大数据不是像传统系统那样为用户提供功能, 而是猜测用户可能需要什么功能推给用户.
大数据技术的发展史
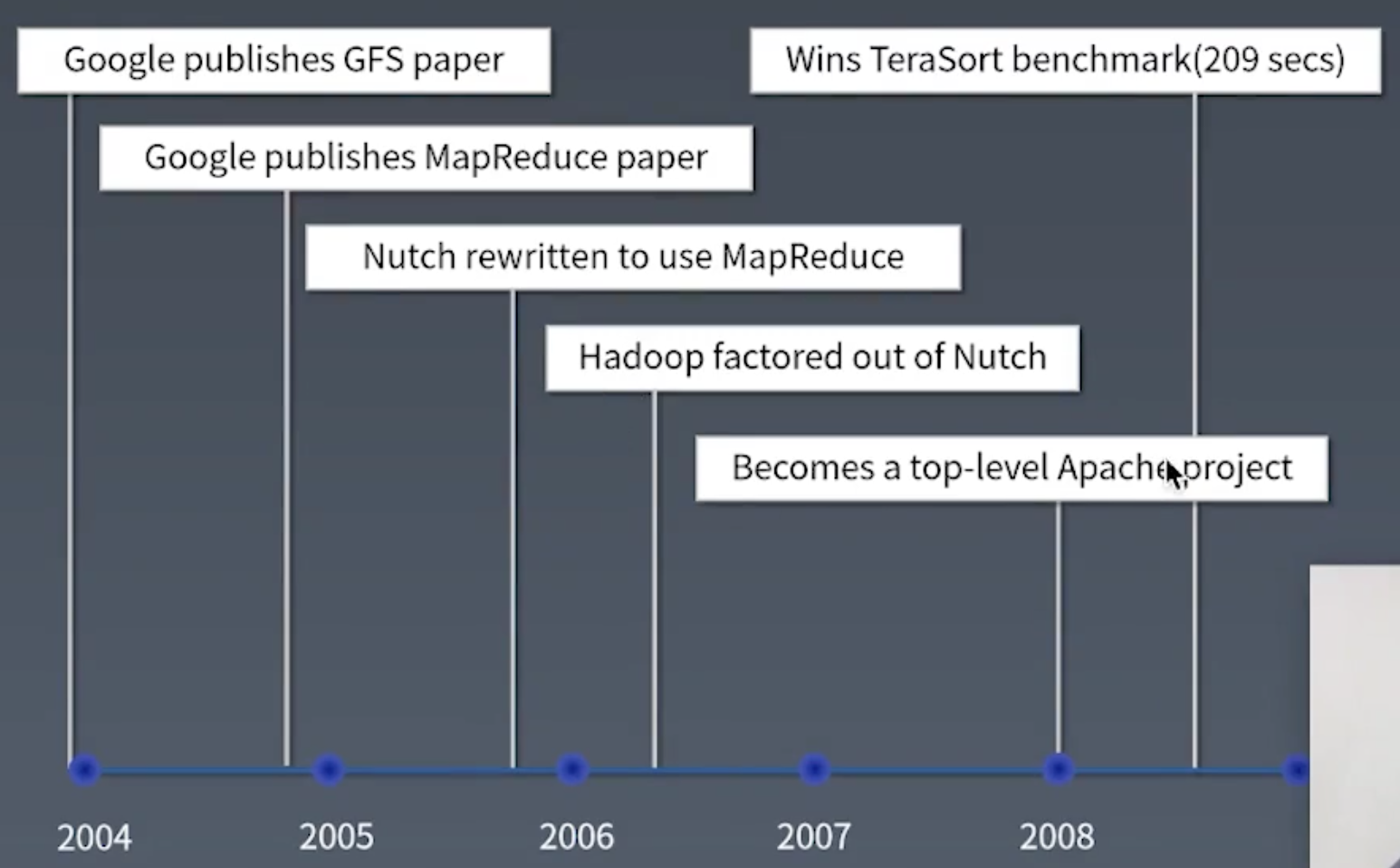
大数据框架
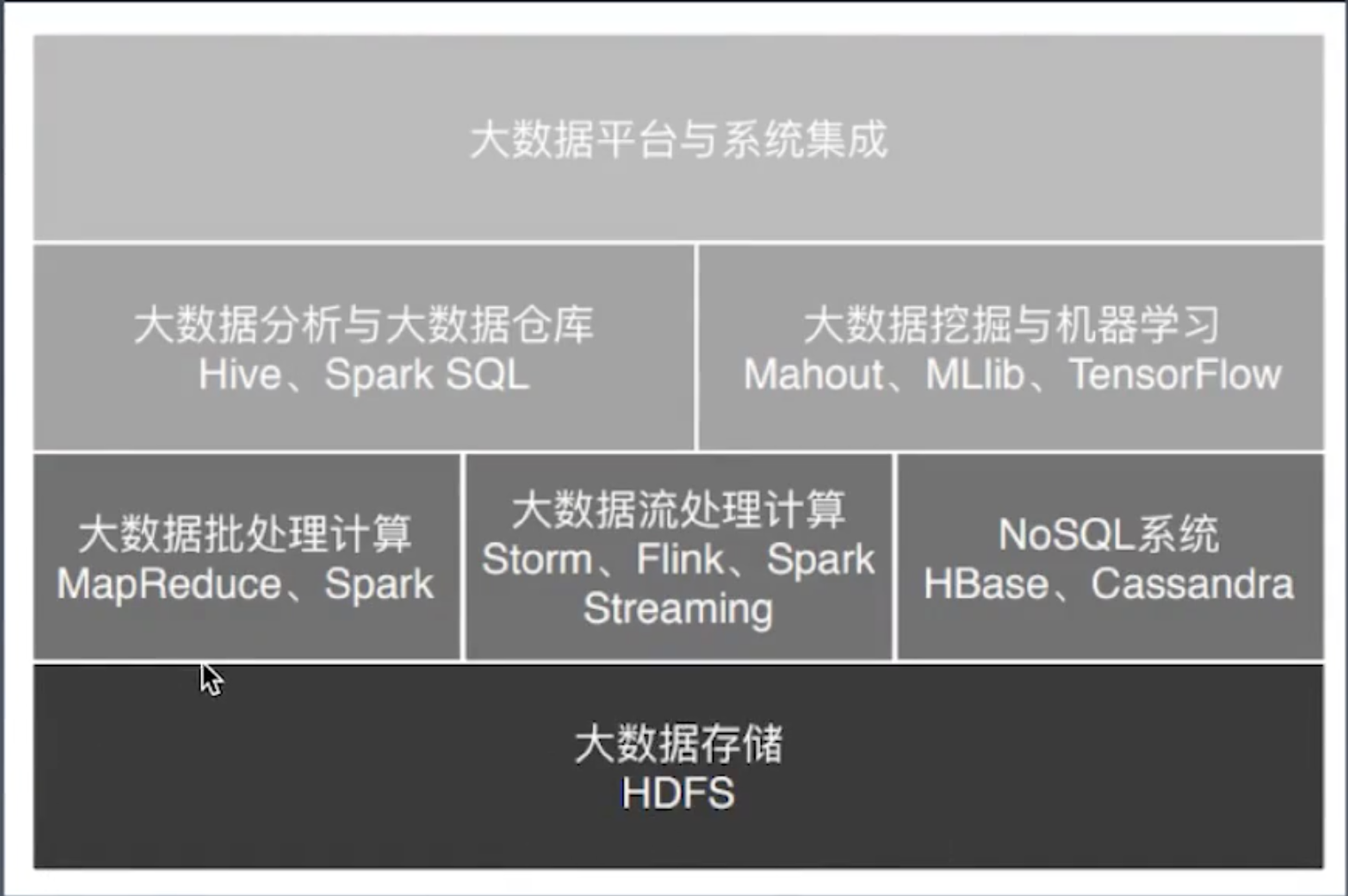
大数据应用发展史
- 搜索引擎时代
- google/yahoo/baidu
- 数据仓库时代
- 数据分析
- hive
- 数据挖掘时代:2012年左右
- 关联推荐
- 阿里千人千面
- 今日头条
- 机器学习:2015年左右
- 通过统计数据规律, 预测正在发生的事情
大数据应用领域
- 医学影像智能识别
- 病历大数据智能诊疗
- AI外语老师
- 智能截图
- 舆情分析
- 大数据风控
