前言
ECMAScript 简介
ES 的全称是 ECMAScript,是 JS 的语言标准,它是由 ECMA 国际标准化组织 制定的一套脚本语言的标准化规范。
ECMAScript 重要版本发布记录:
- 1995 年:ECMAScript 诞生。
- 1997 年:ECMAScript 标准确立。推出浏览器标准语言 ECMAScript 1.0。
- 1999 年:发布 ES3;与此同时,IE5 风靡一时。
- 2009 年:发布 ECMAScript 5.0(简称 ES5)。例如 foreach、Object.keys、Object.create 和 json 标准。
- 2011 年:发布 ECMAScript5.1,成为 ISO 国际标准,从而推动所有浏览器都支持。
- 2015年 6 月:发布 ECMAScript 6(简称 ES6),即 ECMAScript 2015。
- ES6 的后续版本,请尽量用 年份 来命名。
- 2016 年 6 月:发布 ECMAScript 7,即 ECMAScript 2016。
- 2017 年 6 月:发布 ECMAScript 8,即 ECMAScript 2017。
- 2018 年 6 月:发布 ECMAScript 9,即 ECMAScript 2018。
- 2019 年 6 月:发布 ECMAScript 10,即 ECMAScript 2019。
- 2020 年 6 月:发布 ECMAScript 11,即 ECMAScript 2020。
ES6 简介
从上面的 ES 的版本记录可以看出:2015 年 6 月,ES6 正式发布。如果用年份来命名版本号,也可以称之为 ES2015。
ES6 是新的 JS 语法标准。ES6 实际上是一个泛指,泛指 ES 2015 及后续的版本。
很多人在做业务选型的时候,会倾向现在主流的框架 Vue.js 和 React.js,这些框架的默认语法,都是用的 ES6。
ES6 的改进如下:
- ES6 之前的变量提升,会导致程序在运行时有一些不可预测性。而 ES6 中通过 let、const 变量优化了这一点。
- ES6 增加了很多功能,比如:常量、作用域、对象代理、异步处理、类、继承等。这些在 ES5 中想实现,比较复杂,但是 ES6 对它们进行了封装。
- ES6 之前的语法过于松散,实现相同的功能,不同的人可能会写出不同的代码。
ES6 的目标是:让 JS 语言可以编写复杂的大型应用程序,成为企业级开发语言。
推荐阅读链接:
- 阮一峰 | ES6 入门教程:https://es6.ruanyifeng.com/
浏览器兼容性情况
关于 ECMAScript各个版本的浏览器兼容性情况,可以看看 Juriy Zaytsev 统计的兼容性表格:https://kangax.github.io/compat-table/es5/
ES5的兼容性是比较好的,ES6在IE 11浏览器里就不兼容。
将ES6的语法转为ES5
如果我们想在ES5环境中支持ES6的API,可以通过 ES5-shim 这样的工具来实现,或者在我们上一章文章《Vue 框架入门》里使用 Babel 来处理。
Babel 的作用是将 ES6 语法转为 ES5 语法,支持低端浏览器。
这里配置环境的过程就不再多阐述。
ES5中的严格模式
为什么在讲ES6之前,我们需要先了解ES5?因为很多人就是在学习ES6的过程中,才接触到es5这个概念。
我们知道,JS的语法是非常灵活的,比如说,我们随便写一个变量x,这个变量其实是挂在 windows下面的。这种灵活性在有些情况下,反而是一种缺点,造成了全局污染。
因此,ES5还引入了一种严格的运行模式:”严格模式”(strict mode)。
顾名思义,严格模式使得 Javascript 在更严格的语法条件下运行。限制性更强,也更安全。
针对整个文件:将use strict放在文件的第一行,则整个文件将以严格模式运行 ,
针对单个函数:将use strict放在函数体的第一行,则整个函数以严格模式运行。
严格模式下语法和行为改变:
- 必须用var声明变量
- 禁止自定义的函数中的this指向window
- 创建eval作用域
- 对象不能有重名的属性
严格模式和普通模式有不同的区别,如果想了解更多,可以查阅
ES6 语法
let / const
ES5 中,使用 var 定义变量( var 是 variable 的简写)。
ES6 中,新增了 let 和 const 来定义变量:
console.log(a); //这里的 a,指的是 区块 里的 a
上方代码是可以输出结果的,输出结果为 1。因为 var 是全局声明的,所以,即使是在区块里声明,但仍然在全局起作用。<br />也就是说:**使用 var 声明的变量不具备块级作用域特性**。再来看下面这段代码:```javascriptvar a = 1;{var a = 2;}console.log(a); //这里的 a,指的是 区块 里的 a
上方代码的输出结果为 2 ,因为 var 是全局声明的。
总结:
ES5语法中,用 var 定义的变量,容易造成全局污染(污染整个 js 的作用域)。如果不考虑浏览器的兼容性,我们在今后的实战中,尽量避免使用 var 定义变量,尽量用接下来要讲的ES6语法。
let:定义变量
举例 1:
{let a = 'hello';}console.log(a); // 打印结果报错:Uncaught ReferenceError: a is not defined
上方代码,打印报错。
举例 2:
var a = 2;{let a = 3;}console.log(a); // 打印结果:2
通过上面两个例子可以看出,用块级作用域内, 用let 声明的变量,只在局部起作用。
经典面试题:
let 可以防止数据污染,我们来看下面这个 for 循环的经典面试题。
1、用 var 声明变量:
for (var i = 0; i < 10; i++) {console.log('循环体中:' + i);}console.log('循环体外:' + i);
上方代码的最后一行可以正常打印结果,且最后一行的打印结果是 10。说明循环体外定义的变量 i,是全局作用域下的 i。
2、用 let 声明变量:
for (let i = 0; i < 10; i++) {console.log('循环体中:' + i); // // 每循环一次,就会在 { } 所在的块级作用域中,重新定义一个新的变量 i}console.log('循环体外:' + i);
上方代码的关键在于:每次循环都会产生一个块级作用域,每个块级作用域中会重新定义一个新的变量 i。
另外,上方代码的最后一行,打印会报错。因为用 let 定义的变量 i,只在{ }这个块级作用域里生效。
总结:我们要习惯用 let 声明,减少 var 声明带来的污染全局空间。
为了进一步强调 let 不会带来污染,需要说明的是:当我们定义了let a = 1时,如果我们在同一个作用域内继续定义let a = 2,是会报错的。
const:定义常量
在程序开发中,有些变量是希望声明后,在业务层就不再发生变化,此时可以用 const 来定义常量。常量就是值(内存地址)不能变化的量。
举例:
const name = 'smyhvae'; //定义常量
用 const 声明的常量,只在局部(块级作用域内)起作用;而且,用 const 声明常量时,必须赋值,否则报错。
let 和 const 的特点【重要】
- 不属于顶层对象 Window
- 不允许重复声明
- 不存在变量提升
- 暂时性死区
- 支持块级作用域
相反, 用var声明的变量:存在变量提升、可以重复声明、没有块级作用域。
var/let/const 的共同点
- 全局作用域中定义的变量,可以在函数中使用。
- 函数中声明的变量,只能在函数及其子函数中使用,外部无法使用。
for 循环举例(经典案例)
代码 1、我们先来看看如下代码:(用 var 定义变量 i)
<!DOCTYPE html><html lang=""><head><meta /><meta /><meta /><title>Document</title></head><body><input type="button" value="aa" /><input type="button" value="bb" /><input type="button" value="cc" /><input type="button" value="dd" /><script>var myBtn = document.getElementsByTagName('input');for (var i = 0; i < myBtn.length; i++) {myBtn[i].onclick = function () {alert(i);};}</script></body></html>
上方代码中的运行效果如下: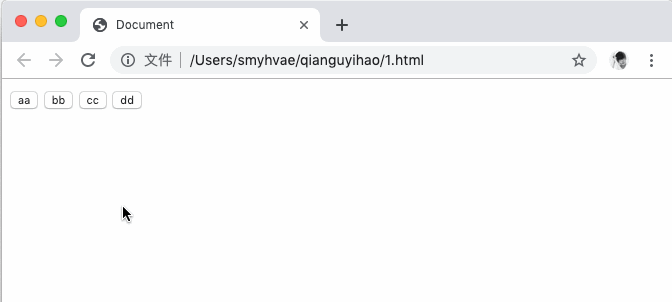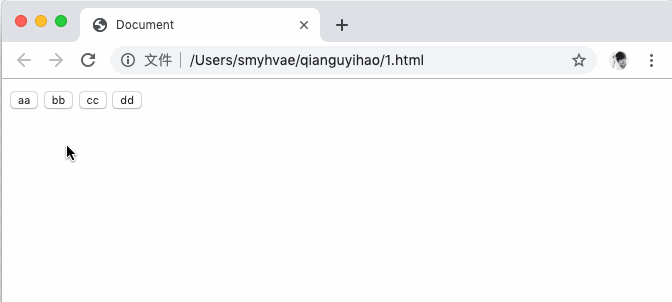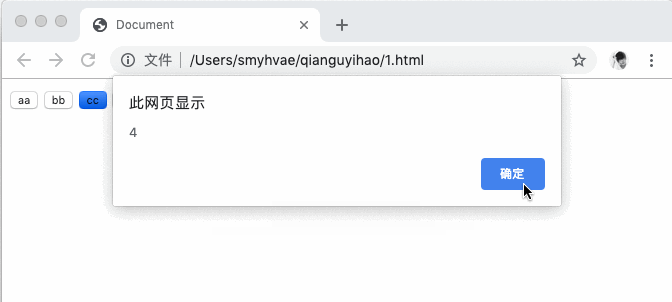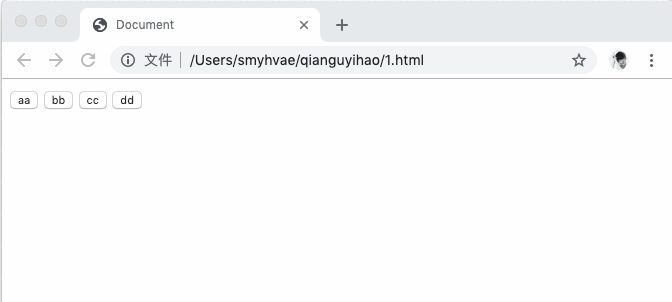
