本地事务和分布式事务的描述
事务

分布式事务
- 分布式事务,就是指不是在单个服务或单个数据库架构下,产生的事务,例如:
- 跨数据源的分布式事务
- 跨服务的分布式事务
- 综合情况
- 在数据库水平拆分、服务垂直拆分之后,一个业务操作通常要跨多个数据库、服务才能完成。例如电商行业中比较常见的下单付款案例,包括下面几个行为:
- 创建新订单
- 扣减商品库存
- 从用户账户余额扣除金额
- 完成上面的操作需要访问三个不同的微服务和三个不同的数据库。

一个数据库的事务,只能管理自己的事务,无法管理其他事务
分布式事务: 分布式系统中,多个服务操作多个数据库,不同服务参与同一个操作时,要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
演示分布式事务问题
- 创建数据库,名为seata_demo,然后导入课前资料提供的SQL文件:
- 导入课前资料提供的微服务:
- 微服务结构如下:

- 其中:seata-demo:父工程,负责管理项目依赖
- account-service:账户服务,负责管理用户的资金账户。提供扣减余额的接口
- storage-service:库存服务,负责管理商品库存。提供扣减库存的接口
- order-service:订单服务,负责管理订单。创建订单时,需要调用account-service和storage-service
- 启动nacos、所有微服务
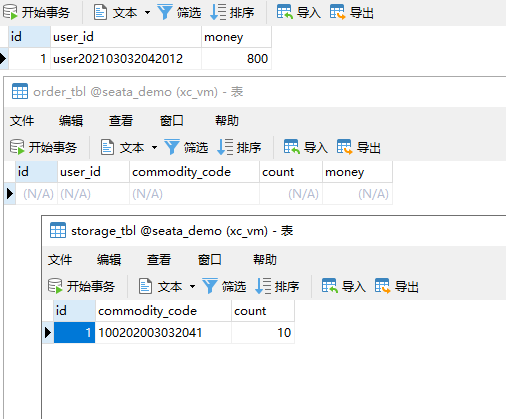
- 测试下单功能,发出Post请求:
请求如下:
http://localhost:8082/order?userId=user202103032042012&commodityCode=100202003032041&count=20&money=200
如图

测试发现,当库存不足时,如果余额已经扣减,并不会回滚,出现了分布式事务问题。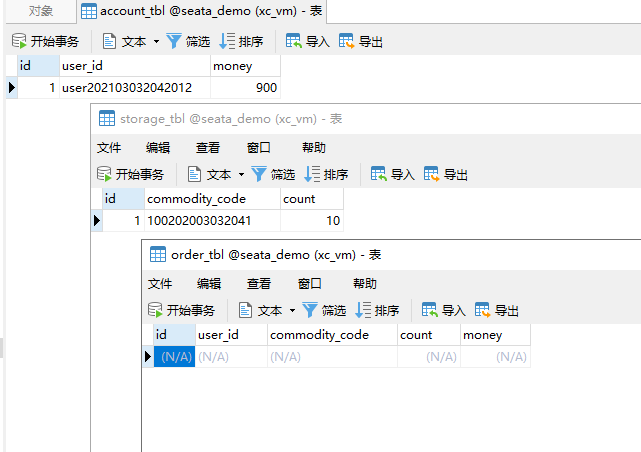
分布式事务的理论有哪些
CAP
- Consistency(一致性)
- Availability(可用性)
- Partition tolerance (分区容错性)
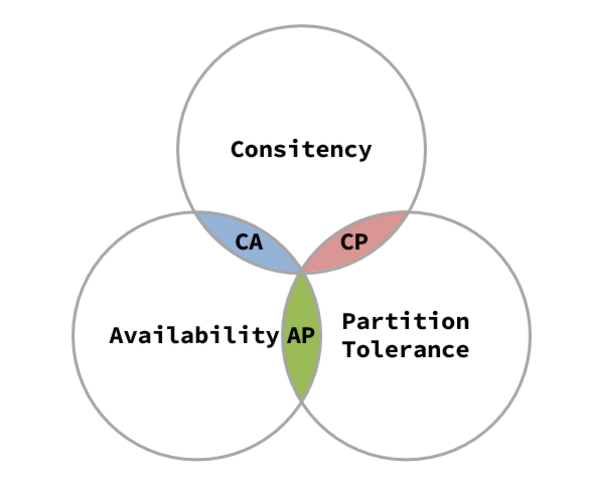
- 它们的第一个字母分别是 C、A、P。
Eric Brewer 说,这三个指标不可能同时做到。这个结论就叫做 CAP 定理。
一致性
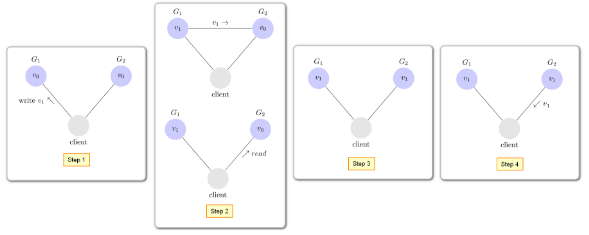
C (一致性):对某个指定的客户端来说,读操作能返回最新的数据。如果读操作时,正在进行写操作,此时读操作会等待,当写操作完后,读操作再进行并返回最新的数据。
可用性
- A (可用性):客户端的请求,服务端并会有响应,此动作不会关系数据有没有同步,所有客户端获得的数据可能不是最新的数据。

分区容错
- 分区:数据库分区
- 容错:由于网络地方不稳定因素,导致两个分区数据没有同步,网络恢复,就会同步
- P (网络分区容错性):在分布式系统中,由于网络等不稳定因素,导致系统服务间的数据没有同步,此时会出现数据上的错误,而这种数据上出错误是可以容忍存在。不稳定因素解决后,服务间的数据最终会同步。
组合形式
- 分布式系統无法同时满足CAP三项,分布式系统中 P 永远存在。
- 因为分布式是多服务
- CAP有哪些组合方式:
- CA,若不需要关注P,那么系统不是分布式系统,加强一致性和可用性,关系数据库按照CA进行设计。
- CP,放弃可用性,追求一致性和分区容错性,比如跨行转账,一次转账请求要等待双方银行系统都完成整个事务才算完成。
- AP,放弃一致性(这里说的一致性是强一致性),追求分区容错性和可用性,这是很多分布式系统设计时的选择,后面的BASE也是根据AP来扩展。比如:订单退款,今日退款成功,明日账户到账,只要在预定的用户可以接受的时间内退款事务走完即可。