- 新零售
- 无人驾驶
HDFS
文件存储要解决的两个问题
- 如何存储大量数据
- 数据以数据块的形式存储在DataNode的磁盘中
- 所有的块可以赋予一个文件进行读写
- 如何快速的存储
- 数据分块以后就可以同时并发读写
- 如何保证存储数据的安全性
- 跨机架备份复制
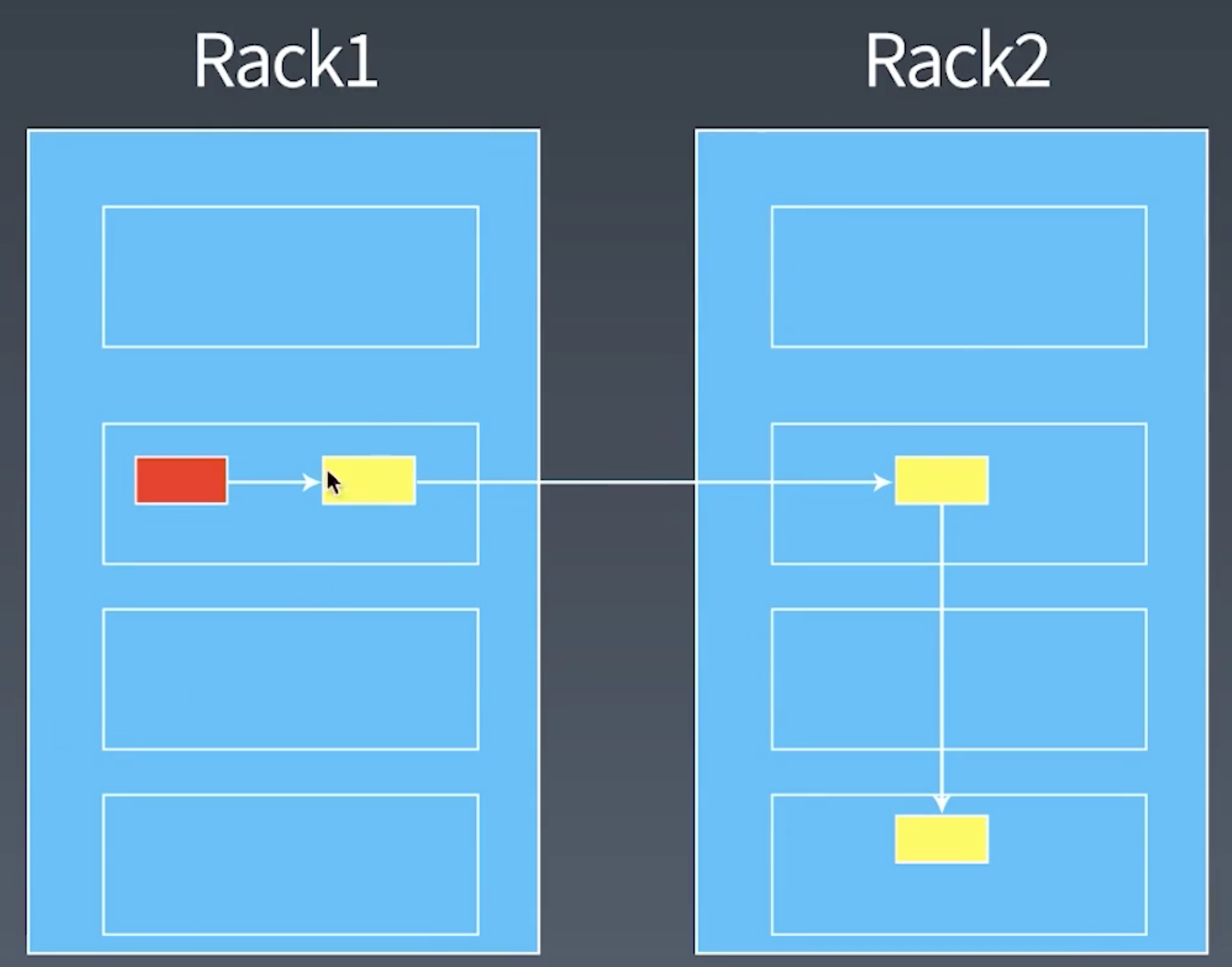
- 数据块默认会复制三份
- 跨机架备份复制
RAID是在同一个服务器的多块硬盘上, 通过数据分片进行数据存储; 而HDFS是通过在多个服务器上进行分片实现;
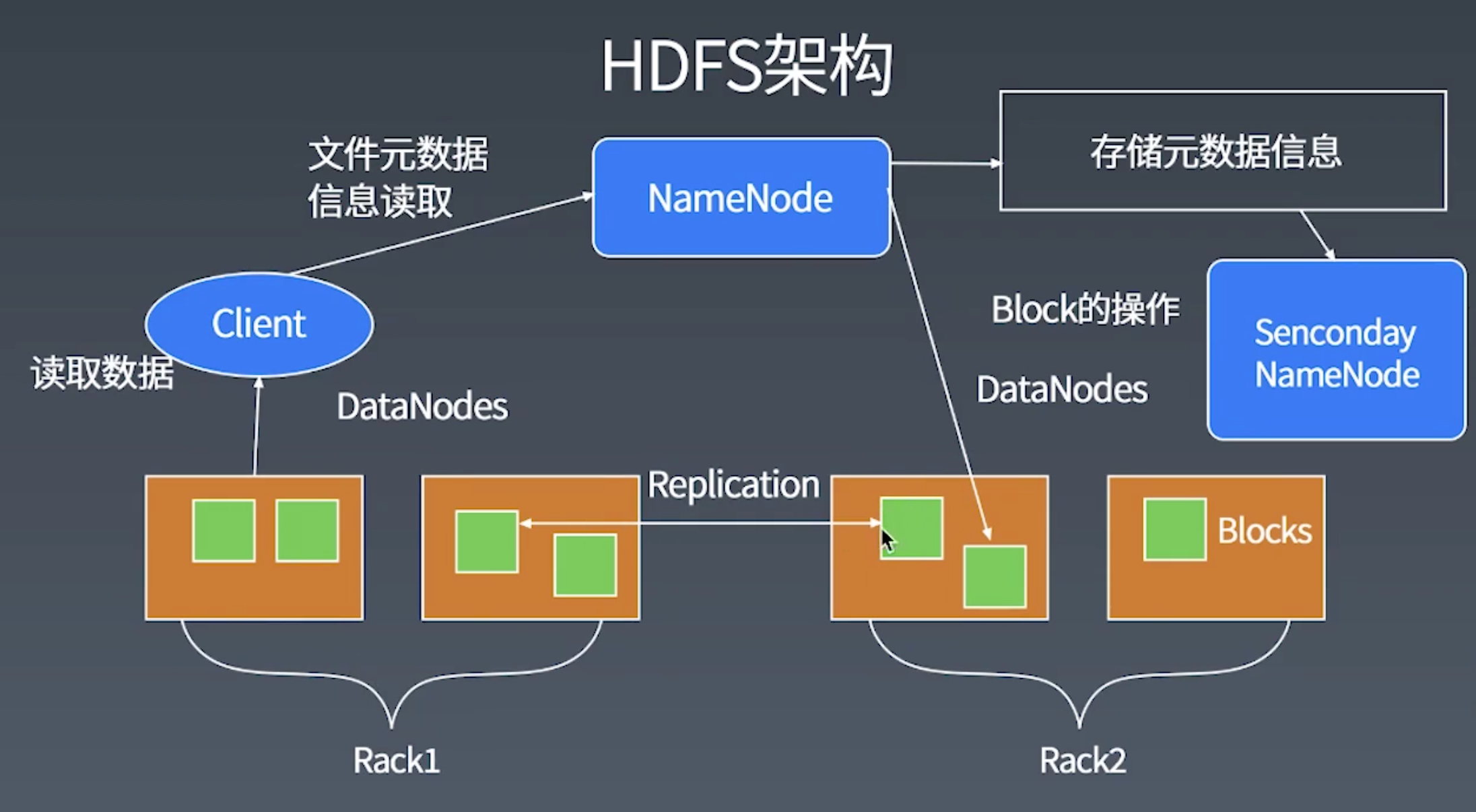
HDFS中有两个重要的角色: NameNode和DataNode.
