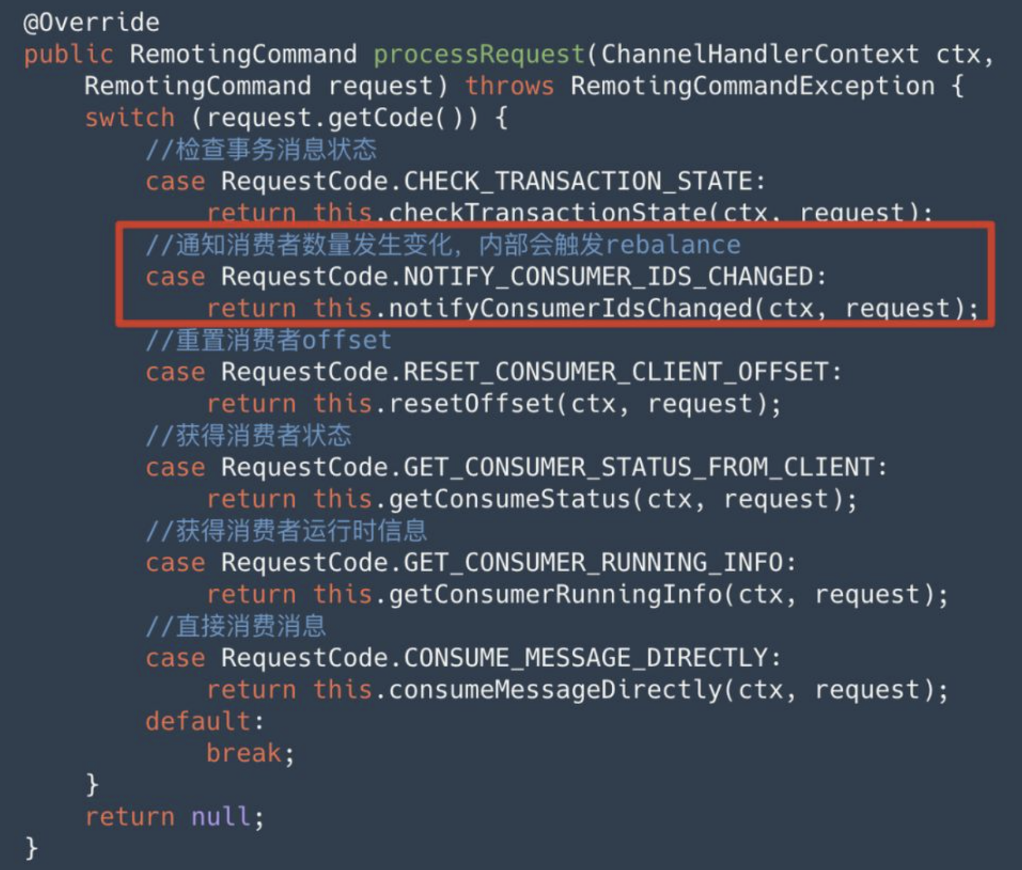
目前,我们关注的是,消费者数量变化时,Broker 给客户端的通知,也就是上图中红色框的内容。在收到通知后,其调用 notifyConsumerIdsChanged 进行处理,这个方法内部会立即触发 Rebalance。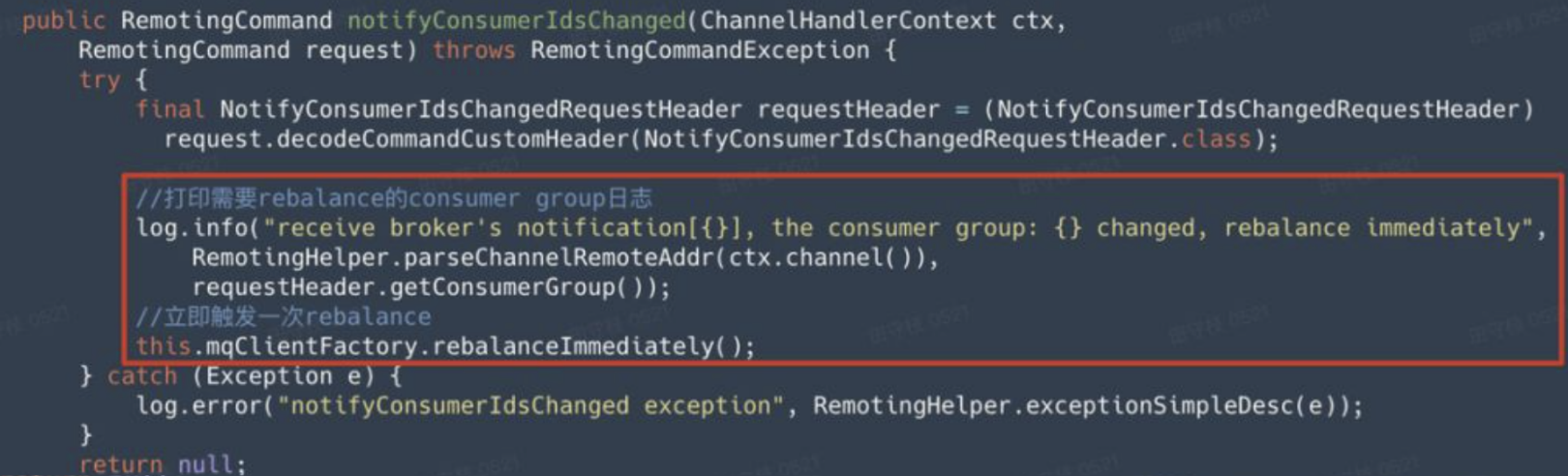
可以看到这里是调用 mqClientFactory 的 rebalanceImmediately 方法触发 Rebalance,而前面讲解消费者启动时是通过 RebalanceService 触发,事实上,后者 RebalanceService 内部也是通过 mqClientFactory 进行触发Rebalance。
2. 周期性触发 rebalance,避免 Rebalance 通知丢失
为了避免 Broker 的 Rebalance 通知丢失问题,客户端还会通过 RebalanceService 定时的触发 Rebalance,默认间隔是20秒,如下图: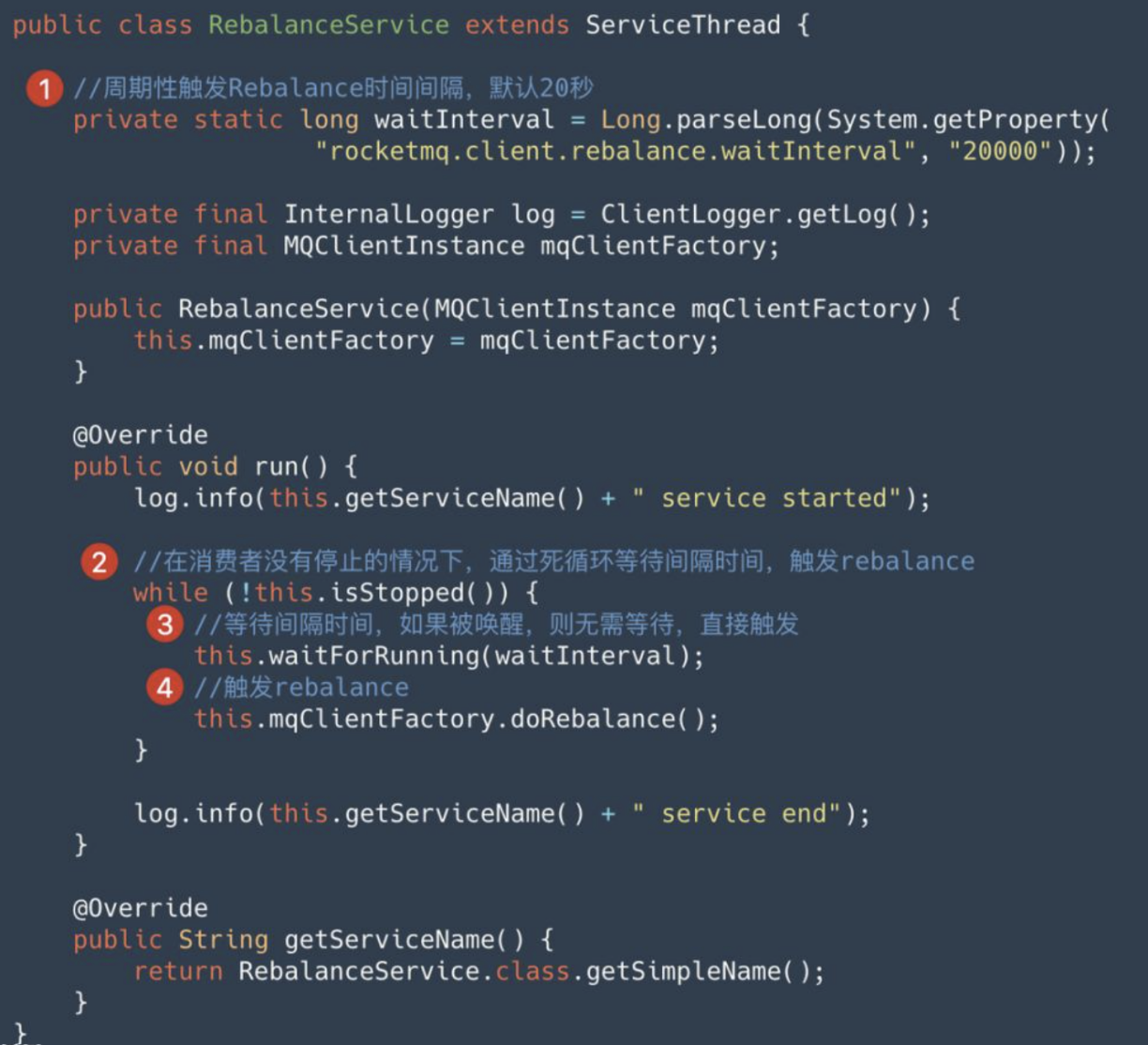
3.3 停止时触发
最后,消费者在正常停止时,需要调用 shutdown 方法,这个方法的工作逻辑如下所示: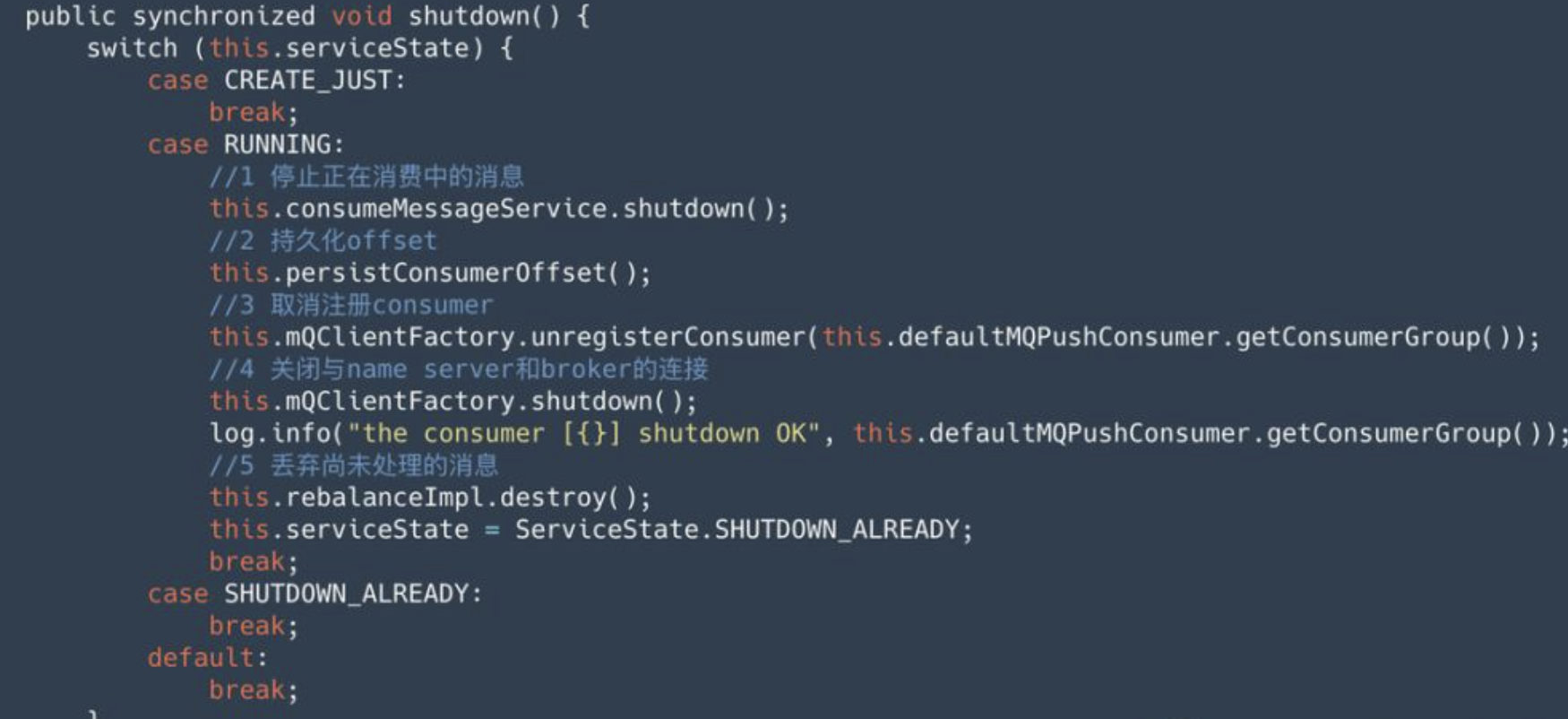
