1. 结构设计
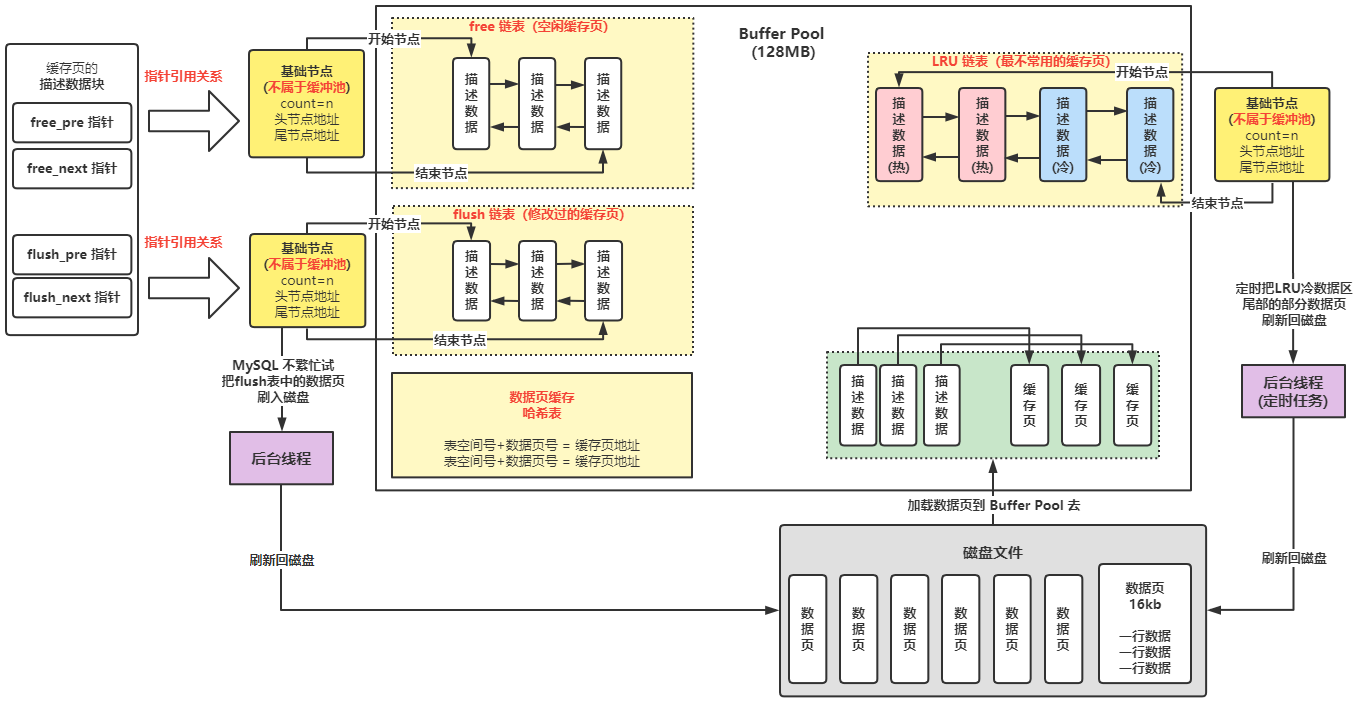
1.1 数据页
- MySQL 中抽象出来的数据单位,每一个数据页放了很多行数据;
- 数据在磁盘和内存中都是以数据页为单位来调用的;
- 内存中的数据页,又称为缓存页;
- 数据页默认大小 16KB;
如果要更新一行数据,就会找到这行数据所在的数据页,然后从磁盘里将这个数据页加载到 Buffer Pool 里去;
1.2 缓存页的描述数据
在 Buffer Pool 中,每个缓存页都有一个块描述数据,包含:
- 这个数据页所属表空间
- 数据页编号
- 在 Buffer Pool 中缓存页所在内存地址;
- 等等;
描述数据的大小,相当于缓存页的5%,大概 800Byte 左右;
1.3 free 链表
作用:管理空闲的缓存页;
- 结构设计:
- 它是一个双向链表结构;
- free 链表里的每一个节点就是一个空闲的缓存页的描述数据块;
- free 链表有一个基础节点,它会引用链表的头节点和尾节点,里面还存储了链表中有多少个节点;
- free 链表依靠描述数据块中包含的两个指针:free_pre 和 free_next,将所有的描述数据块串成一个 free 链表;
- free 链表是一个逻辑概念,并不是真的有一个描述数据的地址集合;
基础节点不属于 Buffer Pool,它是一个40 byte 大小的节点,里面放了 free 链表的头节点地址、尾节点地址、节点总数;
1.4 数据页缓存的哈希表
作用:查看数据页是否已被缓存;
结构设计:
作用:管理被修改过的缓存页,即需要刷新回磁盘的有脏数据的缓存页;
结构设计:
作用:Least Recently Used,使用 LRU 链表来判断哪些缓存页是最不常使用的,根据 LRU 链表去淘汰缓存页;
- 结构设计:
- 它也是一个双向链表,结构和 flush、free 链表类似;
- 工作原理:
- 只要是将数据从磁盘中加载到缓存里,变成非空闲的缓存页,它对应的描述数据块都会放入 LRU 链表;
- 最近被加载的数据页,都会放到 LRU 链表的头部去;
- 本来在 LRU 链表尾部的缓存页,只要你查询、或修改了这个缓存页的数据,就要把这个缓存页挪动到 LRU 链表的头部去:最近被访问的缓存页,一定在 LRU 链表的头部;
- 当你没有空闲的缓存页的时候,就把 LRU 链表最尾部的那个缓存页刷新回磁盘中,然后把你需要的数据从磁盘加载到空闲出来的缓存页中去;
- 简单的 LRU 链表存在的隐患:
- MySQL 的预读机制:
- 触发条件:
- innodb_read_ahead_threshold,默认56,如果顺序的访问了一个区里的多个数据页,访问的数据页的数量超过了这个阈值,就会触发预读机制,把下一个相邻区中的所有数据页都加载到缓存里去;(主要触发规则)
- innodb_random_read_ahead,默认 OFF,如果 Buffer Pool 里缓存了一个区里的 13 个连续的数据页,而且这些数据页都是会被比较频繁的访问,就会触发预读机制,把这个区里的其他的数据页都加载到缓存里去;
- 隐患:
- 默认情况下,主要第一规则触发预读机制,一下子把下一个相邻区里的所有数据页都加载到缓存区,这些其实没什么人会访问的缓存页会都放在 LRU 链表的前面,而且导致之前就在缓存里被频繁访问的缓存页挪动到了尾部,如果此时要淘汰一些缓存页,就会把这些本来被频繁访问的缓存页刷新回磁盘,而那些不怎么被访问的却留在了缓存里,这是不合理的!
- 触发条件:
- 全表扫描:
- 查询时,没有加 where 条件,将这个表的所有数据页都加载到 Buffer Pool;