- nameNode用于记录文件的元数据信息, 文件路径, 复制数, 创建者等等信息
- dataNode用于存放数据本身
- 交互
- nameNode不会主动联系dataNode
- dataNode启动后向nameNode注册, 完成后, 周期性(1小时)的向nameNode上报所有的块信息
- 心跳每三秒一次, 包括nameNode向该dataNode的命令, 如果超时10分钟没有收到, 则认为该dataNode失效
HDFS架构
存储细节
m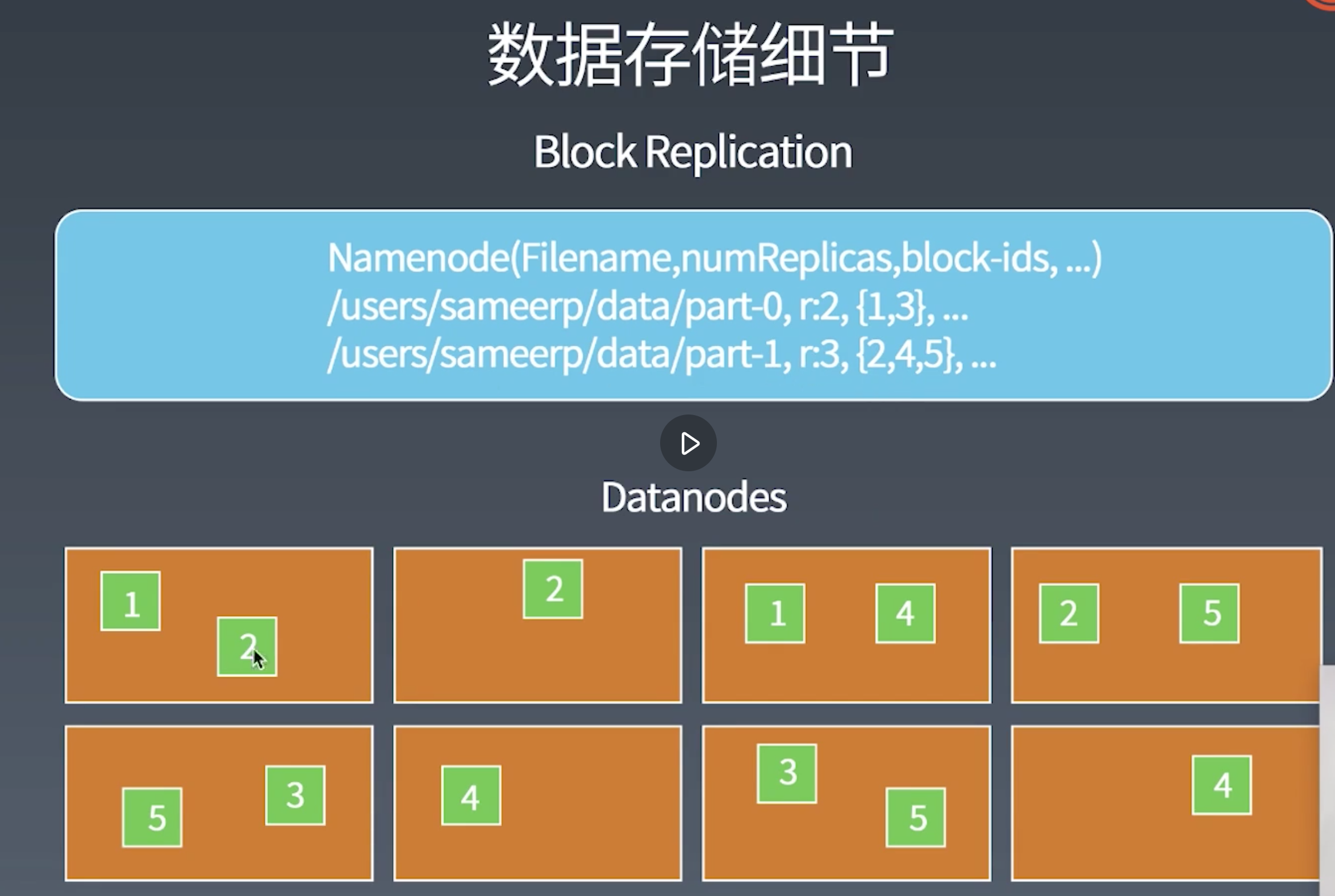
HDFS设计目标
- 适合的场景
- 以流式数据访问模式存储超大文件
- 运行在商用硬件集群上
- 一次写入多次读取
- 不适合的场景
- 低延迟的数据访问
- 大量小文件
- 多用户随机写入修改文件