可以看到停止也分为 5 步,我们重点关注第 2、3 步:
在停止时,会首先通过第 2 步持久化 offset,前文提到过默认情况下,offset 是异步提交的,为了避免重复消费,因此在关闭时,必须要对尚未提交的 offset 进行持久化。其实就是发送更新 offset 请求(UPDATE_CONSUMER_OFFSET)给Broker,Broker 对应更新 ConsumerOffsetManager 中的记录。这样当队列分配给其他消费者时,就可以从这个位置继续开始消费。
接着第 3 步调用 unregisterConsumer 方法,向所有 broker 发送 UNREGISTER_CLIENT 命令,取消注册 Consumer。broker 接收到这个命令后,将 consumer 从 ConsumerManager 中移除,然后通知这个消费者下的其他 Consumer 进行 Rebalance。
至此,我们已经讲解完了 Consumer 启动时/运行时/停止时,所有可能的 Rebalance 触发时机,在下一小节,将介绍消费者 Rebalance 具体步骤。
4. Consumer Rebalance 流程
前面花了大量的篇幅,讲解了 Rebalance 元数据维护,Broker 通知机制,以及 Consumer 的 Rebalance 触发时机,目的是让读者有一个更高层面的认知,而不是直接分析单个 Consumer Rebalance 的具体步骤,避免一叶障目不见泰山。
4.1 Rebalance 流程整体介绍
不同的触发机制最终底层都调用了 MQClientInstance 的 doRebalance 方法,而在这个方法的源码中,并没有区分哪个消费者组需要进行 Rebalance,只要任意一个消费者组需要 Rebalance,这台机器上启动的所有其他消费者,也都要进行 Rebalance。相关源码如下所示:MQClientInstance#doRebalance
MQConsumerInner 有 push 模式和 pull 模式两种实现,分别是:
- DefaultMQPushConsumerImpl
- DefaultMQPullConsumerImpl
二者的 Rebalance 逻辑并不相同
对于 push 模式
其会根据消费者指定的消息监听器是有序还是无序进行判定 Rebalance 过程中是否需要对有序消费进行特殊处理。参见:DefaultMQPushConsumerImpl#doRebalance
对于 pull 模式
总是认为是无序的,因为写死了为 false。参见:DefaultMQPullConsumerImpl#doRebalance
