一、吴恩达-机器学习
1、机器学习入门
机器学习定义:E-经验、T-任务、P-度量
:::info
跳棋游戏:
E-人与程序下了几万次跳棋
T-玩跳棋
P-与新对手玩跳棋赢的概率
:::
机器学习算法:监督学习、非监督学习
课程目的:正确运用学习算法来设计和建立各种机器学习及AI系统
2、监督学习(第2-第9)
学习算法的作用:
- 根据数据画一条直线
- 用一条直线拟合数据
- 用二次函数拟合数据
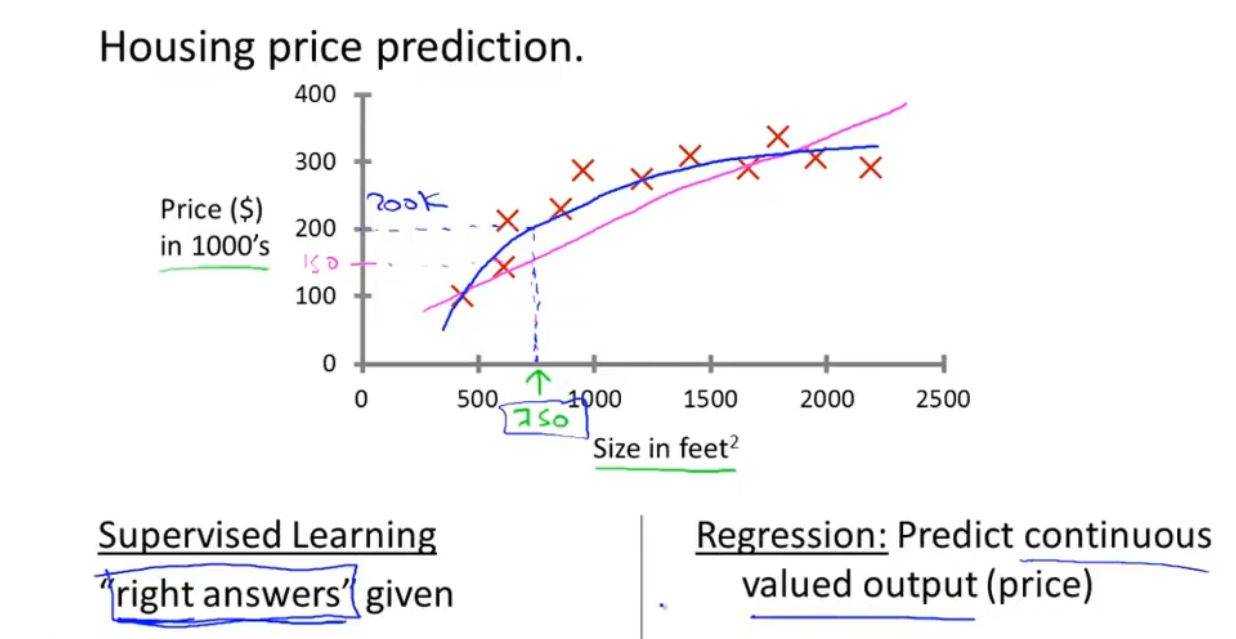
1、回归问题:用一些有数据的正确答案来获得另一些数据的正确答案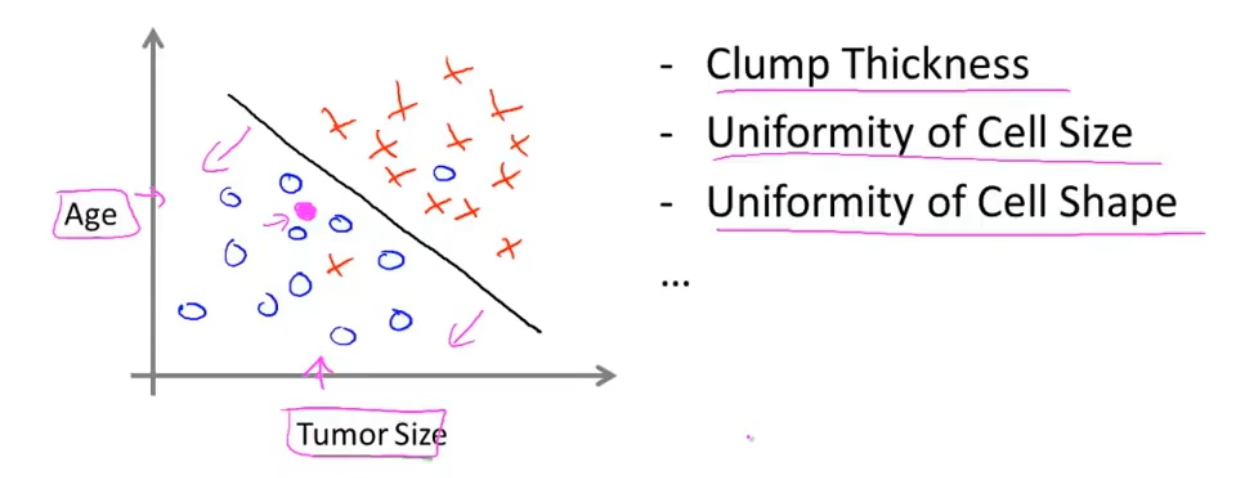
2、分类问题:得出0和1的结论
:::info
计算房价(回归问题——预测连续性输出)
肿瘤是恶性还是良性(分类问题——预测离散型输出)
:::
3、无监督学习
给出一个数据集,不告诉你每个数据的定义,让你找出其中的规律、结构。
1、聚类算法:分簇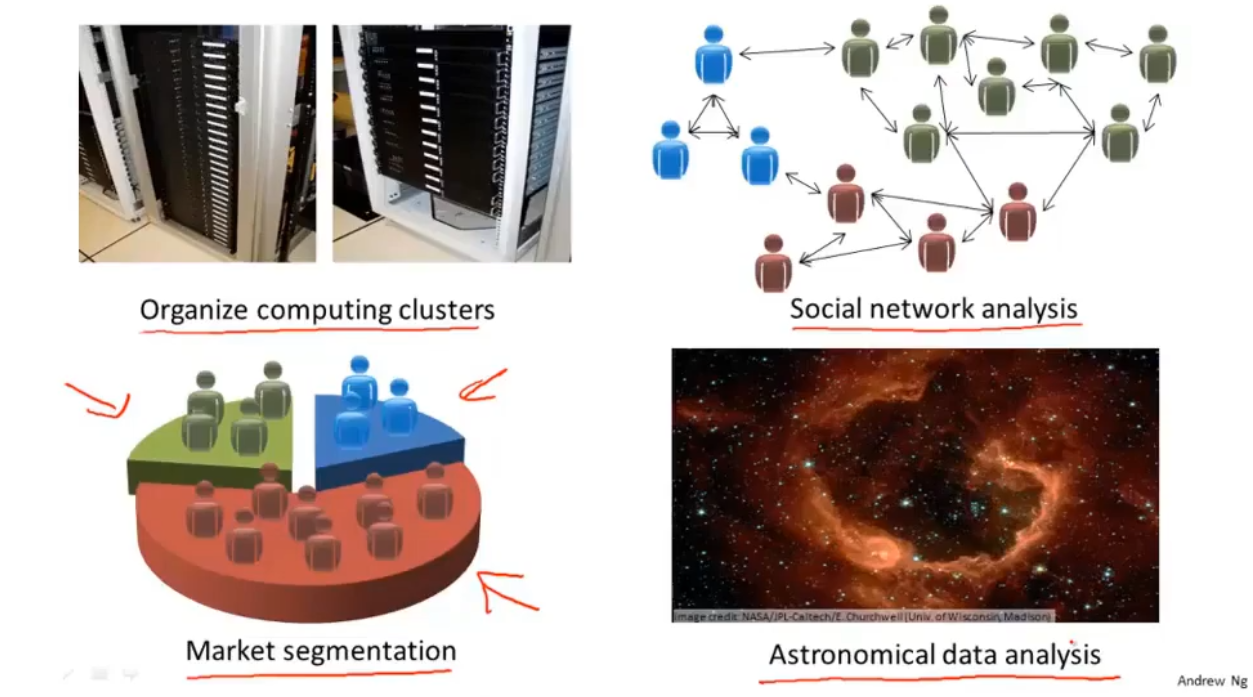
2、鸡尾酒会算法:分类
:::info
两个录音:
第一个录音——混合了音乐和人的声音,人的声音比较大
第二个录音——混合了音乐和人的声音,音乐的声音比较大
1.提取出第一个录音的人声
2.提前出第二个录音的音乐声
:::
3、Octave和matlab
使用Octave建立原型再移植到Java、C++会大大节省时间
4、模型(线性回归)
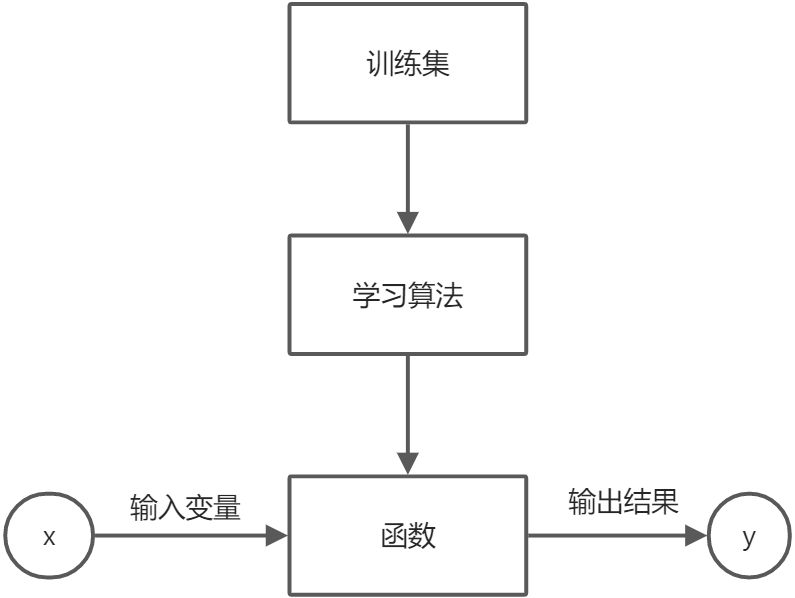 :::info
1、m=训练集中训练样本数量
:::info
1、m=训练集中训练样本数量
2、x=输入变量/特征
3、y=输出变量
4、(xi,yi)=一个训练样本 i:表示的不是幂,表示的是索引,第几个样本
:::
a、一元线性回归模型:hθ(x)=θ0+θ1x
:::info
代价函数/平方误差函数:J(θ0,θ1) :::
:::
:::info
代价函数一:(x,y)-(1,1) (2,2) (3,3)——————————hθ(x)=θ1x,J(θ1)
θ1=1—————————h(x)=x,J(1)=0
θ1=0.5————————h(x)=0.5x,J(1)=0.58
θ1=0—————————h(x)=0,J(1)=2.3
minimize(J(θ1))=0
代价函数J(θ1)为一个反抛物线形状
:::
:::info
代价函数二:hθ(x)=θ0+θ1x,J(θ0,θ1)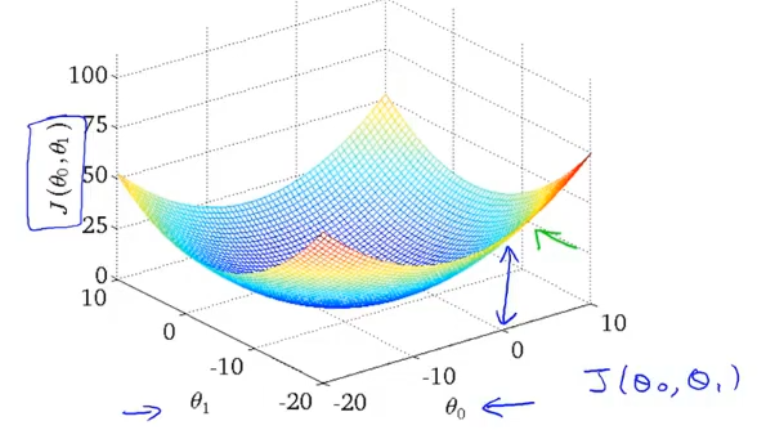
 :::
:::
b、 梯度下降算法(将代价函数J最小化——找到最拟合数据的θ0,θ1,……,θn值)
- 下山:找每一步方向中,最快速下山的点
- 梯度下降算法用的是同步更新