- 如果此时要保证一致性,就必须等待网络恢复,完成数据同步后,整个集群才对外提供服务,服务处于阻塞状态,不可用。
- 如果此时要保证可用性,就不能等待网络恢复,那node01、node02与node03之间就会出现数据不一致。
-
BASE
三个状态
软状态
允许系统中存在中间状态,这个状态不影响系统可用性,如订单的”支付中”状态、不同节点数据副本同步延迟等。举例:你参加工作后,通常在拿到第一个月工资的时候,都会选择向家里汇款,当你完成转账操作后,结果银行提示“您的转账预计3日内到账”,而该笔交易的状态为”转账中“。
最终一致
最终一致是指经过一段时间后,所有节点数据都将会达到一致。如订单的”支付中”状态,早晚会变为“支付成功”或者”支付失败”,使订单状态与实际交易结果达成一致,但需要一定时间的延迟、等待。举例:向家里汇款2天后,家里人收到转载的钱。
基本可用
分布式系统在出现故障时,允许损失部分可用功能,保证核心功能可用。如,电商网站交易付款出现问题了,商品依然可以正常浏览。举例:在这个期间,两个银行的通信网络出现问题,导致实际的转账操作无法完成,但你依然能查询到你的该笔交易状态为“转账中”。
分布式事务实现方案
两阶段提交2PC(XA协议)
介绍说明
2PC是基于XA规范分布式事务解决方案。
- XA 规范 是 X/Open 组织定义的分布式事务处理(DTP,Distributed Transaction Processing)标准,XA 规范 描述了全局的TM与局部的RM之间的接口,几乎所有主流的数据库都对 XA 规范 提供了支持。
- 两阶段提交协议(Two Phase Commitment Protocol)中,涉及到两种角色
- 一个事务协调者(coordinator):负责协调多个参与者进行事务投票及提交(回滚)
- 多个事务参与者(participants):即本地事务执行者
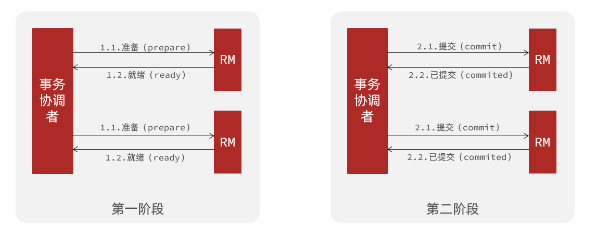
- 两阶段提交:
- prepare阶段:事务执行但不提交阶段
- commit阶段:事务提交阶段
正常情况
异常情况
阶段解释
- 一阶段:
- 事务协调者通知每个事物参与者执行本地事务
- 本地事务执行完成后报告事务执行状态给事务协调者,此时事务不提交,继续持有数据库锁
二阶段:
TCC 其实就是采用的补偿机制,其核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。三个阶段如下: | 操作方法 | 含义 | | —- | —- | | Try | 预留业务资源/数据效验-尝试检查当前操作是否可执行 | | Confirm | 确认执行业务操作,实际提交数据,不做任何业务检查。try成功,confirm必定成功 | | Cancel | 执行业务出错时,需要回滚数据的状态下执行的业务逻辑 |


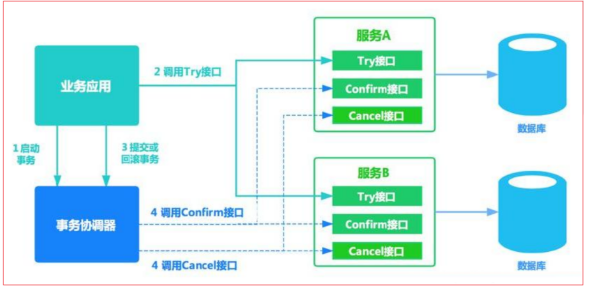


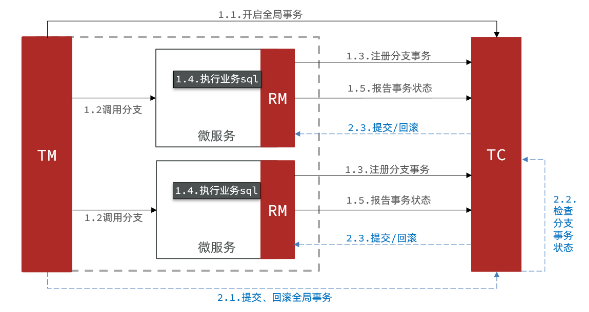
Seata的架构和服务角色
- Seata事务管理中有三个重要的角色:
- TC (Transaction Coordinator) -事务协调者:维护全局和分支事务的状态,协调全局事务提交或回滚。
- TM (Transaction Manager) -事务管理器:定义全局事务的范围、开始全局事务、提交或回滚全局事务。
- RM (Resource Manager) -资源管理器:管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
- 整体的架构如图:

- Seata基于上述架构提供了四种不同的分布式事务解决方案:
- XA模式:强一致性分阶段事务模式,牺牲了一定的可用性,无业务侵入
- TCC模式:最终一致的分阶段事务模式,有业务侵入