我们看到,不管是 push 还是 pull 模式的 Consumer 实现,内部都是调用 RebalanceImpl 的 doRebalance 方法进行触发,将是否有序作为一个参数传入。
在这个方法内部,如果一个消费者订阅了多个 Topic,会迭代每个 Topic 维度逐一触发 Rebalance。相关源码如下所示:RebalanceImpl#doRebalance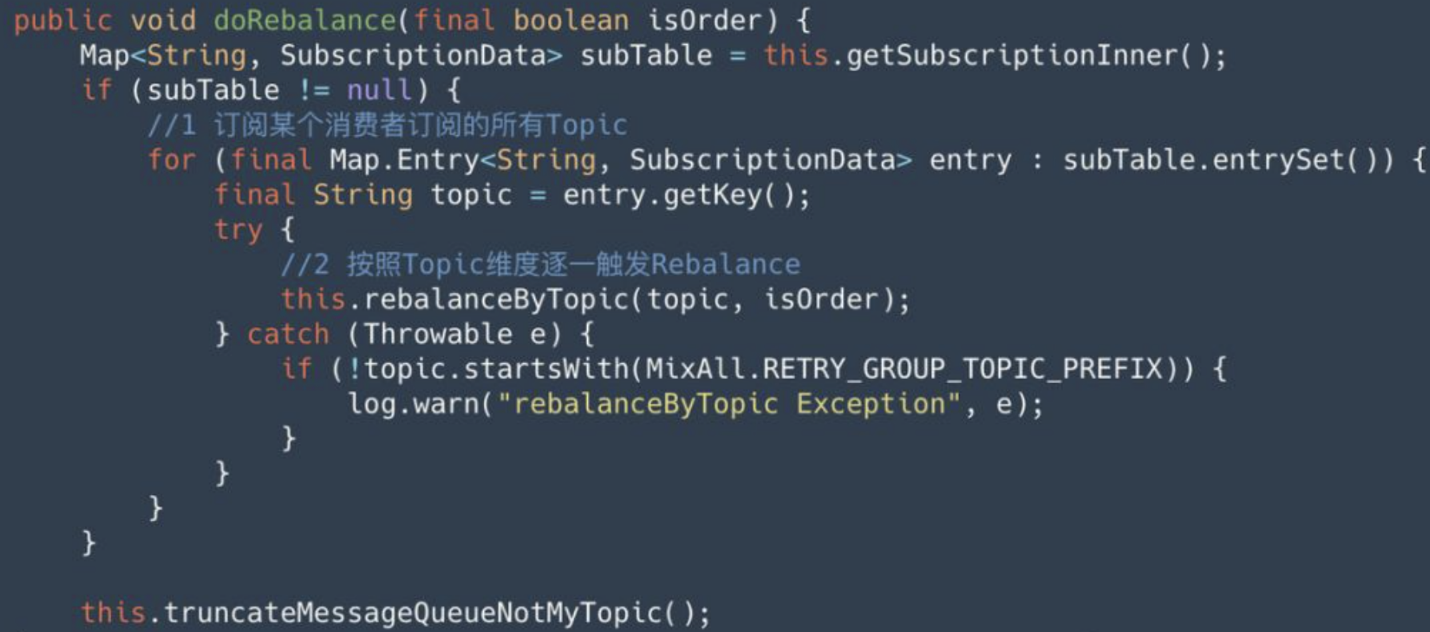
RocketMQ 按照 Topic 维度进行 Rebalance,会导致一个很严重的结果:如果一个消费者组订阅多个 Topic,可能会出现分配不均,部分消费者处于空闲状态。
举例来说:某个消费者组 group_X 下有 4 个消费者实例,分别部署在 192.168.0.[1-4] 四台机器上;订阅了两个主题:TopicX 和 TopicY。如下图:
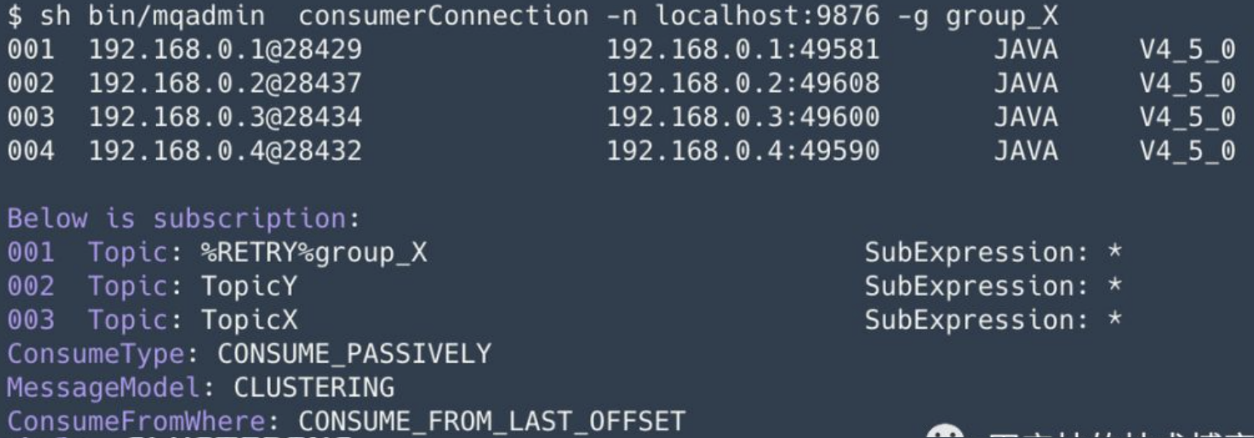
其中:001~004 表示的就是这 4 个消费者的信息,而订阅信息显示了订阅 TopicX 和 TopicY。
假设 TopicX、TopicY 各有 2 个队列,因此总共有 4 个队列;而刚好又有 4 个消费者,我们的期望是每个消费者分配一个队列。然后实际分配情况如下图所示:
