今日内容
- 1- Spark ON hive(参数配置完成)
- 2- Spark SQL 分布式执行引擎(会使用)
- 3- Spark SQL 的运行机制(理解)
- 4- 综合案例(作业)
0 作业答案:
数据说明:
需求说明: 要求每一个都要使用 自定义函数方式 ```properties 1- 助攻这列 +10 操作: 自定义 UDF_c0,对手,胜负,主客场,命中,投篮数,投篮命中率,3分命中率,篮板,助攻,得分0,勇士,胜,客,10,23,0.435,0.444,6,11,271,国王,胜,客,8,21,0.381,0.286,3,9,282,小牛,胜,主,10,19,0.526,0.462,3,7,293,火箭,负,客,8,19,0.526,0.462,7,9,204,快船,胜,主,8,21,0.526,0.462,7,9,285,热火,负,客,8,19,0.435,0.444,6,11,186,骑士,负,客,8,21,0.435,0.444,6,11,287,灰熊,负,主,10,20,0.435,0.444,6,11,278,活塞,胜,主,8,19,0.526,0.462,7,9,169,76人,胜,主,10,21,0.526,0.462,7,9,28
2- 篮板 + 助攻 的次数: 自定义 UDF
3- 统计 胜负的平均分: 自定义 UDAF
代码实现:```properties第一步: 将资料中 data.csv 数据放置到 spark sql的项目的data目录下第二步: 编码实现操作:import pandas as pdfrom pyspark import SparkContext, SparkConffrom pyspark.sql import SparkSessionfrom pyspark.sql.types import *import pyspark.sql.functions as Fimport os# 目的: 锁定远端操作环境, 避免存在多个版本环境的问题os.environ["SPARK_HOME"] = "/export/server/spark"os.environ["PYSPARK_PYTHON"] = "/root/anaconda3/bin/python"os.environ["PYSPARK_DRIVER_PYTHON"] = "/root/anaconda3/bin/python"if __name__ == '__main__':print("pd 函数的案例")# 1) 创建 sparkSession对象spark = SparkSession.builder.master("local[*]").appName("_02_pd_udf").getOrCreate()# 开启 