- α表示的是走的步伐大小,后面一陀是一个偏导数
:::info
α太小,会导致步伐走得太小,梯度下降的很慢,花时间
α太大,步伐走得太大,可能会越过最低点,找不到最小的J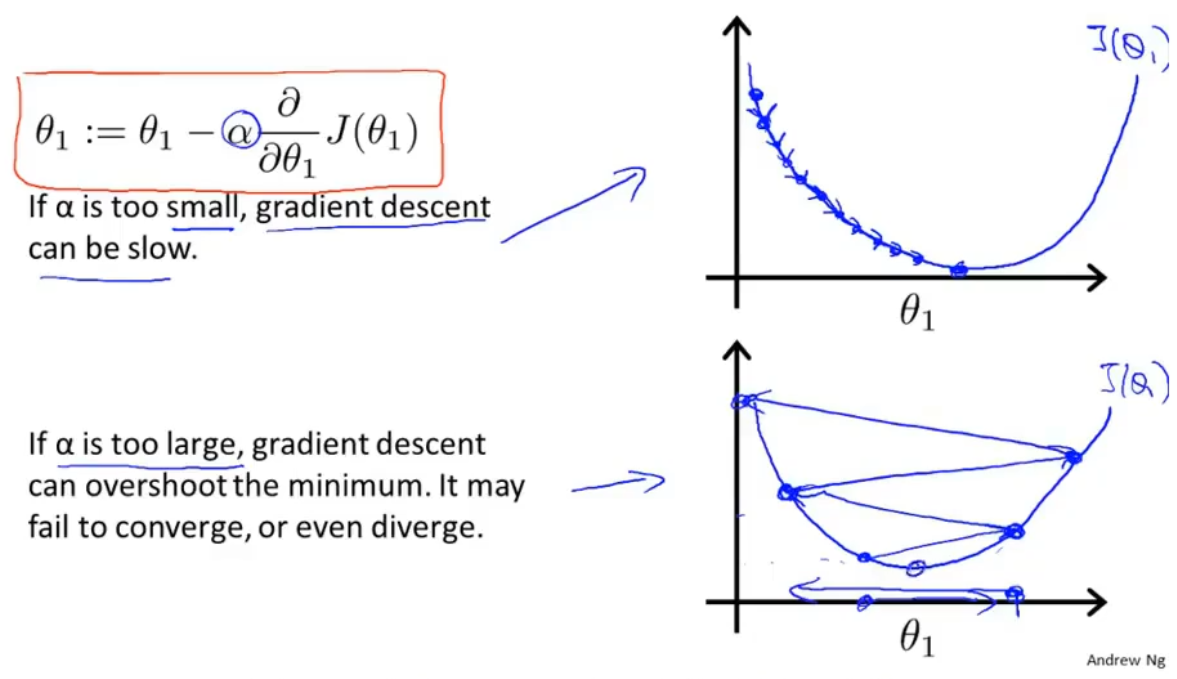
在θ1左边时——偏导数为负,θ1减去偏导数,导致θ1向右移
在θ1右边时——偏导数为正,θ1减去偏导数,导致θ1向左移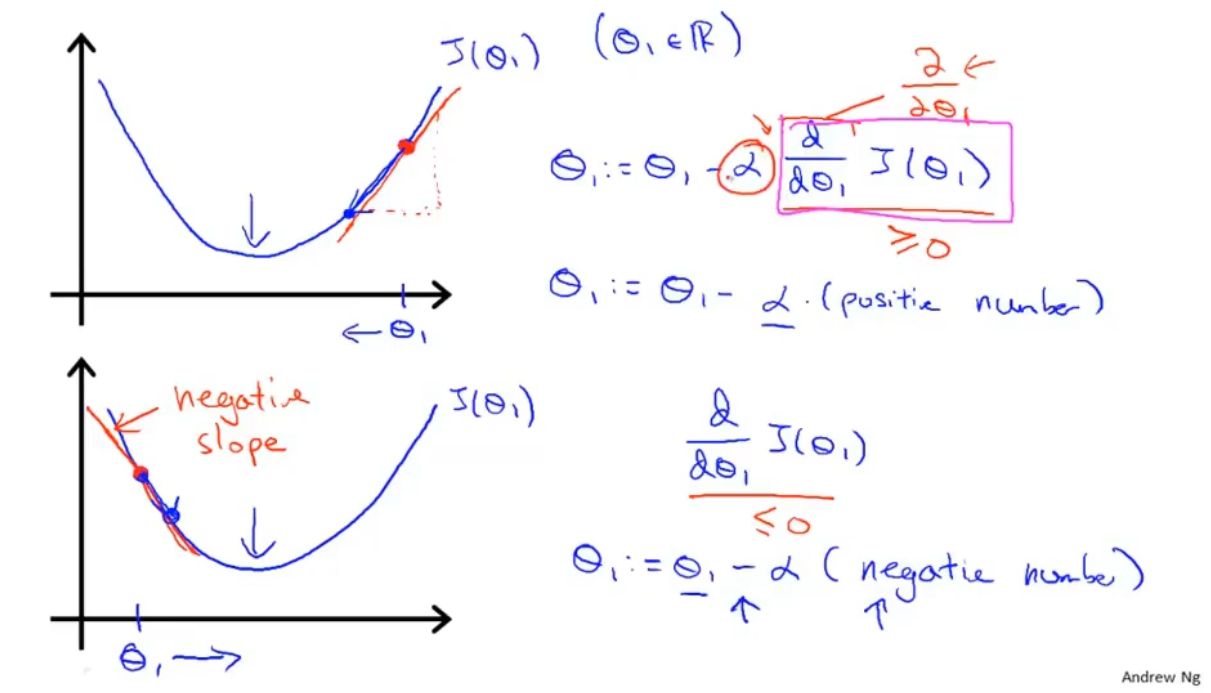 :::
:::
:::info
J(θ0,θ1)的偏导数求法 :::
:::
2022.5.22,第一周
5、矩阵和向量
AMN=M行N列的矩阵,A32=第3行第2列的数据
向量是一种特殊的矩阵,向量只有一列,RM
:::info
矩阵表示:大写字母(ABCD……)
向量表示:小写字母(abcd…….)
下标默认从1开始,A[1]、a[1]
:::
**矩阵和向量的加减乘除(行列=值,列行=矩阵)**
:::info
同时预测4间房子:(矩阵向量)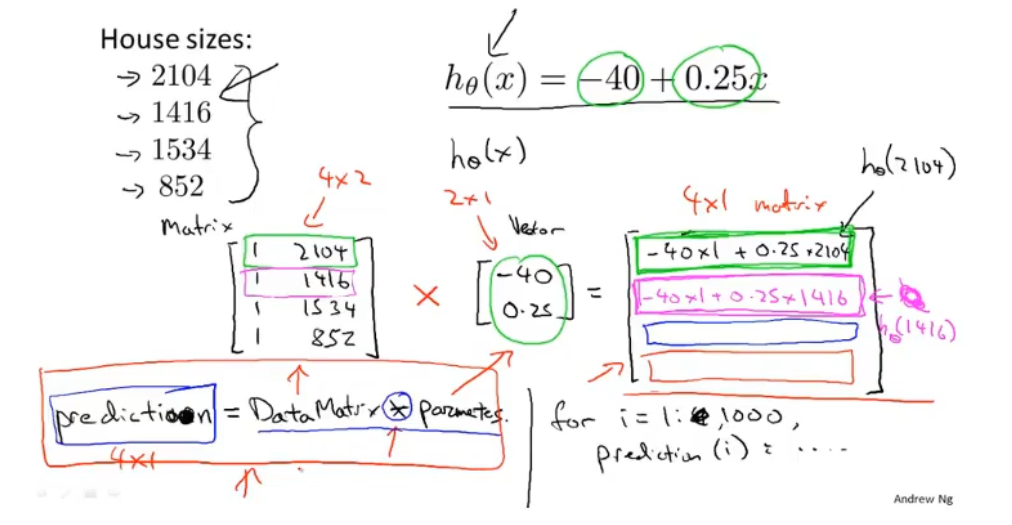 :::
矩阵矩阵:A*MN**BN*P=C*MP
:::info
同时预测4间房子,3个假设函数:(矩阵矩阵)
:::
矩阵矩阵:A*MN**BN*P=C*MP
:::info
同时预测4间房子,3个假设函数:(矩阵矩阵) :::
*矩阵乘法的特征:
:::
*矩阵乘法的特征:
- AB!=BA
- ABC=A(BC)=(AB)C
- 单位矩阵,对角线为1,其他位置为0(A*E=A)
逆矩阵和转置:
A*A-1=E(方阵才有逆矩阵,行列式的值不等于0)
B=AT(行列互换,Aij=Bji)
6、多特征值(多元线性回归)
a、多元线性回归
:::info
n个特征值估计房价: (x1,x2,x3……..)