- AT模式:最终一致的分阶段事务模式,无业务侵入,也是Seata的默认模式
- SAGA模式:长事务模式,有业务侵入
- 无论哪种方案,都离不开TC,也就是事务的协调者。
Seata环境的集成
服务端TC集成
下拉容器和创建容器
```java下拉镜像
docker pull seataio/seata-server:1.4.2
创建容器
docker run \ -e SEATA_IP=192.168.94.128 \ -e SEATA_PORT=8091 \ —name seata-server \ -p 8091:8091 \ -d \ seataio/seata-server:1.4.2
创建容器后可以进入到容器中
docker exec -it seata-server sh
退出容器
exit
查看运行的日志
docker logs -f seata-server
<a name="FaHT2"></a>### 创建Seata的数据库和表- **在mysql服务中添加数据库,导入今天 "资料/seata/seata.sql" 文件到数据库中,导入后的结果:**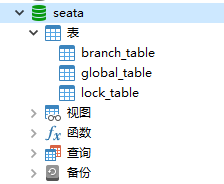<a name="UHaGl"></a>### 配置seata的tc配置信息- **在nacos中namespace下创建配置信息:seataServer.properties**```java# 数据存储方式,db代表数据库store.mode=dbstore.db.datasource=druidstore.db.dbType=mysqlstore.db.driverClassName=com.mysql.jdbc.Driverstore.db.url=jdbc:mysql://192.168.94.128:3306/seata?useUnicode=true&rewriteBatchedStatements=truestore.db.user=rootstore.db.password=rootstore.db.minConn=5store.db.maxConn=30store.db.globalTable=global_tablestore.db.branchTable=branch_tablestore.db.queryLimit=100store.db.lockTable=lock_tablestore.db.maxWait=5000# 事务、日志等配置server.recovery.committingRetryPeriod=1000server.recovery.asynCommittingRetryPeriod=1000server.recovery.rollbackingRetryPeriod=1000server.recovery.timeoutRetryPeriod=1000server.maxCommitRetryTimeout=-1server.maxRollbackRetryTimeout=-1server.rollbackRetryTimeoutUnlockEnable=falseserver.undo.logSaveDays=7server.undo.logDeletePeriod=86400000# 客户端与服务端传输方式transport.serialization=seatatransport.compressor=none# 关闭metrics功能,提高性能metrics.enabled=falsemetrics.registryType=compactmetrics.exporterList=prometheusmetrics.exporterPrometheusPort=9898
- 将导入今天 “资料/seata/registry.conf” 导入到Centos环境中,并执行下面的操作:
```java
将配置文件拷贝到seata容器中