你可能会感到诧异,为何点击任何一个按钮,弹出的内容都是 4 呢?这是因为,我们用 var 定义的变量 i,是在全局作用域声明的。整个代码中,自始至终只有一个变量。
for 循环是同步代码,而 onclick 点击事件是异步代码。当我们还没点击按钮之前,同步代码已经执行完了,变量 i 已经循环到 4 了。
也就是说,上面的 for 循环,相当于如下代码:
var i = 0;myBtn[0].onclick = function () {alert(i);};i++;myBtn[1].onclick = function () {alert(i);};i++;myBtn[2].onclick = function () {alert(i);};i++;myBtn[3].onclick = function () {alert(i);};i++; // 到这里,i 的值已经是4了。因此,当我们点击按钮时,i的值一直都是4
代码 2、上面的代码中,如果我们改为用 let 定义变量 i:
<!DOCTYPE html><html lang=""><head><meta /><meta /><meta /><title>Document</title></head><body><input type="button" value="aa" /><input type="button" value="bb" /><input type="button" value="cc" /><input type="button" value="dd" /><script>var myBtn = document.getElementsByTagName('input');for (let i = 0; i < myBtn.length; i++) {myBtn[i].onclick = function () {alert(i);};}</script></body></html>
上方代码中的运行效果如下: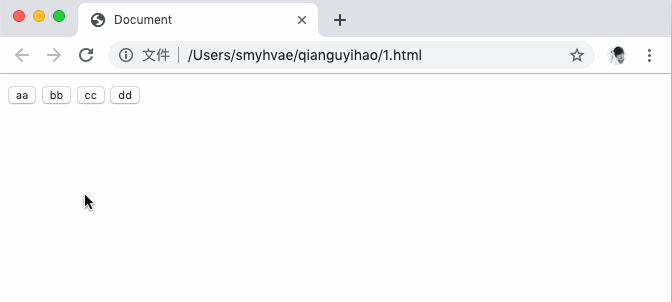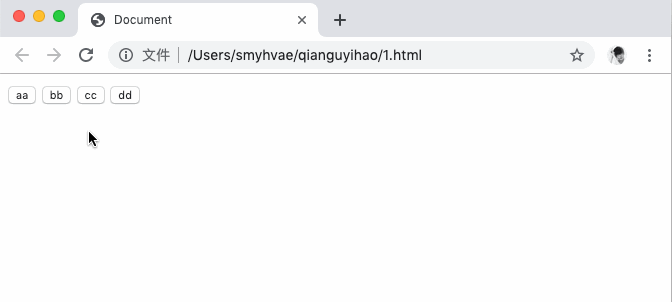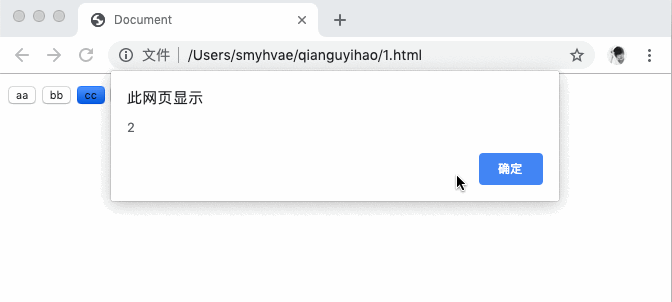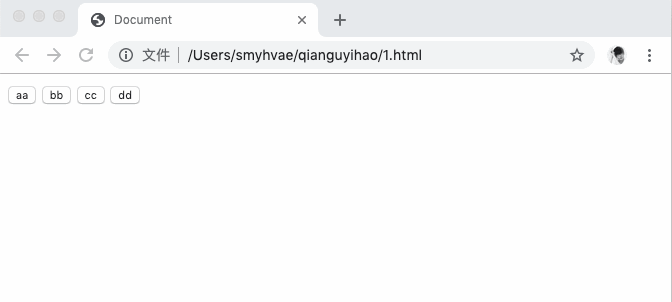
上面这个运行结果,才是我们预期的效果。我们用 let 定义变量 i,在循环的过程中,每执行一次循环体,就会诞生一个新的 i。循环体执行 4 次,就会有四个 i。
暂时性死区 DTC
ES6 规定:使用 let/const 声明的变量,会使区块形成封闭的作用域。若在声明之前使用变量,就会报错。
也就是说,在使用 let/const 声明变量时,变量需要先声明,再使用(声明语句必须放在使用之前)。这在语法上,称为 “暂时性死区”( temporal dead zone,简称 TDZ)。
DTC 其实是一种保护机制,可以让我们养成良好的编程习惯。
代码举例:
const name = '前端修炼';function foo() {console.log(name);const name = 'hello';}foo(); // 执行函数后,控制台报错:Uncaught ReferenceError: Cannot access 'name' before initialization
ES5 中如何定义常量
ES5中有Object.defineProperty这样一个api,可以定义常量。这个API中接收三个参数。
代码举例:
// 定义常量 PIObject.defineProperty(window, 'PI', {value: 3.14,writable: false,});console.log(PI); // 打印结果:3.14PI = 6; //尝试修改常量console.log(PI); //打印结果:3.14,说明修改失败
总结:var/let/const 的区别
1、var 声明的变量会挂载在 window 对象上,而 let 和 const 声明的变量不会
举例:
var a = '我是a';console.log(a); // 打印结果:我是aconsole.log(window.a); // 打印结果:我是a
let b = '我是b';console.log(b); // 打印结果:我是bconsole.log(window.b); // 打印结果:undefined
let c = '我是c';console.log(c); // 打印结果:我是cconsole.log(window.c); // 打印结果:undefined
var 的这一特性,会造成 window 全局变量的污染。举例如下:
var innerHeight = 100;console.log(window.innerHeight); // 打印结果:永远都是100 ==> 会覆盖 window 自带的 innerHeight 属性
2、var 声明的变量存在变量提升,let 和 const 声明的变量不存在变量提升
举例:(先使用,再声明)
console.log(a); // 打印结果:undefined ==> a已经声明但没有赋值var a = '我是a';
console.log(b); // 报错:Uncaught ReferenceError: Cannot access 'b' before initialization ==> 找不到b这个变量let b = '我是b';
console.log(c); // 报错:Uncaught ReferenceError: Cannot access 'c' before initialization ==> 找不到c这个变量const c = '我是c';
3、var 声明不存在块级作用域,let 和 const 声明存在块级作用域
举例:
{var a = '我是a';let b = '我是b';const c = '我是c';}console.log(a); // 我是aconsole.log(b); // 报错:Uncaught ReferenceError: b is not defined ==> 找不到b这个变量console.log(c); // 报错:Uncaught ReferenceError: c is not defined ==> 找不到c这个变量
4、同一作用域下,var 可以重复声明变量,let 和 const 不能重复声明变量
var a = '我是a';var a = 'qianduanxiulian';console.log(a); // 打印结果:qianduanxiulian
let b = '我是b';let b = 'qianduanxiulian';console.log(b); //报错:Uncaught SyntaxError: Identifier 'b' has already been declared ==> 变量 b 已经被声明了
const c = '我是c';const c = 'qianduanxiulian';console.log(c); //报错:Uncaught SyntaxError: Identifier 'c' has already been declared ==> 变量 c 已经被声明了
备注:通过第3、第4点可以看出:使用 let/const 声明的变量,不会造成全局污染。
5、let 和 const 的暂时性死区(DTC)
举例 1:(表现正常)
const name = 'qianduanxiulian';function foo() {console.log(name);}foo(); // 执行函数后,打印结果:qianduanxiulian
上方例子中, 变量 name 被声明在函数外部,此时函数内部可以直接使用。
举例 2:(报错)
const name = 'qianduanxiulian';function foo() {console.log(name);const name = 'hello';}foo(); // 执行函数后,控制台报错:Uncaught ReferenceError: Cannot access 'name' before initialization
代码解释:如果在当前块级作用域中使用了变量 name,并且当前块级作用域中通过 let/const 声明了这个变量,那么,声明语句必须放在使用之前,也就是所谓的 DTC(暂时性死区)。DTC 其实是一种保护机制,可以让我们养成良好的编程习惯。
6、const:一旦声明必须赋值;声明后不能再修改
一旦声明必须赋值:
const a;console.log(a); // 报错:Uncaught SyntaxError: Missing initializer in const declaration
基于上面的种种区别,我们可以知道:var 声明的变量,很容易造成全局污染。以后我们尽量使用 let 和 const 声明变量吧。
const 常量到底能不能被修改
我们知道:用 const 声明的变量无法被修改。但还有一点,我们一定要记住:
- 如果用 const 声明基本数据类型,则无法被修改;
- 如果用 const 声明引用数据类型(即“对象”),这里的“无法被修改”指的是不能改变内存地址的引用;但对象里的内容是可以被修改的。
举例 1:(不能修改)
const name = 'qianduanxiulian';name = 'vae'; // 因为无法被修改,所以报错:Uncaught TypeError: Assignment to constant variable
举例 2:(不能修改)
const obj = {name: 'qianduanxiulian',age: 28,};obj = { name: 'vae' }; // 因为无法被修改,所以报错:Uncaught TypeError: Assignment to constant variable
举例 3:(可以修改)
const obj = {name: 'qianguyihao',age: 28,};obj.name = 'vae'; // 对象里的 name 属性可以被修改
因为 变量名 obj 是保存在栈内存中的,它代表的是对象的引用地址,它是基本数据类型,无法被修改。
但是 obj 里面的内容是保存在堆内存中的,它是引用数据类型,可以被修改。
箭头函数
ES6 在函数扩展方面,新增了很多特性。例如:
- 箭头函数
- 参数默认值
- 参数结构赋值
- 剩余参数
- 扩展运算符
- this 绑定
- 尾调用
箭头函数
定义箭头函数的语法
语法:
(参数1, 参数2 ...) => { 函数体 }
解释:
- 如果有且仅有 1 个形参,则
()可以省略 - 如果函数体内有且仅有 1 条语句,则
{}可以省略,但前提是,这条语句必须是 return 语句。
需要强调的是,箭头函数是没有函数名的,既然如此,那要怎么调用箭头函数呢?你可以将箭头函数赋值给一个变量,通过变量名调用函数;也可以直接使用箭头函数。我们来看看下面的例子。
举例
写法 1、定义和调用函数:(传统写法)
function fn1(a, b) {console.log('haha');return a + b;}console.log(fn1(1, 2)); //输出结果:3
写法 2、定义和调用函数:(ES6 中的写法)
const fn2 = (a, b) => {console.log('haha');return a + b;};console.log(fn2(1, 2)); //输出结果:3
上面的两种写法,效果是一样的。
从上面的箭头函数中,我们可以很清晰地看到变量名、参数名、函数体。
另外,箭头函数的写法还可以精简一下,继续往下看。
在箭头函数中,如果方法体内只有一句话,且这句话是 return 语句,那就可以把 {}省略。写法如下:
const fn2 = (a, b) => a + b;console.log(fn2(1, 2)); //输出结果:3
在箭头函数中,如果形参只有一个参数,则可以把()省略。写法如下:
const fn2 = (a) => {console.log('haha');return a + 1;};// 等同于const fn2 = a => {console.log('haha');return a + 1;};console.log(fn2(1)); //输出结果:2
箭头函数的 this 的指向
箭头函数只是为了让函数写起来更简洁优雅吗?当然不只是这个原因,还有一个很大的作用是与 this 的指向有关。
ES6 之前的普通函数中:this 指向的是函数被调用的对象(也就是说,谁调用了函数,this 就指向谁)。
而 ES6 的箭头函数中:箭头函数本身不绑定 this,this 指向的是箭头函数定义位置的 this(也就是说,箭头函数在哪个位置定义的,this 就跟这个位置的 this 指向相同)。
代码举例:
const obj = { name: '前端修炼手册' };function fn1() {console.log(this); // 第一个 thisreturn () => {console.log(this); // 第二个 this};}const fn2 = fn1.call(obj);fn2();
打印结果:
objobj
代码解释:(一定要好好理解下面这句话)
上面的代码中,箭头函数是在 fn1()函数里面定义的,所以第二个 this 跟 第一个 this 指向的是同一个位置。又因为,在执行 fn1.call(obj)之后,第一个 this 就指向了 obj,所以第二个 this 也是指向 了 obj。
经典题:箭头函数的 this 指向
代码举例:
var name = '新人';var obj = {name: '前端修炼',sayHello: () => {console.log(this.name);},};obj.sayHello();
上方代码的打印结果是什么?你可能很难想到。
正确答案的打印结果是新人。因为 obj 这个对象并不产生作用域, sayHello() 这个箭头函数实际仍然是定义在 window 当中的,所以 这里的 this 指向是 window。
参数默认值
传统写法:
function fn(param) {let p = param || 'hello';console.log(p);}
上方代码中,函数体内的写法是:如果 param 不存在,就用 hello字符串做兜底。这样写比较啰嗦。
ES6 写法:(参数默认值的写法,很简洁)
function fn(param = 'hello') {console.log(param);}
在 ES6 中定义方法时,我们可以给方法里的参数加一个默认值(缺省值):
- 方法被调用时,如果没有给参数赋值,那就是用默认值;
- 方法被调用时,如果给参数赋值了新的值,那就用新的值。
如下:
var fn2 = (a, b = 5) => {console.log('haha');return a + b;};console.log(fn2(1)); //第二个参数使用默认值 5。输出结果:6console.log(fn2(1, 8)); //输出结果:9
提醒 1:默认值的后面,不能再有没有默认值的变量。
比如(a,b,c)这三个参数,如果我给 b 设置了默认值,那么就一定要给 c 设置默认值。
提醒 2:
我们来看下面这段代码:
let x = 'smyh';function fn(x, y = x) {console.log(x, y);}fn('vae');
注意第二行代码,我们给 y 赋值为x,这里的x是括号里的第一个参数,并不是第一行代码里定义的x。打印结果:vae vae。
如果我把第一个参数改一下,改成:
let x = 'smyh';function fn(z, y = x) {console.log(z, y);}fn('vae');
此时打印结果是:vae smyh。
避免使用箭头函数的几个情况
1.使用箭头函数定义对象的方法
// badlet foo = {value: 1,getValue: () => console.log(this.value)}foo.getValue(); // undefined
我们在上面已经经过 因为 foo 这个对象并不产生作用域, getValue() 这个箭头函数实际仍然是定义在 window 当中的,所以 这里的 this 指向是 window。
2.定义原型方法
// badfunction Foo() {this.value = 1}Foo.prototype.getValue = () => console.log(this.value)let foo = new Foo()foo.getValue(); // undefined
3.作为事件的回调函数
// badconst button = document.getElementById('myButton');button.addEventListener('click', () => {console.log(this === window); // => truethis.innerHTML = 'Clicked button';});
解构赋值
解构赋值:ES6 允许我们,按照一一对应的方式,从数组或者对象中提取值,再将提取出来的值赋值给变量。
解构:分解数据结构;赋值:给变量赋值。
解构赋值在实际开发中可以大量减少我们的代码量,并且让程序结构更清晰。
数组的解构赋值
数组的结构赋值:将数组中的值按照位置提取出来,然后赋值给变量。
语法
在 ES6 之前,当我们在为一组变量赋值时,一般是这样写:
var a = 1;var b = 2;var c = 3;
或者是这样写:
var arr = [1, 2, 3];var a = arr[0];var b = arr[1];var c = arr[2];
现在有了 ES6 之后,我们可以通过数组解构的方式进行赋值:(根据位置进行一一对应)
let [a, b, c] = [1, 2, 3];
二者的效果是一样的,但明显后者的代码更简洁优雅。
未匹配到的情况
数据的结构赋值,是根据位置进行一一对应来赋值的。可如果左边的数量大于右边的数量时(也就是变量的数量大于值的数量时),多余的变量要怎么处理呢?
