相关地址
- Prometheus github 地址:https://github.com/coreos/kube-prometheus
组件说明
1.MetricServer:是kubernetes集群资源使用情况的聚合器,收集数据给kubernetes集群内使用,如kubectl,hpa,scheduler等。
2.PrometheusOperator:是一个系统监测和警报工具箱,用来存储监控数据。
3.NodeExporter:用于各node的关键度量指标状态数据。
4.KubeStateMetrics:收集kubernetes集群内资源对象数据,制定告警规则。
5.Prometheus:采用pull方式收集apiserver,scheduler,controller-manager,kubelet组件数据,通过http协议传输。
6.Grafana:是可视化数据统计和监控平台。
构建记录
$ git clone https://github.com/coreos/kube-prometheus.git$ cd kube-prometheus/manifests
修改 grafana-service.yaml 文件
默认使用的访问方式是 ClusterIP ,修改为 NodePode 方式访问
apiVersion: v1kind: Servicemetadata:name: grafananamespace: monitoringspec:type: NodePort #添加内容ports:- name: httpport: 3000targetPort: httpnodePort: 30100 #添加内容selector:app: grafana
修改 prometheus-service.yaml
apiVersion: v1kind: Servicemetadata:labels:prometheus: k8sname: prometheus-k8snamespace: monitoringspec:type: NodePort #添加内容ports:- name: webport: 9090targetPort: webnodePort: 30200 #添加内容selector:app: prometheusprometheus: k8s
修改 alertmanager-service.yaml
apiVersion: v1kind: Servicemetadata:labels:alertmanager: mainname: alertmanager-mainnamespace: monitoringspec:type: NodePort #添加内容ports:- name: webport: 9093targetPort: webnodePort: 30300 #添加内容selector:alertmanager: mainapp: alertmanager
替换镜像地址
quay.io -> quay.azk8s.cn
$ sed -i "s/quay.io/quay.azk8s.cn/g" `grep quay.io -rl ./kube-prometheus/manifests/`
初始化
$ kubectl apply -f manifests/setup/namespace/monitoring createdcustomresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com createdcustomresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com createdcustomresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com createdcustomresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com createdcustomresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com createdclusterrole.rbac.authorization.k8s.io/prometheus-operator createdclusterrolebinding.rbac.authorization.k8s.io/prometheus-operator createddeployment.apps/prometheus-operator createdservice/prometheus-operator createdserviceaccount/prometheus-operator created$ until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; doneNo resources found.$ kubectl apply -f manifests/alertmanager.monitoring.coreos.com/main createdsecret/alertmanager-main createdservice/alertmanager-main created...servicemonitor.monitoring.coreos.com/kube-controller-manager createdservicemonitor.monitoring.coreos.com/kube-scheduler createdservicemonitor.monitoring.coreos.com/kubelet created$ until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; doneNAMESPACE NAME AGEmonitoring alertmanager 47smonitoring coredns 45smonitoring grafana 46smonitoring kube-apiserver 45smonitoring kube-controller-manager 45smonitoring kube-scheduler 45smonitoring kube-state-metrics 46smonitoring kubelet 45smonitoring node-exporter 46smonitoring prometheus 45smonitoring prometheus-operator 45s
pull镜像比较慢!!! 经过漫长的等待,终于启动成功了!!!