HDFS如何写文件

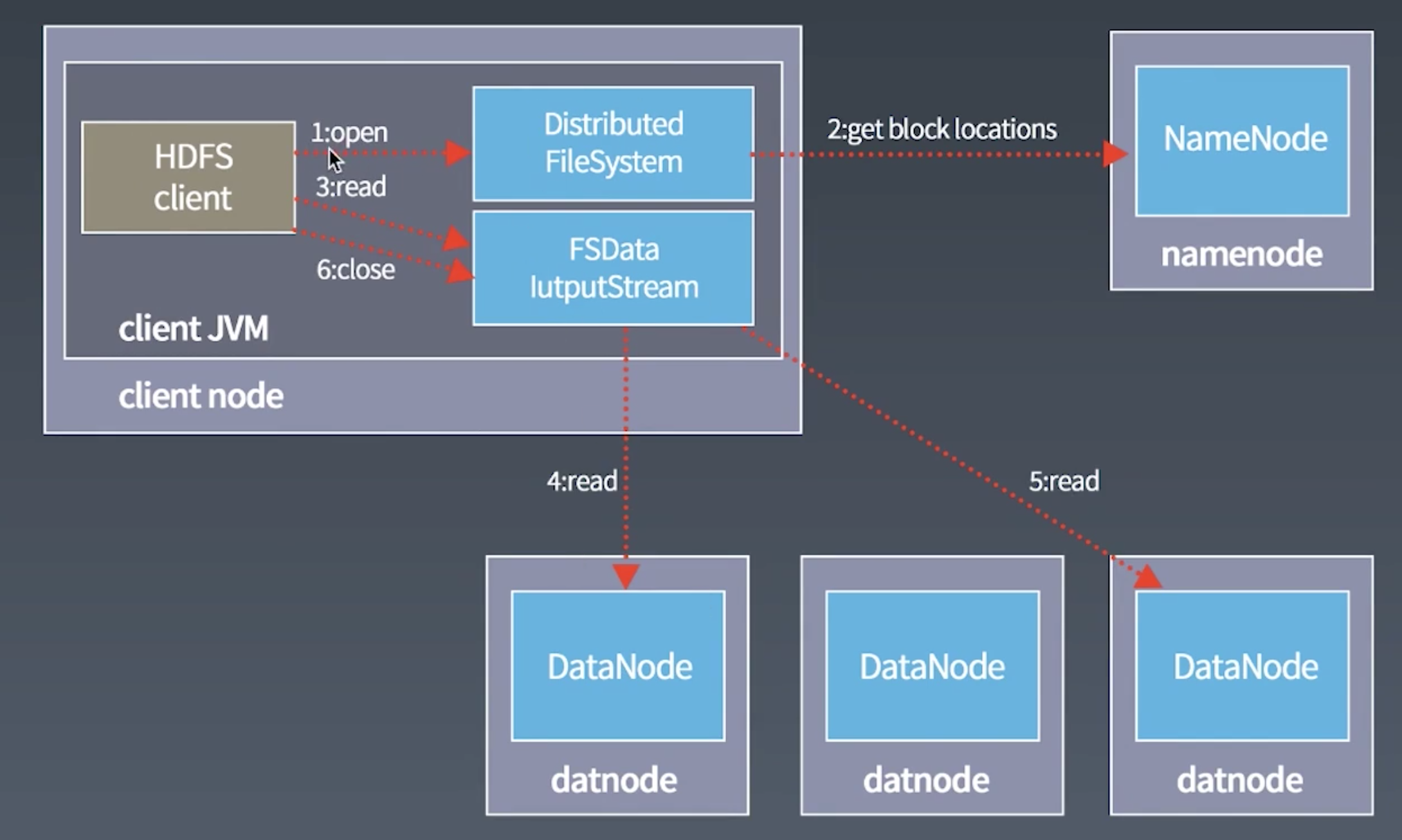
HDFS如何读文件
如何保证高可用
- DataNode的磁盘坏了怎么办
- DataNode正常时, 将坏掉的数据块上报给nameNode
- nameNode会返回将坏掉的数据块复制到哪些新的数据块
- dataNode进行数据块复制
- 时间较短, 因为心跳, 3s即可发现, 开始复制
- DataNode服务器挂了怎么办
- dataNode每3s向nameNode发送心跳, 如果10分钟dataNode没有发送成功, 则nameNode认为该dataNode已经dead
- nameNode将取出该dataNode上的block,进行复制
- 时间较长, 10分钟,而且数据量较大
- NameNode挂了怎么办
