数据结构与算法
时间复杂度
- 不是计算程序的具体运行时间,而是算法执行语句的次数
- O(2^n) 表示对n个数据处理需要进行2^n次计算
- 多项式时间复杂度:
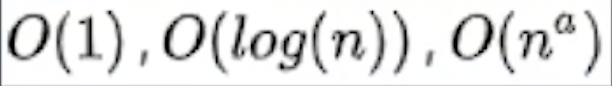
- 非多项式时间复杂度:

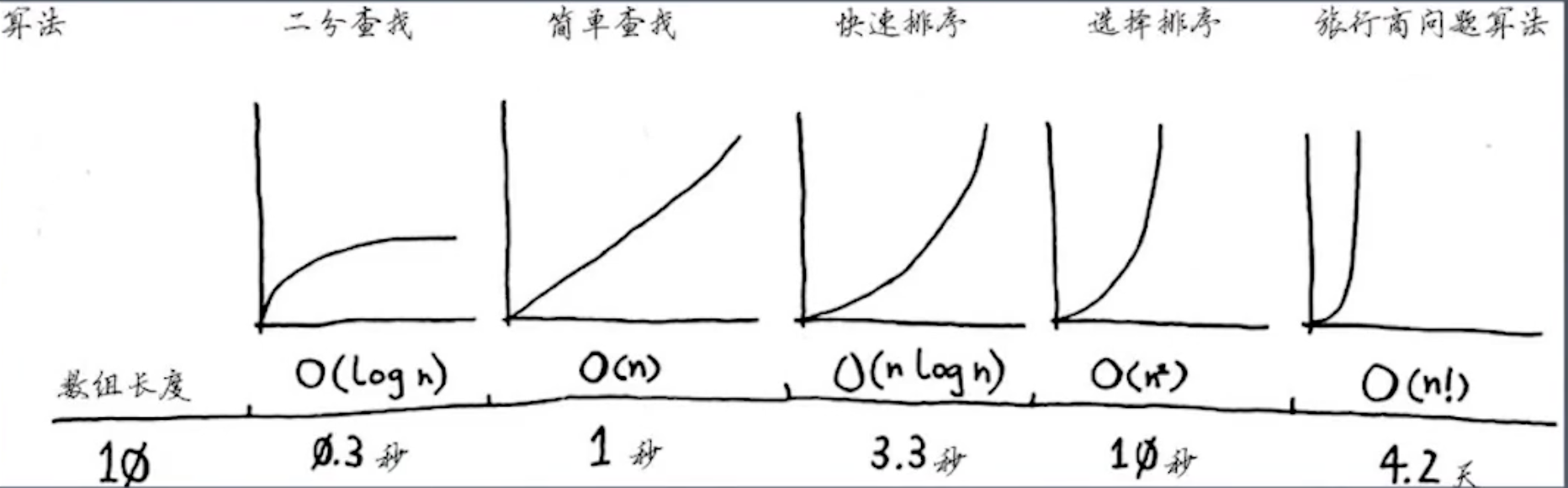
- 常见几个算法的时间复杂度
空间复杂度
- 一个算法在运行过程中临时占用存储空间大小的度量
- O(n)表示需要临时存储n个数据
NP问题
P问题:能在多项式时间复杂度内解决的问题,常规时间复杂度
NP问题:能在多项式时间复杂度内验证答案正确与否的问题
NP ?= P
比如数独,验证是NP问题,但解法并不是P问题
基本数据结构
- 数组
- 内存中一组连续的空间
- 数组中必须存放相同的数据类型
- 基于以上两个规则,根据第一个数据的内存地址,就可以计算得出其他数据的内存地址
- 随机快速读写
- 根据下标访问数据,时间复杂度为O(1)
- 链表
- 可以使用零散的内存空间
- 每个元素都必须包括一个指向下一个数据元素的内存地址的指针
