今日内容:
- 1- Spark的基本内容 (了解 其中关于特点需要记录)
- 2- Spark的环境搭建(参考部署文档, 一步步配置成功即可)
- 3- 基于pycharm完成PySpark的入门案例(掌握— 理解每一个API有什么作用)
1. Spark的基本内容
1.1. Spark的基本介绍
- MapReduce: 分布式计算引擎
分布式计算引擎, 主要用于对大规模的数据进行统计分析的操作, 主要用于批处理(离线处理)MR有什么弊端?1- 执行效率比较低(慢): 整个内部运转过程不断进行 磁盘和内存的交互, 产生大量IO , 从而影响效率2- 对于迭代计算支持不够好, 效率比较低:迭代计算: 当计算操作, 必须多个阶段, 而且每个阶段之间存在依赖关系, 只有当上一个阶段执行完成后, 下一个阶段继续3- MR的代码相对来说比较底层, 开发难度系数较高
正因为MR存在这样的一些弊端, 对于市场而言, 希望能够出现一款效率更高, 对迭代计算支持更加良好, 同时更利于上手一个大规模分布式计算的引擎, 而Spark其实就是在这样的背景下产生了Spark是一款大规模分布式的计算引擎, 主要来源于 加州大学伯克利分校一帮博士导师产生一篇论文 来产出的一款基于内存计算的分布式引擎, 整个Spark核心: RDD(弹性的分布式数据集)Spark是基于scala(基于Java)语言编写的RDD: 弹性分布式数据集, 目前可以理解为就是一个庞大的容器, 整个计算方案计算规则都是在这个RDD中定义处理Spark目前贡献给Apache, 称为Apache旗下顶级开源项目: [https://spark.apache.org/4](https://spark.apache.org/4)
为什么说Spark执行效率比较高呢?
1- Spark提供了全新数据结构: RDD 让程序员从原来的数据操作者变更规则的定义者, 整个内部实施全部spark程序基于规则自动化完成, 整个计算全部都是在RDD中运行的, 迭代计算会更加方便 还可以基于内存进行计算2- Spark基于线程运行的, 而MR是基于进程运行的, 线程的启动和销毁要高于进程的启动和销毁

