借用MaxSquareLoss中的部分代码使用在pytorch-deeplab-xception中
- 基础配置
将MaxSqaureLoss代码中的synthia_list下的train.txt和val.txt放入RAND_CITYSCAPES数据集下
- 在train和mypath中增加synthia

mypath.py增加synthia数据集目录。
train.py下增加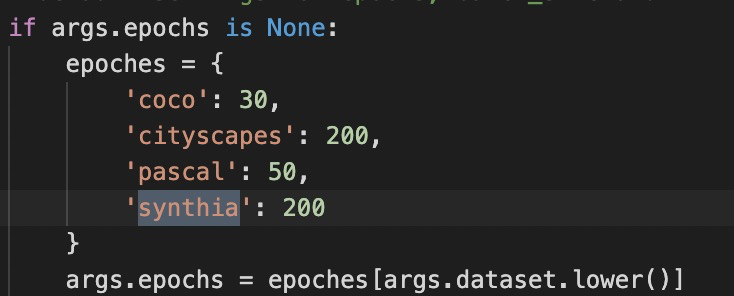
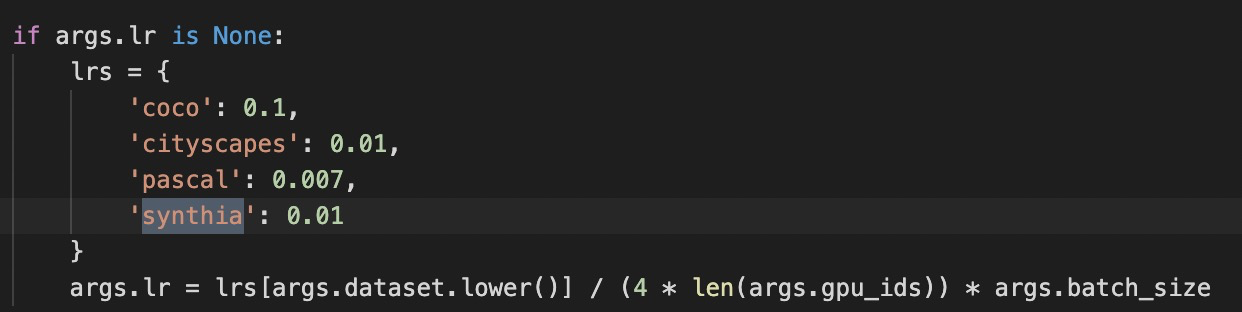

- 相关接入口
在dataloaders.datasets下的init.py文件下的make_data_loader增加如下内容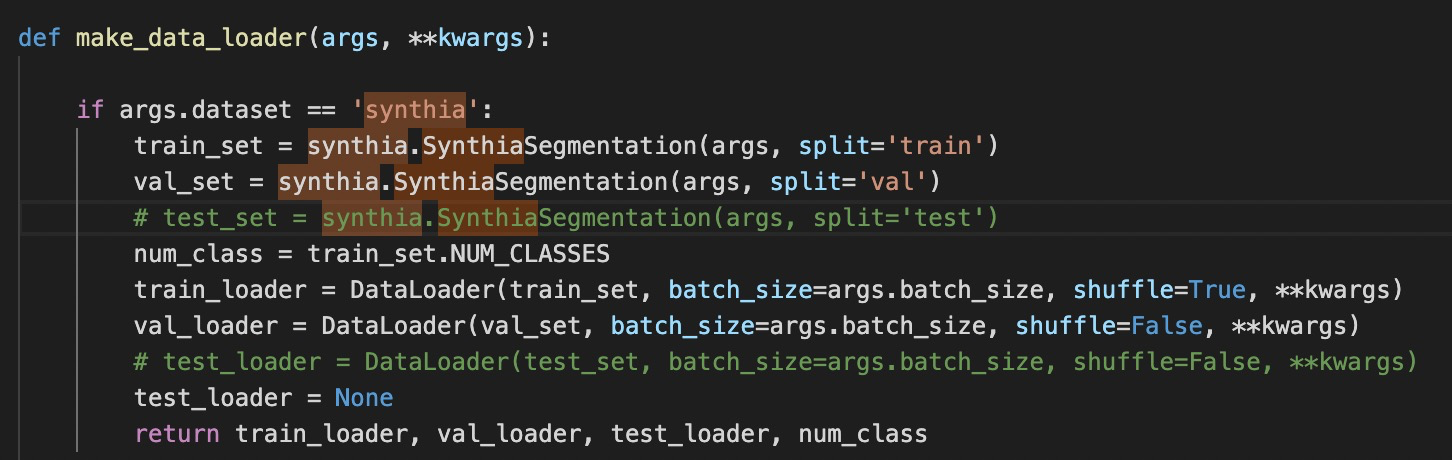
在dataloaders下的utils.py下增加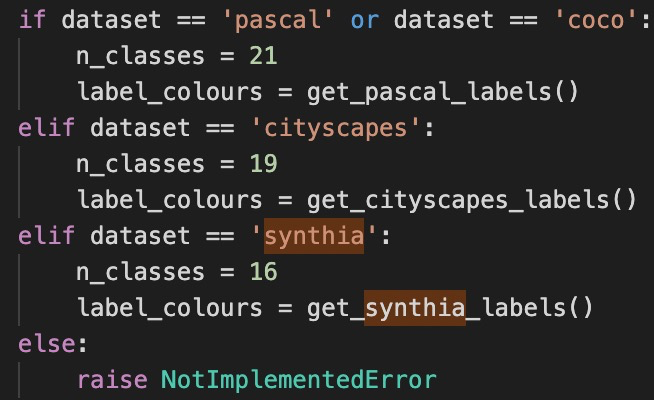
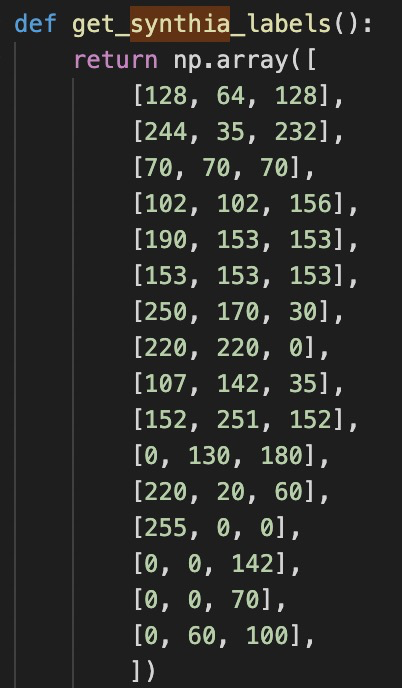 其中get_synthia_labels直接复制get_cityscapes_labels,然后删除最后3个即可。