arrow方案:spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", True)# 2) 读取数据:df = spark.read.format("csv").option("header",True).option("inferSchema",True).load("file:///export/data/workspace/_03_pyspark_sql/data/data.csv")# 3) 为每一个需求 定义一个函数, 并通过装饰者方案注册即可:# 需求1 - 助攻这列 + 10 UDF@F.pandas_udf(returnType=LongType())def add_zg(n:pd.Series) -> pd.Series:return n + 10# 需求2 - 篮板 + 助攻的次数: udf@F.pandas_udf(returnType=LongType())def add_lb_zg(lb:pd.Series,zg:pd.Series) -> pd.Series:return lb + zg# 需求3 - 统计胜负的平均分: UDAF@F.pandas_udf(returnType=DoubleType())def mean_sf(score:pd.Series) -> float:return score.mean()# 4) 使用函数完成对应需求df.withColumn('助攻+10',add_zg('助攻')).show()df.withColumn('助攻+篮板',add_lb_zg('篮板','助攻')).show()df.groupby(df['胜负']).agg(mean_sf('得分')).show()
1- Spark On Hive
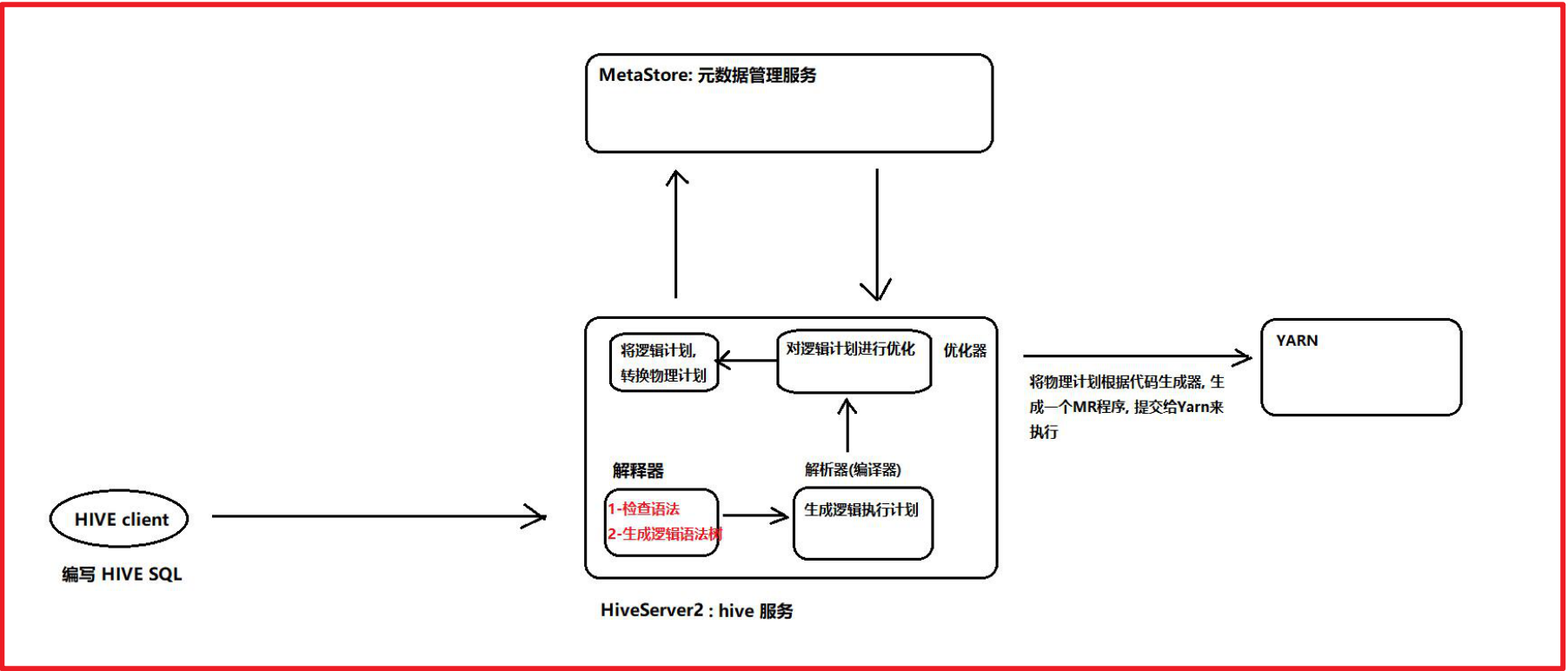
1.1 集成原理说明
说明:
HIVE的HiveServer2 本质上作用: 接收SQL语句 将 SQL 翻译为 MR程序,需要使用到相关元数据的时候,连接metastore来获取即可Spark on HIVE的本质: 将HIVE的MR执行引擎替换为 Spark RDD思考: 对于HIVE来说,本质上将SQL翻译为MR,这个操作是有hiveServer2来负责的,所以说Spark On HIVE主要目的,将HiveServer2替换掉,将其更换为Spark所提供的SparkServer2认为Spark On Hive本质: 替换掉HIVE中HiveServer2 让Spark提供一个spark的hiveServer2,对接metastore 从而完成将SQL翻译为Spark RDD好处:1- 对于Spark来说,也不需要自己维护元数据,可以利用hive的么他store来维护2- 集成HIVE后,整个HIVE的执行效率也提高了Spark集成目的: 抢占HIVE的时长所以Spark后续会提供一个分布式执行引擎,次引擎就是为了模拟HiveServer2,一旦模拟后,会让用户感觉跟操作原来HIVE基本上雷同的,比如说,端口号,连接的方式,配置的方式全部都一致思考: HIVE不启动hiveServer2是否可以执行呢? 