答案是:如果变量在一一对应时,没有找到对应的值,那么,多余的变量会被赋值为 undefined。
解构时,左边允许有默认值
在解构赋值时,是允许使用默认值的。举例如下:
{//一个变量时let [foo = true] = [];console.log(foo); //输出结果:true}{//两个变量时let [a, b] = ['前端修炼']; //a 赋值为:前端修炼。b没有赋值console.log(a + ',' + b); //输出结果:前端修炼,undefined}{//两个变量时let [a, b = 'qianduanxiulian'] = ['前端修炼']; //a 赋值为:前端修炼。b 采用默认值 qianduanxiulianconsole.log(a + ',' + b); //输出结果:前端修炼,qianduanxiulian}
将右边的 undefined和null赋值给变量
如果我们在赋值时,采用的是 undefined或者null,那会有什么区别呢?
{let [a, b = 'qianduanxiulian'] = ['前端修炼', undefined]; //b 虽然被赋值为 undefined,但是 b 会采用默认值console.log(a + ',' + b); //输出结果:前端修炼,qianduanxiulian}{let [a, b = 'qianduanxiulian'] = ['前端修炼', null]; //b 被赋值为 nullconsole.log(a + ',' + b); //输出结果:前端修炼,null}
上方代码分析:
- undefined:相当于什么都没有,此时 b 采用默认值。
- null:相当于有值,但值为 null。
对象的解构赋值
对象的结构赋值:将对象中的值按照属性匹配的方式提取出来,然后赋值给变量。
语法
在 ES6 之前,我们从接口拿到 json 数据后,一般这么赋值:
var name = json.name;var age = json.age;var sex = json.sex;
上面这种写法,过于麻烦了。
现在,有了 ES6 之后,我们可以使用对象解构的方式进行赋值。举例如下:
const person = { name: 'qianduanxiulian', age: 28, sex: '男' };let { name, age, sex } = person; // 对象的结构赋值console.log(name); // 打印结果:qianduanxiulianconsole.log(age); // 打印结果:28console.log(sex); // 打印结果:男
上方代码可以看出,对象的解构与数组的结构,有一个重要的区别:数组的元素是按次序排列的,变量的取值由它的位置决定;而对象的属性没有次序,是根据键来取值的。
未匹配到的情况
对象的结构赋值,是根据属性名进行一一对应来赋值的。可如果左边的数量大于右边的数量时(也就是变量的数量大于值的数量时),多余的变量要怎么处理呢?
答案是:如果变量在一一对应时,没有找到对应的值,那么,多余的变量会被赋值为 undefined。
给左边的变量自定义命名
对象的结构赋值里,左边的变量名一定要跟右边的属性名保持一致么?答案是不一定。我们可以单独给左边的变量自定义命名。
举例如下:
const person = { name: 'qianduanxiulian', age: 28 };let { name: myName, age: myAge } = person; // 对象的结构赋值console.log(myName); // 打印结果:qianduanxiulianconsole.log(myAge); // 打印结果:28console.log(name); // 打印报错:Uncaught ReferenceError: name is not definedconsole.log(age); // 打印报错:Uncaught ReferenceError: age is not defined
上方的第 2 行代码中:(请牢记)
- 等号左边的属性名 name、age 是对应等号右边的属性名。
- 等号左边的 myName、myAge 是左边自定义的变量名。
或者,我们也可以理解为:将右边 name 的值赋值给左边的 myName 变量,将右边 age 的值赋值给左边的 myAge 变量。现在,你应该一目了然了吧?
圆括号的使用
如果变量 foo 在解构之前就已经定义了,此时你再去解构,就会出现问题。下面是错误的代码,编译会报错:
let foo = 'haha';{ foo } = { foo: 'smyhvae' };console.log(foo);
要解决报错,只要在解构的语句外边,加一个圆括号即可:
let foo = 'haha';({ foo } = { foo: 'smyhvae' });console.log(foo); // 输出结果:smyhvae
对象属性简写
es6允许当对象的属性和值相同时,省略属性名
比如:
let x = 0let obj = {x // 省略的x:}
需要注意的是
- 省略的是属性名而不是值
- 值必须是一个变量
对象属性简写与解构赋值经常一起使用
let bar = () => ({x:4, y:5, z:6})let {x:x, y:y, z:z} = bar()// 简写为let {x, y, z} = bar()console.log(x); // 输出结果:4console.log(y); // 输出结果:5console.log(z); // 输出结果:6
上方代码的解构赋值,这里的代码会其实是声明了x,y,z变量,因为bar函数会返回一个对象,这个对象有x,y,z这3个属性,解构赋值会寻找等号右边表达式的x,y,z属性,找到后赋值给声明的x,y,z变量。
字符串解构
字符串也可以解构,这是因为,此时字符串被转换成了一个类似数组的对象。举例如下:
const [a, b, c, d] = 'hello';console.log(a);console.log(b);console.log(c);console.log(typeof a); //输出结果:string
打印结果:
helstring
剩余参数/扩展运算符
剩余参数
剩余参数允许我们将不确定数量的剩余的元素放到一个数组中。
比如说,当函数的实参个数大于形参个数时,我们可以将剩余的实参放到一个数组中。
传统写法:
ES5 中,在定义方法时,参数要确定个数,如下:(程序会报错)
function fn(a, b, c) {console.log(a);console.log(b);console.log(c);console.log(d);}fn(1, 2, 3);
上方代码中,因为方法的参数是三个,但使用时是用到了四个参数,所以会报错: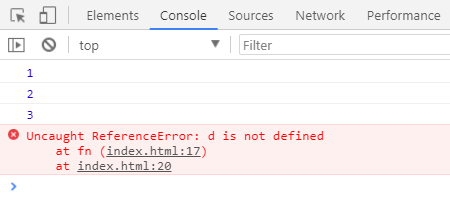
ES6 写法:
ES6 中,我们有了剩余参数,就不用担心报错的问题了。代码可以这样写:
const fn = (...args) => {//当不确定方法的参数时,可以使用剩余参数console.log(args[0]);console.log(args[1]);console.log(args[2]);console.log(args[3]);};fn(1, 2);fn(1, 2, 3); //方法的定义中了四个参数,但调用函数时只使用了三个参数,ES6 中并不会报错。
打印结果:
12undefinedundefined123undefined
上方代码中注意,args 参数之后,不能再加别的参数,否则编译报错。
下面这段代码,也是利用到了剩余参数:
function fn1(first, ...args) {console.log(first); // 10console.log(args); // 数组:[20, 30]}fn1(10, 20, 30);
剩余参数的举例:参数求和
代码举例:
const sum = (...args) => {let total = 0;args.forEach(item => total += item); // 注意 forEach里面的代码,写得 很精简return total;};console.log(sum(10, 20, 30));
剩余参数和解构赋值配合使用
代码举例:
const students = ['张三', '李四', '王五'];let [s1, ...s2] = students;console.log(s1); // '张三'console.log(s2); // ['李四', '王五']
扩展运算符(展开语法)
扩展运算符和剩余参数是相反的。
剩余参数是将剩余的元素放到一个数组中;而扩展运算符是将数组或者对象拆分成逗号分隔的参数序列。
代码举例:
const arr = [10, 20, 30];...arr // 10, 20, 30 注意,这一行是伪代码,这里用到了扩展运算符console.log(...arr); // 10 20 30console.log(10, 20, 30); // 10 20 30
上面的代码要仔细看:arr是一个数组,而...arr则表示10, 20, 30这样的序列。
我们把...arr 打印出来,发现打印结果竟然是 10 20 30,为啥逗号不见了呢?因为逗号被当作了 console.log 的参数分隔符。如果你不信,可以直接打印 console.log(10, 20, 30) 看看。
接下来,我们看一下扩展运算符的应用。
举例1:数组赋值
数组赋值的代码举例:
let arr2 = [...arr1]; // 将 arr1 赋值给 arr2
为了理解上面这行代码,我们先来分析一段代码:(将数组 arr1 赋值给 arr2)
let arr1 = ['www', 'smyhvae', 'com'];let arr2 = arr1; // 将 arr1 赋值给 arr2,其实是让 arr2 指向 arr1 的内存地址console.log('arr1:' + arr1);console.log('arr2:' + arr2);console.log('---------------------');arr2.push('你懂得'); //往 arr2 里添加一部分内容console.log('arr1:' + arr1);console.log('arr2:' + arr2);
运行结果: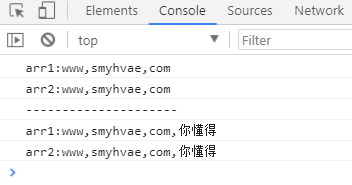
上方代码中,我们往往 arr2 里添加了你懂的,却发现,arr1 里也有这个内容。原因是:let arr2 = arr1;其实是让 arr2 指向 arr1 的地址。也就是说,二者指向的是同一个内存地址。
如果不想让 arr1 和 arr2 指向同一个内存地址,我们可以借助扩展运算符来做:
let arr1 = ['www', 'smyhvae', 'com'];let arr2 = [...arr1]; //【重要代码】arr2 会重新开辟内存地址console.log('arr1:' + arr1);console.log('arr2:' + arr2);console.log('---------------------');arr2.push('你懂得'); //往arr2 里添加一部分内容console.log('arr1:' + arr1);console.log('arr2:' + arr2);
运行结果:
arr1:www,smyhvae,comarr2:www,smyhvae,com---------------------arr1:www,smyhvae,comarr2:www,smyhvae,com,你懂得