docker cp registry.conf seata-server:/seata-server/resources
重新启动seata服务
docker restart seata-server
```java
registry {
# tc服务的注册中心类,这里选择nacos,也可以是eureka、zookeeper等
type = "nacos"
nacos {
# seata tc 服务注册到 nacos的服务名称,可以自定义 spring.application.name
application = "seata-tc-server"
serverAddr = "192.168.94.128:8848"
group = "DEFAULT_GROUP"
# 因为此时都在public中,如果在其他中,需要添加
namespace = ""
cluster = "DEFAULT"
username = "nacos"
password = "nacos"
}
}
config {
# 读取tc服务端的配置文件的方式,这里是从nacos配置中心读取,这样如果tc是集群,可以共享配置
type = "nacos"
# 配置nacos地址等信息
nacos {
serverAddr = "192.168.94.128:8848"
group = "DEFAULT_GROUP"
# 因为此时都在public中,如果在其他中,需要添加
namespace = ""
username = "nacos"
password = "nacos"
dataId = "seataServer.properties"
}
}

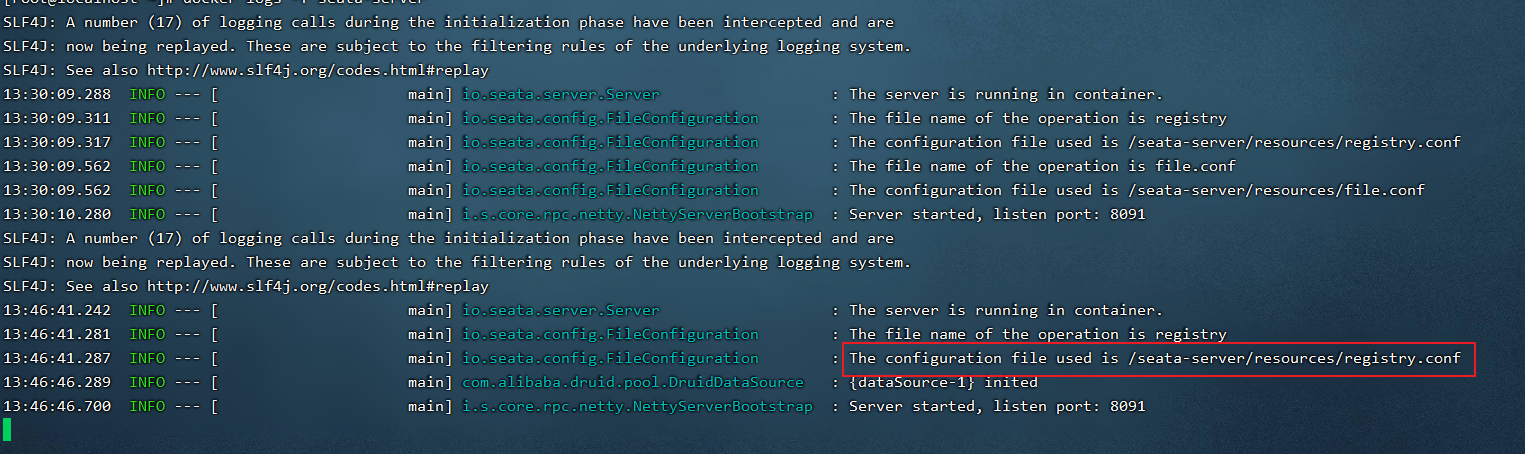
通过Docker日志命令查看是否运行成功
客户端RM集成
引入依赖
首先,在order-service中引入依赖:
<!--seata--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-seata</artifactId> <exclusions> <!--版本较低,1.3.0,因此排除--> <exclusion> <artifactId>seata-spring-boot-starter</artifactId> <groupId>io.seata</groupId> </exclusion> </exclusions> </dependency> <dependency> <groupId>io.seata</groupId> <artifactId>seata-spring-boot-starter</artifactId> <!--seata starter 采用1.4.2版本--> <version>${seata.version}</version> </dependency>配置TC地址
在order-service中的application.yml中,配置TC服务信息,通过注册中心nacos,结合服务名称获取TC地址:
seata: registry: # TC服务注册中心的配置,微服务根据这些信息去注册中心获取tc服务地址 type: nacos # 注册中心类型 nacos nacos: server-addr: 192.168.94.128:8848 # nacos地址 namespace: "" # namespace,默认为空 group: DEFAULT_GROUP # 分组,默认是DEFAULT_GROUP application: seata-tc-server # seata服务名称 username: nacos password: nacos tx-service-group: seata-demo # 事务组名称 service: vgroup-mapping: # 事务组与cluster的映射关系 seata-demo: DEFAULT微服务如何根据这些配置寻找TC的地址呢?