- 想要在链表中查找一个数据,必须变量链表,所以时间复杂度是O(n)
- 增删数据在链表中的效率比数组更好,数组中增删数据,可能会导致其他数据的位置变化,而链表不需要,链表的时间复杂度是O(1)
- 查找数据在数组中的效率比链表更好
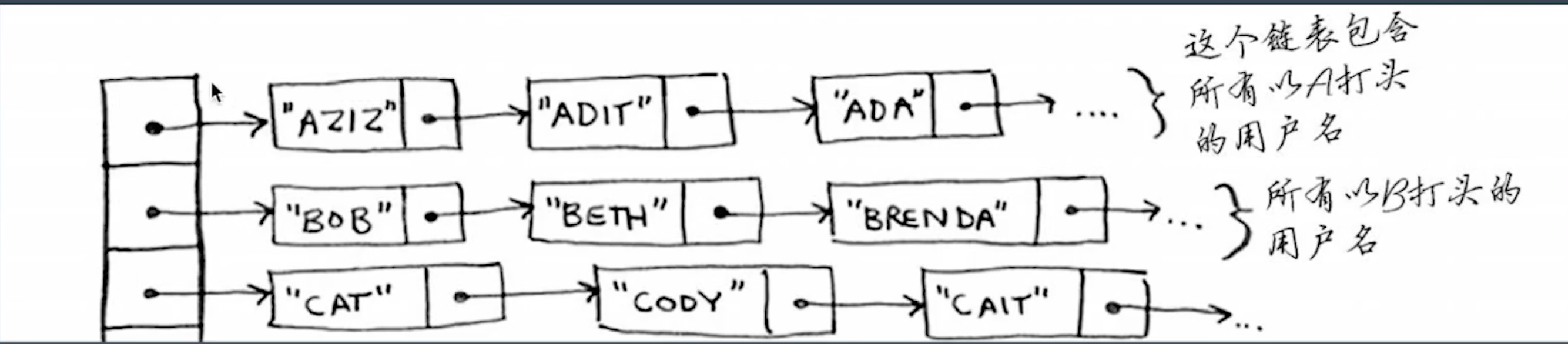
- 数组链表结合,实现数据的快速查找和增删
- 根据首字母查找
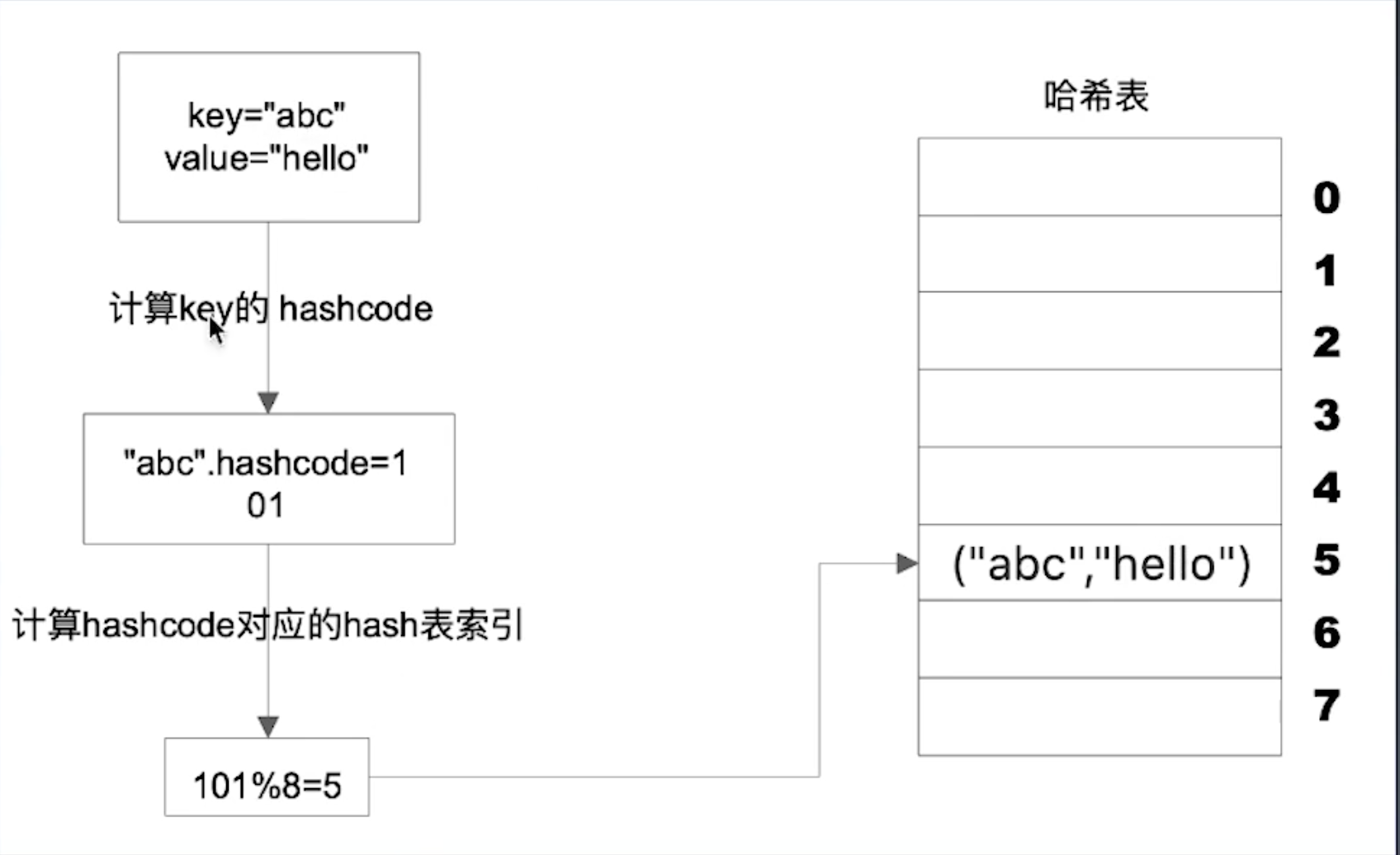
- Hash表
- 能实现快速访问数据,也能快速增删数据,时间复杂度都是O(1)
- Hash冲突
- 当出现多个key计算出同一个HashCode
- 使用链表解决
- Hash碰撞
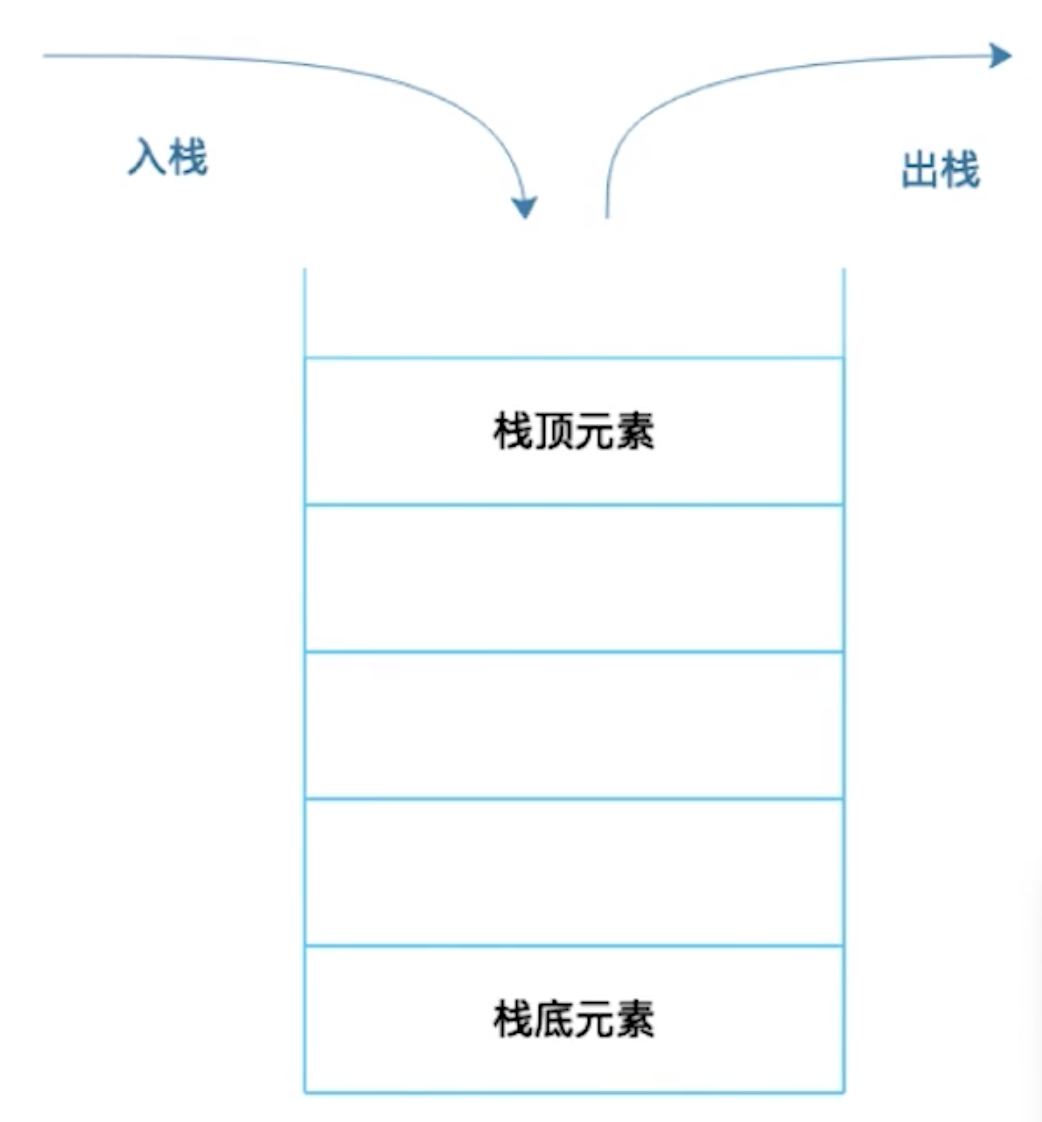
- 栈
- 数组和链表都是线性表(每个节点都有唯一的前驱和唯一的后继)
- 在线性表基础上加入限制规则就会出现新的数据结构:栈
- 实现了『后进先出』
- 队列
- 也是一种受限的线性表
- 实现的是『先进先出』