我们明白了这个例子,就可以避免开发中的很多业务逻辑上的 bug。
举例2:合并数组
代码举例:
let arr1 = ['王一', '王二', '王三'];let arr2 = ['王四', '王五', '王六'];// ...arr1 // '王一','王二','王三'// ...arr2 // '王四','王五','王六'// 方法1let arr3 = [...arr1, ...arr2];console.log(arr3); // ["王一", "王二", "王三", "王四", "王五", "王六"]// 方法2arr1.push(...arr2);console.log(arr1); // ["王一", "王二", "王三", "王四", "王五", "王六"]
举例3:将伪数组或者可遍历对象转换为真正的数组
代码举例:
const myDivs = document.getElementsByClassName('div');const divArr = [...myDivs]; // 利用扩展运算符,将伪数组转为真正的数组
补充:
我们在 JavaScript基础 中也培训过,还有一种 方式,可以将伪数组(或者可遍历对象)转换为真正的数组。语法格式如下:
let arr2 = Array.from(arrayLike);
举例4:在对象中使用扩展运算符
这个其实是ES9的语法,ES9中支持在对象中使用扩展运算符,之前说过数组的扩展运算符原理是消耗所有迭代器,但对象中并没有迭代器,可能是实现原理不同,但是仍可以理解为将键值对从对象中拆开,它可以放到另外一个普通对象中。
let obj = {a:1,b:2,c:3}let obj2 = {...obj,d:4}console.log(obj2)// { a:1, b:2, c:3, d:4}
其实和另外一个ES6新增的API相似,即Object.assign,它们都可以合并对象,但是还是有一些不同。Object.assign会触发目标对象的setter函数,而对象扩展运算符不会。
举例5:函数柯里化
function cal(a,b,c,d){return a + b * c - d;}// 利用展开运算符写柯里化function curry(func,...args){return function (...subArgs){const allArgs = [...args,...subArgs];if(allArgs.length >= func.length){// 参数够了return func(...allArgs);}else{// 参数不够,继续固定return curry(func,...allArgus);}}}// curry:柯里化:用户固定某个函数的前面的参数,const newCal = curry(cal,1,2);// 得到一个新的函数,新的函数调用时,接收剩余参数console.log(newCal(3,4));console.log(newCal(3,8));console.log(newCal(5,4));
Promise
Promise是ES6中推出的新的概念,改变了JS的异步编程,现在前端大部分的异步请求都是使用Promise实现,Axios这个web api也是基于Promise的。
我们这里只是做重要知识点整理,后续会有专门的一篇文章来详细讲解 《JavaScript 异步编程》演变过程。
回调函数
前端我们讲过基础,Javascript 是⼀⻔单线程语⾔。早期我们解决异步场景时,⼤部分情况都是通过回调函数来进⾏。
回调的定义
把函数 A 传给另一个函数 B 调用,那么函数 A 就是回调函数。
例如在浏览器中发送 ajax 请求,就是常⻅的⼀个异步场景,发送请求后,需要等待一段时间,等服务端响应之后我们才能拿到结果。如果我们希望在异步结束之后执⾏某个操作,就只能通过回调函数这样的⽅式进⾏操作。
ES5 中的传统写法:
// 封装 ajax 请求:传入回调函数 success 和 failfunction ajax(url, success, fail) {var xmlhttp = new XMLHttpRequest();xmlhttp.open('GET', url);xmlhttp.send();xmlhttp.onreadystatechange = function () {if (xmlhttp.readyState === 4 && xmlhttp.status === 200) {success && success(xmlhttp.responseText);} else {fail && fail(new Error('接口请求失败'));}};}// 执行 ajax 请求ajax('/a.json',(res) => {console.log('扣款1000元! 第一个接口请求成功:' + JSON.stringify(res));},(err) => {console.log('扣款失败! 请求失败:' + JSON.stringify(err));});
收到响应后,执行后面的回调打印字符串,但是如果这个第三方库有类似超时重试的功能,可能会执行多次你的回调函数,如果是一个支付功能,你就会发现你扣的钱可能就不止1000元了。
使用回调函数处理异步请求相当于把你的回调函数置于了一个黑盒,虽然你声明了等到收到响应后执行你提供的回调函数,可是你并不知道这个第三方库会在什么具体会怎么执行回调函数
第二个众所周知的问题就是,在回调函数中再嵌套回调函数会导致代码非常难以维护,这是人们常说的“回调地狱”
// 封装 ajax 请求:传入回调函数 success 和 failfunction ajax(url, success, fail) {var xmlhttp = new XMLHttpRequest();xmlhttp.open('GET', url);xmlhttp.send();xmlhttp.onreadystatechange = function () {if (xmlhttp.readyState === 4 && xmlhttp.status === 200) {success && success(xmlhttp.responseText);} else {fail && fail(new Error('接口请求失败'));}};}// 执行 ajax 请求ajax('/a.json',(res) => {console.log('第一个接口请求成功:' + JSON.stringify(res));// ajax嵌套调用ajax('b.json', (res) => {console.log('第二个接口请求成功:' + JSON.stringify(res));// ajax嵌套调用ajax('c.json', (res) => {console.log('第三个接口请求成功:' + JSON.stringify(res));});});},(err) => {console.log('请求失败:' + JSON.stringify(err));});
如果多个异步函数存在依赖关系(比如,需要等第一个异步函数执行完成后,才能执行第二个异步函数;等第二个异步函数执行完毕后,才能执行第三个异步函数),就需要多个异步函数进⾏层层嵌套。
⾮常不利于后续的维护,而且会导致回调地狱的问题。失败的一些错误信息可能会被吞掉,而你确完全不知情。
总结一下回调函数的一些缺点:
- 多重嵌套,导致回调地狱
- 代码跳跃,并非人类习惯的思维模式
- 信任问题,你不能把你的回调完全寄托与第三方库,因为你不知道第三方库到底会怎么执行回调(多次执行)
- 第三方库可能没有提供错误处理
- 不清楚回调是否都是异步调用的(可以同步调用ajax,在收到响应前会阻塞整个线程,会陷入假死状态,非常不推荐)
为了能使回调函数以更优雅的⽅式进⾏调⽤,在 ES6 语法中,新增了⼀个名为 Promise 的新规范。
使用 Promise
ES6 中的 Promise 是异步编程的一种方案。
Promise是一个构造函数,通过new关键字创建一个Promise的实例,我们一起来看看Promise是怎么解决回调函数的这些问题的。
// 创建 promise 实例let promise = new Promise((resolve, reject) => {//进来之后,状态为pendingconsole.log('同步代码'); //这行代码是同步的//开始执行异步操作(这里开始,写异步的代码,比如ajax请求 or 开启定时器)if (异步的ajax请求成功) {console.log('333');resolve('请求成功,并传参'); //如果请求成功了,请写resolve(),此时,promise的状态会被自动修改为fulfilled(成功状态)} else {reject('请求失败,并传参'); //如果请求失败了,请写reject(),此时,promise的状态会被自动修改为rejected(失败状态)}});console.log('222');//调用promise的then():开始处理成功和失败promise.then((successMsg) => {// 处理 promise 的成功状态:如果promise的状态为fulfilled,则执行这里的代码console.log(successMsg, '成功了'); // 这里的 successMsg 是前面的 resolve('请求成功,并传参') 传过来的参数},(errorMsg) => {//处理 promise 的失败状态:如果promise的状态为rejected,则执行这里的代码console.log(errorMsg, '失败了'); // 这里的 errorMsg 是前面的 reject('请求失败,并传参') 传过来的参数});
解决 1:多重嵌套,导致回调地狱
Promise在设计的时候引入了链式调用的概念,每个then方法同样也是一个Promise,因此可以无限链式调用下去
// 封装 ajax 请求:传入回调函数 success 和 failfunction ajax(url, success, fail) {var xmlhttp = new XMLHttpRequest();xmlhttp.open('GET', url);xmlhttp.send();xmlhttp.onreadystatechange = function () {if (xmlhttp.readyState === 4 && xmlhttp.status === 200) {success && success(xmlhttp.responseText);} else {fail && fail(new Error('接口请求失败'));}};}new Promise((resolve, reject) => {ajax('a.json', (res) => {console.log(res);resolve();});}).then((res) => {console.log('a成功');return new Promise((resolve, reject) => {ajax('b.json', (res) => {console.log(res);resolve();});});}).then((res) => {console.log('b成功');return new Promise((resolve, reject) => {ajax('c.json', (res) => {console.log(res);resolve();});});}).then((res) => {cnosole.log('c成功');});