其中get_synthia_labels直接复制get_cityscapes_labels,然后删除最后3个即可。
//这里cityscapes一共19类(本身cityscapes不止是19,但实验中都是将其映射为19类。https://github.com/mcordts/cityscapesScripts/blob/master/cityscapesscripts/helpers/labels.py 这是cityscapes的一些label信息-)。
//synthia我们采用其与cityscapes的共用的16类。 这是为了之后的验证和训练。在本代码的训练中重要性没有体现。在适配的时候需要。这部分在4中叙述。
- 数据集相关修改
首先将dataloaders.datasets下的cityscapes下的代码复制,新建synthia.py文件。拷贝。
下面开始修改synthia的数据读入。主要采用了MaxSquareLoss的代码库的内容。修改的基本内容都在我的注释中。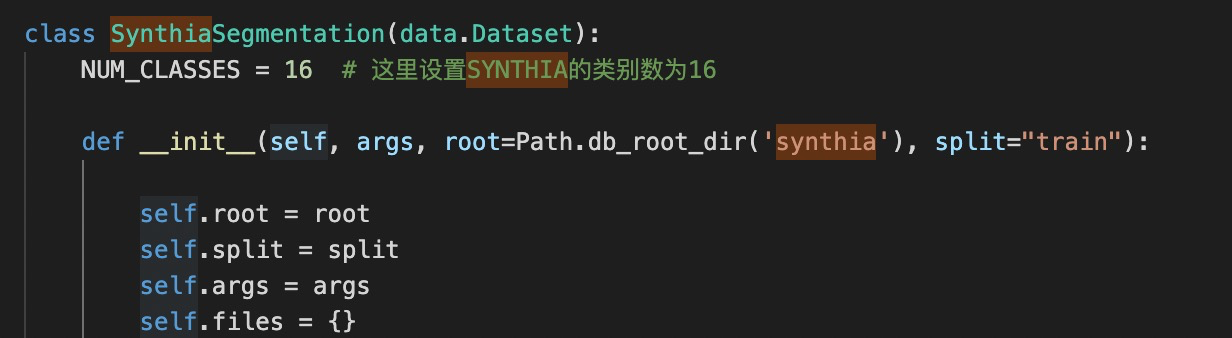