- 我们知道注册到Nacos中的微服务,确定一个具体实例需要四个信息:
- namespace:命名空间
- group:分组
- application:服务名
- cluster:集群名
- 以上四个信息,在刚才的yaml文件中都能找到:

- namespace为空,就是默认的public
- 结合起来,TC服务的信息就是:public@DEFAULT_GROUP@seata-tc-server@SH,这样就能确定TC服务集群了。然后就可以去Nacos拉取对应的实例信息了。
- 配置好后,可以通过Seata的日志查看微服务注册的信息:

Seata分布式方案模式
XA模式
两阶段提交
- XA是规范,目前主流数据库都实现了这种规范,实现的原理都是基于两阶段提交。
- 正常情况:

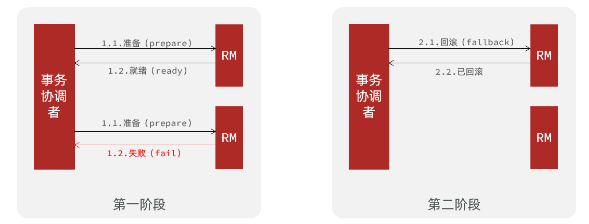
- 异常情况:

一阶段:
- 事务协调者通知每个事物参与者执行本地事务
- 本地事务执行完成后报告事务执行状态给事务协调者,此时事务不提交,继续持有数据库锁
二阶段:
事务协调者基于一阶段的报告来判断下一步操作
RM一阶段的工作:
- 注册分支事务到TC
- 执行分支业务sql但不提交
- 报告执行状态到TC
- TC二阶段的工作:
- TC检测各分支事务执行状态
- 如果都成功,通知所有RM提交事务
- 如果有失败,通知所有RM回滚事务
- TC检测各分支事务执行状态
RM二阶段的工作:
XA模式的优点是什么?
- 事务的强一致性,满足ACID原则。
- 常用数据库都支持,实现简单,并且没有代码侵入
XA模式的缺点是什么?
Seata的starter已经完成了XA模式的自动装配,实现非常简单,步骤如下:
修改application.yml文件(==每个参与事务的微服务==),开启XA模式:
seata: data-source-proxy-mode: XA给发起全局事务的入口方法添加@GlobalTransactional注解:本例中是OrderServiceImpl中的create方法.