可以的 通过 ./hive启动hiveServer2的目的: 为了可能让更多的外部客户端连接,比如说 datagrip
1.2 配置操作
大前提: 要保证之前hive的配置没有问题
建议:在on hive配置前, 尝试先单独启动hive 看看能不能启动成功, 并连接启动hive的命令:cd /export/server/hive/bin启动metastore:nohup ./hive --service metastore &启动hiveserver2:nohup ./hive --service hiveserver2 &基于beeline连接:./beeline 进入客户端输入: !connect jdbc:hive2://node1:10000输入用户名: root输入密码: 密码可以不用输入注意:启动hive的时候, 要保证 hadoop肯定是启动良好了启动完成后,如果能正常连接,那么就可以退出客户端,然后将HIVE直接通过 kill -9 杀掉了
配置操作:
1) 确保 hive的conf目录下的hive-site.xml中配置了metastore服务地址<property><name>hive.metastore.uris</name><value>thrift://node1:9083</value></property>2) 需要将hive的conf目录下的hive-site.xml 拷贝到 spark的 conf 目录下如果spark没有配置集群版本, 只需要拷贝node1即可如果配置spark集群, 需要将文件拷贝每一个spark节点上3) 启动 hive的metastore服务:cd /export/server/hive/binnohup ./hive --service metastore &启动后, 一定要看到有runjar的出现4) 启动 hadoop集群, 以及spark集群(如果采用local模式, 此集群不需要启动)5) 使用spark的bin目录下: spark-sql 脚本 或者 pyspark 脚本打开一个客户端, 进行测试即可测试小技巧:同时也可以将hive的hiveserver2服务启动后, 然后通过hive的beeline连接hive, 然后通过hive创建一个库, 在 spark-sql 脚本 或者 pyspark 脚本 通过 show databases 查看, 如果能看到, 说明集成成功了...测试完成后, 可以将hive的hiveserver2 直接杀掉即可, 因为后续不需要这个服务:首先查看hiveserver2服务的进程id是多少:ps -ef | grep hiveserver2 或者 jps -m查看后,直接通过 kill -9 杀死对应服务即可