查看 pod 状态
**
$ kubectl get pod -n monitoringNAME READY STATUS RESTARTS AGEalertmanager-main-0 2/2 Running 0 10malertmanager-main-1 2/2 Running 0 10malertmanager-main-2 2/2 Running 0 10mgrafana-77978cbbdc-577hl 1/1 Running 0 10mkube-state-metrics-85957fb76d-whzt6 3/3 Running 0 10mnode-exporter-l878g 2/2 Running 0 10mnode-exporter-r4knd 2/2 Running 0 10mnode-exporter-wq5nd 2/2 Running 0 10mprometheus-adapter-859b94658d-b82jr 1/1 Running 0 10mprometheus-k8s-0 3/3 Running 1 10mprometheus-k8s-1 3/3 Running 0 10mprometheus-operator-5748cc95dd-g8fxl 1/1 Running 0 14m
安装成功后,支持 top 命令查看资源状态
$ kubectl top nodeNAME CPU(cores) CPU% MEMORY(bytes) MEMORY%k8s-master01 1900m 47% 1548Mi 19%k8s-node01 1885m 47% 1952Mi 24%k8s-node02 2016m 50% 2328Mi 29%$ kubectl top podNAME CPU(cores) MEMORY(bytes)kafka-0 7m 277Mikafka-1 8m 468Mikafka-2 7m 280Mizookeeper-0 2m 162Mizookeeper-1 2m 175Mizookeeper-2 3m 225Mi
访问 Prometheus
访问
prometheus 对应的 NodePort 端口为 30200 ,访问:http://MasterIP:30200/
查看 Targets 连接状态
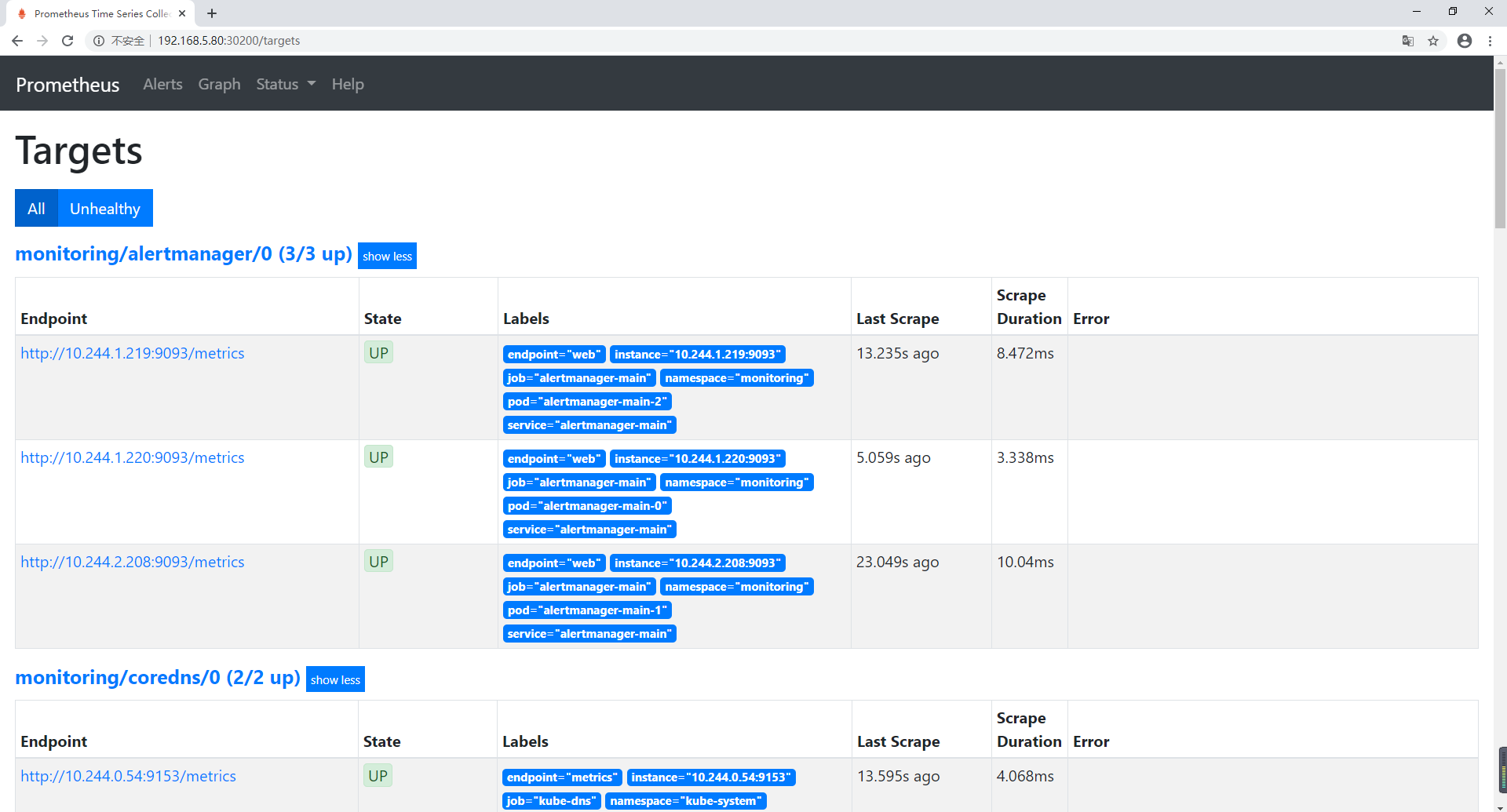
访问地址:http://MasterIP:30200/targets 可以看到 prometheus 已经成功连接上 k8s 的apiserver
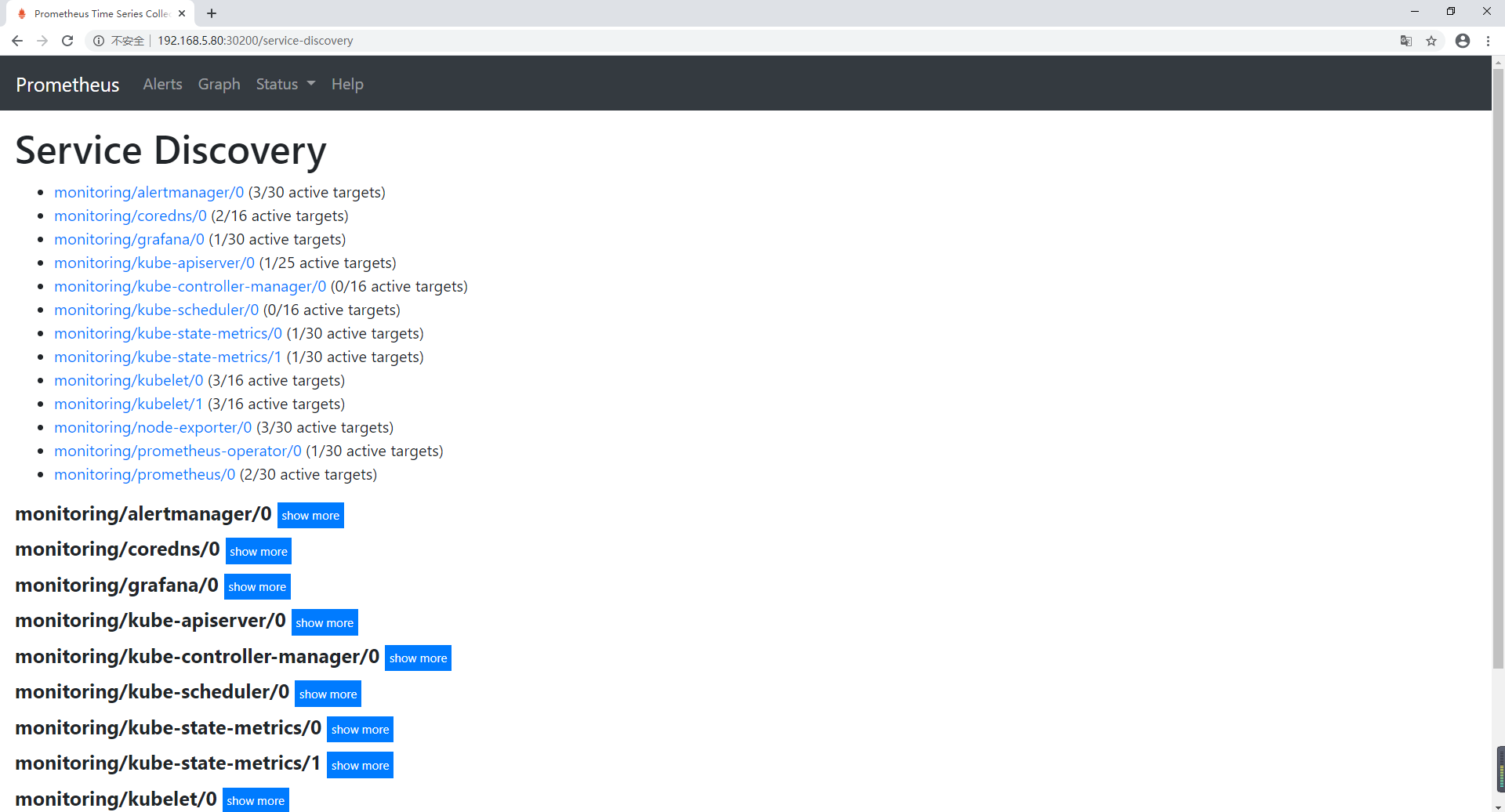
查看 Service Discovery
查看自己的指标
查询解析器
输入查询语句:
sum by (pod_name)( rate(container_cpu_usage_seconds_total{image!="", pod_name!=""}[1m] ) )
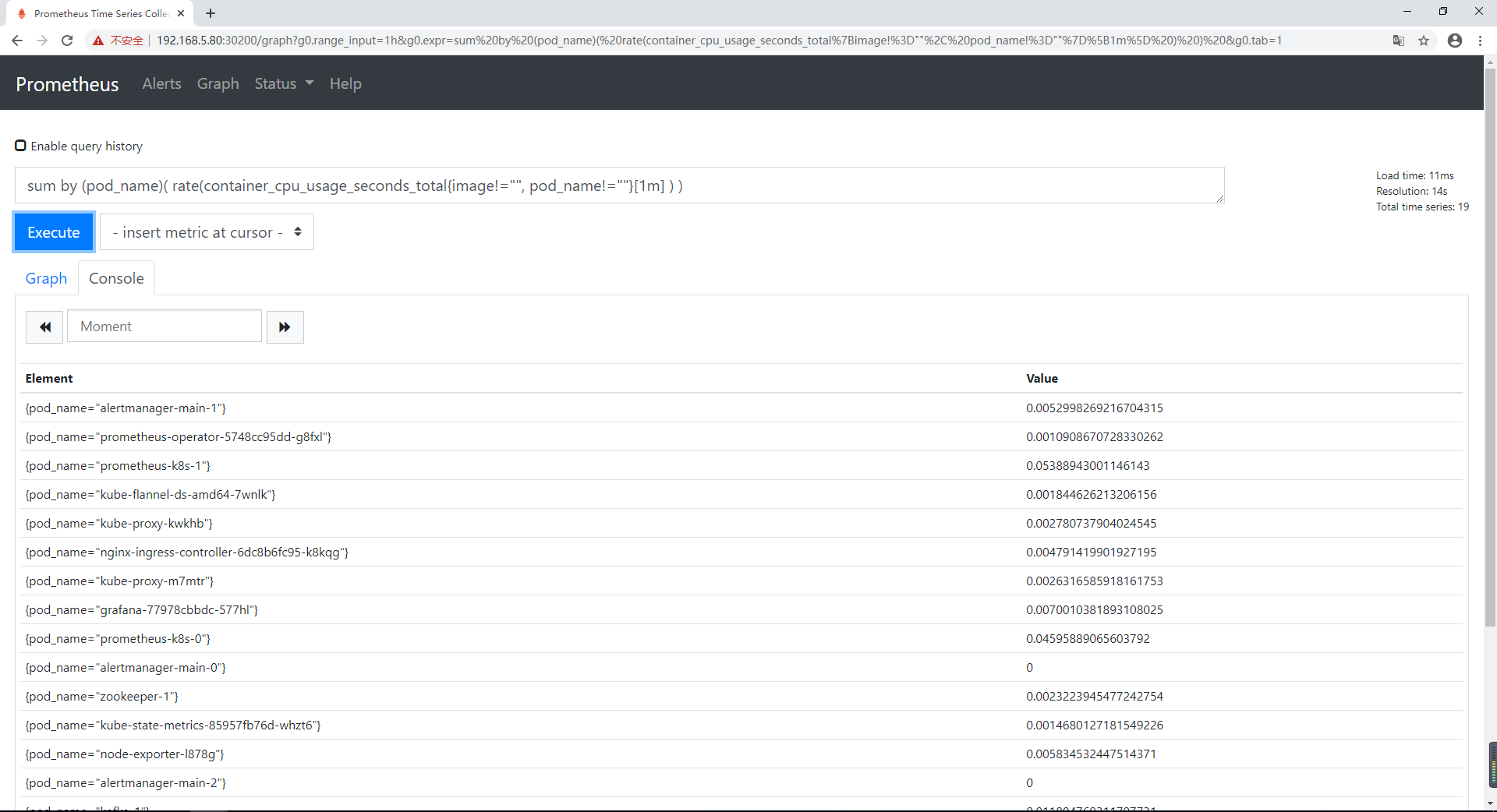
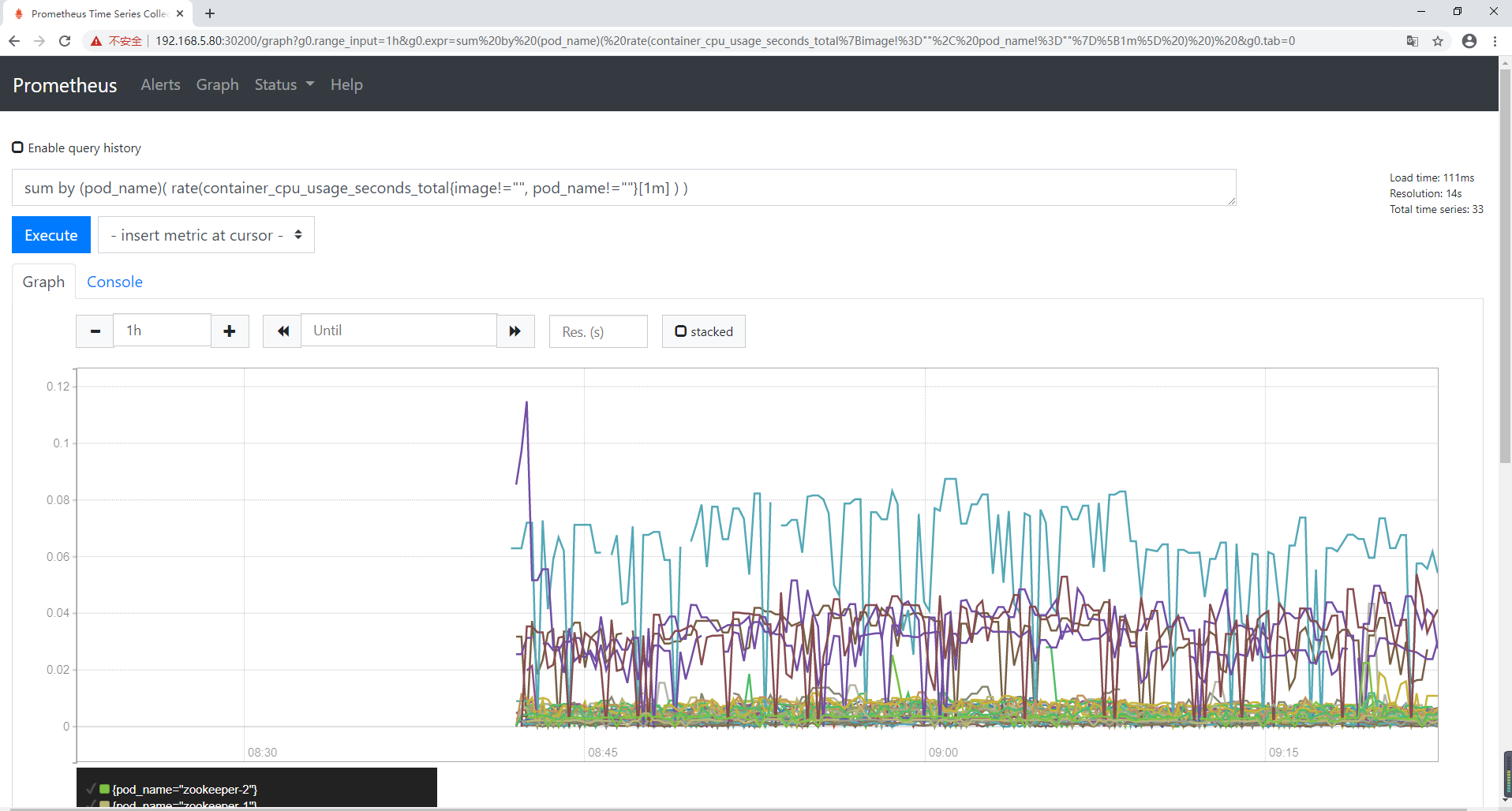