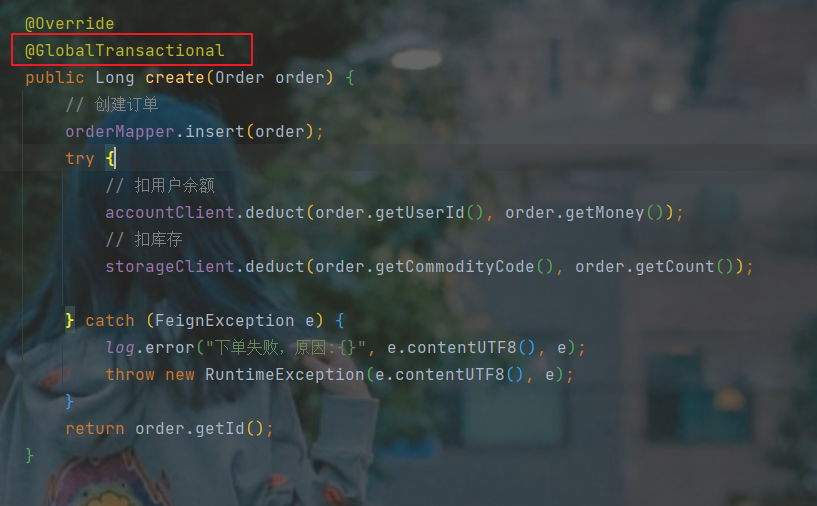
- 重启服务并测试:重启order-service,再次测试,发现无论怎样,三个微服务都能成功回滚。

AT模式
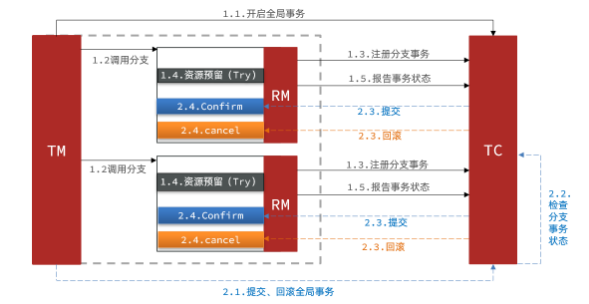
Seata的AT模型
- 基本流程图:

- 阶段一RM的工作:
- 注册分支事务
- 记录undo-log(数据快照)
- 执行业务sql并提交
- 报告事务状态
- 阶段二提交时RM的工作:
- 删除undo-log即可
阶段二回滚时RM的工作:
我们用一个真实的业务来梳理下AT模式的原理。
- 比如,现在又一个数据库表,记录用户余额: | id | money | | —- | —- | | 1 | 100 |
其中一个分支业务要执行的SQL为:
update tb_account set money = money - 10 where id = 1
AT模式下,当前分支事务执行流程如下:
一阶段:
- TM发起并注册全局事务到TC
- TM调用分支事务
- 分支事务准备执行业务SQL
RM拦截业务SQL,根据where条件查询原始数据,形成快照。
{ "id": 1, "money": 100 }RM执行业务SQL,提交本地事务,释放数据库锁。此时 money = 90
- RM报告本地事务状态给TC
- 二阶段:
- TM通知TC事务结束
- TC检查分支事务状态
- 如果都成功,则立即删除快照
- 如果有分支事务失败,需要回滚。读取快照数据({“id”: 1, “money”: 100}),将快照恢复到数据库。此时数据库再次恢复为100
- 流程图:

AT与XA的区别
简述AT模式与XA模式最大的区别是什么?
在多线程并发访问AT模式的分布式事务时,有可能出现脏写问题,如图:

- 解决思路就是引入了全局锁的概念。在释放DB锁之前,先拿到全局锁。避免同一时刻有另外一个事务来操作当前数据。

优缺点
- AT模式的优点:
- 一阶段完成直接提交事务,释放数据库资源,性能比较好
- 利用全局锁实现读写隔离
- 没有代码侵入,框架自动完成回滚和提交
AT模式的缺点:
AT模式中的快照生成、回滚等动作都是由框架自动完成,没有任何代码侵入,因此实现非常简单。
- 只不过,AT模式需要一个表来记录全局锁、另一张表来记录数据快照undo_log。
- 导入数据库表,记录全局锁
- 导入课前资料提供的Sql文件:seata-at.sql,其中lock_table导入到TC服务关联的数据库(已经添加),undo_log表导入到微服务关联的数据库:

修改各个业务服务application.yml文件,将事务模式修改为AT模式即可:
seata: data-source-proxy-mode: AT # 默认就是AT重启服务并测试
TCC模式
TCC模式与AT模式非常相似,每阶段都是独立事务,不同的是TCC通过人工编码来实现数据恢复。需要实现三个方法:
阶段一( Try ):检查余额是否充足,如果充足则冻结金额增加30元,可用余额扣除30
- 初识余额:

- 余额充足,可以冻结:

- 此时,总金额 = 冻结金额 + 可用金额,数量依然是100不变。事务直接提交无需等待其它事务。
- 阶段二(Confirm):假如要提交(Confirm),则冻结金额扣减30
- 确认可以提交,不过之前可用金额已经扣减过了,这里只要清除冻结金额就好了:

- 此时,总金额 = 冻结金额 + 可用金额 = 0 + 70 = 70元
- 阶段二(Canncel):如果要回滚(Cancel),则冻结金额扣减30,可用余额增加30
- 需要回滚,那么就要释放冻结金额,恢复可用金额:

4Seata的TCC模型
- Seata中的TCC模型依然延续之前的事务架构,如图:
优缺点
- TCC模式的每个阶段是做什么的?
- Try:资源检查和预留
- Confirm:业务执行和提交
- Cancel:预留资源的释放
- TCC的优点是什么?