1.3 如何在代码中集成HIVE
2- Spark SQL 分布式执行引擎
目前, 我们已经完成了spark集成hive的操作, 但是目前集成后, 如果需要连接hive, 此时需要启动一个spark的客户端(pyspark,spark-sql, 或者代码形式)才可以, 这个客户端底层, 相当于启动服务项, 用于连接hive服务, 进行处理操作, 一旦退出了这个客户端, 相当于这个服务也不存在了, 同样也就无法使用了此操作非常类似于在hive部署的时候, 有一个本地模式部署(在启动hive客户端的时候, 内部自动启动了一个hive的hiveserver2服务项)
大白话:目前后台没有一个长期挂载的spark的服务(spark hiveserver2 服务), 导致每次启动spark客户端,都行在内部构建一个服务项, 这种方式 ,仅仅适合于测试, 不适合后续开发
如何启动spark的分布式执行引擎呢? 这个引擎可以理解为 spark的hiveserver2服务
cd /export/server/spark./sbin/start-thriftserver.sh \--hiveconf hive.server2.thrift.port=10000 \--hiveconf hive.server2.thrift.bind.host=node1 \--hiveconf spark.sql.warehouse.dir=hdfs://node1:8020/user/hive/warehouse \--master local[*]

启动后: 可以通过 beeline的方式, 连接这个服务, 直接编写SQL即可:
cd /export/server/spark/bin./beeline输入:!connect jdbc:hive2://node1:10000

相当于模拟了一个HIVE的客户端, 但是底层运行是spark SQL 将其转换为RDD来运行的
方式二: 如何通过 datagrip 或者 pycharm 连接 spark进行操作:




注意事项: 在使用download下载驱动的时候, 可能下载比较慢, 此时可以通过手动方式, 设置一个驱动:





3- Spark SQL的运行机制
回顾:Spark RDD中Driver的运行机制