上面代码中,then 是可以链式调用的,一旦 return 一个新的 promise 实例之后,后面的 then 就可以拿到前面 resolve 出来的数据。这种扁平化的写法,更方便维护;
解决2:代码跳跃,并非人类习惯的思维模式
Promise 使得能够同步思维书写代码,而书写的格式也是符合人类的思维,从先到后。
也许你可能会奇怪,上面的代码,怎么这么多?而且有不少重复。因为这里只是采用了一种笨拙的方式来写,为的是方便大家理解 promise 的执行过程。
针对同一个接口的多次嵌套调用,我们其实可以对 promise 的链式调用进行封装。
// 定义 ajax 请求:传入回调函数 success 和 failfunction ajax(url, success, fail) {var xmlhttp = new XMLHttpRequest();xmlhttp.open('GET', url);xmlhttp.send();xmlhttp.onreadystatechange = function () {if (xmlhttp.readyState === 4 && xmlhttp.status === 200) {success && success(xmlhttp.responseText);} else {fail && fail(new Error('接口请求失败'));}};}// 第一步:model层,接口封装function getPromise(url) {return new Promise((resolve, reject) => {ajax(url, (res) => {// 这里的 res 是接口的返回结果。返回码 retCode 是动态数据。if (res.retCode == 0) {// 接口请求成功时调用resolve('request success' + res);} else {// 接口请求异常时调用reject({ retCode: -1, msg: 'network error' });}});});}// 第二步:业务层的接口调用。这里的 data 就是 从 resolve 和 reject 传过来的,也就是从接口拿到的数据getPromise('a.json').then((res) => {// a 请求成功。从 resolve 获取正常结果:接口请求成功后,打印a接口的返回结果console.log(res);return getPromise('b.json'); // 继续请求 b}).then((res) => {// b 请求成功console.log(res);return getPromise('c.json'); // 继续请求 c}).then((res) => {// c 请求成功console.log(res);}).catch((e) => {// 从 reject中获取异常结果console.log(e);});
解决3:信任问题,你不能把你的回调完全寄托与第三方库,因为你不知道第三方库到底会怎么执行回调(多次执行)
Promise本身是一个状态机,具有以下3个状态:
- pending(等待)
- fulfilled(成功)
- rejected(拒绝)
当请求发送没有得到响应的时候为pending状态,得到响应后会resolve(决议)当前这个Promise实例,将它变为fulfilled/rejected(大部分情况会变为fulfilled)
当请求发生错误后会执行reject(拒绝)将这个Promise实例变为rejected状态。
一个Promise实例的状态只能从pending => fulfilled 或者从 pending => rejected,即当一个Promise实例从pending状态改变后,就不会再改变了(不存在fulfilled => rejected 或 rejected => fulfilled)
而Promise实例必须主动调用then方法,才能将值从Promise实例中取出来(前提是Promise不是pending状态),这一个“主动”的操作就是解决这个问题的关键,即第三方库做的只是改变Promise的状态,而响应的值怎么处理,这是开发者主动控制的,这里就实现了控制反转,将原来第三方库的控制权转移到了开发者上。
getPromise('a.json').then((res) => {// 主动调用then方法获取值后,用户可以自行处理})
解决4:第三方库可能没有提供错误处理
Promise的then方法会接受2个函数,第一个函数是这个Promise实例被resolve时执行的回调,第二个函数是这个Promise实例被reject时执行的回调,而这个也是开发者主动调用的
使用Promise在异步请求发送错误的时候,即使没有捕获错误,也不会阻塞主线程的代码(准确的来说,异步的错误都不会阻塞主线程的代码)。
etPromise('a.json').then((res) => {console.log(res);},(err) => {// a 请求失败console.log('a: err');}).catch((err) => {// 统一处理请求失败console.log(err);});
解决5:不清楚回调是否都是异步调用的
Promise在设计的时候保证所有响应的处理回调都是异步调用的,不会阻塞代码的执行,Promise将then方法的回调放入一个叫微任务的队列中(MicroTask),确保这些回调任务在同步任务执行完以后再执行,这部分也是事件循环的知识点。
- 在执行一个 Promise 对象的时候,当走完resolve();之后,就会立刻把 .then()里面的代码加入到微任务队列当中。
- 任务的一般执行顺序:同步任务 —> 微任务 —> 宏任务。 ```javascript setTimeout(() => { // 宏任务 console.log(‘setTimeout’); }, 0);
new Promise((resolve, reject) => { resolve(); console.log(‘promise1’); // 同步任务 }).then((res) => { // 微任务 console.log(‘promise then’); });
console.log(‘qianguyihao’); // 同步任务
上方代码执行的顺序依次是:同步任务 --> 微任务 --> 宏任务。<a name="dfHmq"></a>#### Async Await 函数在日常开发中,建议全面拥抱新的Promise语法,现在的异步编程基本也都使用的是Promise。<br />在ES7,async/await进一步的优化Promise的写法,async函数始终返回一个Promise,await可以实现一个"等待"的功能,async/await被成为异步编程的终极解决方案,即用同步的形式书写异步代码,并且能够更优雅的实现异步代码顺序执行以及在发生异步的错误时提供更精准的错误信息。```javascriptconst request1 = function() {const promise = new Promise(resolve => {request('https://www.baidu.com/xxx_url', function(response) {if (response.retCode == 200) {// 这里的 response 是接口1的返回结果resolve('request1 success'+ response);} else {reject('接口请求失败');}});});return promise;};async function queryData() {const response = await request1();});return response;}queryData().then(data => {console.log(data);});
字符串的扩展
在 ES6 中,标准库升级了很多,我们这里在讲一下 .includes(),以及模版字符串。字符串更多方法我们在前面文章中已经讲过。
.includes( )
主要是用来检查包不包含指定的字符串
写法 1、判断字符串是否包含某些字符串:(传统写法)
var string = 'food';var substring = 'foo';console.log(string.indexOf(substring) > -1);// true
之前我们使用 indexOf() 函数的返回值是否 >-1 来判断字符串是否包含某些字符串,现在我们更简单地使用 .includes() 来返回一个布尔值来判断:
写法 2、判断字符串是否包含某些字符串:(ES6写法)
const string = 'food';const substring = 'foo';console.log(string.includes(substring));// true
startsWith()、endsWith()、repeat()
ES6 中的字符串其他扩展如下:
- startsWith(str):判断是否以指定字符串开头
- endsWith(str):判断是否以指定字符串结尾
- repeat(count):重复指定次数
举例:
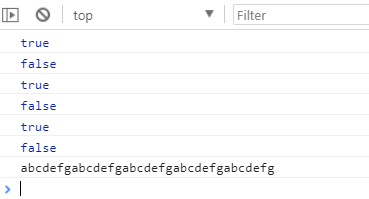
let str = 'abcdefg';console.log(str.includes('a')); //trueconsole.log(str.includes('h')); //false//startsWith(str) : 判断是否以指定字符串开头console.log(str.startsWith('a')); //trueconsole.log(str.startsWith('d')); //false//endsWith(str) : 判断是否以指定字符串结尾console.log(str.endsWith('g')); //trueconsole.log(str.endsWith('d')); //false//repeat(count) : 重复指定次数aconsole.log(str.repeat(5));
模板字符串
ES6 中引入了模板字符串,让我们省去了字符串拼接的烦恼。下面一起来看看它的特性。
特性1:在模板字符串中插入变量
以前,让字符串进行拼接的时候,是这样做的:(传统写法的字符串拼接)
var name = 'coder';var age = '26';console.log('name:' + name + ',age:' + age); //传统写法
这种写法,比较繁琐,而且容易出错。
现在,有了 ES6 语法,字符串拼接可以这样写:
var name = '前端开发';var age = '26';console.log('我是' + name + ',age:' + age); //传统写法console.log(`我是${name},age:${age}`); //ES6 写法。注意语法格式
注意,上方代码中,倒数第二行用的符号是单引号,最后一行用的符号是反引号(在 tab 键的上方)。
特性2:在模板字符串中插入表达式
以前,在字符串中插入表达式的写法必须是这样的:
const a = 5;const b = 10;console.log('this is ' + (a + b) + ' and\nnot ' + (2 * a + b) + '.');
现在,通过模板字符串,我们可以使用一种更优雅的方式来表示:
const a = 5;const b = 10;// 下面这行代码,故意做了换行。console.log(`this is ${a + b} andnot ${2 * a + b}.`);
打印结果:
this is 15 andnot 20.