n:表示n个特征值
x(i):表示第i行,第i个向量
x(i)j:表示第i行的第j个特征值,第i个向量的第j个
hθ(x)=θ0+θ1x1+θ2x2+………+θnxn (x0=1)
=θT*x
:::
多元线性回归的梯度下降法:
b、特征缩放(使特征值的取值范围尽量接近-1<x<1)
多个特征的取值范围越大,代价函数收敛的越慢,J找到的时间越慢
:::info
2个特征值:
房屋的面积:0-2000 缩小范围:2000/2000=1
房间的数量:1-5 缩小范围:5/5=1
:::
确定x的范围:
x=(m-u)/s
m=特征x的取值范围,u=特征x的平均值,s=特征x的最大值-最小值
c、学习率α
纵轴代表代价函数的最小值、横轴代表代价函数的迭代次数
若minJ(θ)逐渐增大或上下波动,则说明学习率α太大,应该减小学习率α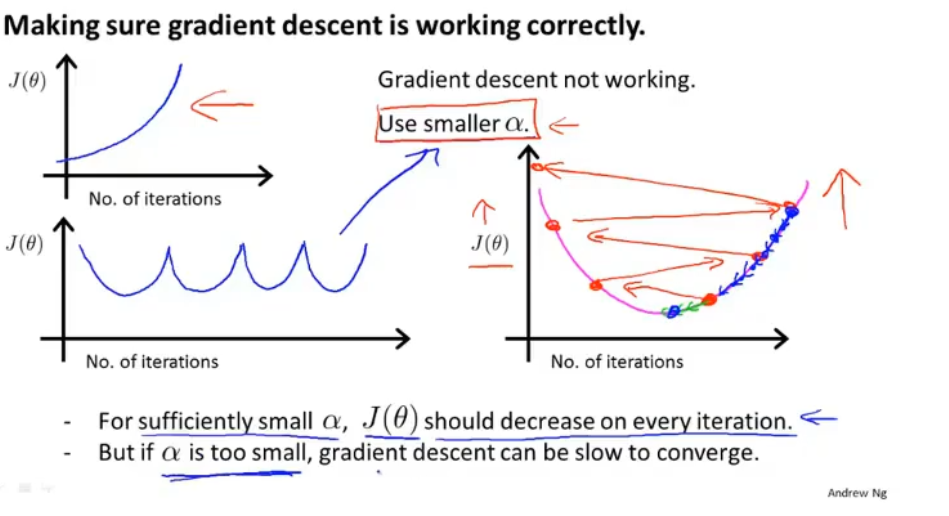
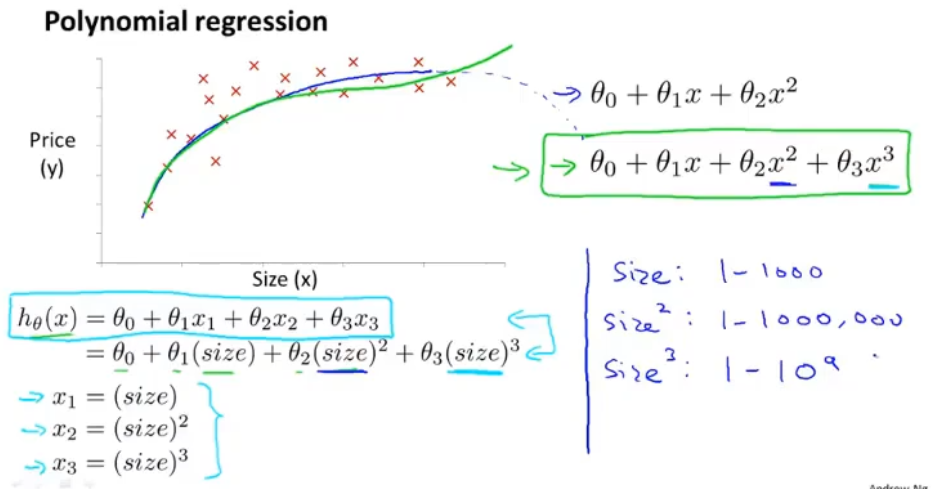
d、特征选择
- 两个特征值分别为:房子宽度、长度,可以转换为一个特征值:房子的面积
- 一个3次方程:可以转化为特征值x,特征值x的平方,特征值x的三次方
e、正规方程(直接获得θ的最优解,不需要用到梯度下降,也不需要特征缩放)
最小值点=导数为0的点
θ=(XTX)-1XTy X=所以特征值形成一个矩阵,第一列全为1
:::info
梯度下降算法和正规方程的比较:
梯度下降算法——>需要大量的迭代计算(正规方程不需要)
梯度下降算法——>需要不断确定学习率α(正规方程不需要)
当n非常大的时候(特征值很多),梯度下降算法依然非常适用,而正规方程矩阵计算量太大
:::
7、octave
a、octave在线工具:https://octave-online.net/
b、octave的基本操作