1- 当Driver启动后,首先会创建SparkContext对象,此对象创建完成后,在其底层同事创建: DAGSchedule 和 TaskScheduler2- 当遇到一个action算子后,就会触发启动一个JOB任务,首先DAGSchedule将所有action依赖的RDD算子全部合并在一个stage中,然后从后往前进行回溯,遇到RDD之间有宽依赖(shuffle),就会拆分为一个新的stage阶段,通过这种方式形成最终的一个DAG执行流程图,并且划分好stage,根据每个阶段内部的分区的数量,形成每个阶段需要运行多少个线程(Task),将每个阶段的Task线程放置到一个TaskSet列表中,最后将各个阶段的TaskSet列表发送给TaskSchedule3- TaskSchedule接收到DAGSchedule传递过来TaskSet,一次的运行每一个stage,将其各个线程分配给各个executor来进行运行执行4- 后续不断监控各个线程执行状态,直到整个任务执行完成
Spark SQL底层依然需要将SQL语句翻译为Spark RDD操作 所以 Spark SQL也是存在上述的流程,只不过在上述流程中加入了从Spark SQL翻译为Spark RDD的过程
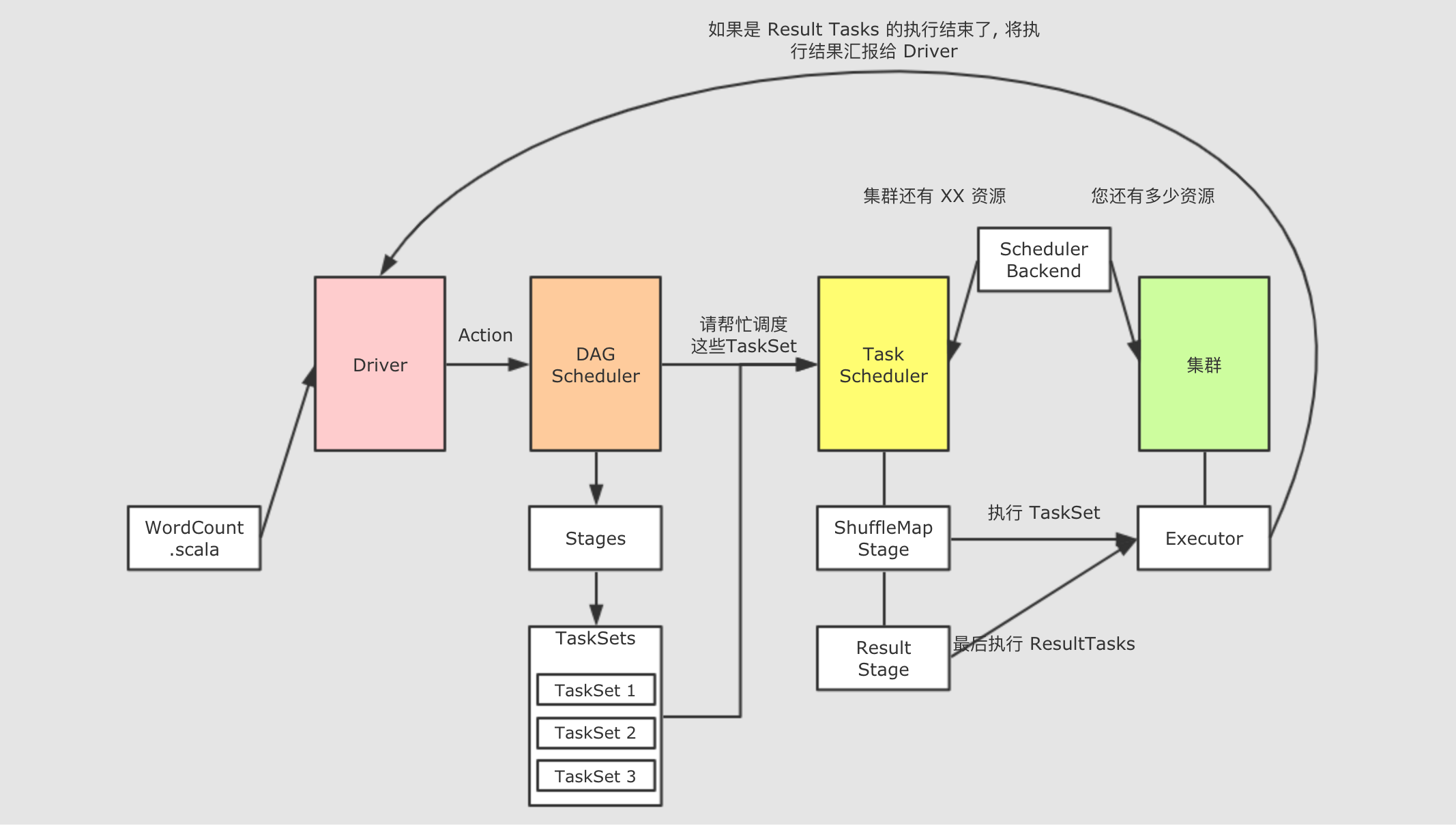
内部详细流程:大白话梳理
1- 当客户端讲SQL提交到Spark中,首先会将SQL提交给catalyst优化器2- 优化器首先会解析SQL,根据SQL的执行顺序形成一个逻辑语法树(AST)3- 接着对这个逻辑语法树加入相关的元数据(连接metastore服务),标识出需要从哪里读取数据,数据的存储格式,用到哪些表,表的字段类型 等等...,形成一个未优化的逻辑优化4- catalyst开始执行RBO(规则优化)工作 : 将未优化的逻辑计划根据spark提供的优化方案对计划进行优化操作,比如说可以执行谓词下推,列值裁剪,提前聚合... 优化后得到一个优化后的逻辑执行计划5- 开始执行 CBO(成本优化)工作: 在进行优化的时候,由于优化的规则比较多,可能匹配出多种优化方案,最终可能会产生多个优化后的逻辑执行计划,此时通过代价函数(选最优),选择出一个效率最高的物理计划6- 将物理计划,通过代码生成器工具 将其转换为RDD程序7- 将RDD提交到集群中运行,后续的运行流程 跟之前RDD运行流程就完全一致了
专业术语:
1- sparkSQL底层解析是有RBO 和 CBO优化完成的2- RBO是基于规则优化, 对于SQL或DSL的语句通过执行引擎得到未执行逻辑计划, 在根据元数据得到逻辑计划, 之后加入列值裁剪或谓词下推等优化手段形成优化的逻辑计划3- CBO是基于优化的逻辑计划得到多个物理执行计划, 根据代价函数选择出最优的物理执行计划4- 通过codegenaration代码生成器完成RDD的代码构建5- 底层依赖于DAGScheduler 和TaskScheduler 完成任务计算执行