- 早期: 持久化元数据
- 操作日志, 记录文件的创建,删除,修改文件等操作
- Fsimage
- 主从nameNode
- zookeeper
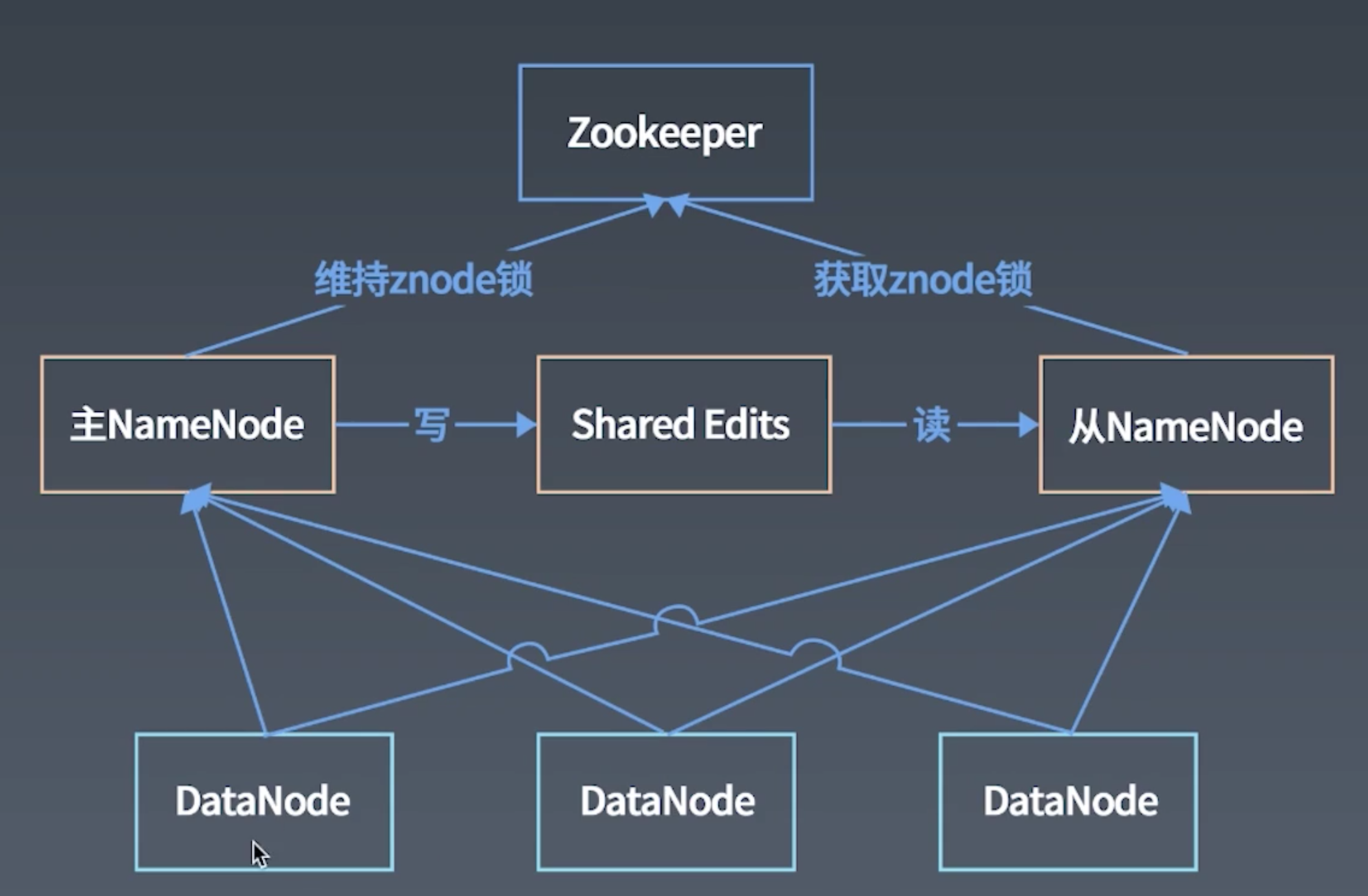
- 因为要发心跳, 同时只会有一个主节点使用
- zookeeper
- 早期: 持久化元数据
- client挂了怎么办
- 一致性问题
- HDFS一致性模型
- 一致性问题
开放接口
- HDFS文件接口
- Java接口
MapReduce
是对大规模数据进行计算的框架, 思路是, “移动计算比移动数据更划算”
执行时是把MapReduce分发到数据所在服务器上进行计算, 在本地进行计算, 以提高计算性能.
MapReduce特性
- 自动实现分布式并行计算
- 容错
- 提供状态监控工具
