B+树是B树的一种变体,有着比B树更高的查询性能,<br />由于B+树的中间节点没有data数据,所以同样大小的磁盘页可以容纳更多的元素节点,所以数据量相同的情况下,B+树比B树更加矮胖,因此使用的IO查询次数更少,<br />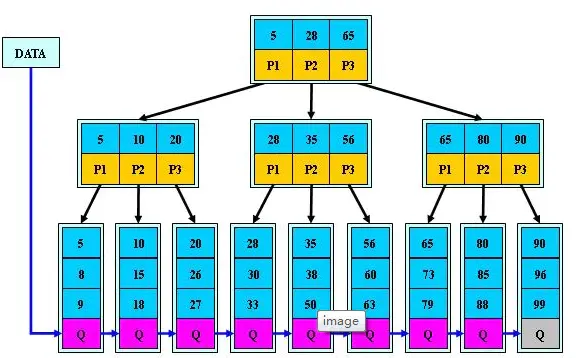
特征:
根节点至少有两个节点,
每个中间节点都至少包含(m/2)个孩子,最多有m个孩子
每个叶子节点都包含k-1个元素,其中m/2 <=k <=m,(最终到底是k,还是k-1.一直没有说清楚,维基百科说是-1,mysql数据库用的是k)
所有的叶子节点在同一层,并且叶子节点才会存在数据,普通节点只是关键字搜索,叶子节点之间用链表关联
每个节点的元素,从小到大排列,
所有的元素在叶子节点上都有显示,会包含普通节点的元素,
所有中间节点的元素都同时存在于子节点,在子节点元素中最大(最小)元素
中间节点在子节点元素中最大,也就是根节点原色最大,也就是整个B+树的最大元素,以后插入的元素都要始终保持最大元素在根节点中
B+树有的是子节点中包含父节点的元素,有的不包含,具体我也分不清,理解意思就行了,情况不一致,查找不会有什么区别,但是添加删除,有区别,会有关于父级的操作不同,一个不用处理,一个需要替换,上移,
使用场景
文件系统和数据库系统中常用B/B+树,它通过对每个节点存储个数的扩展,使得对连续的数据能够进行较快的定位和访问,能够有效减少查找事件,提高存储的空间局部性从而减少IO操作,它广泛用于文件系统及数据库中
windows:HPFS文件系统
Mac:HFS,HFS+文件系统
linux:ResiserFS,XFS,Ext3FS,JFS文件系统
数据库:ORACLE,MYSQL,SQLSERVER
B+树查找
跟普通的B树类似,但是需要逐层寻找到叶子节点才会命中元素,根据中间节点的元素范围,去下一级,直到叶子节点,
添加元素
是将元素插入到叶子节点中,然后进行平衡操作
当是一棵空树的时候,就是根节点,既是根节点,也是叶子节点,直接插入即可
1.添加到叶子节点中,插入后,当叶子节点的数量小于等于m-1(或者m)时,
不需要其他操作
2.添加到叶子节点中,插入后,当叶子节点的数量大于m-1(或者m)时,
将叶子节点分裂,分裂出来的左节点2个key,右节点3个key,变为中间节点key的子节点,中间节点key上移至父节点
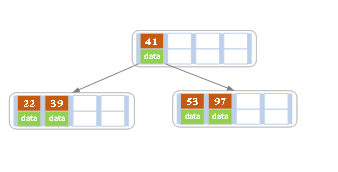
3.当添加叶子节点后,需要上移节点,当父节点的元素值数量也大于m-1时
就需要再次分裂,中间节点向上转移,变为父节点,循环操作,直到最后,都符合标准
至于根节点的右侧节点,是否包含33,没有解释清楚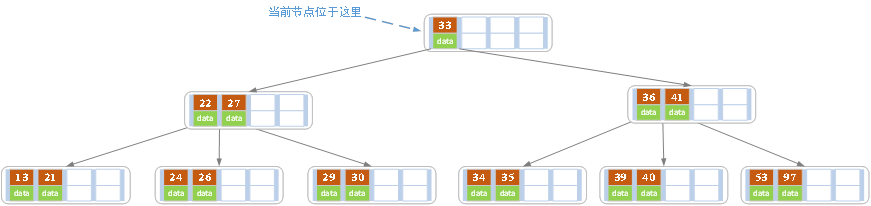
删除元素
如果叶子节点中没有相应的key,则删除失败,
1.删除叶子节点,如果删除后,叶子节点的元素数量大于等于(m/2)-1,
无需操作
2.删除叶子节点,如果删除后,叶子节点的元素数量小于(m/2)-1,且兄弟节点有富裕,大于(m/2)-1
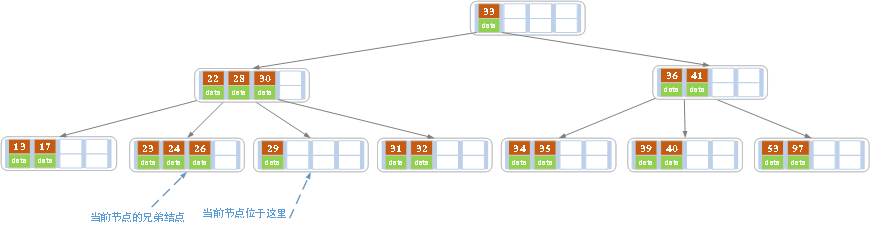
向兄弟节点借一个元素,同时用借到的元素替换父节点,(当前节点跟兄弟节点共同的父节点元素),删除完成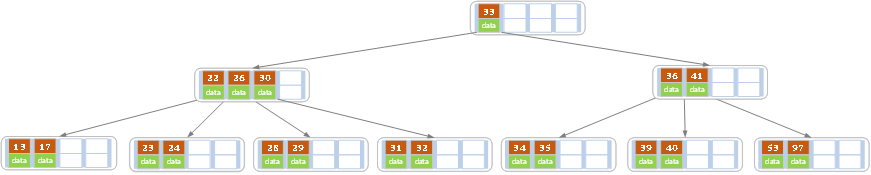
3.删除叶子节点,如果删除后,叶子节点的元素数量小于(m/2)-1,且兄弟节点没有富裕,等于(m/2)-1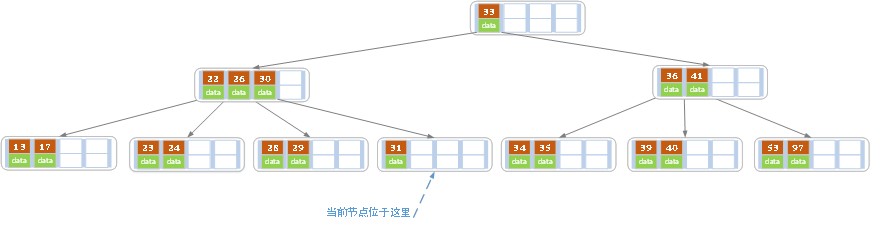
将本叶子节点跟,兄弟节点合并,成为一个新的叶子节点,并删除父节点中的元素,指向新的节点
如果父节点数量不够,需要再次循环执行,直到符合规范,

若有收获,就点个赞吧
0 人点赞