- 应用场景:消息队列,生产者消费者

- 应用:
- 搜索好友中关系最近的有钱人
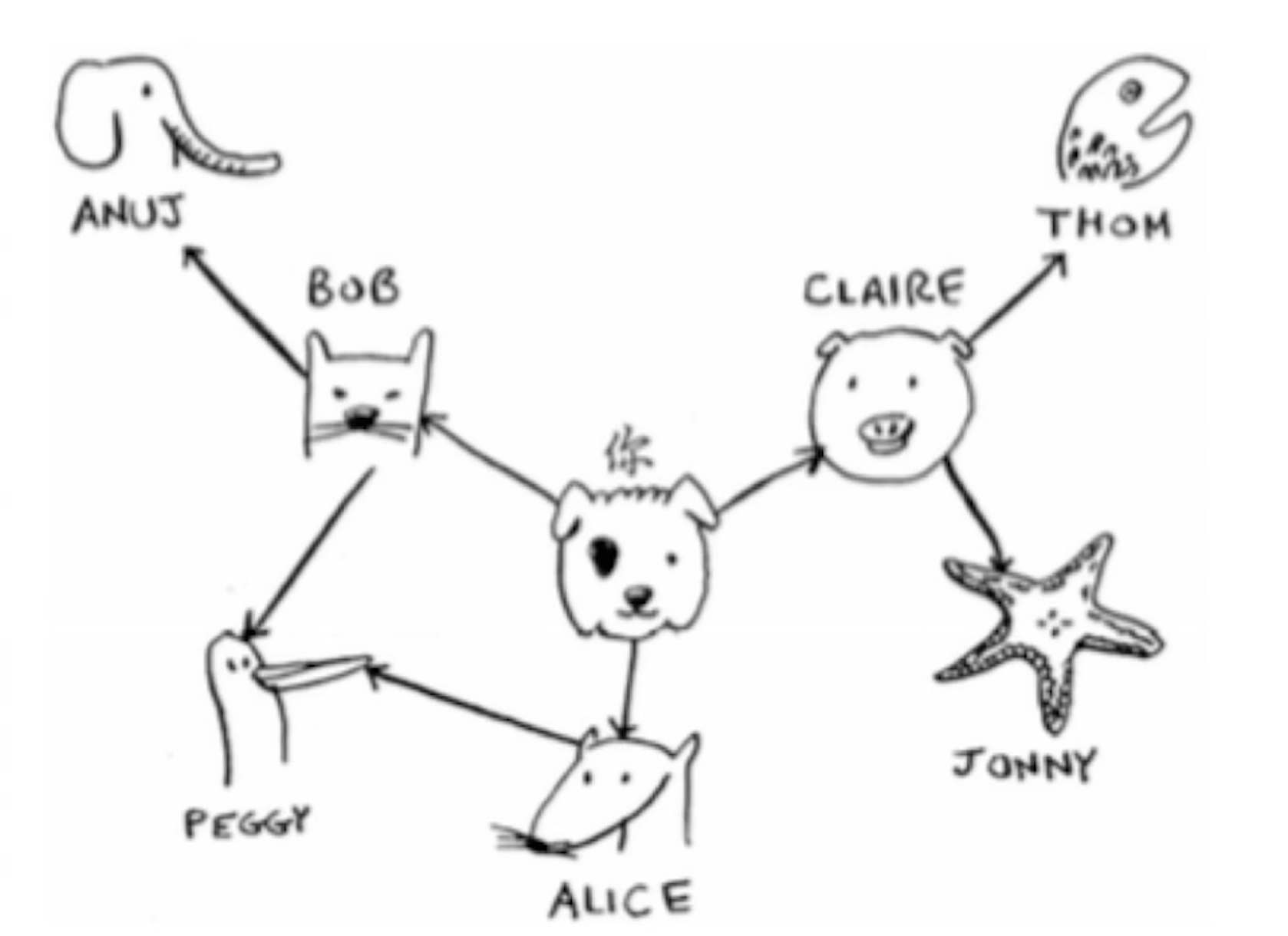
- 用队列搜索最短路径
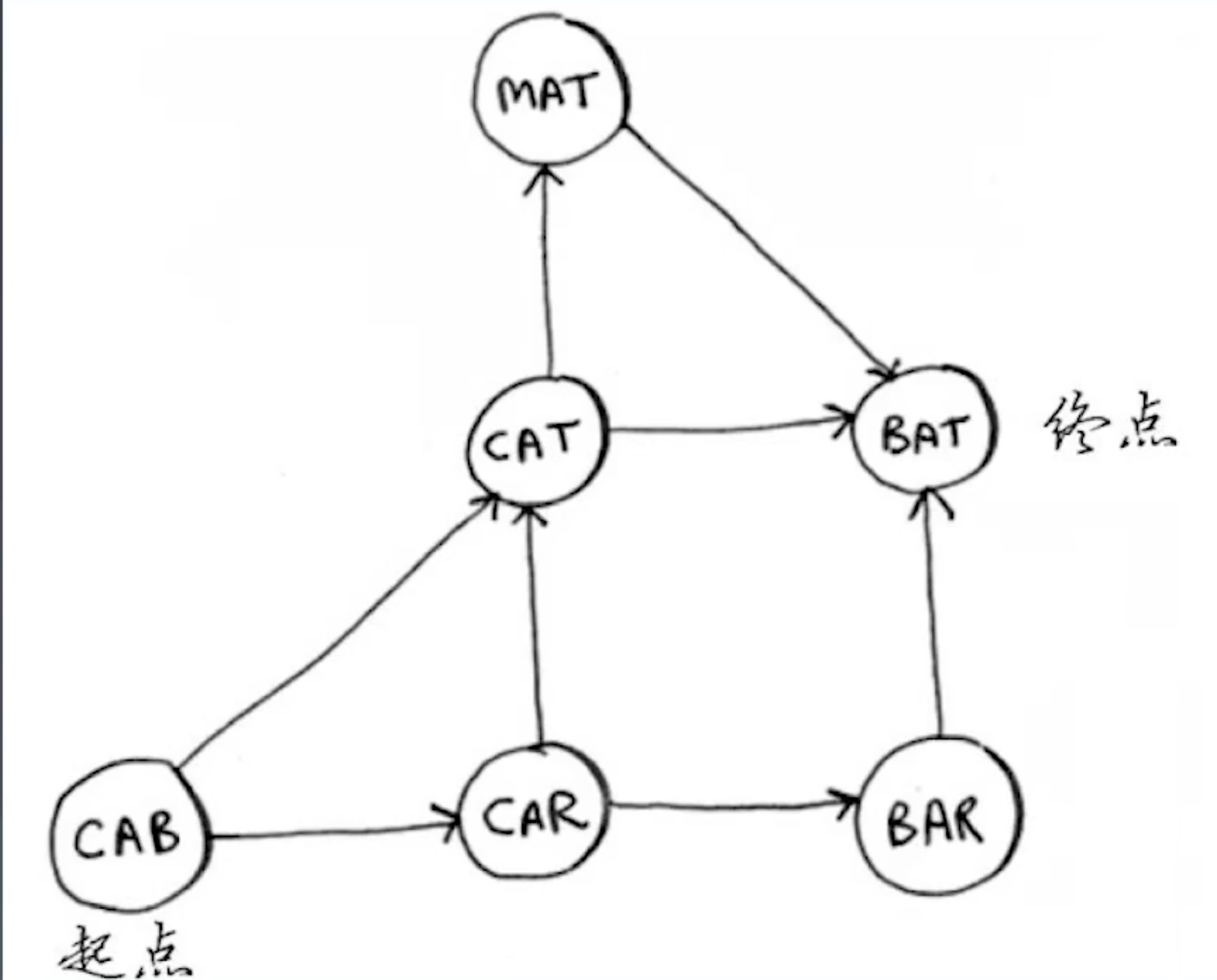
- 搜索好友中关系最近的有钱人
- 树
- 不是线性表
- 二叉排序树
- 左子树上所有节点的值都小于或等于它的根节点的值
- 右子树上所有节点的值都大于或等于它的根节点的值
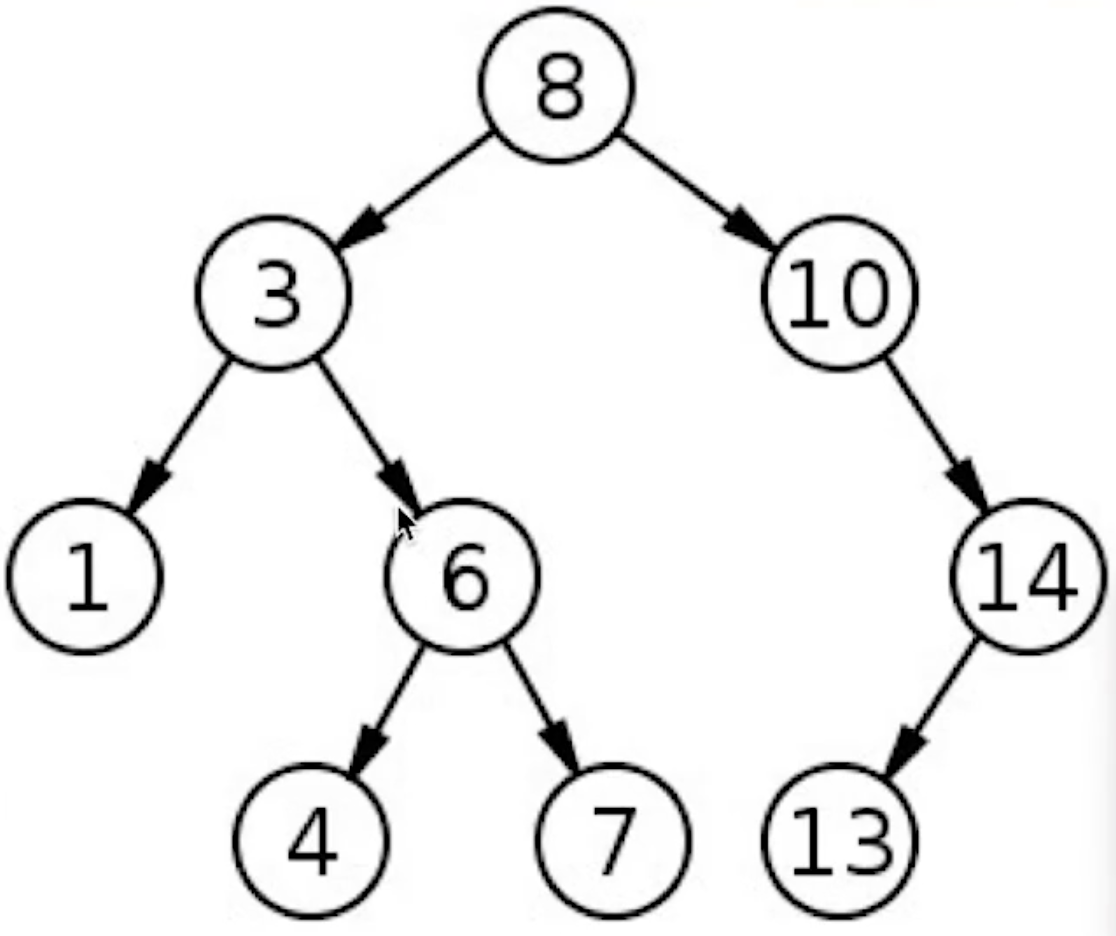
- 时间复杂度是O(logn)
- 4的查找过程:
- 4<8 : 8的左子树
- 4>3: 3的右子树
- 4<6: 6的左子树
- 平衡二叉排序树和不平衡二叉排序树
- 从任何一个节点出发,左右子树深度只差绝对值不超过1
- 平衡二叉排序树时间复杂度是O(logn), 而不平衡儿茶排序树不是
- 旋转二叉树恢复平衡
- 插入时,最多需要两次旋转就会恢复平衡
- 删除时,需要维护从被删节点到根节点这条路径上所有节点的平衡性