通过观察 Client IP 列,我们看到 192.168.0.1、192.168.0.2 各出现 2 两次,也就是分配到了两个队列,另外 2 个IP(192.168.0.3、192.168.0.4)并没有出现,表示没有分配到任何队列。
之所以出现分配不均,就是因为按照 Topic 维度进行 Rebalance,因此这里 TopicX 和 TopicY 会各 Rebalance 一次。且每次 Rebalance 时都对消费者组下的实例进行排序,所以 TopicX 和 TopicY 各自的两个队列,都分配给消费者组中的前两个消费者了。
由于订阅多个 Topic 时可能会出现分配不均,这是在 RocketMQ 中我们为什么不建议同一个消费者组订阅多个 Topic 的重要原因。在这一点上,Kafka 与不 RocketMQ 同,其是将所有 Topic 下的所有队列合并在一起,进行 Rebalance,因此相对会更加平均。
4.2 单个 Topic Rebalance 流程
单个 Topic 的 Rebalance 流程,是在 RebalanceImpl 类的 rebalanceByTopic 方法中进行的,整体上可以分为 3 大步骤:
- 获得 Rebalance 元数据信息
- 进行队列分配
- 分配结果处理
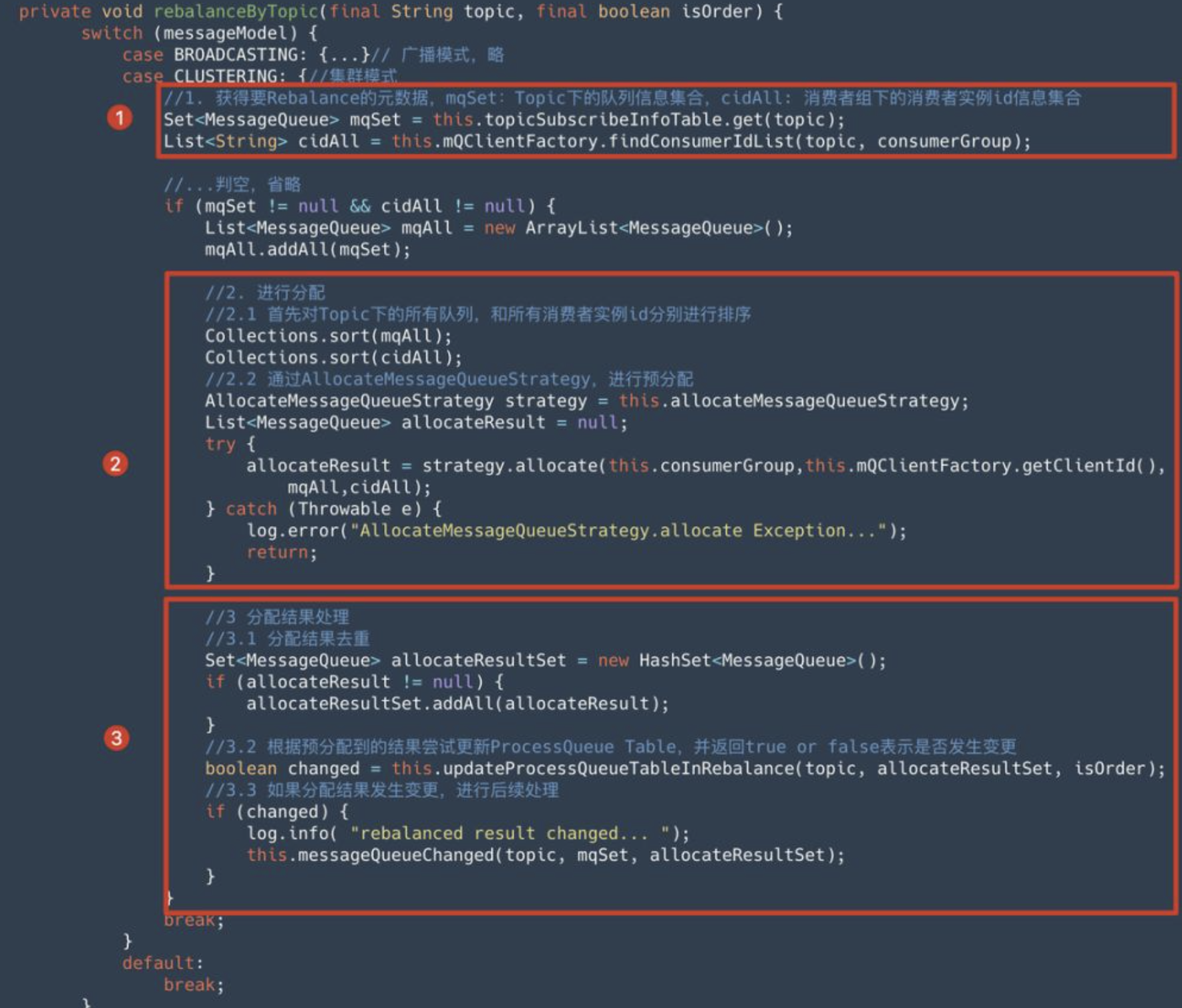
4.2.1 获得 Rebalance 元数据
消费者在 Rebalance 时需要获得:Topic 的队列信息和消费者组实例信息。
- 对于队列信息:
- 会从之前的缓存的 Topic 路由信息中获取;Topic 路由信息会定时的进行更新。
- 对于消费者组实例信息:
- 前面我们提到过 Broker 通过
ConsumerManager维护了所有的消费者信息,findConsumerIdList方法内部会会发送GET_CONSUMER_LIST_BY_GROUP给请求给任意一个 Broker 进行获取。
- 前面我们提到过 Broker 通过
4.2.2 进行队列分配
RocketMQ 的分配策略使用 AllocateMessageQueueStrategy 接口表示,并提供了多种实现:
- AllocateMessageQueueAveragely:平均分配,默认
- AllocateMessageQueueAveragelyByCircle:循环分配
- AllocateMessageQueueConsistentHash:一致性哈希
- AllocateMessageQueueByConfig:根据配置进行分配
