读写分离——为了应对数据库的并发问题
主从
- 读写分离基本点:
- 一主多从数据库分布
- 主从实时同步
- 主数据库负责写操作,从数据库负责读操作
- 具体实现:
- 代理层
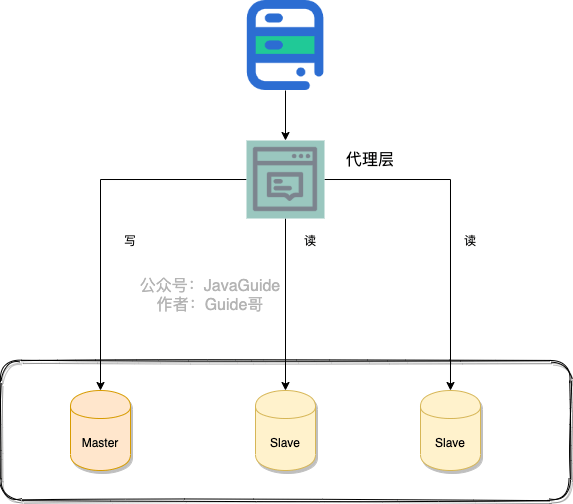
中间件有 MySQL Router(官方)、Atlas(基于 MySQL Proxy)、Maxscale、MyCat。
- 组件方式(常用)
引入第三方组件来帮助我们读写请求,比如sharding-jdbc jar包
- 主从复制原理
MySQL binlog(binary log 即二进制日志文件) 主要记录了 MySQL 数据库中数据的所有变化(数据库执行的所有 DDL 和 DML 语句)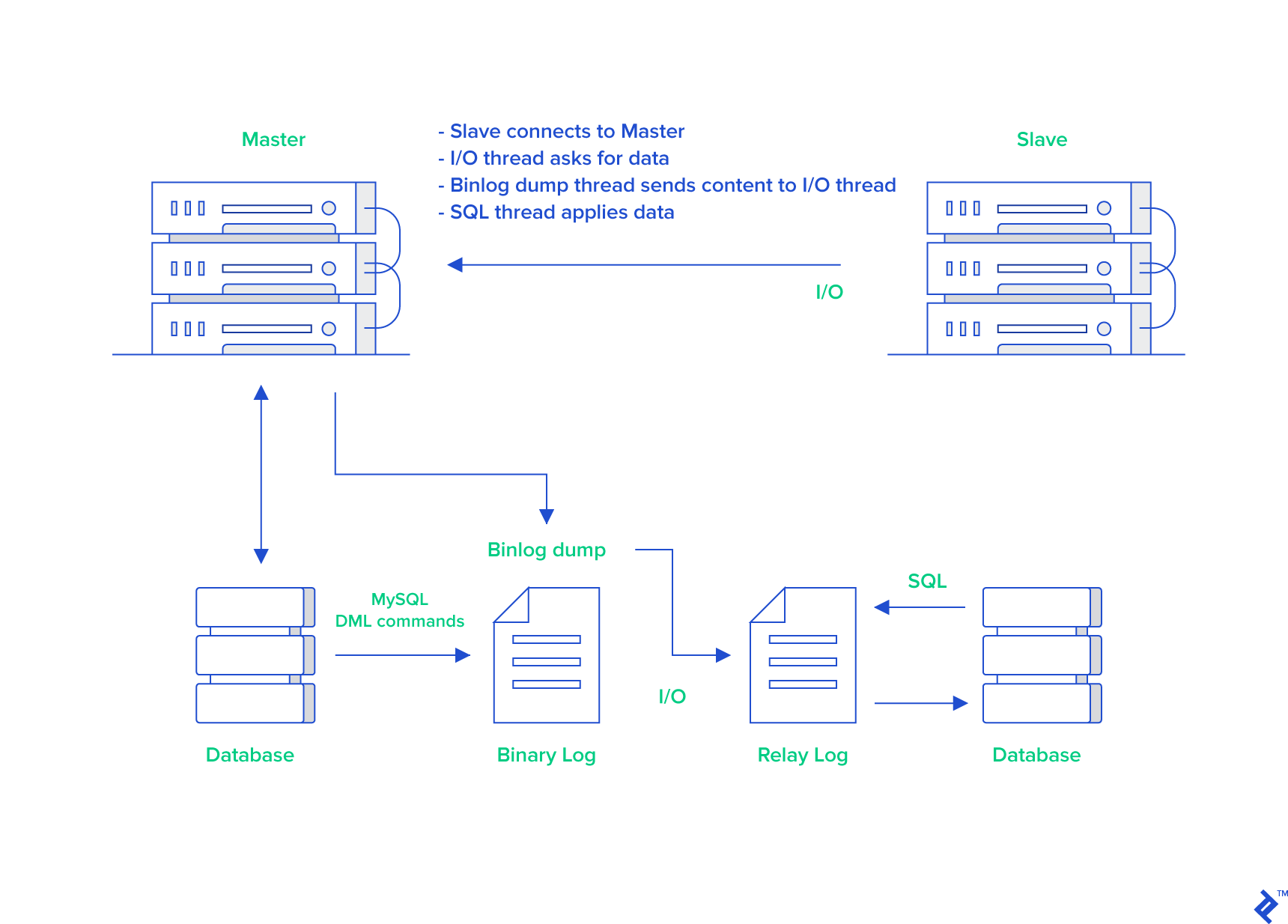
过程:1.对Master数据库都会被记录在bin log中
2.Slave库请求连接主库,并创建IO线程向主库请求更新的binlog
3.主库开binlog dump线程传递binlog,从库的IO线程负责接收,接收后写入在relay log中
4.从库开SQL线程再次执行relay log中的操作
- 阿里开源工具,canal
该工具可以帮助实现 MySQL 和其他数据源比如 Elasticsearch 或者另外一台 MySQL 数据库之间的数据同步。原理就是模拟MySQL主从复制的过程,依赖于binlog。
分库分表——为了分担数据库的存储压力
- 分库:将原本在一个数据库中的数据放到多个数据库中
- 分表:对单表的数据进行水平拆分或者垂直拆分
- 什么时候分?
- 单表数据太大,千万级别以上,读写速度缓慢(分表)
- 数据库中的数据占用空间太大,备份时间长(分库)
- 应用并发量(分库)
- 带来的问题
- join操作:同一个数据库中的表分布在了不同的数据库中。分库以后导致无法使用join,需要手动进行数据封装
- 事务:同一个数据库中的表分布在了不同的数据库中。数据库自带的事务就不管用了
- 分布式id:不同的数据节点要生成全局唯一主键,需要分布式id
- 成本:DBA参与、更多的数据库服务器
- 推荐方案
ShardingSphere 项目(包括 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar)
- 数据迁移:停机迁移、双写方案(借助canal)

若有收获,就点个赞吧
0 人点赞