设置NUM_CLASS为16类。
 图像路径和GT路径。
图像路径和GT路径。
///这个synthia子集一共9400张图片,9000张训练,400张验证。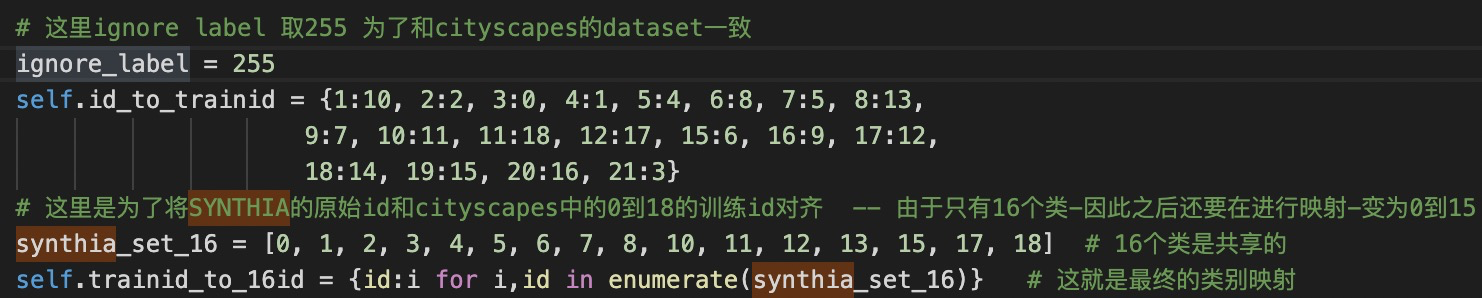
映射相关代码。
id_to_trainid,进行的映射就是将SYNTHIA的id,映射到cityscapes的id。意思是,两个数据集中,相同物体的id本身是不同的。//这个是之后在域适配中使用。
主要要做的后面的,将trainid 映射为16id。其中synthia_set_16表示和cityscapes共用的16个类的trainid。
然后将其映射到0-16.
///如果没有cityscapes的要求,可以直接进行映射。而不需要第一步
//具体的内容查看RAND_CITYSCAPES的README文件。
注意:这里为了和deeplabv3+源代码相同,ignore_label设置为255. ///在MaxLoss代码中-ignore_label为-1!!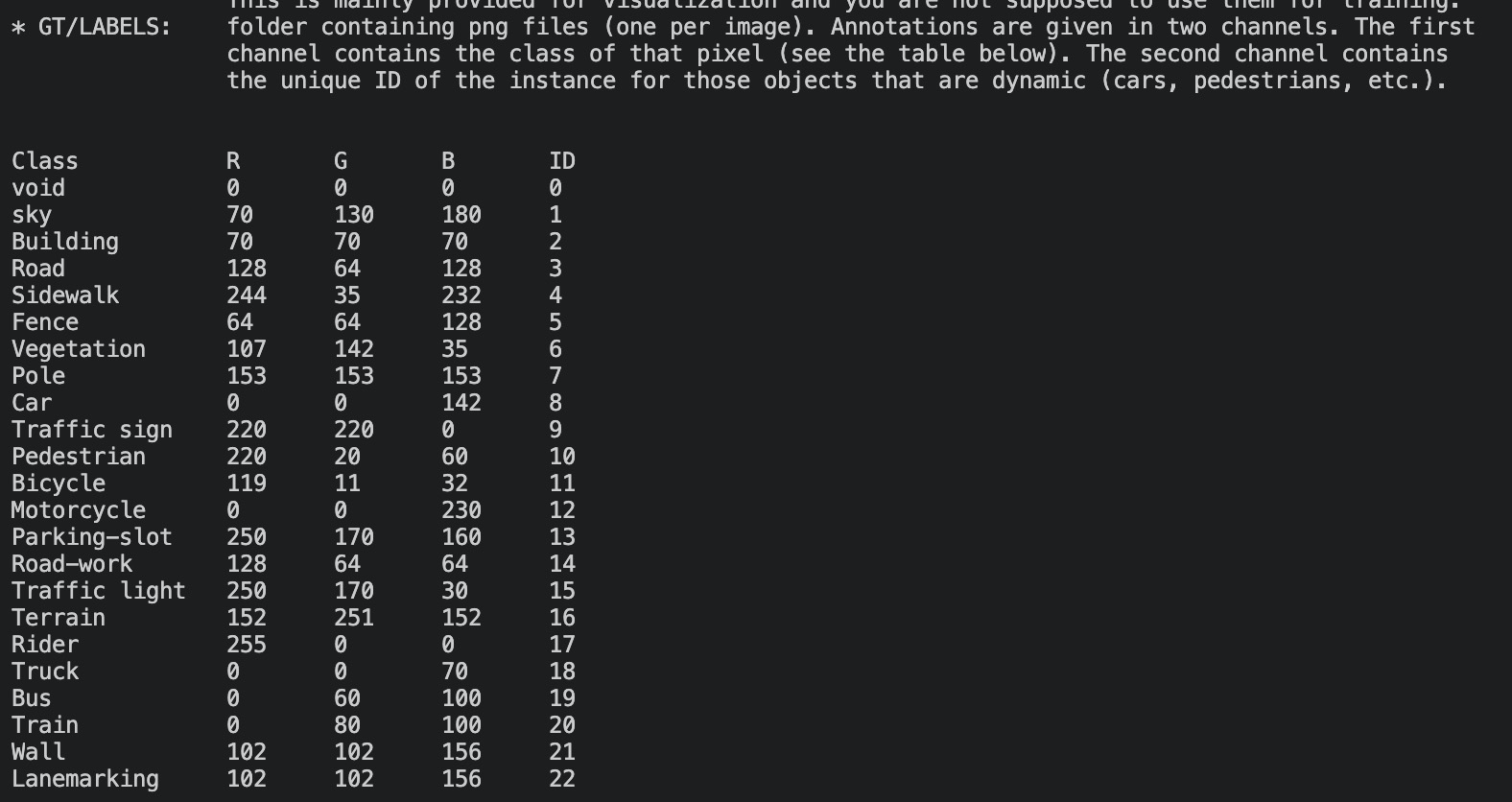