")









pwd #显示当前路径cd #/切换当前位置ls #显示文件load demo.txt/load('demo.txt') #引入文件数据save test.txt v -ascii #用ascii格式存储文件log(V) #对数运算exp(V) #以e为底的幂运算abs(V) #V的绝对值sum(a) #求和sum(A,1) #每一列求和,返回一个行向量sum(A,2) #每一行求和,返回一个列向量prod(a) #积乘floor(a) #去小数点ceil(a) #向上取整max(A,[],1) #A中每一列的最大值max(A,[],3) #A中每一行的最大值flipud(A) #矩阵垂直翻转pinv(A) #求A的逆矩阵
c、octave的可视化

 :::info
plot(t,y1);
:::info
plot(t,y1);
hold on;
plot(t,y2,’r’); #使用红色线
xlabel(‘time’) #x轴标签
ylabel(‘value’) #y轴标签
legend(‘sin’,’cos’) #显示图例
title(‘myplot’) 设置标题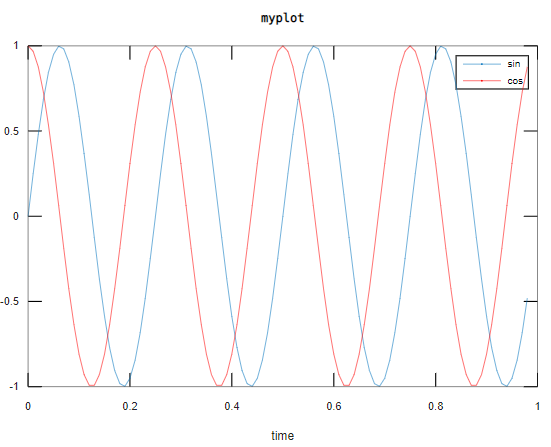 :::
:::info
subplot(1,2,1); #创建一个12的方格块,取第一块的地方
:::
:::info
subplot(1,2,1); #创建一个12的方格块,取第一块的地方
plot(t,y1);
subplot(1,2,2); #12的方格块中,取第二块的地方
plot(t,y2); :::
:::info
A=magic(5)
:::
:::info
A=magic(5)
imagesc(A) #生成不同颜色块的图
imagesc(A),colorbar,colormap gray; #生成灰度图 :::
:::
d、控制语句if、while、for和函数的使用
e、使numpy实现算法找到代价函数J
import numpy as np
# 调用函数costFunctionJ求代价函数
def costFunctionJ(x,y,theta):
m=x.shape[0]
predictions=np.matmul(x,theta)
sqrErrors=(predictions-y)**2
J=1/(2*m)*sum(sqrErrors) #返回J代价函数值,然后取最小的
return J
x=np.array([1,1,1,2,1,3]).reshape(3,2) #x轴的值
y=np.array([1,2,3]).reshape(3,1) #y轴的值
# theta=np.array([0,1]).reshape(2,1) #代价函数为y=x时,返回0 (0+0+0)/6=0 ——J值最小找到拟合函数了
# theta=np.array([0,0]).reshape(2,1) #代价函数为y=0时,返回2.3333 (1+4+9)/6=2.3333
theta=np.array([1,1]).reshape(2,1) #代价函数为y=x+1时,返回0.5 (1+1+1)/6=0.5
print(costFunctionJ(x,y,theta))
8、逻辑回归(0、1…….)
a.线性回归不能用于分类问题(邮件、肿瘤),logistic回归算法也叫分类算法可以用于离散型问题
:::info
hθ(x)=g(θTx)————————————-g(z)=1/(1+e-z)——————-g(z)称为为logistic函数


 hθ(x)>=0.5(θTx>=0),预测y=1————————hθ(x)<0.5(θT*x<0),预测y=0
:::
hθ(x)>=0.5(θTx>=0),预测y=1————————hθ(x)<0.5(θT*x<0),预测y=0
:::
b.决策边界(可以区分y=1、y=0的边界)