1.2. Spark的发展史
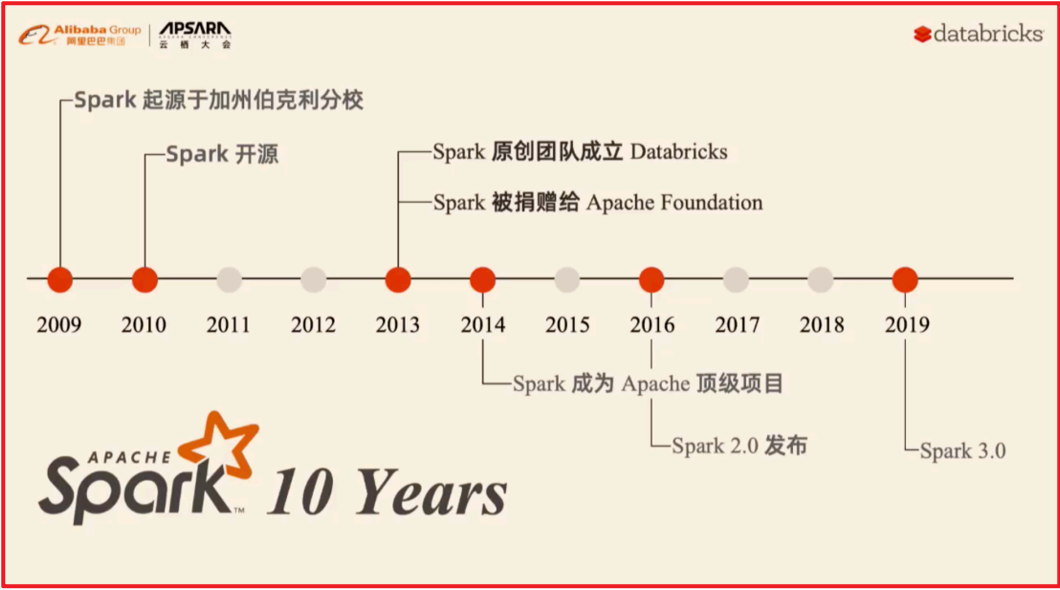

pyspark: 本质上就是一个python的库, 使用python语言操作spark, 必须要下载pyspark
1.3. Spark的特点
- 1- 速度快
原因一: Spark基于RDD计算模型进行处理, 整个计算操作可以基于内存来计算, 也可以基于磁盘来计算, 而且可以更好更方便的进行迭代计算, 整个迭代过程汇总, 中间的结果是可以保存在内存中, 内存不足可以保存到磁盘原因二: Spark是基于线程运行的, 线程的启动和销毁要高于进程的启动和销毁, 而MR是基于进程的
- 2- 易用性
原因一: Spark提供多种语言的操作API, 操作Spark不仅仅可以使用python, 也可以使用 scala SQL java R....原因二: Spark提供的API更加的高阶, 意味很多功能方法全部都定义好了, 比如说转换, 遍历, 排序 ... 而且不同语言的操作API基本都是一致的,大大降低了程序员学习的成本
- 3- 通用型
spark提供多组组件,从而应对未来不同的场景SparkCore: Spark核心, 学习Spark基础, 学习主要点就是RDD其中包含各种操作语言的客户端,以及RDD维护, 对资源的处理的操作API全部都是在CORE中Spark SQL: 最重要的, 必须学会Spark可以使用SQL方式操作Spark, Spark sql组件, 用于支持这种方案, 需要将SQL翻译为RDD来运行Spark Steaming: spark的流式处理 -- 目前不在涉及, 所有实时部分全部集中在Flink中完成Spark可以支持进行流式计算,也就是实时计算structured Steaming: 结构化的流式处理Spark MLlib: Spark的机器学习库 --- 针对一些特定行业人群主要是用于 进行机器学习 算法相关的行业使用的库, 比如说 回归 聚类 ....Spark graphX: Spark的图计算库 --- 针对一些特定行业人群主要是用于进行图计算, 比如说: 地图中行程规划
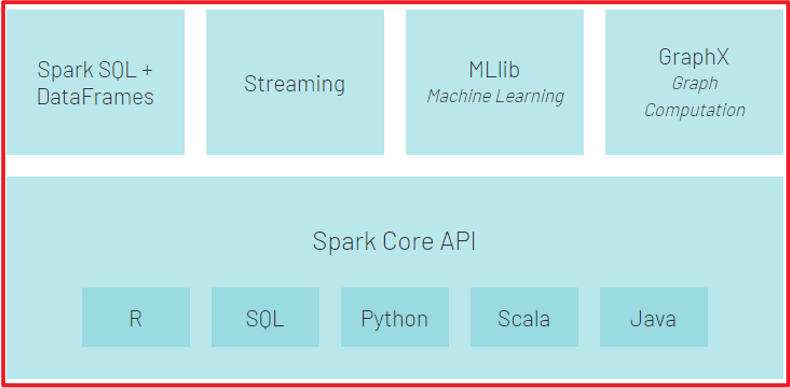
- 4- 随处运行
原因一: Spark的计算程序可以运行在不同的资源调度平台上, 比如 local yarn spark集群 还支持一些云上调度环境(mesos...)原因二: Spark可以和大数据生态圈中各种软件进行集成, 这样可以更加方便的对接使用
2. Spark的环境安装
2.0 从教育项目环境恢复到基础课环境
目标网络信息:
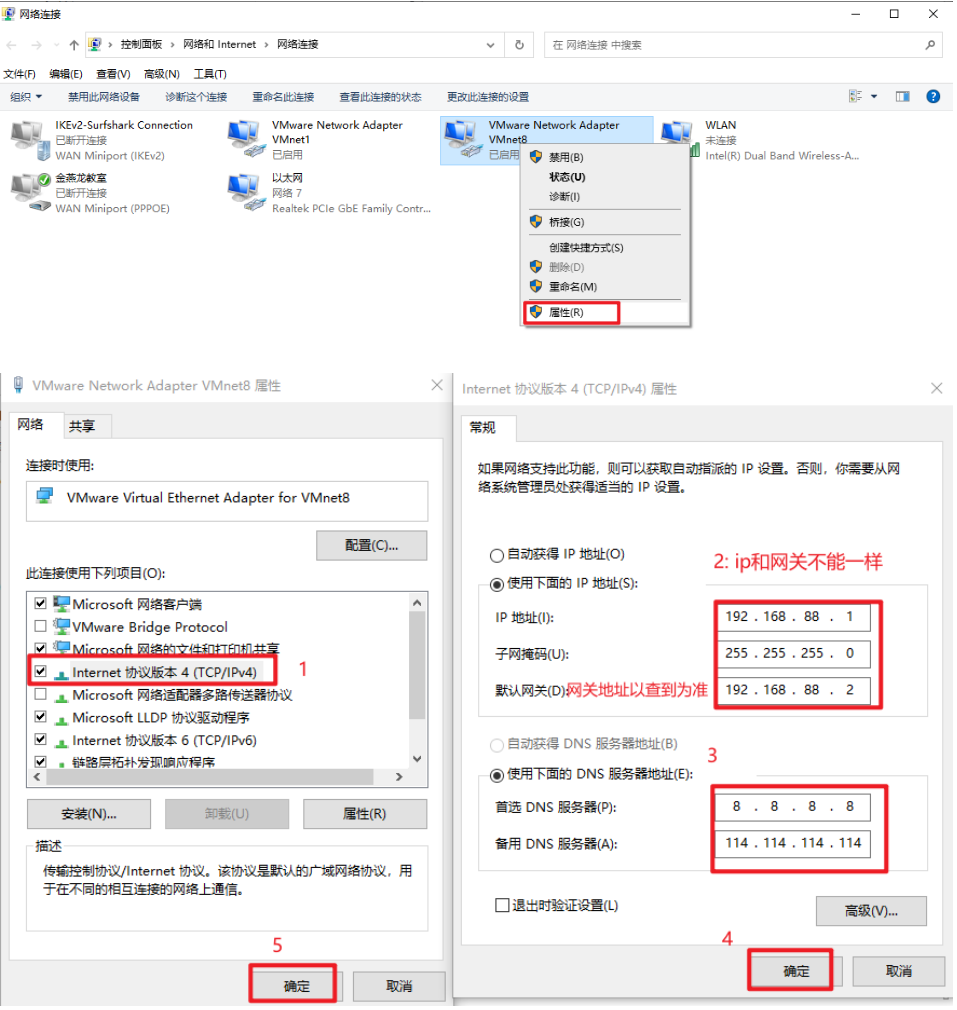
1- 了解网段 : ip中第三段 目前是 192.168.88 (所有虚拟机必须都是此网段下)查看虚拟机的ip地址即可: ifconfig2- 了解此网段下的网关地址: 需要到虚拟机中查看网关(所有的服务器必须指向同一个网关)网关地址查看文件位置: /etc/sysconfig/network-scripts/ifcfg-ens33查看此文件vim /etc/sysconfig/network-scripts/ifcfg-ens33
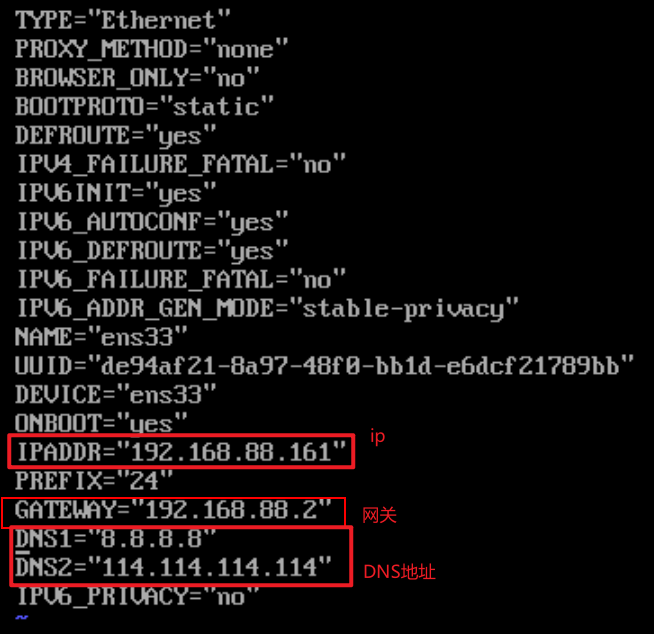
修改外部的网络:
- 1- 修改VMware的网络编辑器:


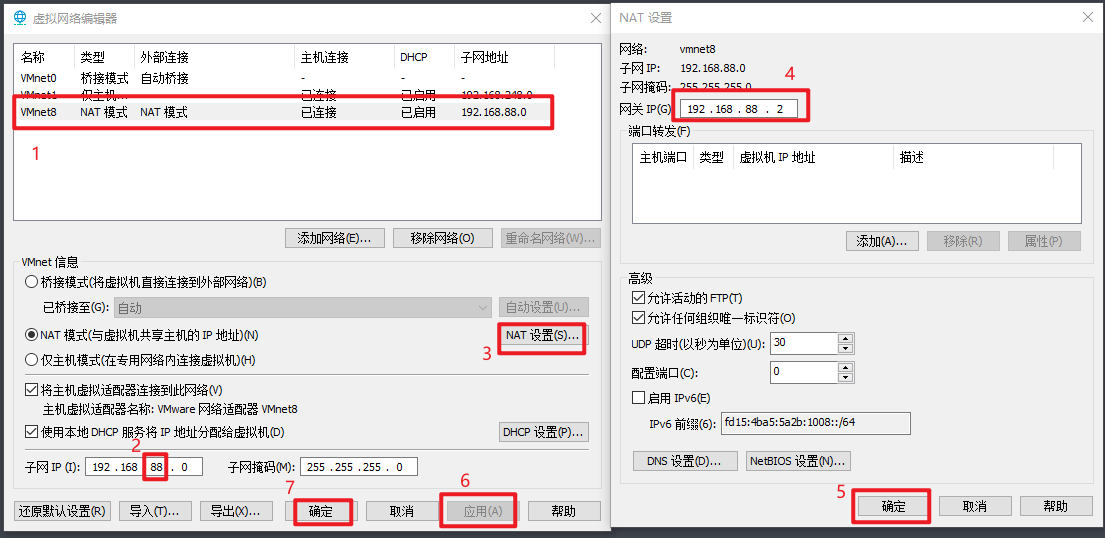
- 2- 修改windows的网络适配器
- 3- 即可在fineShell 或者 CRT 或者其他各种连接工具进行连接操作:
- 4- 连接后, 请测试网络是否畅通
ping www.baidu.com
2.1. Local模式安装
local模式主要是用于开发测试环境, 不能作为生产环境
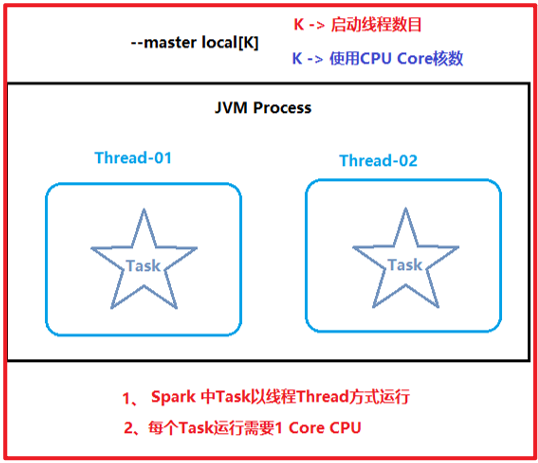
local本质上就是一个JVM进程程序 在这个程序中, 运行多个线程来分布式处理
local模式是一种单机模式, 仅适合于小量数据集的处理, 无法处理大规模数据
整个Loca模式Spark环境搭建操作, 请参考<
如何退出客户端程序: 严禁使用 ctrl + z (这不是退出, 而是挂载在了后台)
推荐使用以下的方式尝试退出客户端:ctrl + cctrl+ d:quit!quitquit:exit!exitexit
2.2. PySpark库安装
pyspark 是python下的一个库, 如果需要安装pyspark, 首先需要先保证有python的环境, 而且当前这个spark版本要求python的环境必须为3以上版本, 而目前虚拟机的版本为 Python2的版本

此时, 需要先安装python3的版本, 目前在虚拟机中, 需要安装的python版本为: 3.8.8
此处在安装python环境的时候, 我们不在采用原有的直接安装python包的方式, 而且是选择使用 anaconda (数据科学库)原因:1: anaconda是一个数据科学库, 这个库包含有python的环境 + python各种进行数据分析的库, 可以节省一部分关于数据科学库安装操作2: anaconda提交一套完善的虚拟环境, 可以基于anaconda构建多套互相隔离的虚拟环境(沙箱环境),可以在不同环境中安装不同的python的版本, 以及安装不同的python包
整个Loca模式Spark环境搭建操作, 请参考<
注意1:
每一个节点都需要安装 python的环境, 但是pyspark库仅需要在node1安装即可, 因为spark框架内部以及集成了pyspark库, 提交到spark环境中, 运行的时候, 不需要python环境中pyspark, 此时安装pyspark仅仅是为了让pycharm去加载, 然后能够编写代码.以及在本地客户端上进行直接测试操作
注意2:
如果大家直接使用 后续的快照, 那么所有的环境都是已经安装完成的, 大家可以直接使用即可,但是由于我的失误, 安装pyspark库的时候, 不小心安装为3.2.0版本, 并不是3.1.2 导致版本不一致,会存在兼容问题, 需要卸载掉pyspark 重新安装如何卸载?pip uninstall pyspark如何安装呢?pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark==3.1.2
扩展: anaconda的常用命令
安装库:conda install 包名pip install -i 镜像地址 包名卸载库:conda uninstall 包名pip uninstall 包名设置 anaconda下载的库的镜像地址:conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/conda config --set show_channel_urls yes如何使用anaconda构建虚拟(沙箱)环境:1- 查看当前有那些虚拟环境:conda env list2- 如何创建一个新的虚拟环境conda create 虚拟环境名称 python=版本号例如: 创建一个pyspark_env 虚拟环境conda create -n pyspark_env python=3.83- 如何进入虚拟环境(激活)source activate pyspark_env或者conda activate pyspark_env4- 如何退出虚拟环境:deactivate pyspark_env或者conda deactivate
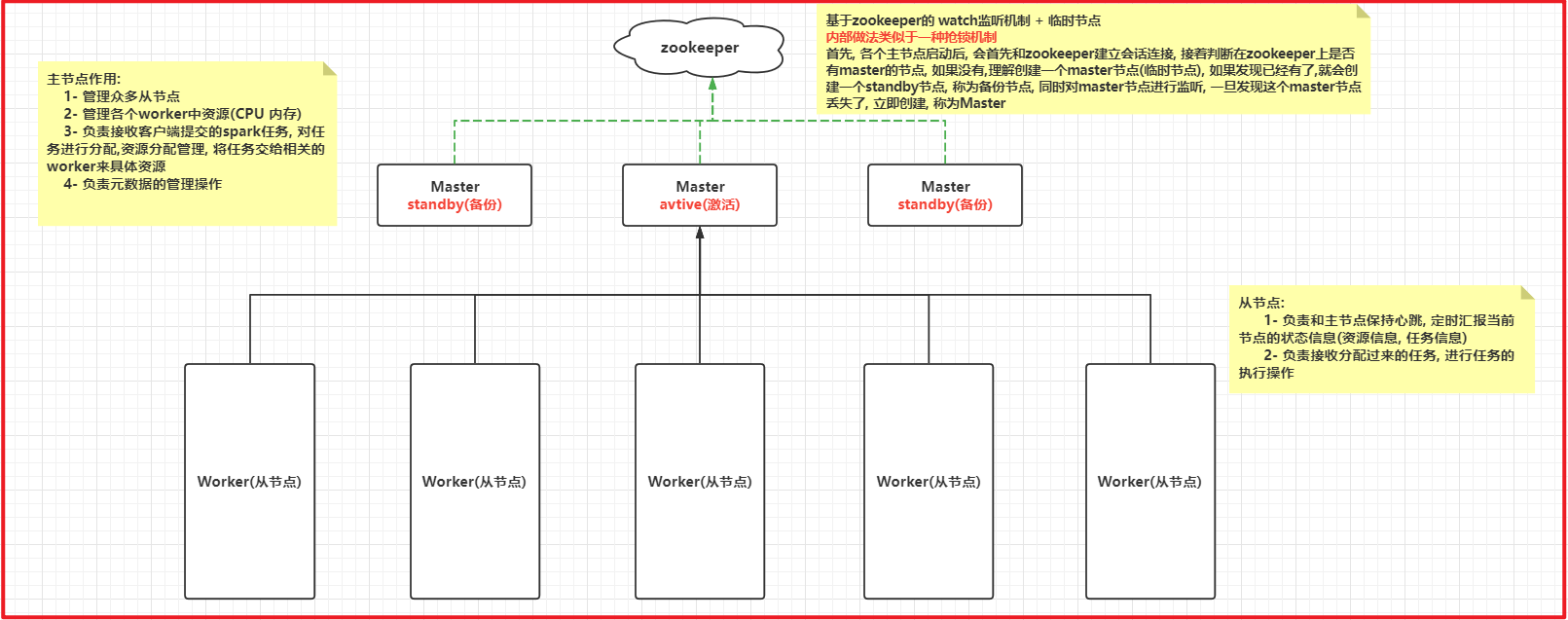
2.3 Spark集群模式架构
3. 基于pycharm完成PySpark入门案例