后面便是getitem相关内容。 读图片
读图片
读groundtruth。注意gt_image的读入方法,使用imageio.imread,然后读取的是第0个channel。
////这个是他本身数据格式的问题!!最好采用这个方法-其他的会出错。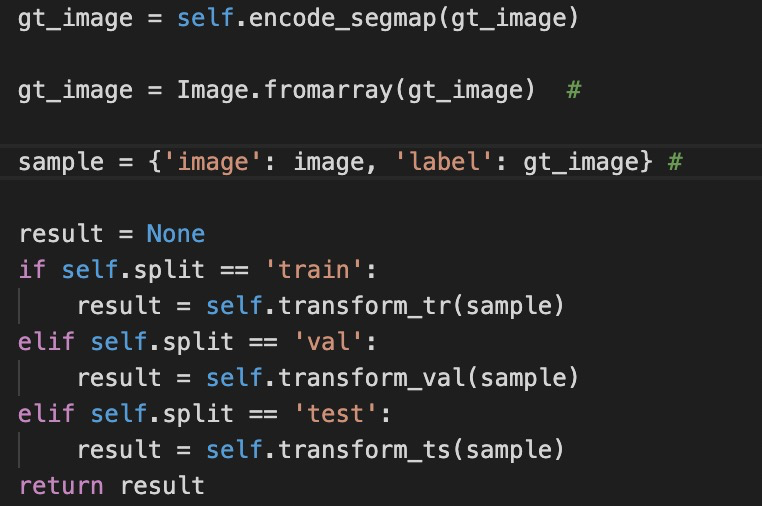 剩余部分内容统一于deeplabv3+源代码。
剩余部分内容统一于deeplabv3+源代码。
encode_segmap—即将gt进行映射,变为0-15,然后无关的设置为255.
//注意:这个ignore就是igore,不是void。分割的时候不会考虑他,也不会分割出他。—大概是这样?
这里使用了MaxLoss代码库中的id2trainId。注意修改ignore_label为255!!!如果有-1就不对了-因为网络输出肯定是整数的。 ///不过这部分为也没仔细看。
完成了mask的编码后。最后做的事情还是原来的。
最后:要想网络结果好,还有一些cropsize,等等之类的参数要调整-不容易。

若有收获,就点个赞吧
0 人点赞