- 为了减少二叉树的平衡性维护,使用红黑树
- 红黑(排序)树
- 每个节点只有两种颜色
- 为了解决平衡二叉树时带来的复杂性问题。红黑树只是近似的平衡
- 通过限制增删节点时如何染色的规则,来保持平衡性
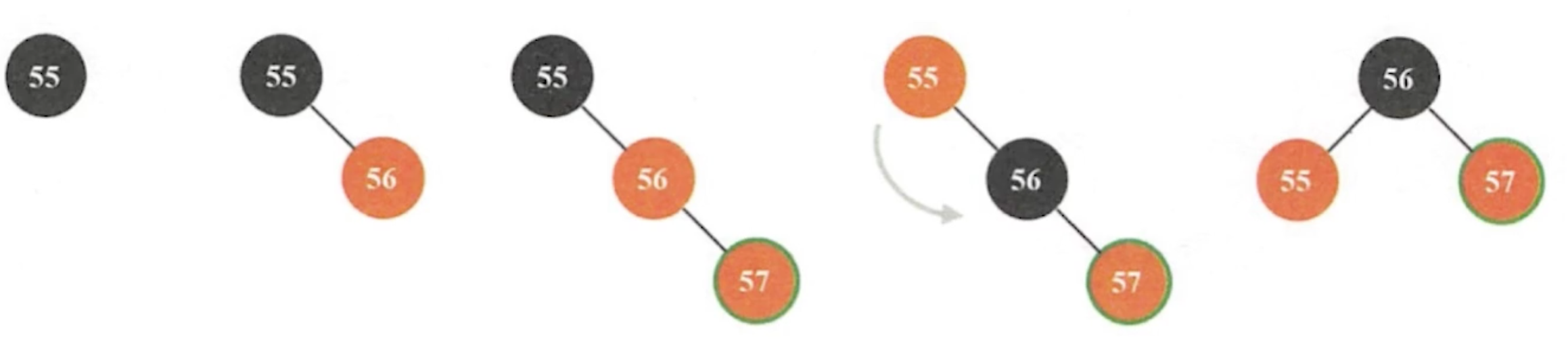
- 通过限制增删节点时如何染色的规则,来保持平衡性
- 约束
- 根节点是黑色的
- 每个叶子节点都是黑色的空节点
- 从根节点到叶子节点,不会出现两个连续的红色节点
- 从任何一个节点到叶子节点,这条路径上都有相同数目的黑色节点
- 红黑树VS平衡二叉树
- 红黑树最多只需要 三次 旋转就会达到平衡,时间复杂度是O(1)
- 大量增删时,红黑树的效率更高
- 红黑树的平衡性不如平衡二叉树,查找效率要差一些
跳表
穷举算法
- 递归算法
- 自己调用自己
- 在方法开始的地方,确定一个退出条件;否则会导致Stack Overflow异常
- 贪心算法
- 背包问题
- 动态规划
网络通信协议
OSI七层模型和TCP/IP四层模型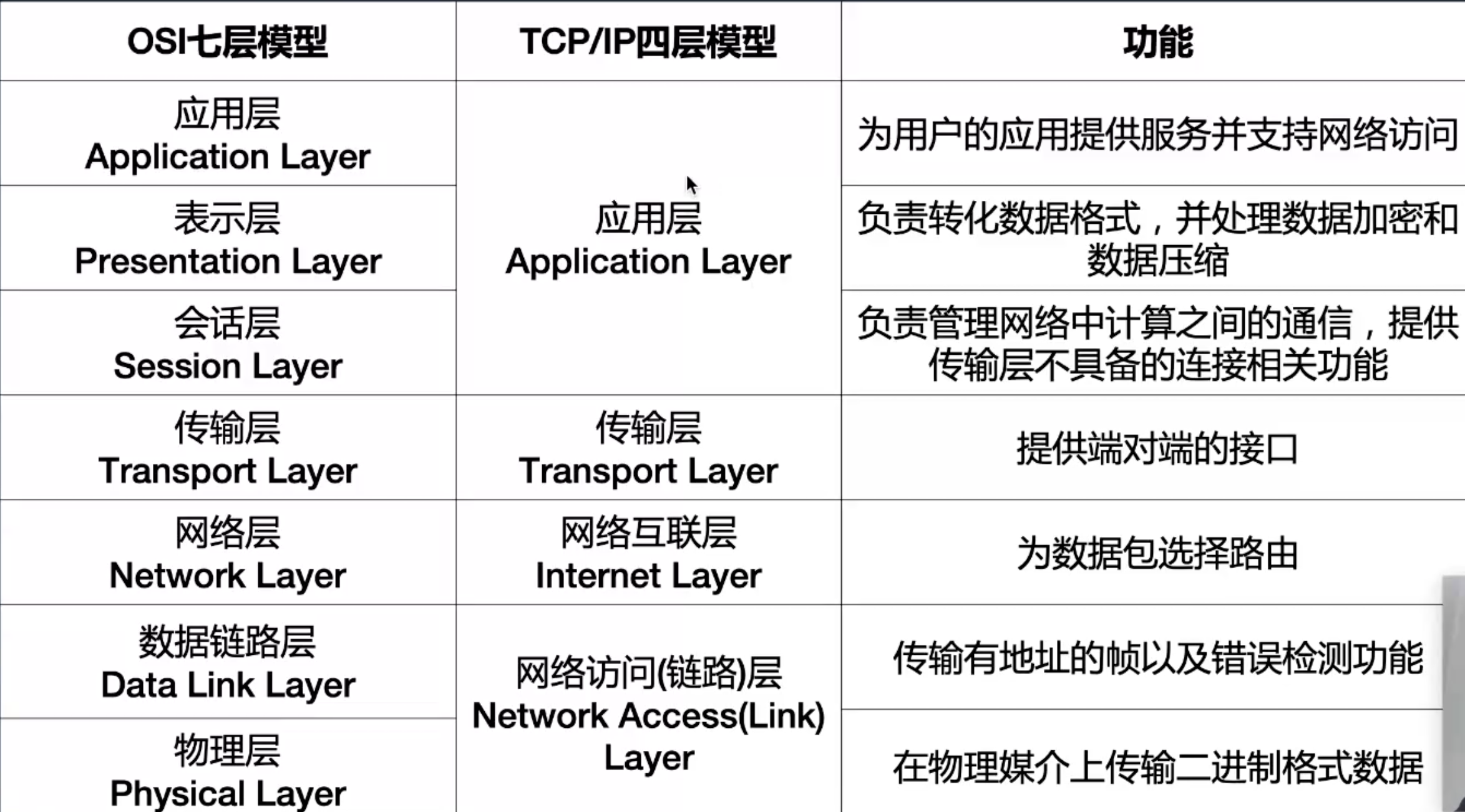