- 一阶段完成直接提交事务,释放数据库资源,性能好
- 相比AT模型,无需生成快照,无需使用全局锁,性能最强
- 不依赖数据库事务,而是依赖补偿操作,可以用于非事务型数据库
TCC的缺点是什么?
当某分支事务的try阶段阻塞时,可能导致全局事务超时而触发二阶段的cancel操作。在未执行try操作时先执行了cancel操作,这时cancel不能做回滚,就是空回滚。
- 如图:

执行cancel操作时,应当判断try是否已经执行,如果尚未执行,则应该空回滚。
业务悬挂
对于已经空回滚的业务,之前被阻塞的try操作恢复,继续执行try,就永远不可能confirm或cancel ,事务一直处于中间状态,这就是业务悬挂。
执行try操作时,应当判断cancel是否已经执行过了,如果已经执行,应当阻止空回滚后的try操作,避免悬挂
实现TCC模式
解决空回滚和业务悬挂问题,必须要记录当前事务状态,是在try、还是cancel?

思路分析
这里我们定义一张表:
CREATE TABLE `account_freeze_tbl` ( `xid` varchar(128) NOT NULL, `user_id` varchar(255) DEFAULT NULL COMMENT '用户id', `freeze_money` int(11) unsigned DEFAULT '0' COMMENT '冻结金额', `state` int(1) DEFAULT NULL COMMENT '事务状态,0:try,1:confirm,2:cancel', PRIMARY KEY (`xid`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT;xid:是全局事务id
- freeze_money:用来记录用户冻结金额
- state:用来记录事务状态
那此时,我们的业务开怎么做呢?
- Try业务:
- 记录冻结金额和事务状态到account_freeze表
- 扣减account表可用金额
- Confirm业务
- 根据xid删除account_freeze表的冻结记录
- Cancel业务
- 修改account_freeze表,冻结金额为0,state为2
- 修改account表,恢复可用金额
- 如何判断是否空回滚?
- cancel业务中,根据xid查询account_freeze,如果为null则说明try还没做,需要空回滚
- 如何避免业务悬挂?
- try业务中,根据xid查询account_freeze ,如果已经存在则证明Cancel已经执行,拒绝执行try业务
接下来,我们改造account-service,利用TCC实现余额扣减功能。
声明TCC接口
- TCC的Try、Confirm、Cancel方法都需要在接口中基于注解来声明,
- 我们在account-service项目中的cn.itcast.account.service包中新建一个接口,声明TCC三个接口: ```java package cn.itcast.account.service;
import io.seata.rm.tcc.api.BusinessActionContext; import io.seata.rm.tcc.api.BusinessActionContextParameter; import io.seata.rm.tcc.api.LocalTCC; import io.seata.rm.tcc.api.TwoPhaseBusinessAction;
@LocalTCC // 设置TCC模式 public interface TCCAccountService { /**
* 从用户账户中扣款
*/
// 此注解使用在try方法上,方法名称可以自定义
// 预留冻结
@TwoPhaseBusinessAction(name = "deduct",commitMethod = "confirm",rollbackMethod = "cancel")
void deduct(
@BusinessActionContextParameter(paramName = "userId") String userId,
@BusinessActionContextParameter(paramName = "money") int money);
// confirm: 提交
// BusinessActionContext: 业务上下文对象
void confirm(BusinessActionContext context);
// cancel: 事务补偿
void cancel(BusinessActionContext context);
}
<a name="hURpC"></a>
#### 编写实现类
- **在account-service服务中的cn.itcast.account.service.impl包下新建一个类,实现TCC业务:**
```java
package cn.itcast.account.service.impl;
import cn.itcast.account.entity.Account;
import cn.itcast.account.entity.AccountFreeze;
import cn.itcast.account.mapper.AccountFreezeMapper;
import cn.itcast.account.mapper.AccountMapper;
import cn.itcast.account.service.TCCAccountService;
import io.seata.core.context.RootContext;
import io.seata.rm.tcc.api.BusinessActionContext;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.util.ObjectUtils;
/**
* <p></p>
*
* @Description:
*/
@Service
public class TCCAccountServiceImpl implements TCCAccountService {
@Autowired
private AccountMapper accountMapper;
@Autowired
private AccountFreezeMapper accountFreezeMapper;
@Override
public void deduct(String userId, int money) {
String xid = RootContext.getXID();
// try业务中,根据xid查询account_freeze ,如果已经存在则证明Cancel已经执行,拒绝执行try业务
AccountFreeze freeze = accountFreezeMapper.selectById(xid);