3.0 如何清理远端环境
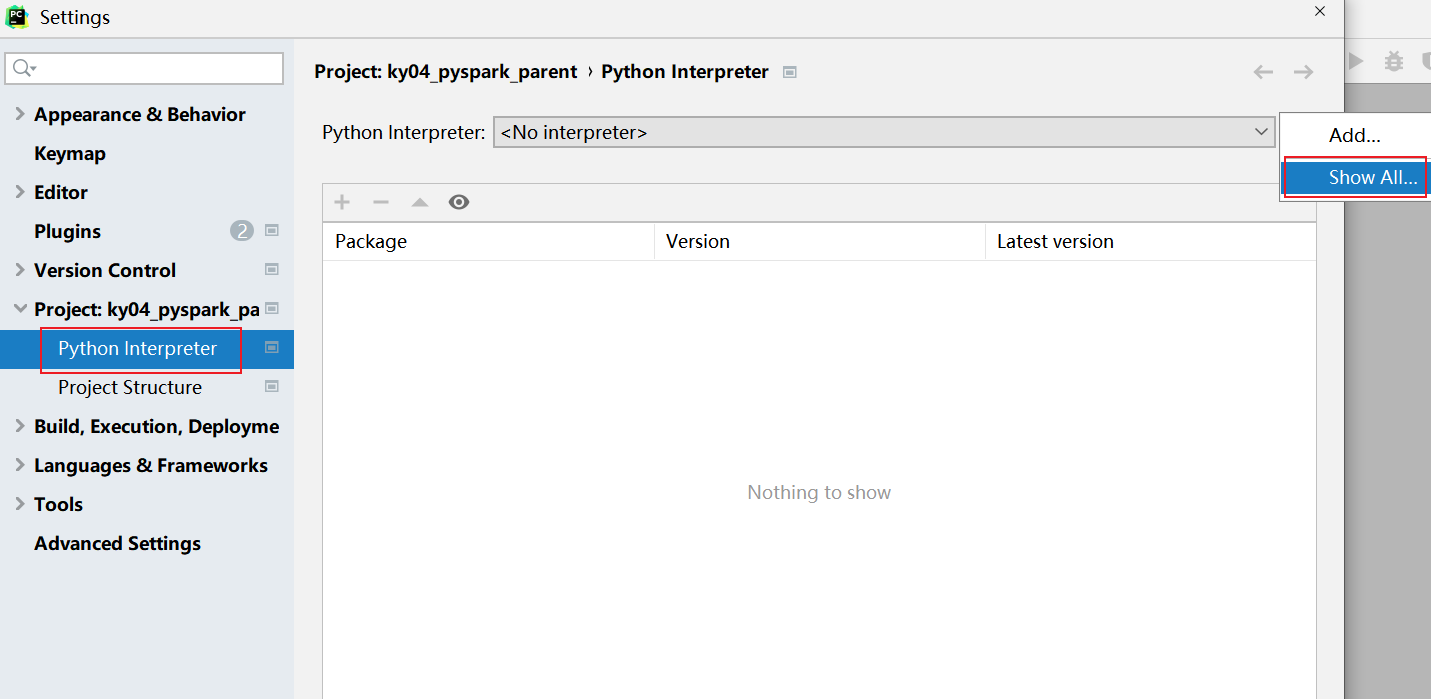
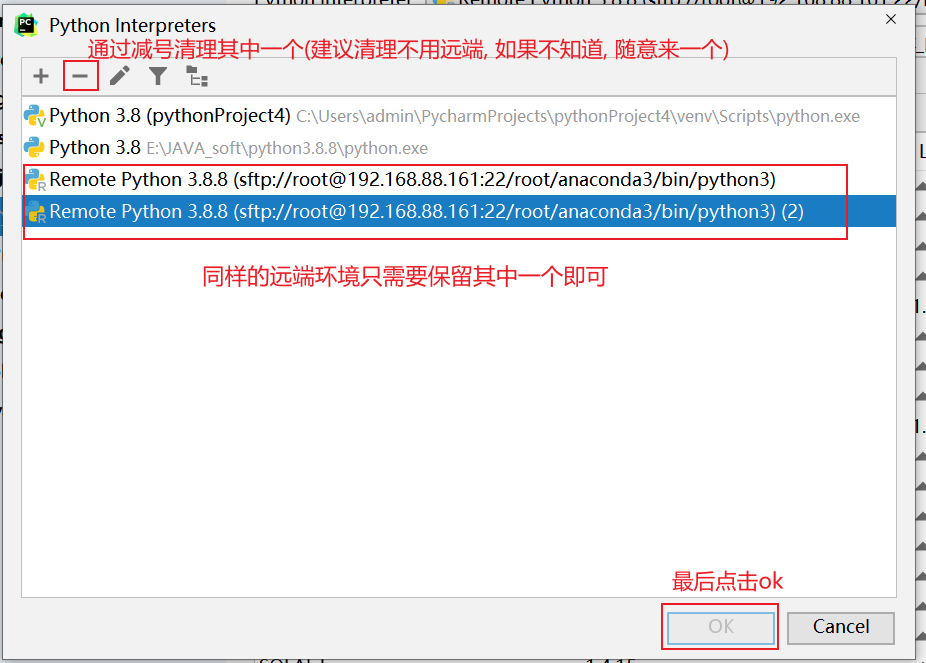
接下来, 还需要清理远端地址:
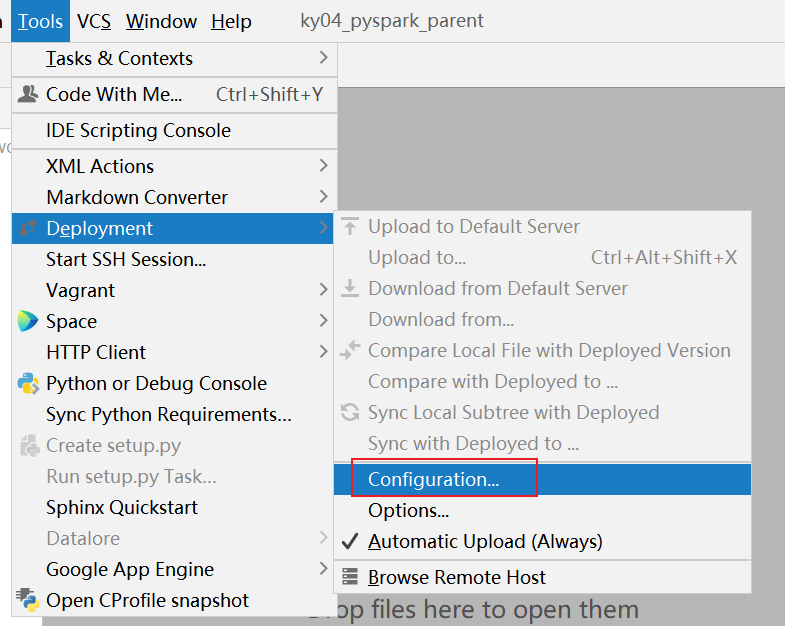
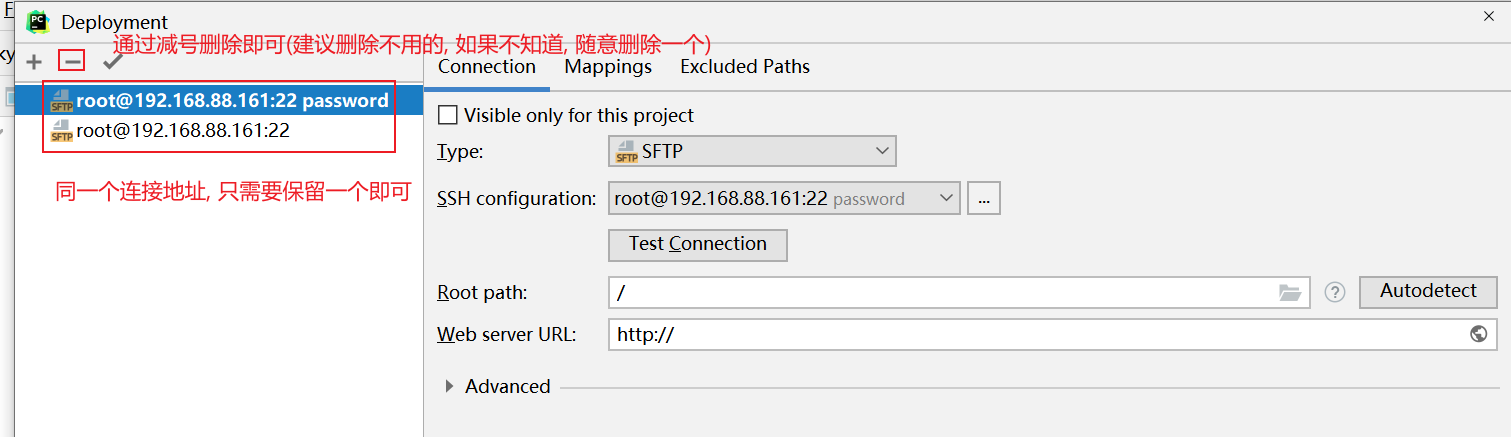
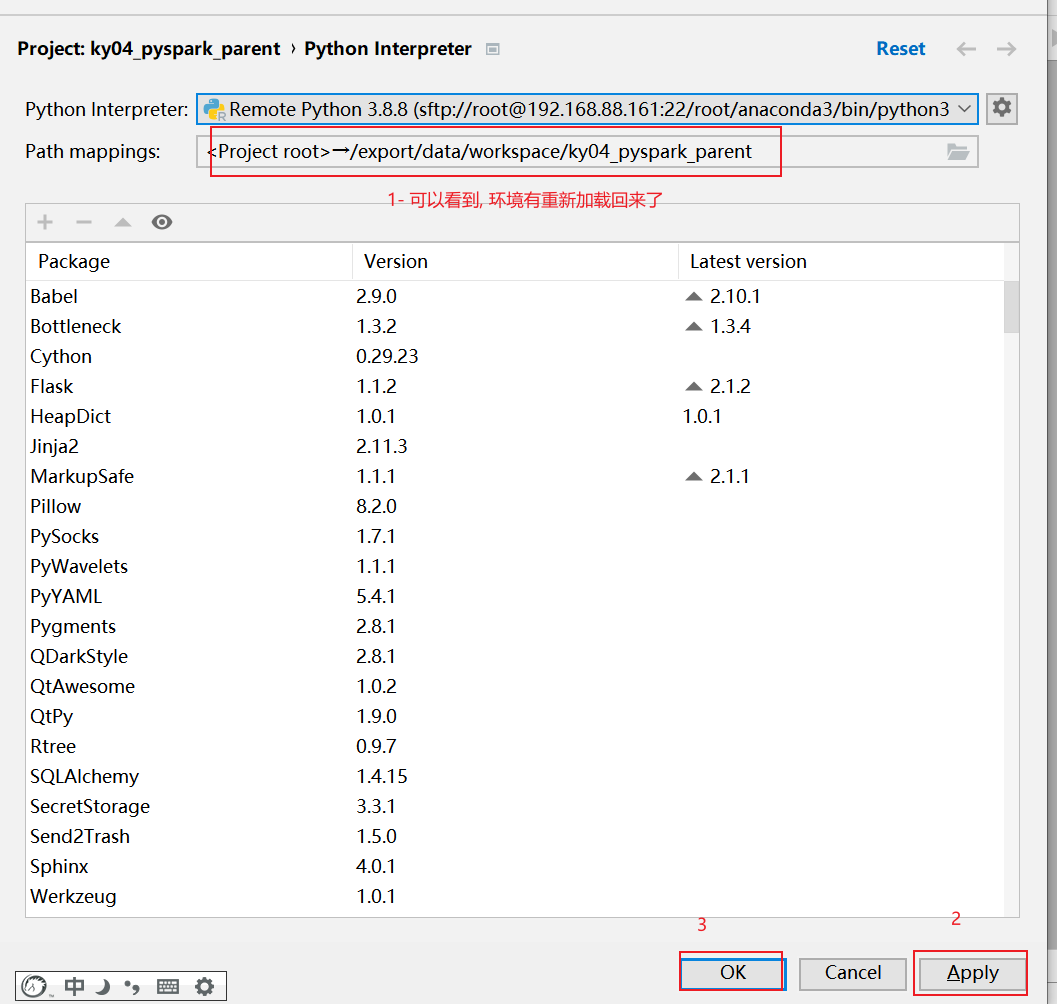
清理后, 重新配置当前项目使用远端环境:
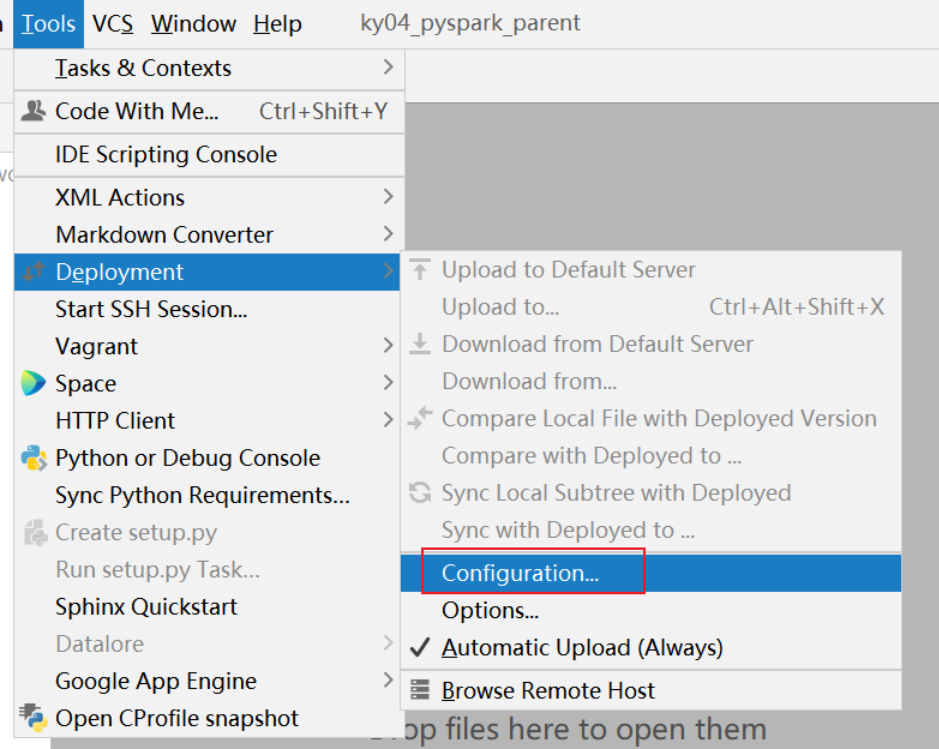
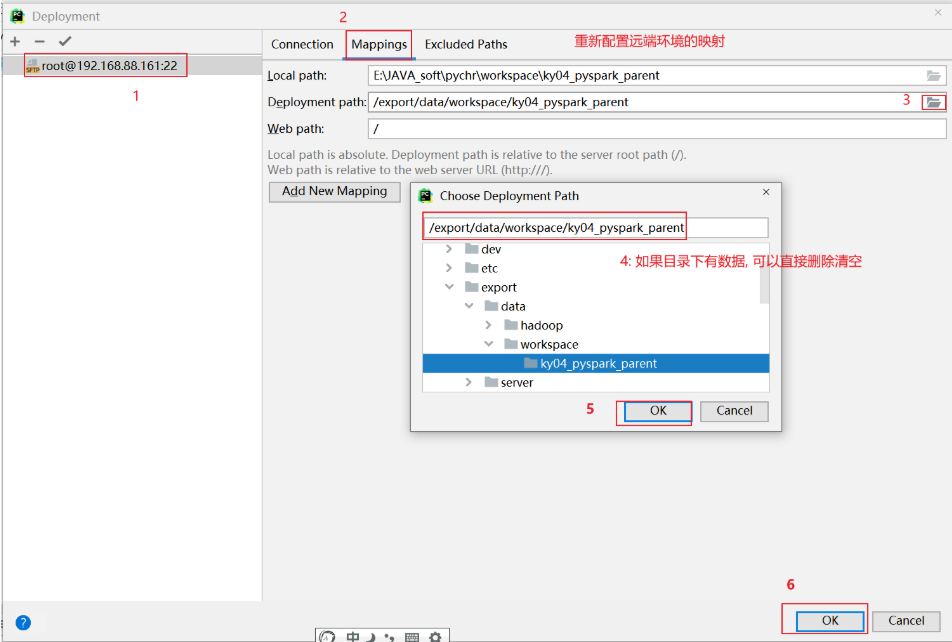
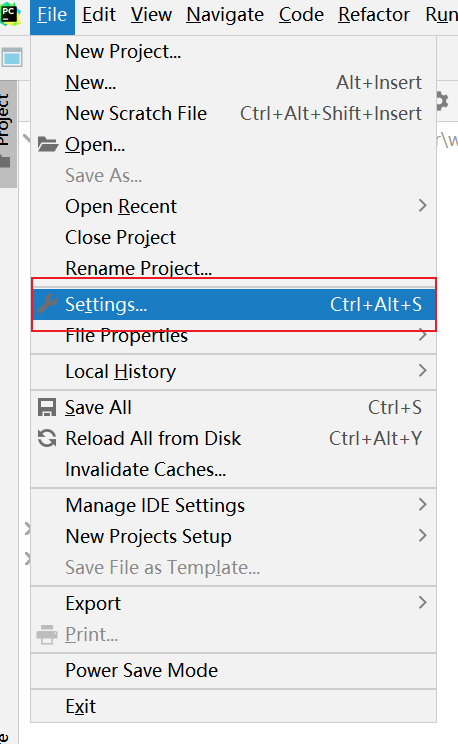
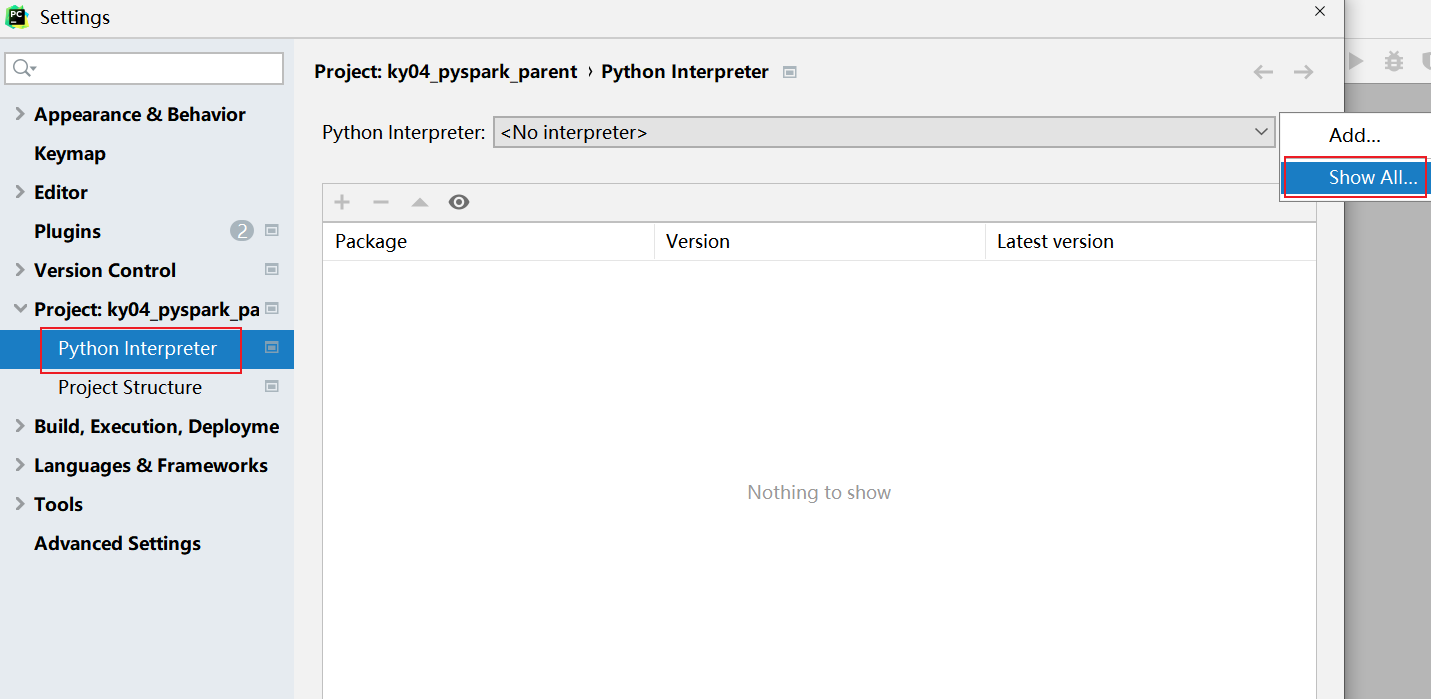
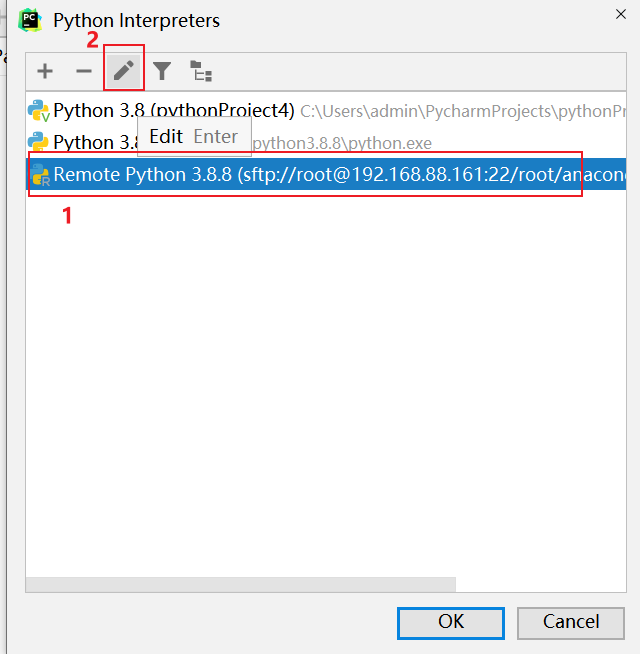
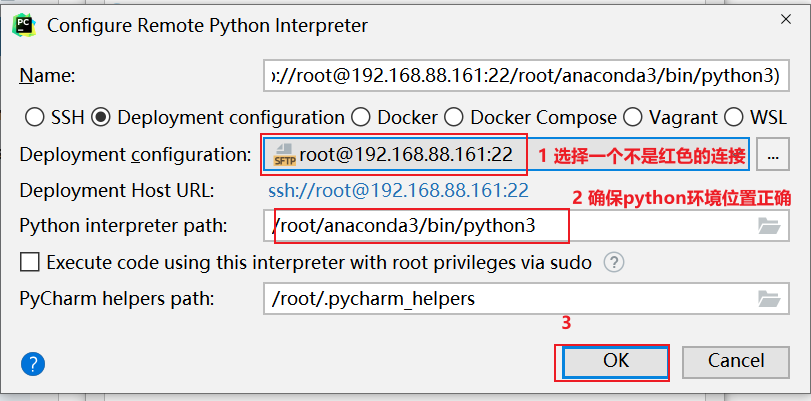