两台主机通信时打包解包的过程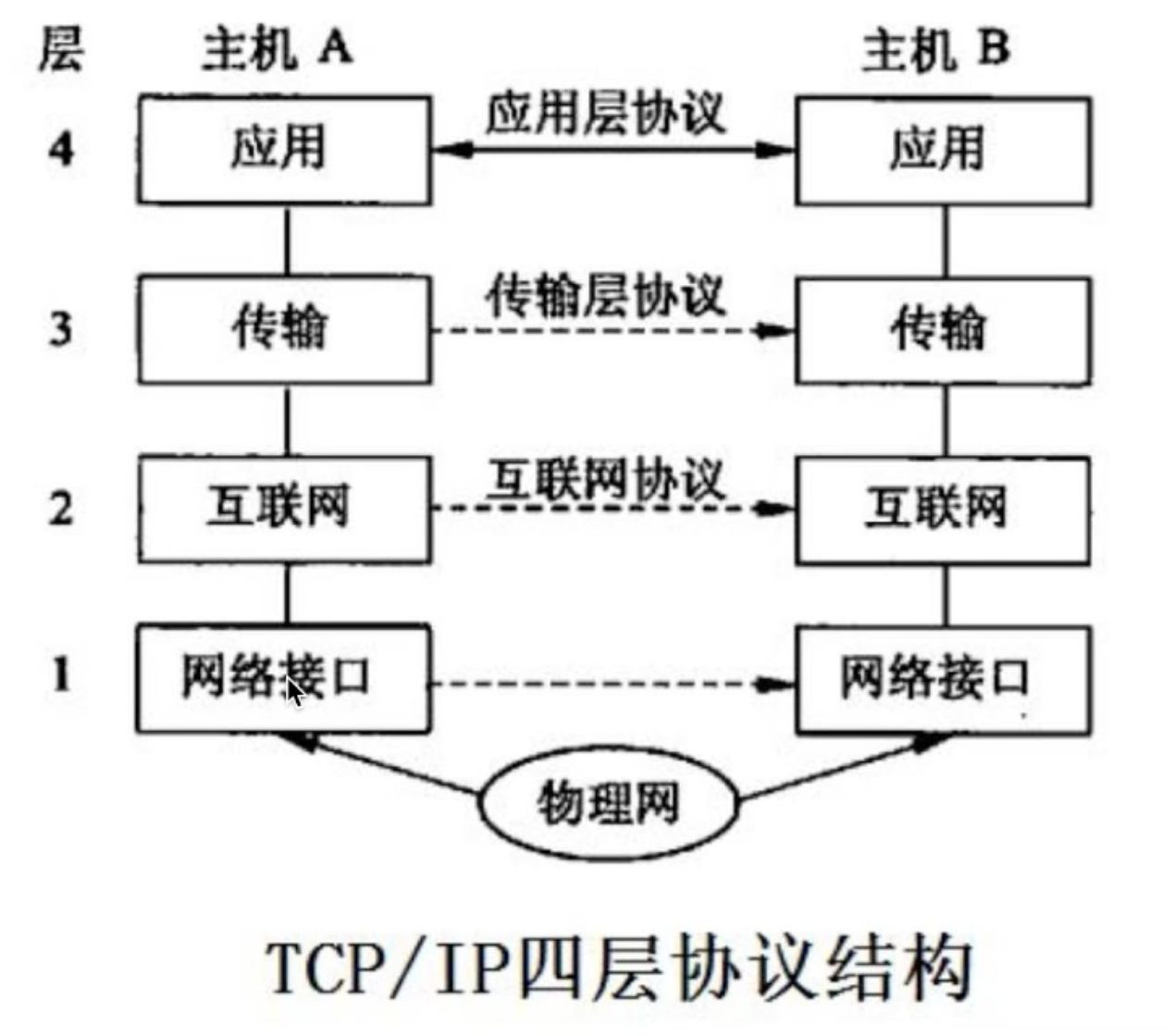
网络数据包格式
http协议版本之间的区别
1.0协议:每次连接都需要三次握手
1.1协议:引入保持连接,允许客户端复用TCP连接,但一个连接不能并发,一个连接只能处理一个请求。在一个页面中如果有多个静态资源,就需要建立多个tcp连接
2.0协议:引入http流的概念,允许将不同的http请求并发地复用到同一个TCP连接上,使得浏览器可以高效地复用tcp连接。但当多个http请求复用一个tcp连接时,如果前面的请求/响应还没完成,后面的请求/响应就无法进行,也就是会出现队头堵塞现象。
3.0协议:不再使用TCP作为会话的传输层,而是使用QUIC。该协议在传输层将流作为一等公民引入。QUIC是基于UDP的。
非阻塞网络I/O
单线程的阻塞
服务端中有两个socket, 一个server的socketSocket,一个连接到客户端的socket
socketSocket.accept()
socket.getInputStream().read(): 从客户端中读取数据