if (!(ObjectUtils.isEmpty(freeze))) {
// 优化方案
accountFreezeMapper.deleteById(xid);
return;
}
//- 记录冻结金额和事务状态到account_freeze表
AccountFreeze accountFreeze = new AccountFreeze();
accountFreeze.setXid(xid);
accountFreeze.setFreezeMoney(money);
accountFreeze.setUserId(userId);
accountFreeze.setState(AccountFreeze.State.TRY);
accountFreezeMapper.insert(accountFreeze);
// - 扣减account表可用金额
accountMapper.deduct(userId, money);
}
@Override
public void confirm(BusinessActionContext context) {
// 根据xid删除account_freeze表的冻结记录
String xid = context.getXid();
accountFreezeMapper.deleteById(xid);
}
@Override
public void cancel(BusinessActionContext context) {
String xid = context.getXid();
String userId = context.getActionContext("userId").toString();
Integer money = (Integer) context.getActionContext("money");
// cancel业务中,根据xid查询account_freeze,如果为null则说明try还没做,需要空回滚
AccountFreeze freeze = accountFreezeMapper.selectById(xid);
if (ObjectUtils.isEmpty(freeze)) {
AccountFreeze accountFreeze = new AccountFreeze();
accountFreeze.setXid(xid);
accountFreeze.setFreezeMoney(0);
accountFreeze.setUserId(userId);
accountFreeze.setState(AccountFreeze.State.CANCEL);
accountFreezeMapper.insert(accountFreeze);
return;
}
//- 修改account_freeze表,冻结金额为0,state为2
AccountFreeze accountFreeze = new AccountFreeze();
accountFreeze.setXid(xid);
accountFreeze.setFreezeMoney(0);
accountFreeze.setState(AccountFreeze.State.CANCEL);
accountFreezeMapper.updateById(accountFreeze);
// - 修改account表,恢复可用金额
accountMapper.refund(userId, money);
}
}
编写实现类
- 在account-service服务中的cn.itcast.account.web.AccountController类中修改TCC类的调用: ```java package cn.itcast.account.web;
import cn.itcast.account.service.AccountService; import cn.itcast.account.service.TCCAccountService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.http.ResponseEntity; import org.springframework.web.bind.annotation.PathVariable; import org.springframework.web.bind.annotation.PutMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController;
/**
@author */ @RestController @RequestMapping(“account”) public class AccountController {
//@Autowired //private AccountService accountService; @Autowired private TCCAccountService accountService; @RequestMapping(“/{userId}/{money}”) public ResponseEntity
deduct(@PathVariable(“userId”) String userId, @PathVariable(“money”) Integer money){ accountService.deduct(userId, money); return ResponseEntity.noContent().build();} }
SAGA模式
- Saga 模式是 Seata 即将开源的长事务解决方案,将由蚂蚁金服主要贡献。
- 其理论基础是Hector & Kenneth 在1987年发表的论文Sagas。
Seata官网对于Saga的指南:https://seata.io/zh-cn/docs/user/saga.html
原理
在 Saga 模式下,分布式事务内有多个参与者,每一个参与者都是一个冲正补偿服务,需要用户根据业务场景实现其正向操作和逆向回滚操作。
- 分布式事务执行过程中,依次执行各参与者的正向操作,如果所有正向操作均执行成功,那么分布式事务提交。如果任何一个正向操作执行失败,那么分布式事务会去退回去执行前面各参与者的逆向回滚操作,回滚已提交的参与者,使分布式事务回到初始状态。
Saga也分为两个阶段:
优点:
- 事务参与者可以基于事件驱动实现异步调用,吞吐高
- 一阶段直接提交事务,无锁,性能好
- 不用编写TCC中的三个阶段,实现简单
缺点:
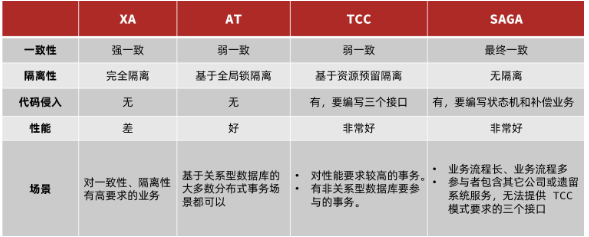
我们从以下几个方面来对比四种实现:
- 一致性:能否保证事务的一致性?强一致还是最终一致?
- 隔离性:事务之间的隔离性如何?
- 代码侵入:是否需要对业务代码改造?
- 性能:有无性能损耗?
- 场景:常见的业务场景
- 如图:

若有收获,就点个赞吧
0 人点赞