全部点击ok关闭即可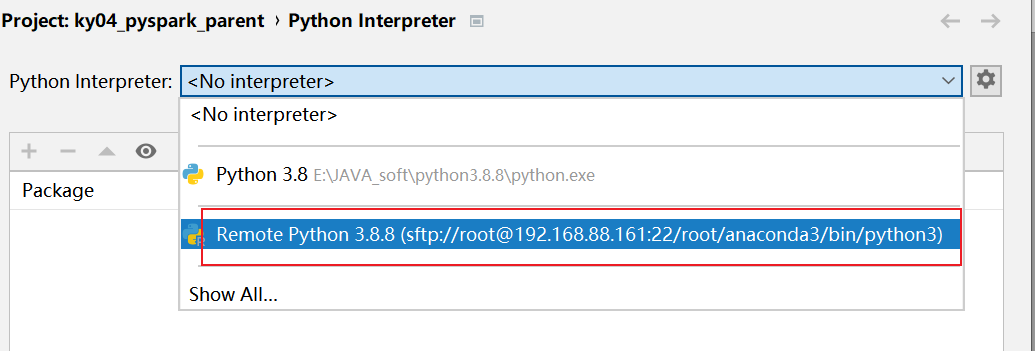
设置自动上传
3.1 pycharm如何连接远程环境
背景说明:
一般在企业中, 会存在两套线上环境, 一套环境是用于开发(测试)环境, 一套环境是用于生产环境, 首先一般都是先在开发测试环境上进行编写代码, 并且在此环境上进行测试, 当整个项目全部开发完成后, 需要将其上传到生产环境, 面向用于使用如果说还是按照之前的本地模式开发方案, 每个人的环境有可能都不一致, 导致整个团队无法统一一套开发环境进行使用, 从而导致后续在进行测试 上线的时候, 出现各种各样环境问题pycharm提供了一些解决方案: 远程连接方案, 允许所有的程序员都去连接远端的测试环境的, 确保大家的环境都是统一, 避免各种环境问题发生, 而且由于连接的远程环境, 所有在pycharm编写代码, 会自动上传到远端环境中, 在执行代码的时候, 相当于是直接在远端环境上进行执行操作
操作实现: 本次这里配置远端环境, 指的连接虚拟机中虚拟环境, 可以配置为 base环境, 也可以配置为 pyspark_env虚拟环境, 但是建议配置为 base环境, 因为base环境自带python包更全面一些