5.30第二周
c、代价函数
logistic回归与线性回归不同,代价函数的形状也不同,原来的算法线性回归能收敛的到最小值,而logistic回归不能收敛到最小值。
:::info
线性回归:hθ(x)=θTx
logistic回归:hθ(x)=1/(1+e-(θTx)) 且0 :::
:::info
当y=0时,预测值hθ(x)为1时,付出的代价为无穷大
:::
:::info
当y=0时,预测值hθ(x)为1时,付出的代价为无穷大
当y=0时,预测值hθ(x)为0时,付出的代价为0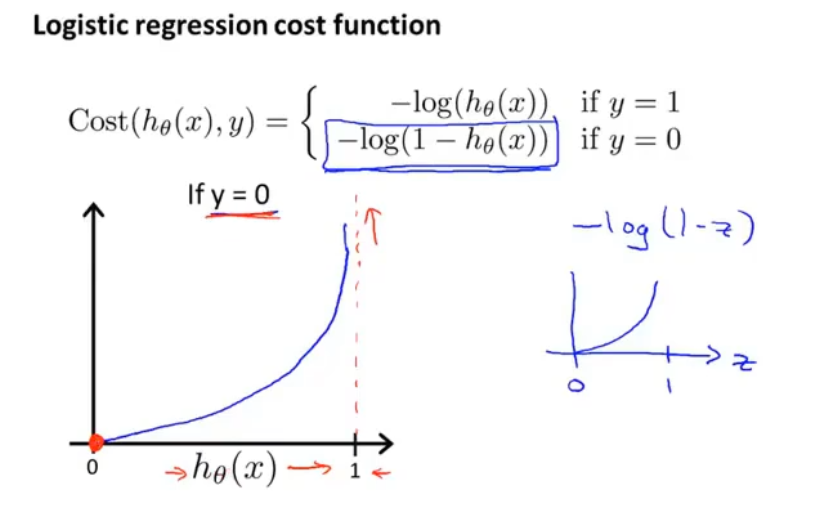 :::
由于y的值只有两种:0、1,所以代价函数J(θ)可以写成
:::
由于y的值只有两种:0、1,所以代价函数J(θ)可以写成
d、梯度下降
更新θ的方程和线性回归的函数一样,只不过hθ(x)函数不一样
e、高级优化函数(比梯度下降高级、优化)
优点:
- 不需要使用学习率α
- 收敛的比梯度下降块

 f、1对多的分类问题
f、1对多的分类问题
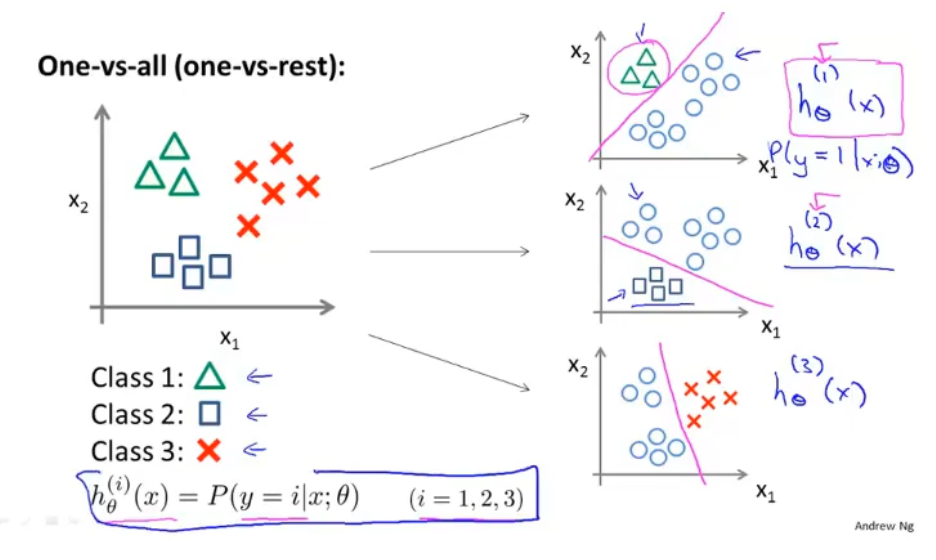
9、过度拟合
过度拟合导致变量太多,效果反而变差
 :::info
过度拟合的解决方法:
:::info
过度拟合的解决方法:
- 减少特征变量——就是减少变量
-
a、正则化(减少θ的大小)
λ为正则化参数
 :::info
若λ参数太大,(θ1,θ2…..)会变得非常小,从而导致欠拟合,代价函数为一条直线
:::info
若λ参数太大,(θ1,θ2…..)会变得非常小,从而导致欠拟合,代价函数为一条直线 :::
:::
b、线性回归正则化
c、逻辑回归正则化
10、非线性(分类问题、神经网络)
(1)、神经网络
神经网络算法最初的目的是模拟大脑的算法。
大脑中可以学会各种功能: 舌头学会看
- 鼻子学会看
- …………….
(2)、模型(输入层—隐藏层—输出层)


神经网络算法就是让特征值(x1、x2….)变成隐藏值/新的特征值(a1、a2……)作为逻辑回归的输入来计算。(神经网络的最后一层是逻辑回归算法)
(3)、两个例子