- 模型抽象简洁, 程序员易用
举例: WordCount
- 统计每个单词出现的次数

- map类的map方法

- key: 表示value在文件中的偏移量
- value: 表示从文件中读取的某一行
- reduce类的reduce方法

- key: 表示map()返回的key, 即每个单词
- values: 表示map()返回的每个单词的数量, 固定是1
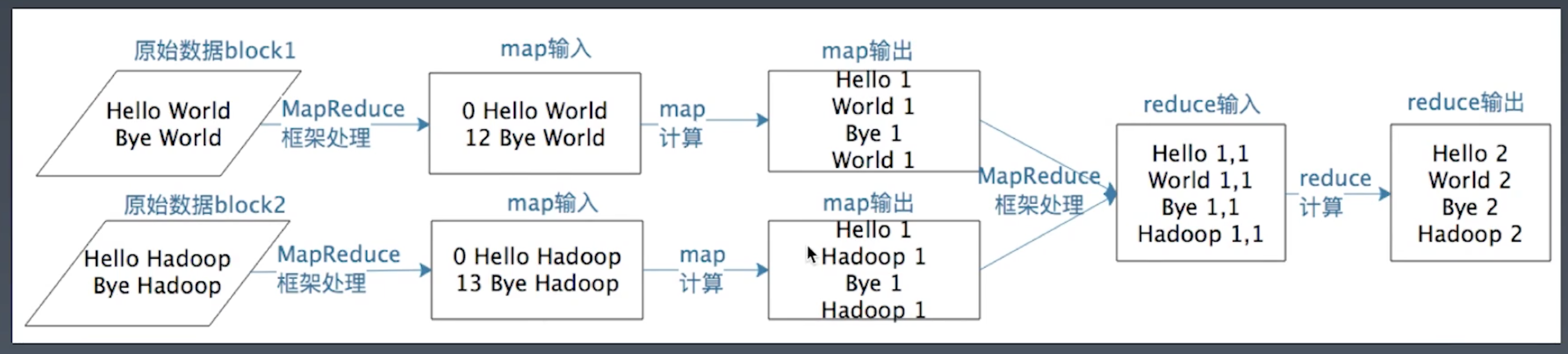
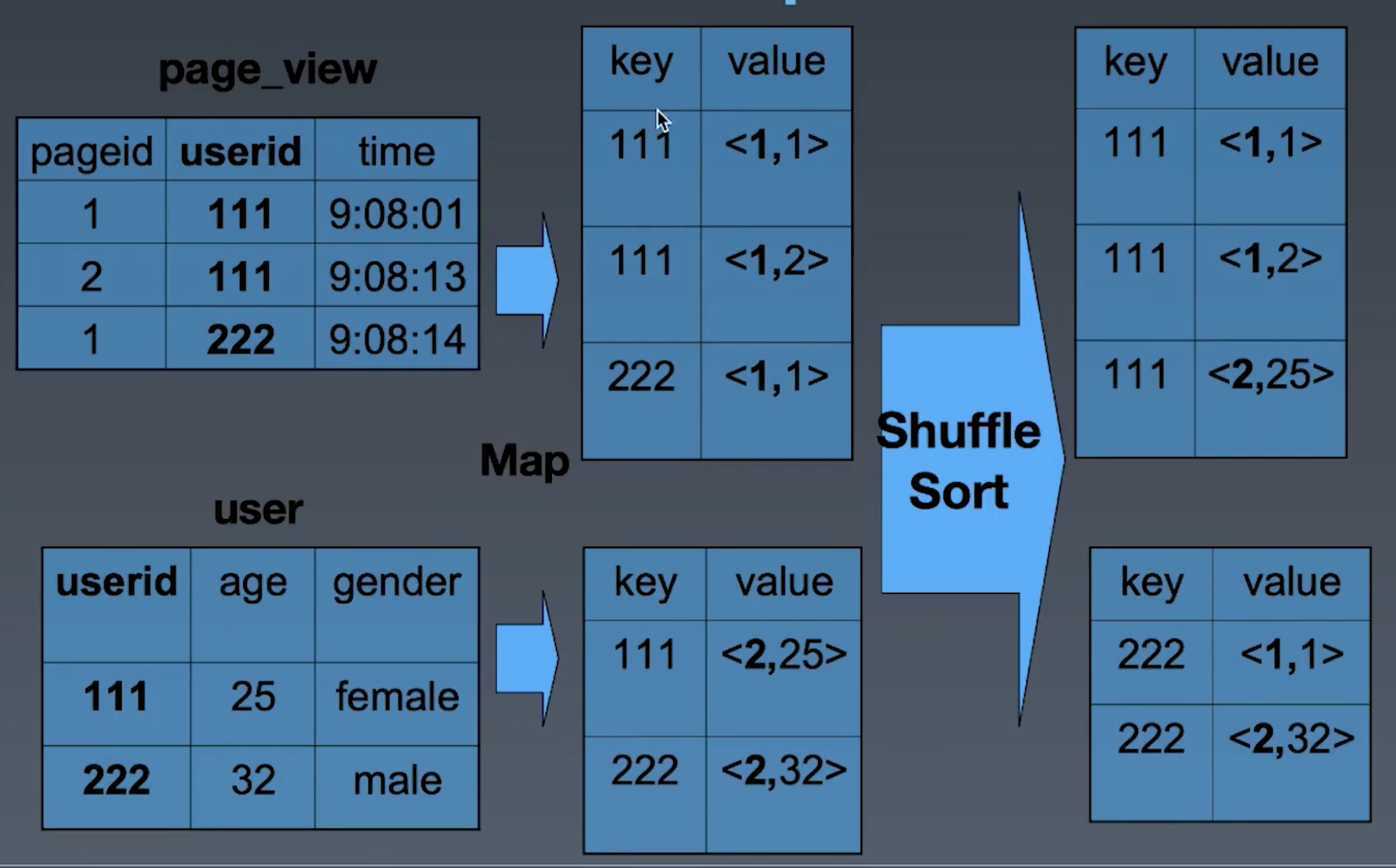
MapReduce的实现过程
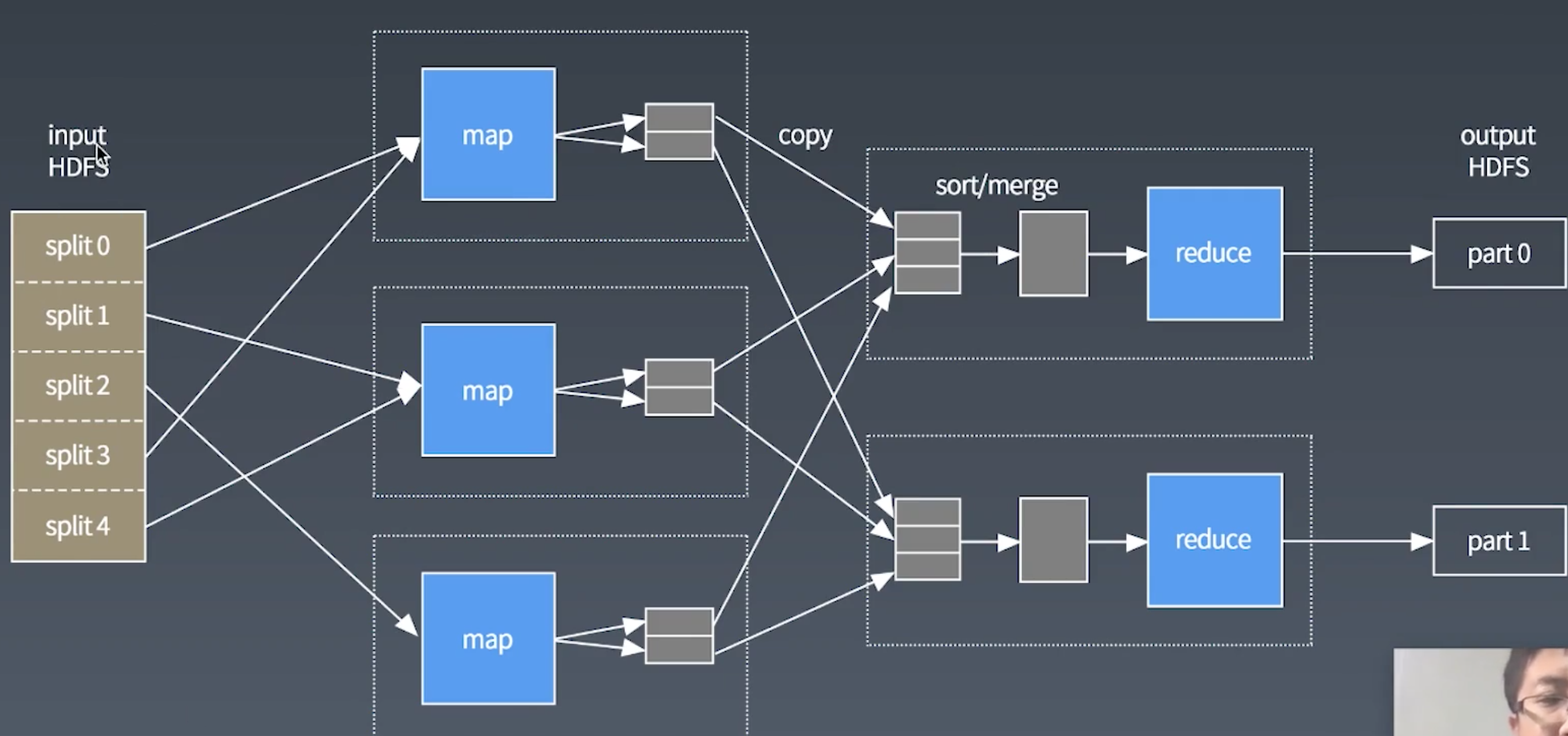
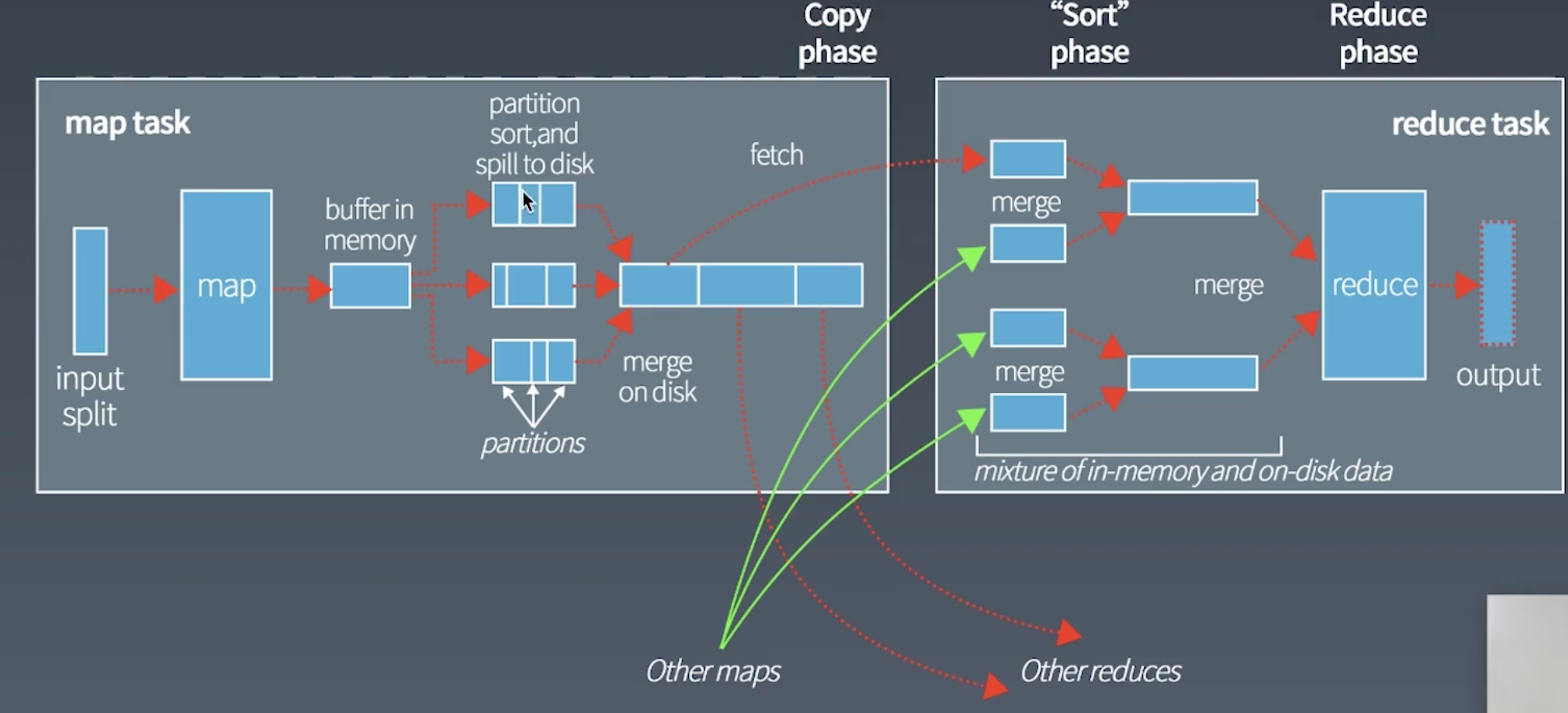