上述的查询有出现数据,说明 node-exporter 往 prometheus 中写入数据正常,接下来我们就可以部署 grafana 组件,实现更友好的 webui 展示数据了
访问 Grafana
查看 grafana 服务暴露的端口号
$ kubectl get service -n monitoring | grep grafanagrafana NodePort 10.106.235.215 <none> 3000:30100/TCP 53m
访问
访问地址:http://MasterIP:30100 默认账号 用户名:admin 密 码:admin
修改密码并登陆
添加数据源
添加数据源 grafana 默认已经添加了 Prometheus 数据源,grafana 支持多种时序数据源,每种数据源都有各自的查询编辑器
配置数据源,使用默认填写的信息进行 Test
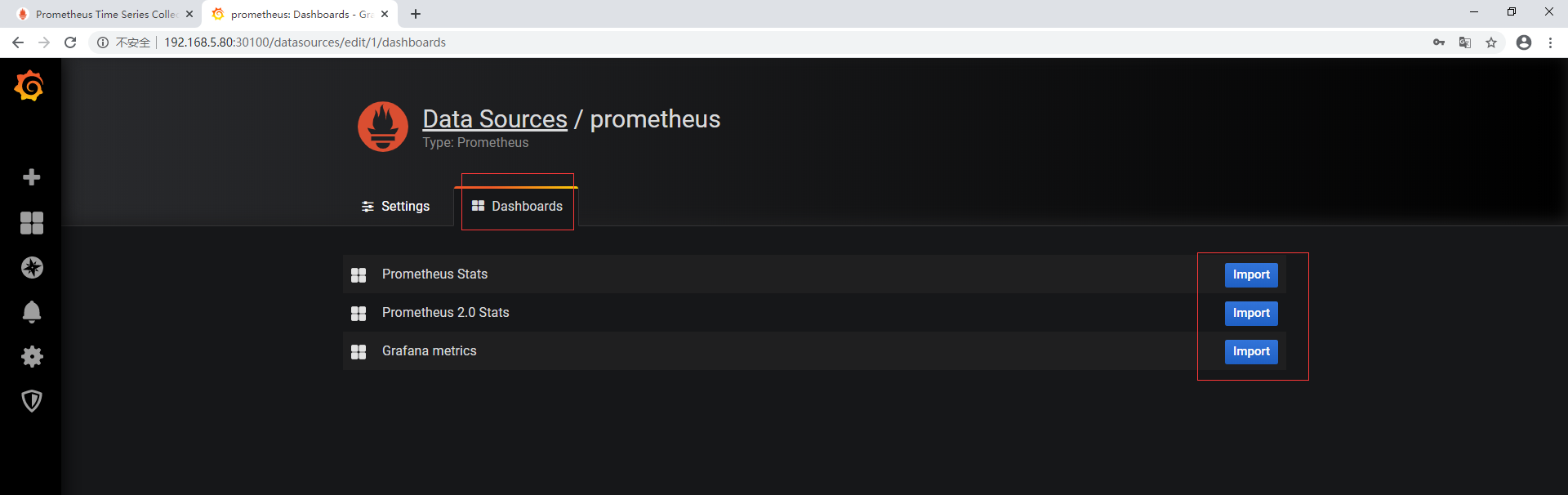
从 Dashboard 中导入模板
查看监控面板
Horizontal Pod Autoscaling
Horizontal Pod Autoscaling 可以根据 CPU 利用率自动伸缩一个 Replication Controller、Deployment 或者Replica Set 中的 Pod 数量
$ kubectl run php-apache --image=gcr.io/google_containers/hpa-example \--requests=cpu=200m --expose --port=80