(4)、神经网络多类别分类问题
输出值为一个向量,可以表示不同的结果
且训练集中的y(实际值)也为向量

(4)、代价函数


(5)、反向传播算法(使代价函数J最小化)
:::info 反向传播算法是为了计算出偏导数,然后使用梯度下降或者其他算法
反向传播算法是找到去最低点的方向
梯度下降算法是沿着最低点一步一步下去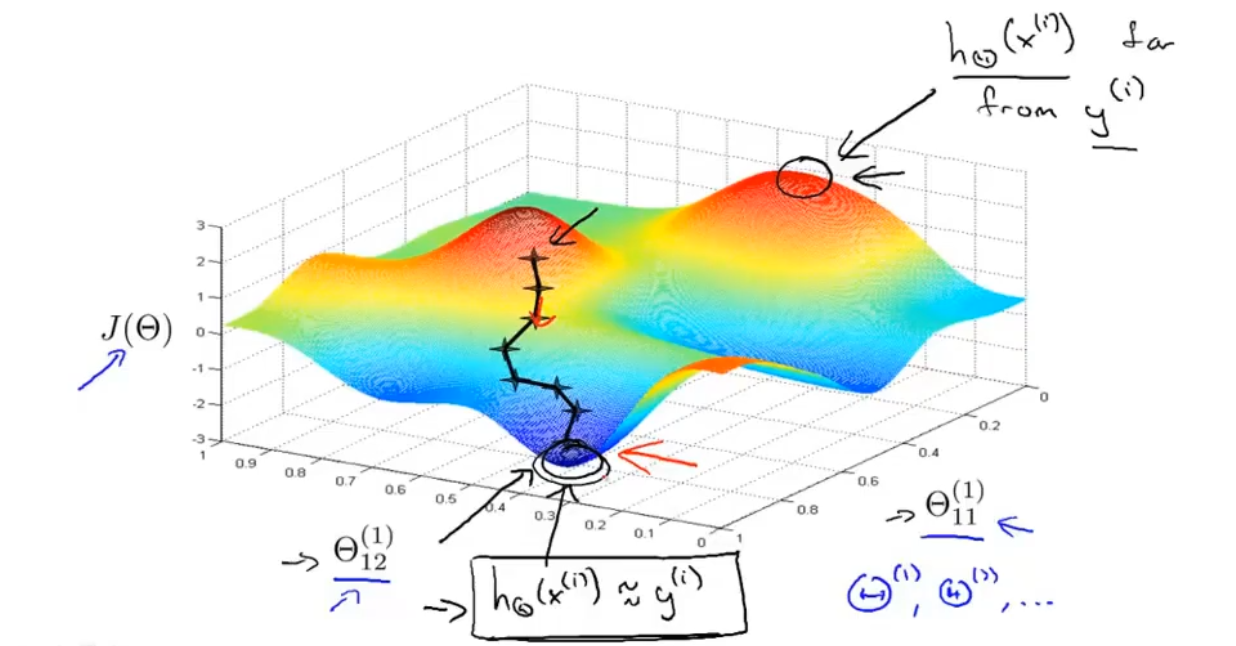 :::
计算出偏导数,然后使用梯度下降或者其他算法
:::
计算出偏导数,然后使用梯度下降或者其他算法
反省传播算法计算机误差值,第一层没有误差,因为就是用的是训练集的数据



(6)、梯度检验(减小导数值的误差,梯度下降和反向传播的导数值)
梯度检验算法非常慢,消耗大量空间,时间。
可以检验梯度下降和反向传播算法的正确性
运行反向传播算法或者梯度下降时必须先关闭梯度检验算法。

(7)、随机初始值(梯度下降和反向传播算法中θ的初始值)
θ的初始值:(p,-p)之间(8)、反向传播算法总结
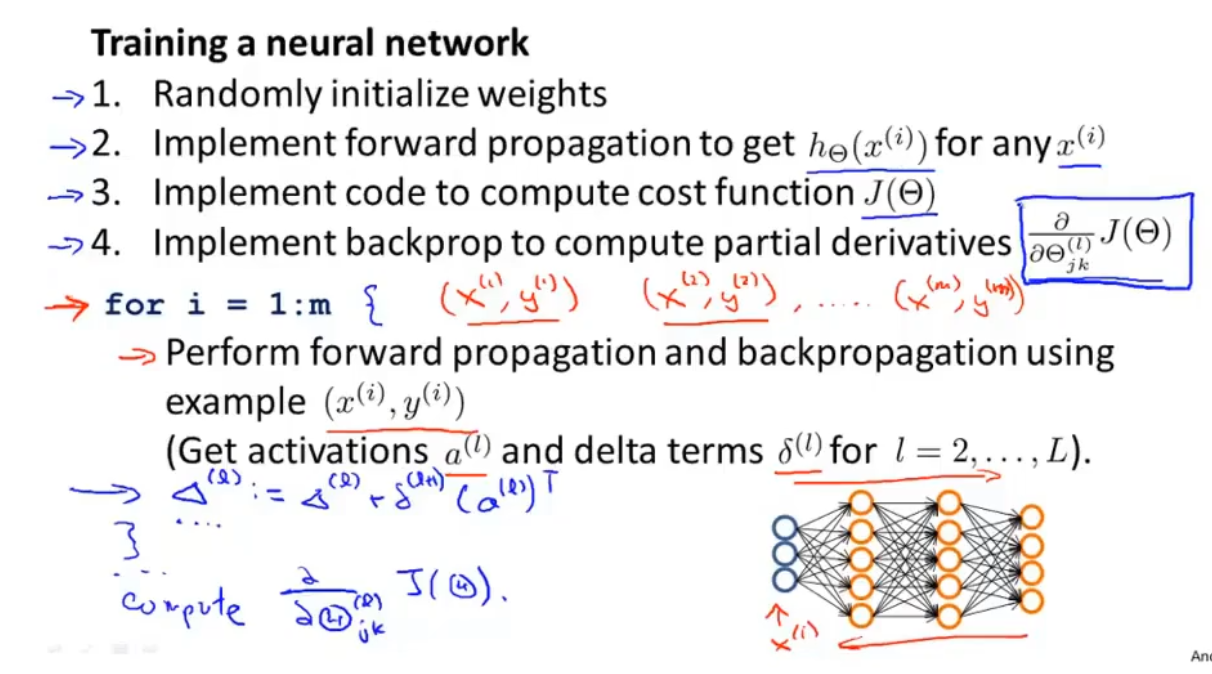
a、建立神经网络模型

b、训练模型的步骤
:::info




- 构建神经网络,并随即初始化权重
- 执行前向传播算法(算出每个x的输出值y的向量)
- 计算代价函数J(θ)
- 执行反向传播算法,算出偏导数项(J(θ)对θ的偏导数)
- 梯度检验(检验偏导数值与数值算出来的作比较,误差大不大)
-
11、使用算法后下一步
:::info 使用算法过后,找到了代价函数,但仍然与真实数据有很大的误差怎么办?
找更多的训练数据—— 对高方差时有效
- 减少一些特征(防止过拟合)—— 对高方差时有效
- 增加一些特征(防止欠拟合)—— 对高偏差时有效
- 增加多项式特征(x12,x22……………)—— 对高偏差时有效
- 增大正则化参数大小—— 对高方差时有效
减小正则化参数大小—— 对高偏差时有效 ::: 使用机器学习诊断法来判断上面哪些方法没用,从而选择出最适合的方法
(1)、防止过拟合
:::info 两部分:将真实数据,随机分成70%的训练集和30%的测试集
三部分:60%训练集、20%验证集(cv)、20%测试集(test)

步骤:使用验证集拟合,确定多项式d——使用测试集评估 :::(2)、判断过拟合、欠拟合
:::info

横坐标:多项式d 纵坐标:误差
左边的为高偏差(欠拟合):验证误差和训练误差都很高
右边的为高方差(过拟合):验证误差很高,训练误差很低 :::(3)、选择正则化参数
:::info


左边高方差(过拟合),右边高偏差(欠拟合) :::(4)、学习曲线
:::info m:训练集样本容量.