- AllocateMessageQueueByMachineRoom:根据机房
- AllocateMachineRoomNearby:就近分配
这里举例来进行说明。假设某个 Topic 有10个队列,消费者组有 3 个实例 c1、c2、c3,使用 AllocateMessageQueueAveragely 分配结果如下图所示: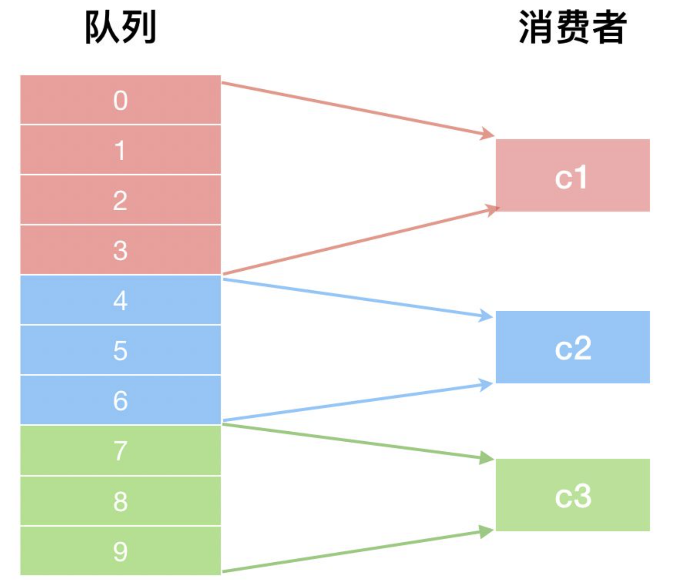
因为这是一个平均分配策略,在分配时,每个消费者 (c1、c2、c3) 平均分配 3 个,此时还多出 1 个,多出来的队列按顺序分配给消费者队列的头部元素,因此 c1 多分配 1 个,最终 c1 分配了 4 个队列。
需要注意的是,每个消费者是自己给自己分配,相当于存在多个大脑。那么如何保证分配结果的一致呢?通过以下两个手段来保证:
- 对 Topic 队列,以及消费者各自进行排序
- 每个消费者需要使用相同的分配策略。
尽管每个消费者是各自给自己分配,但是因为使用的相同的分配策略,定位从队列列表中哪个位置开始给自己分配,给自己分配多少个队列,从而保证最终分配结果的一致。
对于其他分配策略,感兴趣的读者可以自行阅读源码,在实际开发中使用的很少,这里并不介绍。特别的,mqadmin 工具提供了一个 allocateMQ 子命令,通过其我们可以预览某个 Topic 在多个消费者分区是如何分配的,使用方式如下:sh bin/mqadmin allocateMQ -i ip1,ip2,ip3 -t TopicA -n localhost:9876
这个工具可以将模拟分配的结果进行 json 格式展示。
4.2.3 队列分配结果处理
处理队列变更
消费者计算出分配给自己的队列结果后,需要与之前进行比较,判断添加了新的队列,或者移除了之前分配的队列,也可能没有变化。
- 对于新增的队列,需要先计算从哪个位置开始消费,接着从这个位置开始拉取消息进行消费;
- 对于移除的队列,要移除缓存的消息,并停止拉取消息,并持久化 offset。
可参考
updateProcessQueueTableInRebalance()实现。
其他处理
调用 messageQueueChanged 方法进行额外后续处理:
对于 push 模式:
- 主要是进行一些流控参数的更新。
对于 pull 模式:
- 是回调用户自定义的
MessageQueueListener。
版权声明:本文为CSDN博主「tianshouzhi」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/tianshouzhi/article/details/103607572

若有收获,就点个赞吧
0 人点赞