特性3:模板字符串中可以换行
因为模板字符串支持换行,所以可以让代码写得非常美观。
代码举例:
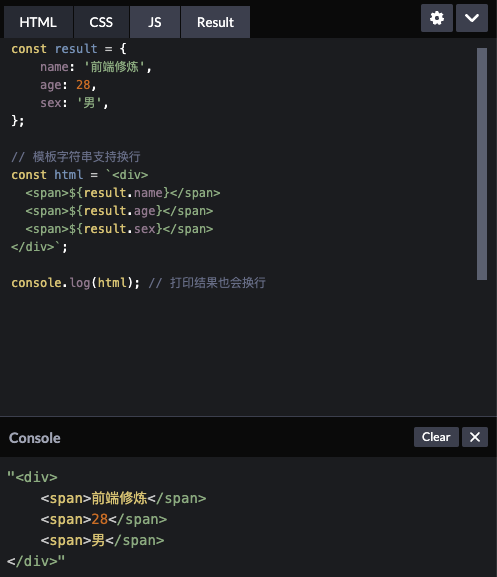
const result = {name: '前端修炼',age: 28,sex: '男',};// 模板字符串支持换行const html = `<div><span>${result.name}</span><span>${result.age}</span><span>${result.sex}</span></div>`;console.log(html); // 打印结果也会换行
特性4:模板字符串中可以调用函数
模板字符串中可以调用函数。字符串中调用函数的位置,将会显示函数执行后的返回值。
举例:
function getName() {return 'qianduanxiulian';}console.log(`www.${getName()}.com`); // 打印结果:www.qianduanxiulian.com
特性5:模板字符串支持嵌套使用
const nameList = ['HTML', 'CSS', 'JavaScript'];function myTemplate() {// join('') 的意思是,把数组里的内容合并成一个字符串return `<ul>${nameList.map((item) => `<li>${item}</li>`).join('')}</ul>`;}document.body.innerHTML = myTemplate();
效果如下: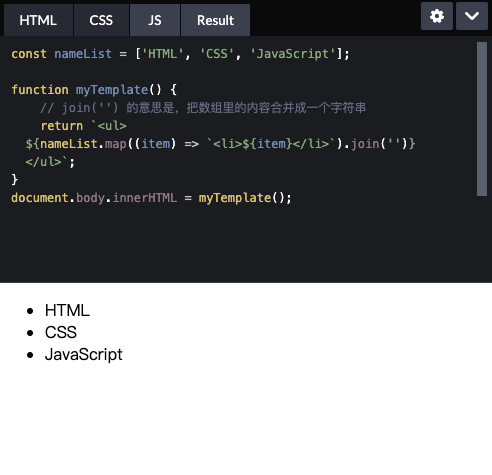
数值、数组、对象的扩展
Number 的扩展
- 二进制与八进制数值表示法: 二进制用
0b, 八进制用0o。
举例:
console.log(0b1010); //10console.log(0o56); //46
Number.isFinite(i):判断是否为有限大的数。比如Infinity这种无穷大的数,返回的就是 false。Number.isNaN(i):判断是否为 NaN。Number.isInteger(i):判断是否为整数。Number.parseInt(str):将字符串转换为对应的数值。Math.trunc(i):去除小数部分。
举例:
//Number.isFinite(i) : 判断是否是有限大的数console.log(Number.isFinite(NaN)); //falseconsole.log(Number.isFinite(5)); //trueconsole.log(Number.isFinite(Infinity)); //false//Number.isNaN(i) : 判断是否是NaNconsole.log(Number.isNaN(NaN)); //trueconsole.log(Number.isNaN(5)); //falsse//Number.isInteger(i) : 判断是否是整数console.log(Number.isInteger(5.23)); //falseconsole.log(Number.isInteger(5.0)); //trueconsole.log(Number.isInteger(5)); //true//Number.parseInt(str) : 将字符串转换为对应的数值console.log(Number.parseInt('123abc')); //123console.log(Number.parseInt('a123abc')); //NaN// Math.trunc(i) : 直接去除小数部分console.log(Math.trunc(13.123)); //13
数组的扩展
下面提到的数组的几个方法,更详细的内容,可以看《04-JavaScript 基础/数组的常见方法.md》。
- Array.from()
- find()
- findIndex()
对象的扩展
扩展1:Object.is
Object.is(v1, v2);
作用:判断两个数据是否完全相等。底层是通过字符串来判断的。
我们先来看下面这两行代码的打印结果:
console.log(0 == -0);console.log(NaN == NaN);
打印结果:
truefalse
上方代码中,第一行代码的打印结果为 true,这个很好理解。第二行代码的打印结果为 false,因为 NaN 和任何值都不相等。
但是,如果换成下面这种方式来比较:
console.log(Object.is(0, -0));console.log(Object.is(NaN, NaN));
打印结果却是:
falsetrue
代码解释:还是刚刚说的那样,Object.is(v1, v2)比较的是字符串是否相等。
扩展2:Object.assign() 实现浅拷贝
Object.assgin() 在日常开发中,使用得相当频繁,非掌握不可。
语法:
// 语法1obj2 = Object.assgin(obj2, obj1);// 语法2Object.assign(目标对象, 源对象1, 源对象2...);
解释:将obj1 拷贝给 obj2。执行完毕后,obj2 的值会被更新。
作用:将 obj1 的值追加到 obj2 中。如果对象里的属性名相同,会被覆盖。
从语法2中可以看出,Object.assign() 可以将多个“源对象”拷贝到“目标对象”中。
例 1:
const obj1 = {name: 'qianduanxiulian',age: 28,info: {desc: 'hello',},};// 浅拷贝:把 obj1 拷贝给 obj2。如果 obj1 只有一层数据,那么,obj1 和 obj2 则互不影响const obj2 = Object.assign({}, obj1);console.log('obj2:' + JSON.stringify(obj2));obj1.info.desc = '永不止步'; // 由于 Object.assign() 只是浅拷贝,所以当修改 obj1 的第二层数据时,obj2 对应的值也会被改变。console.log('obj2:' + JSON.stringify(obj2));
代码解释:由于 Object.assign() 只是浅拷贝,所以在当前这个案例中, obj2 中的 name 属性和 age 属性是单独存放在新的堆内存地址中的,和 obj1 没有关系;但是,obj2.info 属性,跟 obj1.info属性,它俩指向的是同一个堆内存地址。所以,当我修改 obj1.info 里的值之后,obj2.info的值也会被修改。
打印结果:
obj2:{"name":"qianduanxiulian","age":28,"info":{"desc":"hello"}}obj2:{"name":"qianduanxiulian","age":28,"info":{"desc":"永不止步"}}
例 2:
const myObj = {name: 'qianduanxiulian',age: 28,};// 【写法1】浅拷贝:把 myObj 拷贝给 obj1const obj1 = {};Object.assign(obj1, myObj);// 【写法2】浅拷贝:把 myObj 拷贝给 obj2const obj2 = Object.assign({}, myObj);// 【写法3】浅拷贝:把 myObj 拷贝给 obj31。注意,这里的 obj31 和 obj32 其实是等价的,他们指向了同一个内存地址const obj31 = {};const obj32 = Object.assign(obj31, myObj);
上面这三种写法,是等价的。所以,当我们需要将对象 A 复制(拷贝)给对象 B,不要直接使用 B = A,而是要使用 Object.assign(B, A)。