socket.getOutputStream().write(): 往客户端中写数据
accept,read,write三个点都有可能被阻塞,导致后面的请求进来时无法响应
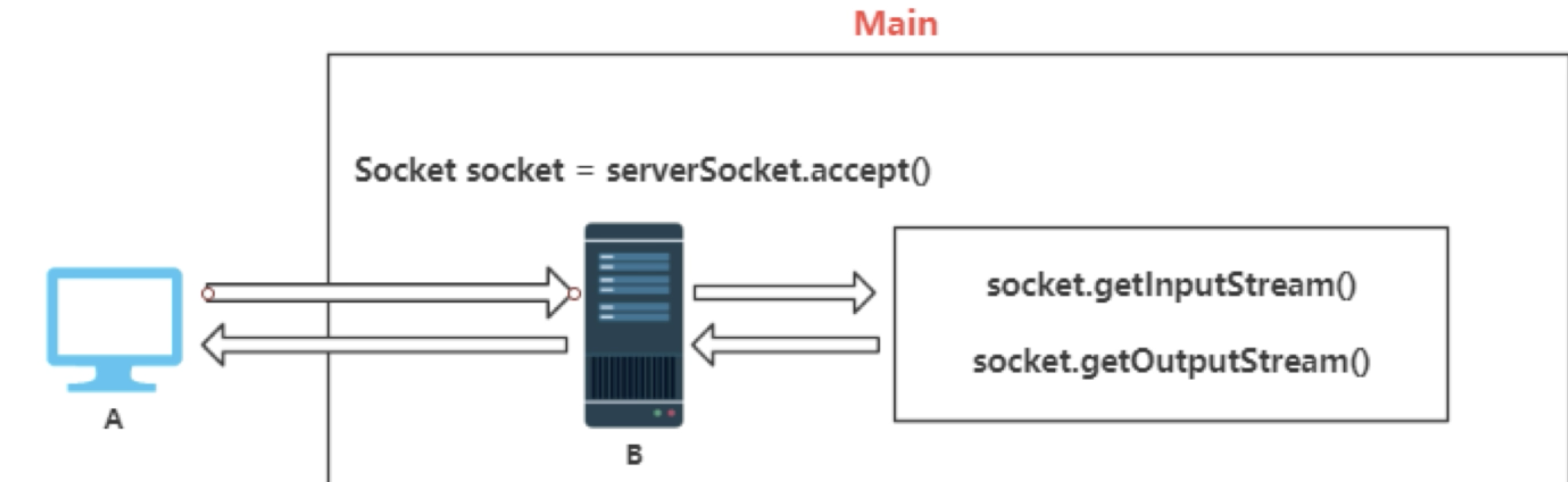
多线程服务器的阻塞
主线程只负责accept,每个请求进来,都创建一个socket。
每个socket再创建单独的线程来负责read和write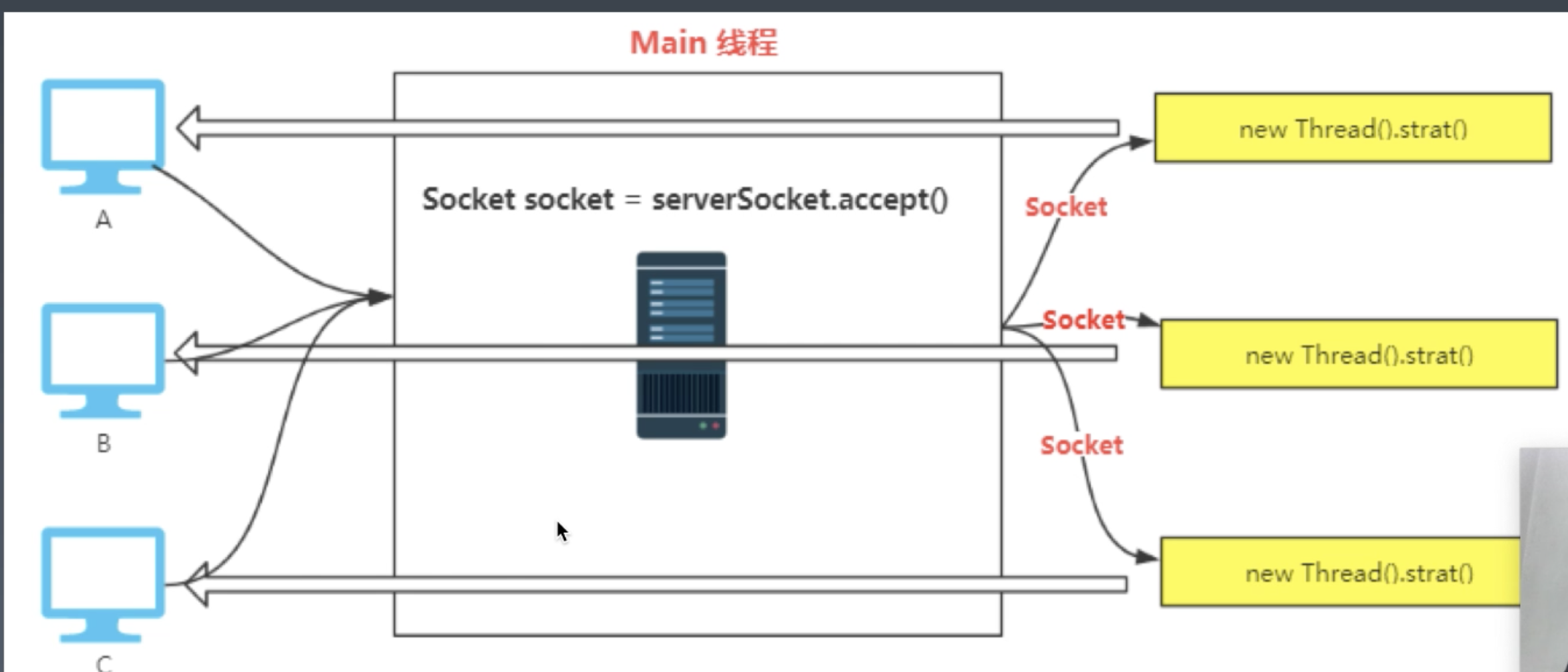
每次创建线程可以优化成使用线程池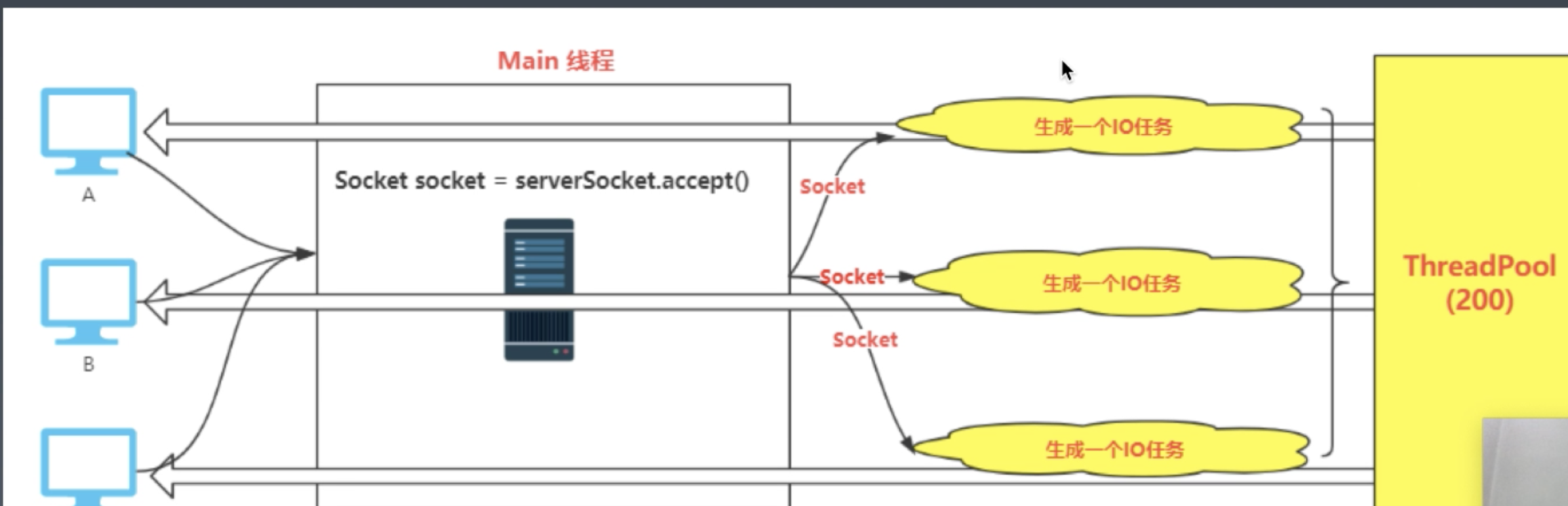
在read和write时还是会因为阻塞导致等待
怎么优化
Socket接收数据,系统内核的处理过程
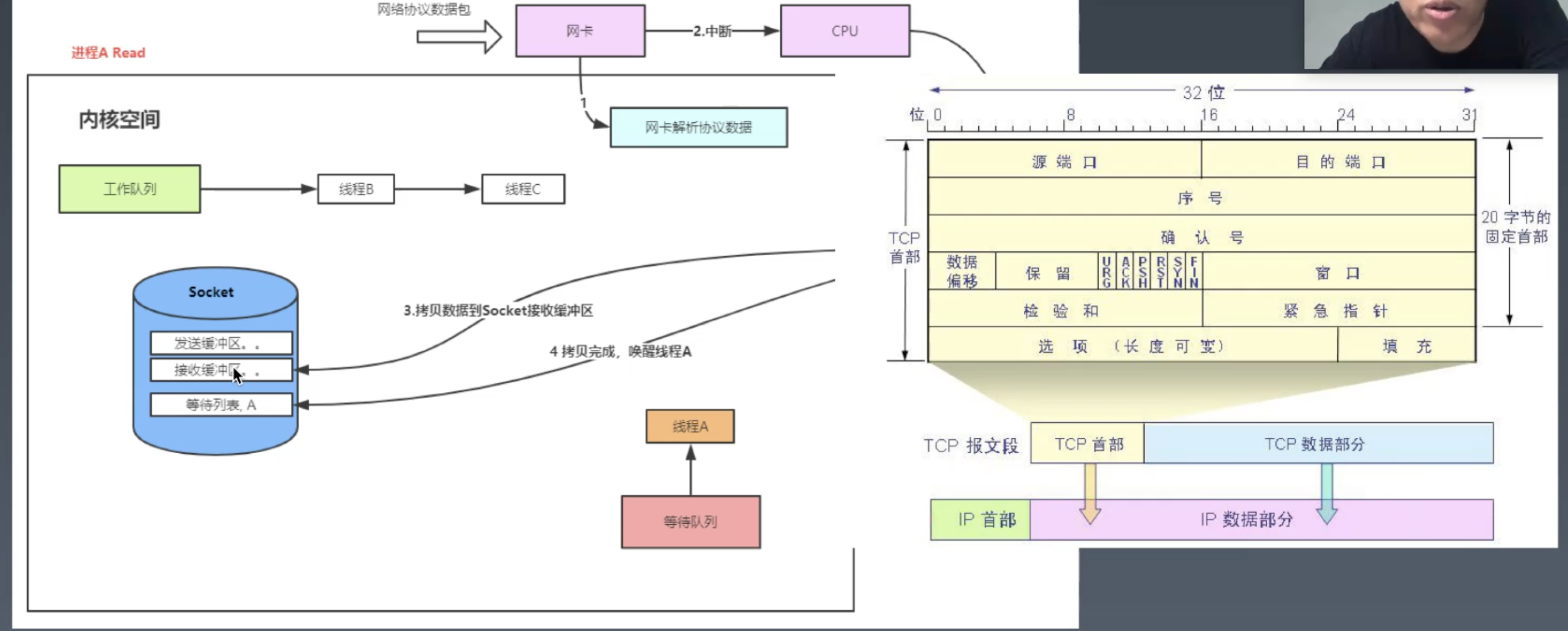
I/O操作需求等待buffer状态才能继续
非阻塞I/O
I/O操作立即返回,发起线程不会阻塞等待
read:
- 当socket接收缓冲区有数据时,读n个(不保证能读完整,因此可能需要多次读)