使用再多的训练数据对于该算法也无用,训练误差和验证误差很接近。
使用更多的训练数据对于验证误差有用,最终和训练误差相接近 :::(5)、项目步骤
先设计运行一个简单粗暴的算法
- 通过学习曲线调整误差的产生
进行误差分析,输出评估率,调整算法 :::info
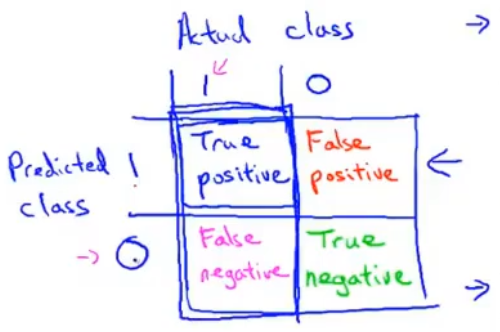
预测值、实际值:
预测值=1、实际值=1——真阳性
预测值=1、实际值=0——假阳性
预测值=0、实际值=0——真阴性
预测值=0、实际值=1——假阴性
查准率=真阳性/(真阳性+假阳性) 查准率越高越好
召回率=真阳性/(真阳性+假阴性) 召回率越高越好 :::查准率和召回率的权衡 :::info 预测癌症:0
当临界值为0.8时/比较高——查准率比较高,而召回率比较低
当临界值为0.3时/比较低——查准率比较低,而召回率比较高 :::
:::评估度量值(怎样的查准率和召回率比较好) :::info 查准率和召回率的平均值不适合做评估度量值
使用F值公式 :::
:::训练集越多对算法越的条件

首先很多特征值x才能确定y值,其次算法中特征值参数比较多且算法较好时
12、支持向量机算法(SVM)
(1)、逻辑logistic回归算法支持向量机


(2)、大间距分类器(SVM算法)
支持向量机把到两边的间距最大化,黑线为支持向量机的间距
尽量把正样本和负样本用最大间距分开。 :::info
一般情况下,C被设置成非常大的数。
:::info
一般情况下,C被设置成非常大的数。
当C非常大时,异常点对决策边界的影响也比较大,黑线变成粉线
当C比较小时,异常点对决策边界的影响较小,依然为黑线 :::
:::
(3)、支持向量机算法构造非线性分类器
a.核函数一
:::info

exp表示的是:e的n次方
核函数就是相似度函数,与标记点多相似
 :::
:::
b.核函数二

 :::
:::
c.SVM中的参数C
:::info
C类似与正则化参数
C太大——低偏差,高方差;C太小——高偏差,低方差 :::
:::
(4)、逻辑回归和SVM的判断
n=特征值的数量,m=样本的数量
当n非常大时(n>>m),使用逻辑回归算法或者不带核函数的SVM(线性核函数)
当n比较小或非线性分类时,使用带有核函数的SVM比较好
当m比较大(n<
13、无监督学习(只需要X,不需要Y)
(1)K-means算法(聚类算法)
- 簇分配
-
(2)K-means算法的优化目标函数
(3)初始化聚类中心
K-means算法会收敛到不同的簇中,因为随机初始化状态不同,会导致效果差的局部最优
当K在2-10的范围中,使用多次随机初始化比较好
(4)第二种监督学习应用(降维/压缩数据)
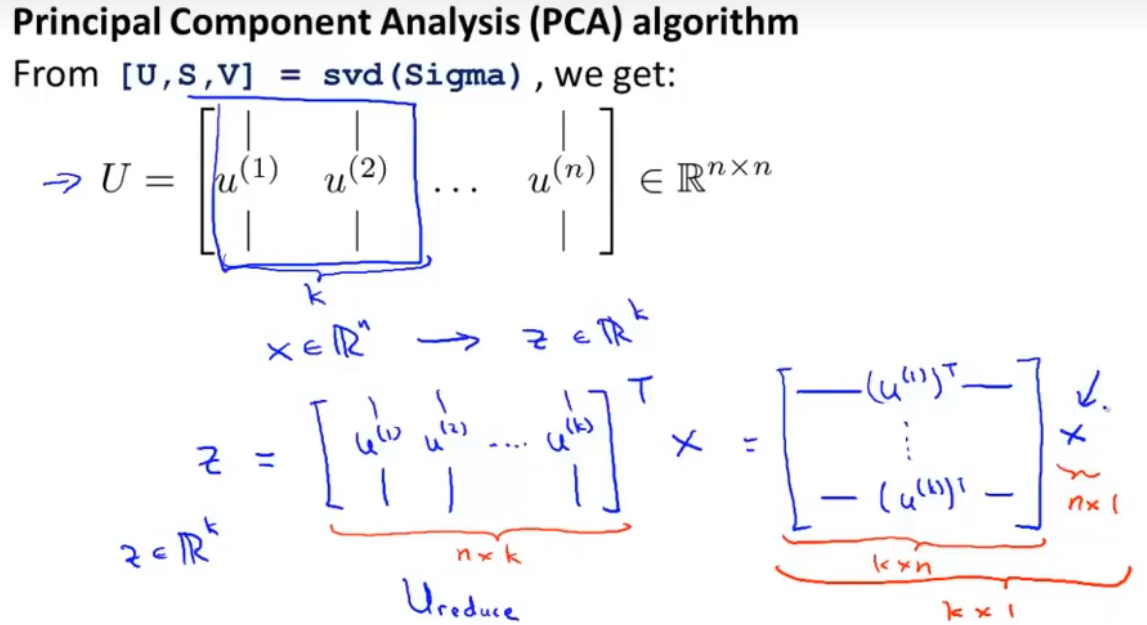
(5)实现降维/压缩数据的算法——PCA主成分分析
(5)PCA算法中选择K的方式
(6)PCA算法的应用
使用PCA去加快学习算法的速度
- 不建议使用PCA去防止过拟合
- 压缩文件、可视化



 :::
:::