项目名为: sz30_pyspark_parent (强烈建议与我项目名一致)





创建项目后, 设置自动上传操作

校验是否有pyspark

ok 后, 就可以在项目上创建子项目进行干活了: 最终项目效果图

最后, 就可以在 main中编写今日代码了, 比如WordCount代码即可
扩展: 关于pycharm 专业版 高级功能
- 1- 直接连接远端虚拟机, 进行文件上传, 下载 查看等等操作


- 2- 可以模拟shell控制台:



- 3- 模拟datagrip操作:

3.2 WrodCount代码实现_local
3.2.1 WrodCount案例流程实现

3.2.2 代码实现
# 演示 pyspark的入门案例: WordCountfrom pyspark import SparkContext, SparkConfimport osos.environ['SPARK_HOME'] = '/export/server/spark'os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 快捷键: main + 回车if __name__ == '__main__':print("pyspark的入门案例: WordCount")# 1- 创建Spark核心对象: SparkContextconf = SparkConf().setMaster('local[*]').setAppName('wordCount')sc = SparkContext(conf=conf)# 2- 首先读取数据# 此处的路径地址, 不应该这样写, 因为后续有可能无法加载到, 建议添加文件协议# 如果读取本地文件: file:///# 如何读取HDFS文件: hdfs://node1:8020/# 注意, 由于我们采用连接远程环境的方案, 代码的执行最终是运行在远端环境, 所以说此处所说的本地文件指定 远程环境中本地文件rdd_init = sc.textFile('file:///export/data/workspace/sz30_pyspark_parent/_01_pyspark_base/data/words.txt')# 此处读的过程中, 采用一行行的读取, 将每一行收集回来,放置到一个列表中"""['hello world hello hadoop','hadoop hello world hive','hive hive hadoop','hadoop hadoop hive','hive hadoop hello hello','sqoop hive hadoop hello hello','hello world hello hadoop','hadoop hello world hive','hive hive hadoop']"""# 3- 对每一行的数据执行切割操作,转换为一个个列表# 一对一的转换操作: map#rdd_map = rdd_init.map(lambda line: line.split())# 预估一下结果:"""[['hello,world,hello,hadoop'],['hadoop,hello,world,hive'],['hive,hive,hadoop']]给我的感觉就是比较胖 大的列表套了一个小的列表希望结果: 扁平化处理[hello,world,hello,hadoop,hadoop,hello,world,hive,hive,hive,hadoop]"""# map转换增强版, 用于进行一对多的转换操作, 相当于 先执行map操作. 然后执行flat(扁平化操作)rdd_flatmap = rdd_init.flatMap(lambda line: line.split())# 4- 将每一个单词转换为 (单词,1)rdd_map = rdd_flatmap.map(lambda word:(word,1))# 期望结果:"""[(hello,1),(world,1),(hello,1),(hadoop,1),(hadoop,1)]"""# 5- 根据key进行分组聚合统计操作rdd_res = rdd_map.reduceByKey(lambda agg,curr: agg+curr)print(rdd_res.collect())
可能出现的错误:

无法加载到java_home原因:目前pycharm连接远程的python环境, 执行python的代码, 最终是将代码运行在远端环境的, 但是在远端环境中, 可能存在多个python环境, 以及内部加载的 .bashrc中环境信息, 但是这个环境中压根就没有 JAVA_HOME安装pyspark库同步安装了另一个 py4j的库, spark程序运行, 需要将python的代码 转换为java代码从而运行(只有其中一部分)解决方案? 需要在bashrc中配置相关的环境信息第一步: 需要修改 虚拟机中 .bashrc文件:vim ~/.bashrc在文件中, 添加以下两行内容:export JAVA_HOME=/export/server/jdk1.8.0_241/export PYSPARK_PYTHON=/root/anaconda3/bin/python3第二步: 重新加载bashrcsource ~/.bashrc第三步: 需要在代码中添加以下内容,用于锁定远程版本 (放置在mian函数的上面)os.environ['SPARK_HOME'] = '/export/server/spark'os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'

3.3 [扩展] 部署windows开发环境(不需要做)
- 1- 第一步: 需要安装Python 环境 , 建议使用anaconda 来安装即可
- 2- 第二步: 在Python安装pySpark
执行:pip install pyspark==3.1.2

- 3- 第三步: 配置 hadoop的环境

首先, 需要将 hadoop-3.3.0 放置到一个没有中文, 没有空格的目录下接着将目录中bin目录下有一个 hadoop.dll文件, 放置在c:/windows/system32 目录下 (配置后, 需要重启电脑)最后, 将这个hadoop3.3.0 配置到环境变量中:


配置后, 一定一直点确定退出, 否则就白配置了….
- 4-第四步: 配置spark本地环境

首先, 需要将 spark-3.1.2... 放置到一个没有中文, 没有空格的目录下最后, 将这个 spark-3.1.2... 配置到环境变量中:


配置后, 一定一直点确定退出, 否则就白配置了….
- 5-配置pySpark环境
需要修改环境变量


配置后, 一定一直点确定退出, 否则就白配置了….
- 6- 配置 jdk的环境:

首先: 需要将 jdk1.8 放置在一个没有中文, 没有空格的目录下接着:要在环境变量中配置 JAVA_HOME, 并在path设置



若有收获,就点个赞吧
0 人点赞