- 当socket接收缓冲区没有数据时,返回失败(不会等待)
write
- 当socket发送缓冲区满时,返回失败(不会等待)
- 当socket发送缓冲区不满,写n个数据(不保证一次性全部写入,因此可能需要多次写)
Java NIO
channel相当于socket

数据库架构
连接器
- 数据库连接器为每个请求分配一块专用的内存空间来进行会话的上下文管理
- 建立连接是相对较重的操作,因此通常会使用连接池
语法分析器
- 构建sql语法树
- 当关键字拼写错误时,会导致语法树构建失败。
- 所以,sql报错时,会提示某个关键词附近有错误,但不能确定是哪个关键字。
语义分析与优化器
- 将各种复杂嵌套的sql进行语义等价转化
- 利用索引等信息进一步进行优化
- 优化后生成执行计划

statement和prepareStatement的区别?
- PrepareStatement会预先提交带占位符的sql到数据库进行预处理,提前生成执行计划,当给定占位符参数时,执行引擎就直接执行,效率会更高;而statement 每次执行时都需要重新进行语法分析,生成执行计划等操作。
- PrepareStatement可以防止sql注入

合理使用索引
- 每次加索引都需要对现有数据进行遍历,同时有新的数据或数据修改都会被阻塞
- 在更小的字段上创建索引,以减少占用空间
数据库的事务是如何实现的
- 通过事务日志实现的
- 在进行事务操作时,事务日志会先记录更新前的数据记录,然后再更新数据库中的记录。如果全部更新记录成功,则事务正常结束;如果某条记录更小失败,则这个事务全部回滚,已经更新的记录根据事务日志中记录的数据进行恢复。
扩展
多项式时间复杂度和非多项式时间复杂度的区别?
NP问题的分类:NP-hard问题/NP完全问题
二叉树旋转
背包问题怎么解决
迪杰斯特拉算法
遗传算法
tcp连接的三次握手和四次挥手
Java NIO selector/epoll/poll
B+树与B树的原理
索引与B+树的关系
聚簇索引和非聚簇索引的区别及原理
一种学习方法,运用自己已经掌握的知识猜实现方式,再去证明,看对不对,不对的话,是哪里不对,为什么要这么做

若有收获,就点个赞吧
0 人点赞