创建 HPA 控制器 - 相关算法的详情请参阅 这篇文档
$ kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
增加负载,查看负载节点数目
$ kubectl run -i --tty load-generator --image=busybox /bin/sh$ while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done
资源限制 - Pod
Kubernetes 对资源的限制实际上是通过 cgroup 来控制的,cgroup 是容器的一组用来控制内核如何运行进程的相关属性集合。针对内存、CPU 和各种设备都有对应的 cgroup
默认情况下,Pod 运行没有 CPU 和内存的限额。 这意味着系统中的任何 Pod 将能够像执行该 Pod 所在的节点一样,消耗足够多的 CPU 和内存 。一般会针对某些应用的 pod 资源进行资源限制,这个资源限制是通过 resources 的 requests 和 limits 来实现
spec:containers:- image: xxxximagePullPolicy: Alwaysname: authports:- containerPort: 8080protocol: TCPresources:limits:cpu: "4"memory: 2Girequests:cpu: 250mmemory: 250Mi
requests 要分分配的资源,limits 为最高请求的资源值。可以简单理解为初始值和最大值
资源限制 - 名称空间
Ⅰ、计算资源配额
apiVersion: v1kind: ResourceQuotametadata:name: compute-resourcesnamespace: spark-clusterspec:hard:pods: "20"requests.cpu: "20"requests.memory: 100Gilimits.cpu: "40"limits.memory: 200Gi
Ⅱ、配置对象数量配额限制
apiVersion: v1kind: ResourceQuotametadata:name: object-countsnamespace: spark-clusterspec:hard:configmaps: "10"persistentvolumeclaims: "4"replicationcontrollers: "20"secrets: "10"services: "10"services.loadbalancers: "2"
Ⅲ、配置 CPU 和 内存 LimitRange
apiVersion: v1kind: LimitRangemetadata:name: mem-limit-rangespec:limits:- default:memory: 50Gicpu: 5defaultRequest:memory: 1Gicpu: 1type: Container
- default 即 limit 的值
- defaultRequest 即 request 的值

若有收获,就点个赞吧
0 人点赞