例 3:
let obj1 = { name: 'qianduanxiulian', age: 26 };let obj2 = { city: 'hangzhou', age: 28 };let obj3 = {};Object.assign(obj3, obj1, obj2); // 将 obj1、obj2的内容赋值给 obj3console.log(obj3); // {name: "qianduanxiulian", age: 28, city: "hangzhou"}
上面的代码,可以理解成:将多个对象(obj1和obj2)合并成一个对象 obj3。
例4:【重要】
const obj1 = {name: 'qianduanxiulian',age: 28,desc: 'hello world',};const obj2 = {name: '许嵩',sex: '男',};// 浅拷贝:把 obj1 赋值给 obj2。这一行,是关键代码。这行代码的返回值也是 obj2Object.assign(obj2, obj1);console.log(JSON.stringify(obj2));
打印结果:
{"name":"qianduanxiulian","sex":"男","age":28,"desc":"hello world"}
注意,例 4 在实际开发中,会经常遇到,一定要掌握。它的作用是:将 obj1 的值追加到 obj2 中。如果两个对象里的属性名相同,则 obj2 中的值会被 obj1 中的值覆盖。
扩展 3:__proto__属性
举例:
let obj1 = { name: 'smyhvae' };let obj2 = {};obj2.__proto__ = obj1;console.log(obj1);console.log(obj2);console.log(obj2.name);
打印结果: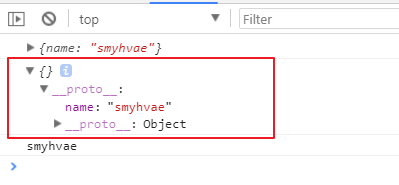
上方代码中,obj2 本身是没有属性的,但是通过__proto__属性和 obj1 产生关联,于是就可以获得 obj1 里的属性。
Set 数据结构
ES6 提供了 新的数据结构 Set。Set 类似于数组,但成员的值都是唯一的,没有重复的值。
Set 的应用有很多。比如,在 H5 页面的搜索功能里,用户可能会多次搜索重复的关键字;但是在数据存储上,不需要存储重复的关键字。此时,我们就可以用 Set 来存储用户的搜索记录,Set 内部会自动判断值是否重复,如果重复,则不会进行存储,十分方便。
生成 Set 数据结构
Set 本身就是一个构造函数,可通过 new Set() 生成一个 Set 的实例。
举例 1:
const set1 = new Set();console.log(set1.size); // 打印结果:0
举例 2、可以接收一个数组作为参数,实现数组去重:
const set2 = new Set(['张三', '李四', '王五', '张三']); // 注意,这个数组里有重复的值// 注意,这里的 set2 并不是数组,而是一个单纯的 Set 数据结构console.log(set2); // {"张三", "李四", "王五"}// 通过扩展运算符,拿到 set 中的元素(用逗号分隔的序列)// ...set2 // "张三", "李四", "王五"// 注意,到这一步,才获取到了真正的数组console.log([...set2]); // ["张三", "李四", "王五"]
注意上方的第一行代码,虽然参数里传递的是数组结构,但拿到的 set2 不是数组结构,而是 Set 结构,而且里面元素是去重了的。通过 [...set2]就可以拿到set2对应的数组。
Symbol
概述
背景:ES5中对象的属性名都是字符串,容易造成重名,污染环境。
概念:ES6 引入了一种新的原始数据类型Symbol,表示独一无二的值。它是 JavaScript 语言的第七种数据类型,前六种是:undefined、null、布尔值(Boolean)、字符串(String)、数值(Number)、对象(Object)。
特点:
- Symbol属性对应的值是唯一的,解决命名冲突问题
- Symbol值不能与其他数据进行计算,包括同字符串拼串
- for in、for of 遍历时不会遍历Symbol属性。
创建Symbol属性值
Symbol是函数,但并不是构造函数。创建一个Symbol数据类型:
let mySymbol = Symbol();console.log(typeof mySymbol); //打印结果:symbolconsole.log(mySymbol); //打印结果:Symbol()
打印结果: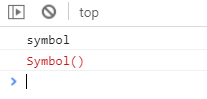
将Symbol作为对象的属性值
let mySymbol = Symbol();let obj = {name: 'smyhvae',age: 26};//obj.mySymbol = 'male'; //错误:不能用 . 这个符号给对象添加 Symbol 属性。obj[mySymbol] = 'hello'; //正确:通过**属性选择器**给对象添加 Symbol 属性。后面的属性值随便写。console.log(obj);
上面的代码中,我们尝试给obj添加一个Symbol类型的属性值,但是添加的时候,不能采用.这个符号,而是应该用属性选择器的方式。打印结果:
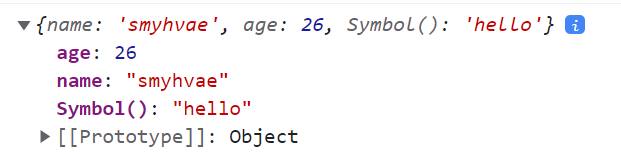
现在我们用for in尝试对上面的obj进行遍历:
let mySymbol = Symbol();let obj = {name: 'smyhvae',age: 26};obj[mySymbol] = 'hello';console.log(obj);//遍历objfor (let i in obj) {console.log(i);}
打印结果: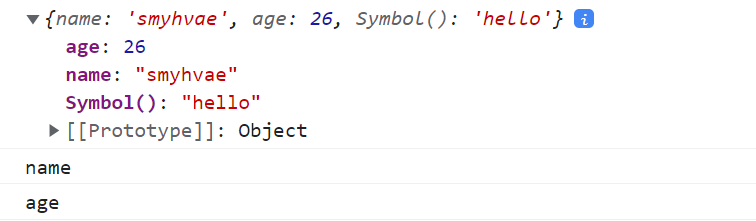
从打印结果中可以看到:for in、for of 遍历时不会遍历Symbol属性。
创建Symbol属性值时,传参作为标识
如果我通过 Symbol()函数创建了两个值,这两个值是不一样的:
let mySymbol1 = Symbol();let mySymbol2 = Symbol();console.log(mySymbol1 == mySymbol2); //打印结果:falseconsole.log(mySymbol1); //打印结果:Symbol()console.log(mySymbol2); //打印结果:Symbol()

上面代码中,倒数第三行的打印结果也就表明了,二者的值确实是不相等的。
最后两行的打印结果却发现,二者的打印输出,肉眼看到的却相同。那该怎么区分它们呢?
既然Symbol()是函数,函数就可以传入参数,我们可以通过参数的不同来作为标识。比如:
//在括号里加入参数,来标识不同的Symbollet mySymbol1 = Symbol('one');let mySymbol2 = Symbol('two');console.log(mySymbol1 == mySymbol2); //打印结果:falseconsole.log(mySymbol1); //打印结果:Symbol(one)console.log(mySymbol2); //打印结果:Symbol(two)。颜色为红色。console.log(mySymbol2.toString());//打印结果:Symbol(two)。颜色为黑色。
打印结果: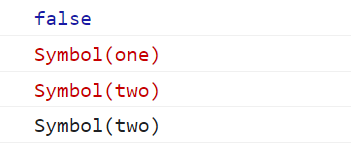
定义常量
Symbol 可以用来定义常量:
const MY_NAME = Symbol('my_name');

若有收获,就点个赞吧
0 人点赞