- 隐患:
- 全表扫描加载进来的数据页,会占据 LRU 链表的头部,如果淘汰缓存页时,将一直被频繁访问的缓存页给淘汰掉了,而后续全表扫描的数据又几乎都没有用到,这就是不合理的!
- MySQL 的预读机制:
优化后的基于冷热数据分离的 LRU 链表(MySQL 真正采用的):
- 结构设计:
- LRU 链表会被拆为两个部分:热数据、冷数据,默认占比:63%、37%,可配置 innodb_old_blocks_pct 参数;
- 工作原理:
- 结构设计:
innodb_buffer_pool_size:设置 Buffer Pool 大小;
- innodb_buffer_pool_instances:设置多个 buffer pool 提高并发能力;
- 如果设置 pool_size 128M,Buffer Pool 真正大小其实会超出一些,128+128*0.05=134.4,里面还要包含每个缓存页的描述数据;
- innodb_old_blocks_pct:默认37,设置 LRU 链表的冷热数据比例,即冷数据占37%;
- innodb_old_blocks_time:默认1000,即1000毫秒,一个数据页被加载到缓存页之后,在1s之后,你访问这个缓存页,他才会被挪动到热数据区域的链表头部;
innodb_buffer_pool_chunk_size:默认128MB,chunk 结构块的大小;
2. 工作原理
2.1 Buffer Pool 的初始化
数据库启动,会按照你设置的 innodb_buffer_pool_size 大小,稍微再加大一点,去找操作系统申请一块内存区域作为 Buffer Pool 的内存区域;
- 内存区域申请完毕后,MySQL 会按照默认的 16KB 缓存页大小,以及对应的 800byte 左右的描述数据的大小,将 Buffer Pool 划分成一个一个空白的缓存页,以及对应的描述数据块;
可能所有的缓存页都是空闲的,一条数据都没有,free 链表保存了所有空白缓存页的描述数据块;
2.2 查看数据页缓存哈希表
执行 CURD 的时候,先看看这个数据页有没有被缓存;
通过“表空间号+数据页号”作为 key 去哈希表里查一下,如果已经缓存了就直接使用,如果没有缓存就往下执行;
2.3 将磁盘上的数据页加载到 Buffer Pool 的缓存页中去
从 free 链表获取一个描述数据块,然后依赖它获取到对应的空闲缓存页;
- 将磁盘上的数据页读取到对应的空闲缓存页中去,同时把相关的一些描述数据写入到对应的描述数据块中去,比如这个数据页所属的表空间之类的信息;
- 把这个描述数据块从 free 链表里移除掉;
- 在数据页缓存哈希表中,写入一个 key-value 对,key 是表空间号+数据页号,value 是缓存页地址,下次再次访问这个数据页时,直接使用;
-
2.4 查询或修改加载进来的缓存页
查询:如果在加载进缓存的 1s 之后,查询了这个缓存页
- 如果本来就在冷数据区,那么就会把这个缓存页从 LRU 链表的冷数据区域中移动到热数据区头部;
- 如果本来就在热数据区,且在后面 3/4 部分,那么就移动到热数据的头部;
- 如果本来就在热数据区,且在前面 1/4 部分,那么就不会移动;
修改:
定时把 LRU 链表尾部的部分缓存页刷入磁盘;
- 后台线程运行一个定时任务,每隔一段时间就回把 LRU 链表的冷数据区尾部的一些缓存页,刷新回磁盘,清空这几个缓存页,把它们加入回 free 链表,从 flush 链表中移除,从 LRU 链表中移除;
- 实际上在缓存页没用完的时候,可能就回清空一些缓存页出来;