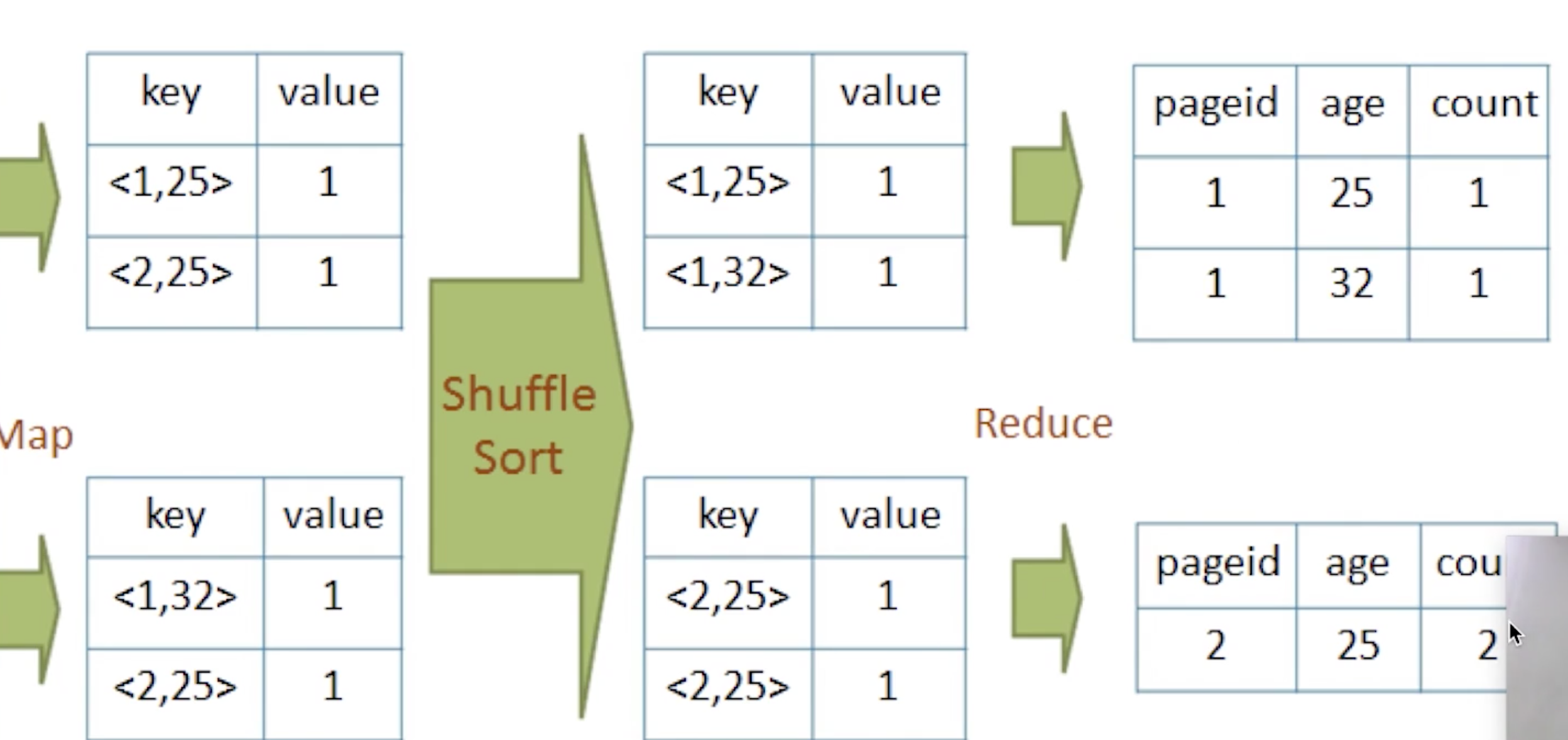
shuffle: 将不同的map的输出中的相同的key, 通过网络copy放到不同的reduce中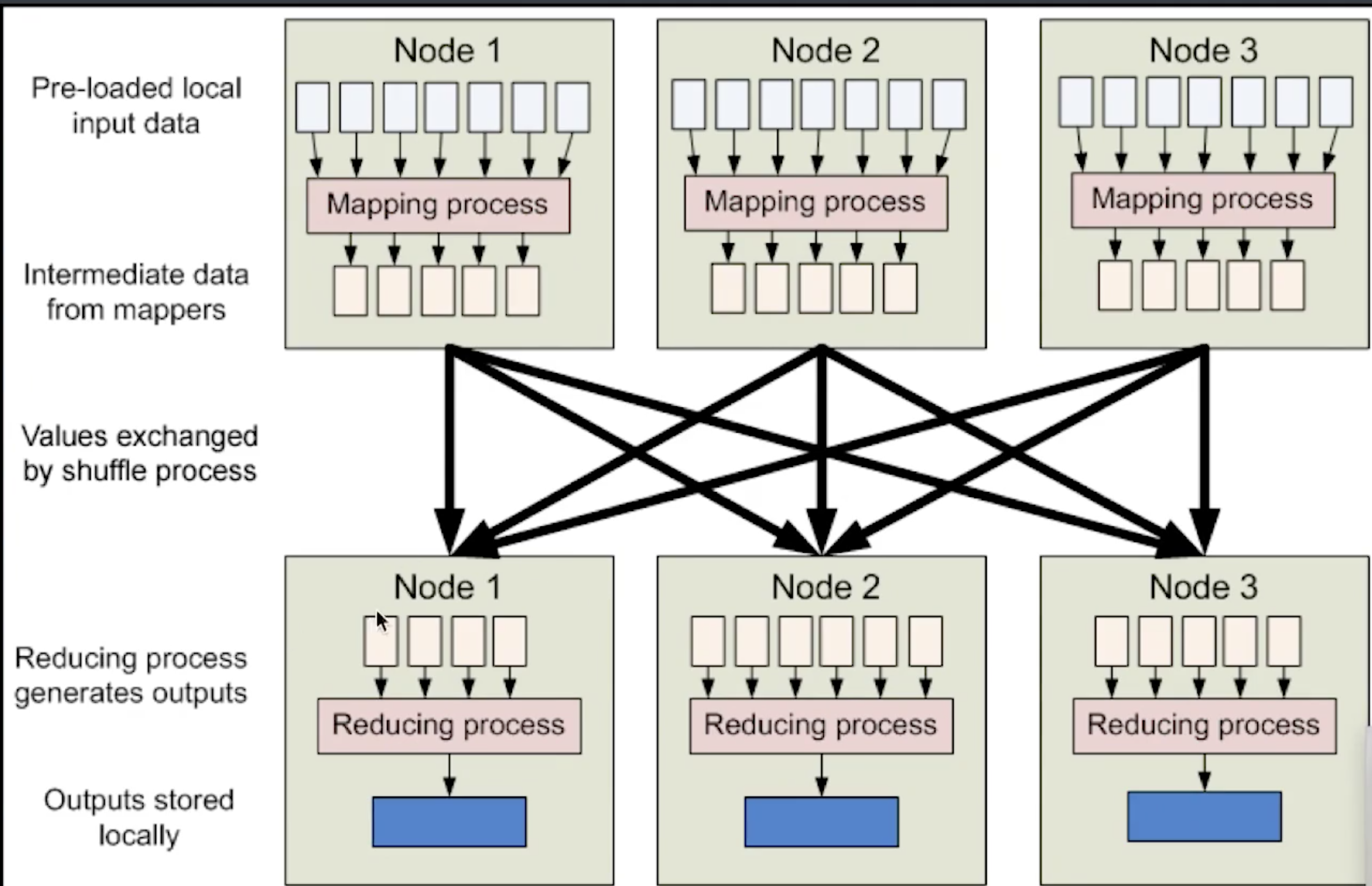
MapReduceV1 的整体架构

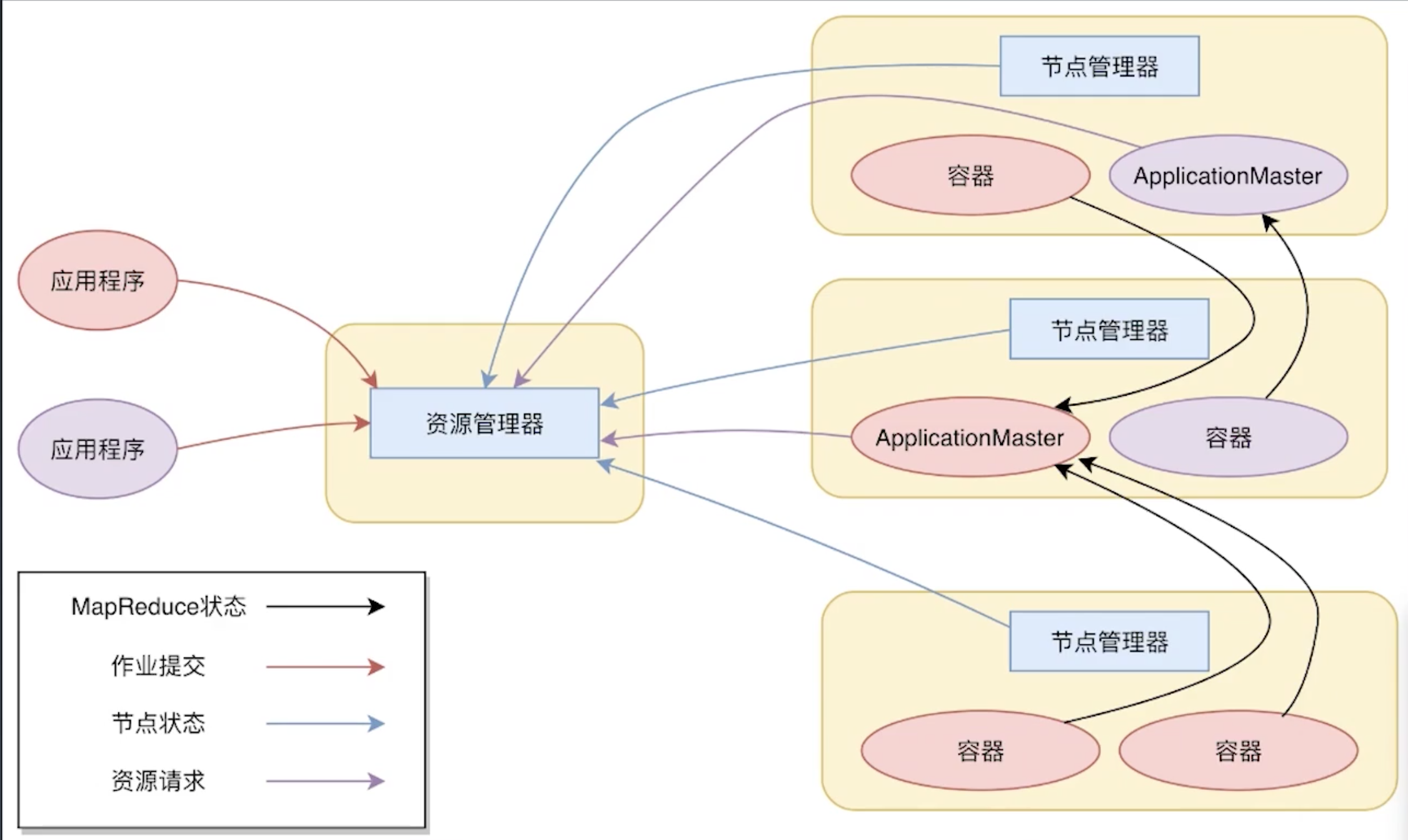
YARN: 下一代MapReduce框架
- 不再是传统的MapReduce框架, 甚至与MapReduce无关
- 一个通用的运行时框架, 用户可以自己编写自己的计算框架, 在该运行环境中运行.
MapReduce架构中, 最重要的是要把MapReduce程序分发到大数据集群的服务器上, Hadoop1中, 这个过程主要通过TaskTracker和JobTracker完成.