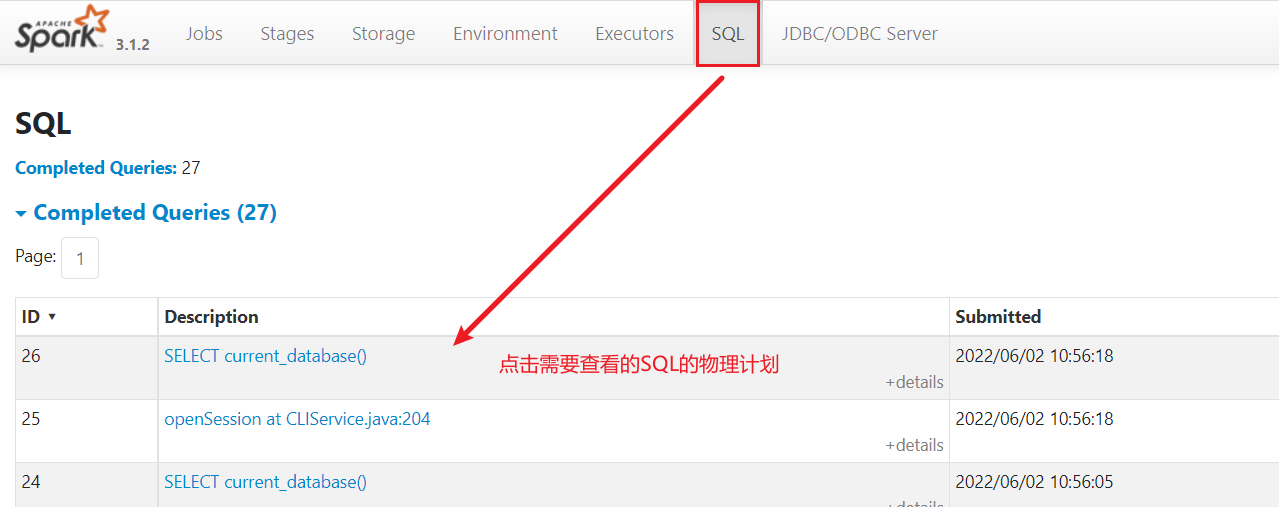
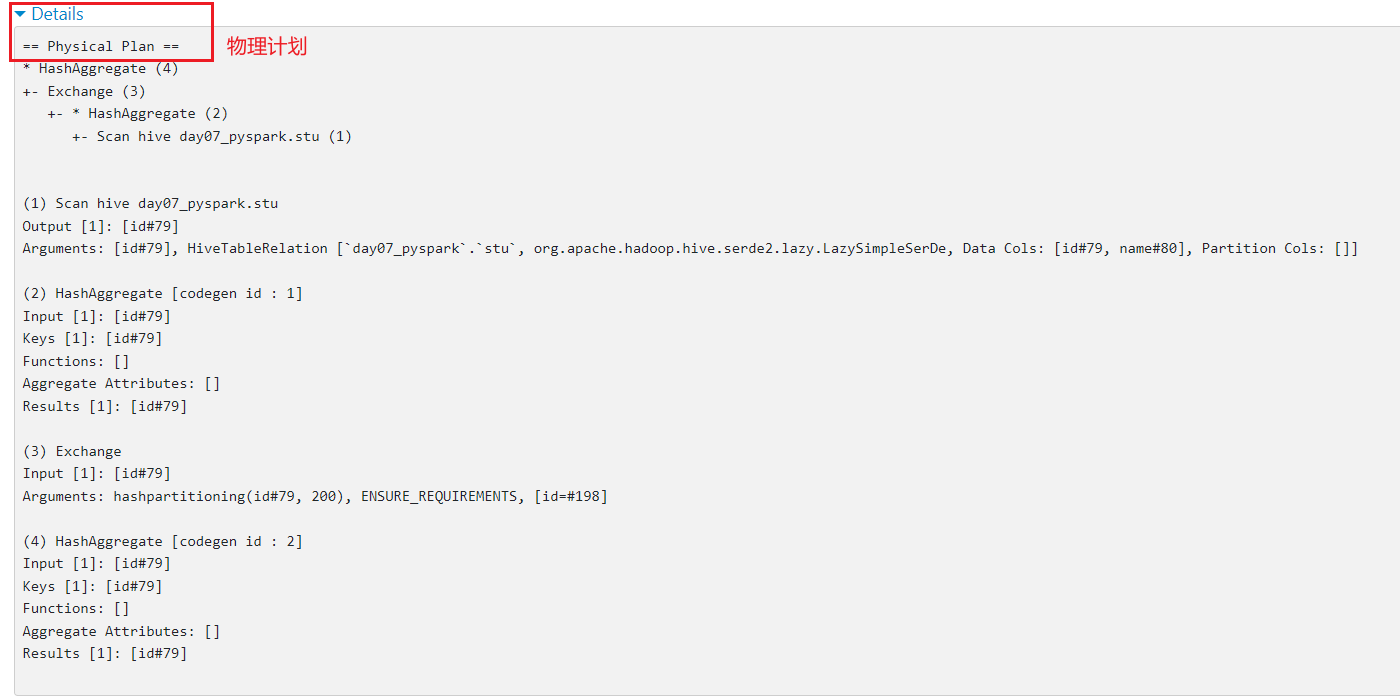
如何查看物理执行计划呢?
- 方式一 : 通过spark thrift server的服务界面: 大概率是 4040界面

4.1 新零售综合案例
数据结构介绍:
InvoiceNo string 订单编号(退货订单以C 开头)StockCode string 产品代码Description string 产品描述Quantity integer 购买数量(负数表示退货)InvoiceDate string 订单日期和时间 12/1/2010 8:26UnitPrice double 商品单价CustomerID integer 客户编号Country string 国家名字字段与字段之间的分隔符号为 逗号
E_Commerce_Data.csv

拿到数据之后, 首先需要对数据进行过滤清洗操作: 清洗目的是为了得到一个更加规整的数据
清洗需求:需求一: 将客户id(CustomerID) 为 0的数据过滤掉需求二: 将商品描述(Description) 为空的数据过滤掉需求三: 将日期格式进行转换处理:原有数据信息: 12/1/2010 8:26转换为: 2010-01-12 08:26
相关的需求(DSL和SQL):
(1) 客户数最多的10个国家(2) 销量最高的10个国家(3) 各个国家的总销售额分布情况(4) 销量最高的10个商品(5) 商品描述的热门关键词Top300(6) 退货订单数最多的10个国家(7) 月销售额随时间的变化趋势(8) 日销量随时间的变化趋势(9) 各国的购买订单量和退货订单量的关系(10) 商品的平均单价与销量的关系
2.1.1 完成数据清洗过滤的操作
2.1.2 需求统计分析操作
4.2 在线教育案例
数据结构基本介绍:
student_id string 学生idrecommendations string 推荐题目(题目与题目之间用逗号分隔)textbook_id string 教材idgrade_id string 年级idsubject_id string 学科idchapter_id strig 章节idquestion_id string 题目idscore integer 点击次数answer_time string 注册时间ts timestamp 时间戳字段与字段之间的分隔符号为 \t

需求:
需求一: 找到TOP50热点题对应科目. 然后统计这些科目中, 分别包含几道热点题目需求二: 找到Top20热点题对应的饿推荐题目. 然后找到推荐题目对应的科目, 并统计每个科目分别包含推荐题目的条数
数据存储在 资料中: eduxxx.csv

若有收获,就点个赞吧
0 人点赞