- 仅仅把 LRU 链表冷数据区的刷入磁盘是不够的,不能因为 LRU 热数据区的缓存页被频繁的修改,就让它们永远的停留在缓存里,不刷入磁盘中,这是不合理的;
- 定时把 flush 链表中的一些缓存刷入磁盘;
- 后台线程会在 MySQL 不怎么忙的时候,把 flush 链表中的缓存页都刷入磁盘中,这样被你修改过的数据,迟早都会刷入磁盘,同时这些缓存页会从 flush 链表和 LRU 链表中移除,然后加入 free 链表中去;
- 极端情况,free 链表没有空间缓存页了,如果要从磁盘加载数据页到一个空闲缓存页,此时就会从 LRU 链表冷数据区的尾部找到一个缓存页,把它刷入磁盘和清空,然后把数据页加载到这个腾出来的空闲缓存页里去;
:::info Buffer Pool 简化版的动态运行效果:
- 一边不停的加载数据到缓存页里,不停的查询和修改缓存数据,然后 free 链表中的缓存页不停的减少,flush 链表中的缓存页不停的在增加,LRU 链表中的缓存页不停的在增加和移动;
- 后台线程不停的在 LRU 链表的冷数据区域的缓存页以及 flush 链表的缓存页,刷入磁盘中来清空缓存页,然后 flush 链表和 LRU 链表中的缓存页在减少,free 链表中的缓存页在增加; :::
3. Buffer Pool 的生产优化经验
3.1 多个 Buffer Pool 优化并发能力
- 默认情况下,如果你给 Buffer Pool 分配的内存小于 1GB,那么最多就只会给你一个 Buffer Pool;
如果机器的内存很大,分配给 Buffer Pool 的内存页很大,比如 8GB,那么此时就可以同时设置多个 Buffer Pool,例如下面的配置:
- 设置了 4个 buffer pool,每个2GB;
- 每个 buffer pool 负责一部分的缓存页和描述数据,但是它们有自己独立的 free、flush、LRU 链表;
[server]innodb_buffer_pool_size = 8589934592innodb_buffer_pool_instances = 4
多个线程可以在不同的 buffer pool 中加锁和执行自己的操作,可以并发执行;
3.2 基于 chunk 机制支持运行时动态调整 Buffer Pool 大小
chunk 默认大小 128MB,可设置 innodb_buffer_pool_chunk_size 参数;
- Buffer Pool 总大小 8G,设置4个 buffer pool,每个 buffer pool 2GB、包含 16 个 chunk;
- 每个 buffer pool 里的 chunk就是一系列的描述数据和数据页,buffer pool 里的所有 chunk 共享一套 free、flush、LRU 链表;
假设现在 Buffer Pool 总大小8G,要动态加到16G,那么只要盛情一系列的128MB大小的 chunk 就可以了,只要每个 chunk 试连续的128M内存就可以,然后把这些申请到的 chunk 内存分配给 Buffer pool 就可以,而并不需要额外申请16G连续内存空间,将已有数据拷贝过去;
3.3 应该给 Buffer Pool 设置多少内存?
关键公式:Buffer Pool 总大小 = (chunk大小 * buffer pool 数量) 的倍数;
- 例如,buffer pool 设置16个,chunk大小buffer pool 数量 = 16128MB = 2048MB,然后如果 Buffer Pool 总大小设置 20G,是符合的规则的,此时就是 2048M的10倍;

若有收获,就点个赞吧
0 人点赞