缺点是, 服务器集群资源调度管理和MapReduce执行过程耦合在一起, 就会导致如果想在当前集群中运行其他任务, 就无法统一使用集群中的资源了
YARN架构
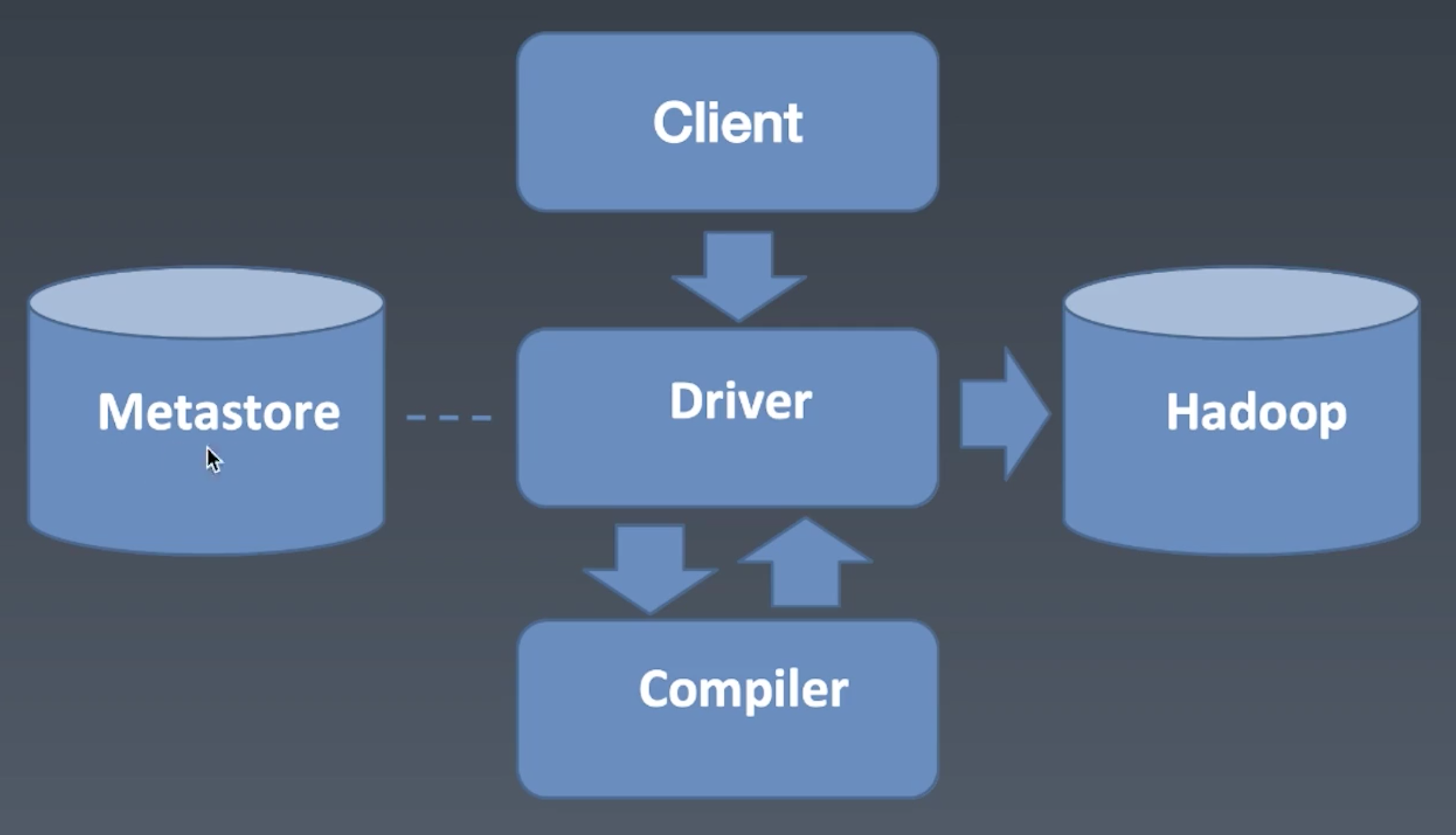
Hive
大数据任务大部分是需要sql计算的, Hive 提供将sql转换为mapReduce的功能.

MapReduce的实现: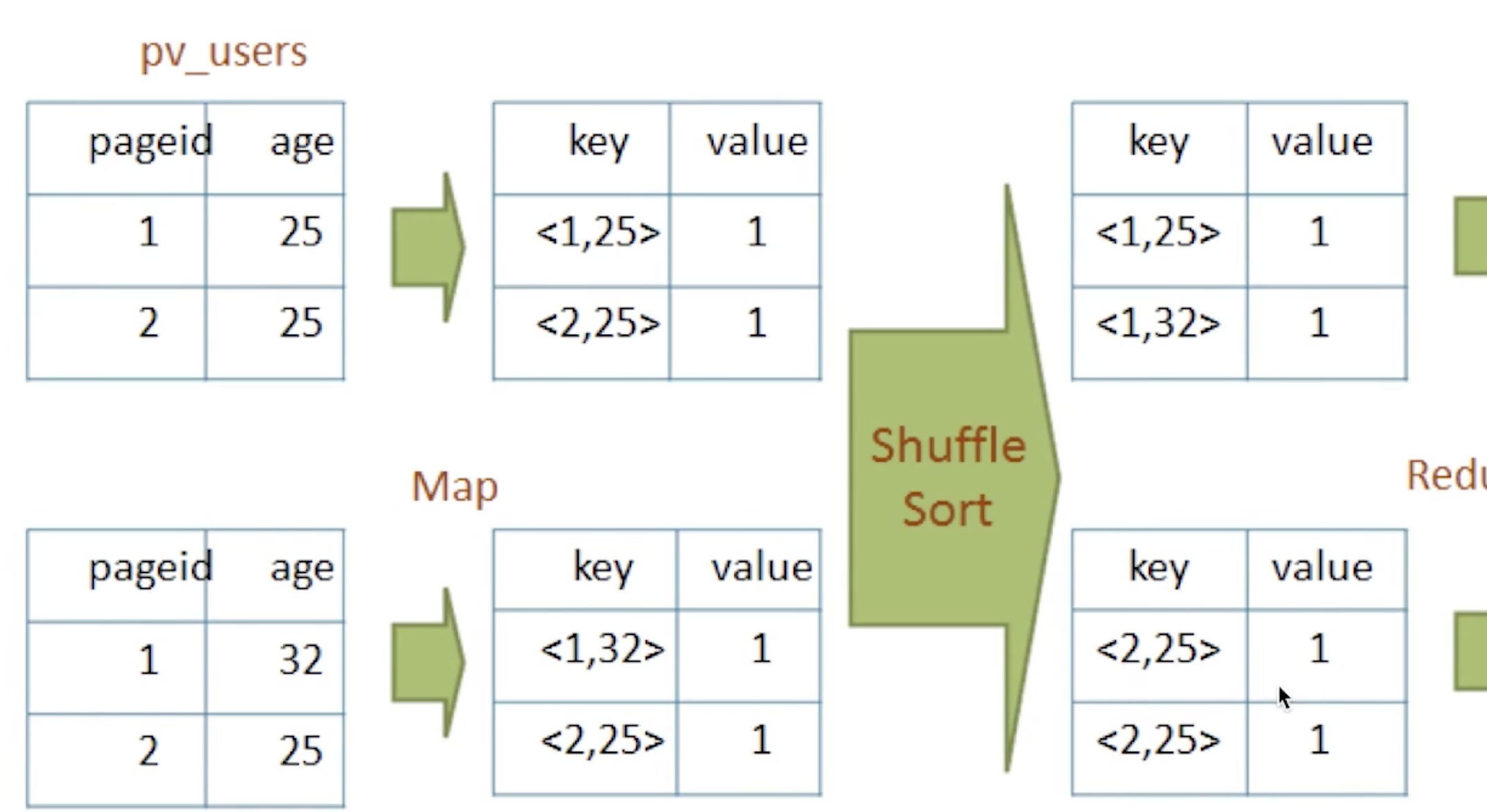
Hive架构
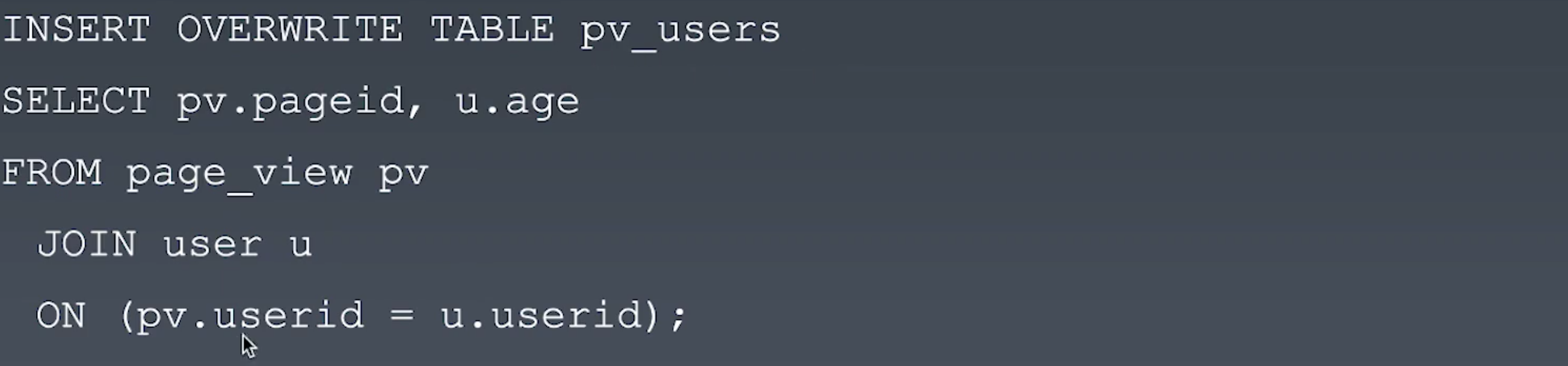
HiveQL-join


若有收获,就点个赞吧
0 人点赞
