1.更新操作
1.1 Insert操作
对于新增操作,
create_time,update_time,deleted ,version字段会自动填充。
merchant_code,tenant_id,dept_id,create_by,update_by,在用户登陆的情况下,会自动填充
1.2 update操作
1.2.1 id更新
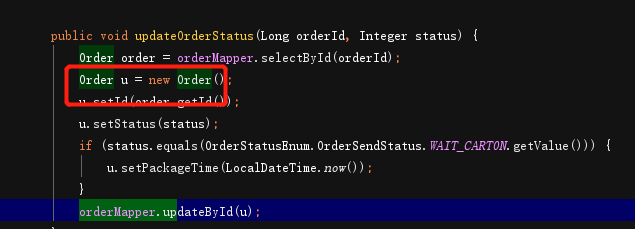
数据表更新,只更新需要的字段,不允许行记录更新数据。
此时的版本信息version字段无效(version是针对乐观锁而设计的字段信息)。
1.2.2 LambdaQueryWrapper查询条件更新
此更新,若使用乐观锁,查询条件需要传入查询出的version信息。若更新成功,version会自动+1。
1.3 delete操作
1.3.1 物理删除
调用mapper中的physicalDeleteById方法,此方法有基础框架自动生成。
/*** 物理删除表中记录** @param id 表主键* @return*/@Delete("delete from system_operation_log where id=#{id}")int physicalDeleteById(@Param("id") Long id);
物理删除仅适合数据量增长较快,且与业务无关的记录。比如:定时任务的执行计划
1.3.2 逻辑删除
逻辑删除,正常调用mybatis-plus提供的delete方法即可。
2 查询操作
2.1 分页查询
默认分页查询最大查询记录行数pageSize为100,当pageSize > 100时,系统会自动设置 pageSize=100.
特殊应用场景下,可通过以下配置修改pageSize默认最大值。
##设置分页查询,最大100条限制功能,默认100条mybatis-plus.max-limit=100
2.2 批量查询
CoreBaseMapper中定义里了limit方法,直接调用接口中的方法即可。
limit方法对条数做了限制,最大100。
如果要不限制,请使用limitNotRecommended方法
public interface CoreBaseMapper<T> extends BaseMapper<T> {T getByPrimaryForUpdate(Serializable id);default String limit(int num) {return num > 100 ? "limit 100" : "limit " + num;}default String limitNotRecommended(int num) {return "limit " + num;}}
使用方法
//对查询记录限制为100lambdaQueryWrapper.last(xxxMapper.limit(120));//不对查询记录限制为100,实际仍为120lambdaQueryWrapper.last(xxxMapper.limitNotRecommended(120));
对于确实需要查询大量数据作为计算条件的查询,可以将查询分片计算。
//按每50个一组分割List<List<User>> parts = Lists.partition(users, 50);parts.stream().forEach(list -> {process(list);})
2.3 查询返回列
Repository中,对于所有直接查DB的操作,都应要求添加查询返回列参数。
例如:
/*** 根据条件分页查SystemTaskNotify源信息** @param systemTaskNotify 查询条件* @param pageIndex 页码* @param pageSize 页记录行数* @param columns 查询字段列表* @return SystemTaskNotify分页信息*/public IPage<SystemTaskNotify> page(SystemTaskNotify systemTaskNotify, long pageIndex, long pageSize, List<String> columns) {Page page = new Page(pageIndex, pageSize);LambdaQueryWrapper<SystemTaskNotify> lambdaQueryWrapper = new LambdaQueryWrapper<>();initSelectCondition(lambdaQueryWrapper, systemTaskNotify);lambdaQueryWrapper.ne(SystemTaskNotify::getId, 100L);initSelectColumn(lambdaQueryWrapper, columns);Page selectPage = systemTaskNotifyMapper.selectPage(page, lambdaQueryWrapper);return selectPage;}
此方法内部调用了initSelectColumn方法,会设置查询的返回列表字段,initSelectColumn的实现如下:
/*** 设置sql查询项** @param queryWrapper LambdaQueryWrapper* @param columns 待查询属性列表*/private void initSelectColumn(LambdaQueryWrapper<SystemTaskNotify> queryWrapper, List<String> columns) {if (CollectionUtils.isEmpty(columns)) {return;}List<SFunction<SystemTaskNotify, ?>> columnsTemp = selectColumnsFilter(columns.contains("id") ? SystemTaskNotify::getId : null,columns.contains("bizType") ? SystemTaskNotify::getBizType : null,columns.contains("notifyId") ? SystemTaskNotify::getNotifyId : null,columns.contains("nextTime") ? SystemTaskNotify::getNextTime : null,columns.contains("status") ? SystemTaskNotify::getStatus : null,columns.contains("executeTimes") ? SystemTaskNotify::getExecuteTimes : null,columns.contains("context") ? SystemTaskNotify::getContext : null,columns.contains("createDate") ? SystemTaskNotify::getCreateDate : null,columns.contains("version") ? SystemTaskNotify::getVersion : null,columns.contains("createBy") ? SystemTaskNotify::getCreateBy : null,columns.contains("createTime") ? SystemTaskNotify::getCreateTime : null,columns.contains("updateBy") ? SystemTaskNotify::getUpdateBy : null,columns.contains("updateTime") ? SystemTaskNotify::getUpdateTime : null);SFunction<SystemTaskNotify, ?>[] col = new SFunction[columnsTemp.size()];for (int i = 0; i < columnsTemp.size(); i++) {col[i] = columnsTemp.get(i);}queryWrapper.select(col);}
selectColumnsFilter为框架提供的字段过滤方法。
Repository中默认生成了表包含字段,方便快速构建返回列
private void selectConditionSample() {List<String> columns = new ArrayList<>();columns.add("id");columns.add("bizType");columns.add("notifyId");columns.add("nextTime");columns.add("status");columns.add("executeTimes");columns.add("context");columns.add("createDate");columns.add("version");columns.add("createBy");columns.add("createTime");columns.add("updateBy");columns.add("updateTime");columns.add("deleted");}
2.4缓存数据查询
缓存数据查询,最好是全字段查询,即columns传null即可,这样缓存数据会比较全,减少不必要的二次查询。

若有收获,就点个赞吧
0 人点赞