(7)异常检测
- 网站发现异常用户
- 飞机引擎异常检测
- 数据中心检测计算机异常
(8)高斯分布

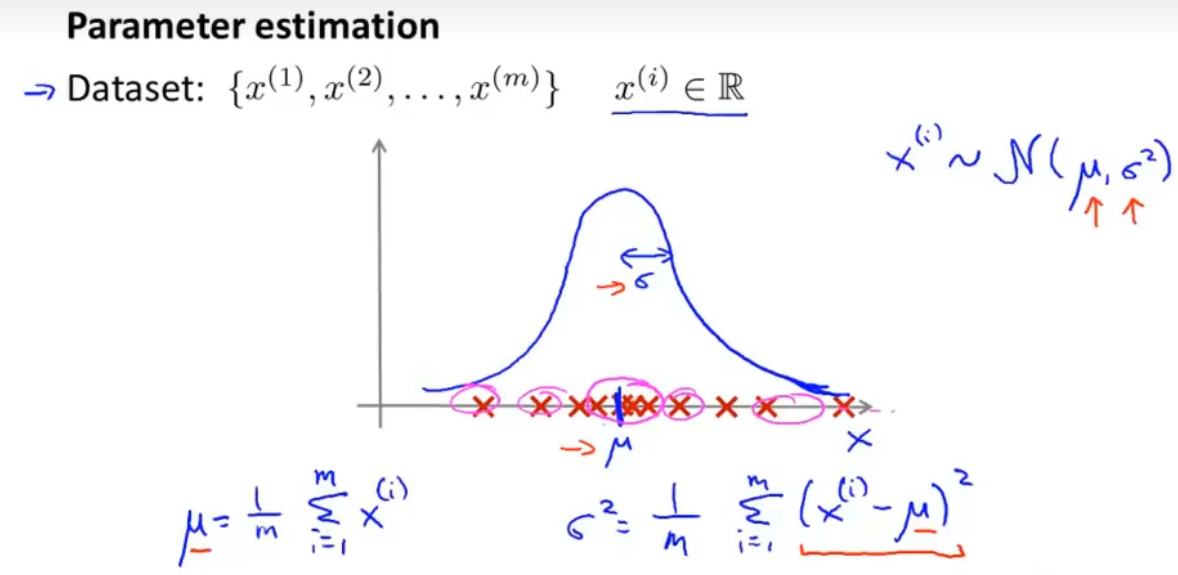
(9)高斯分布构建异常检测算法

(10)异常检测和监督学习
当正样本比较少,负样本比较多时,使用异常检测比较好。
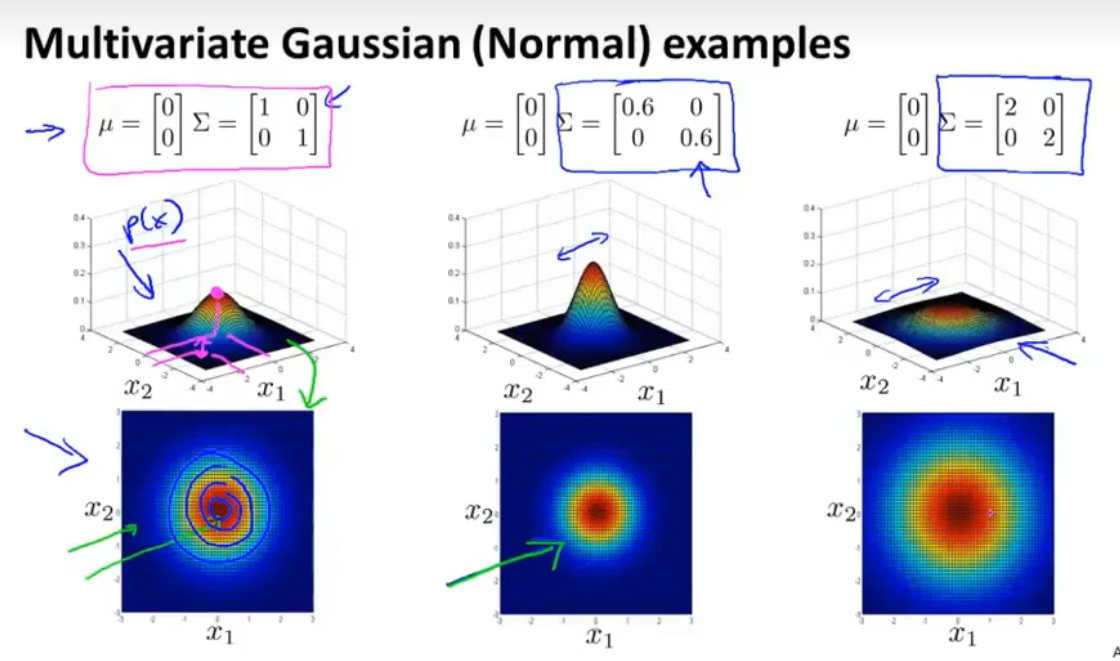
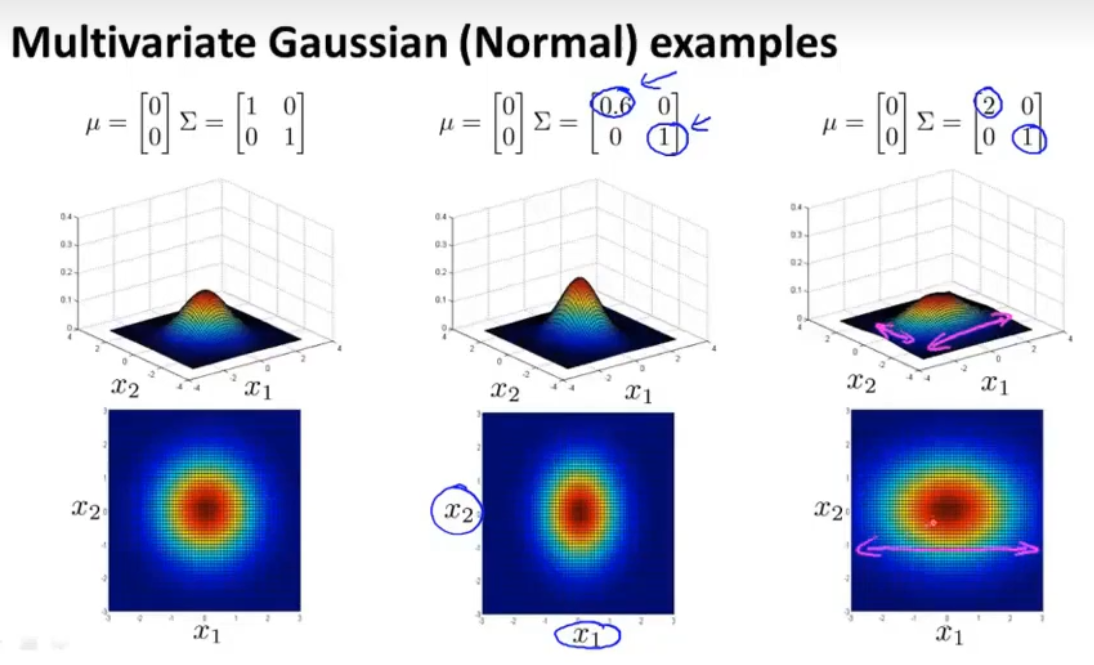
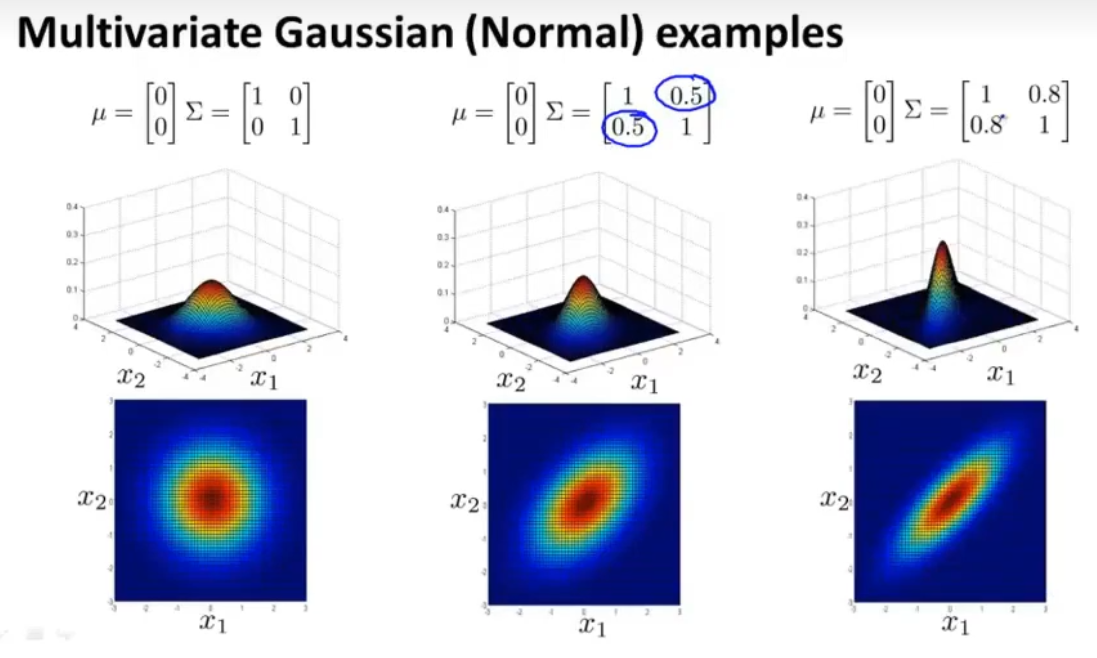
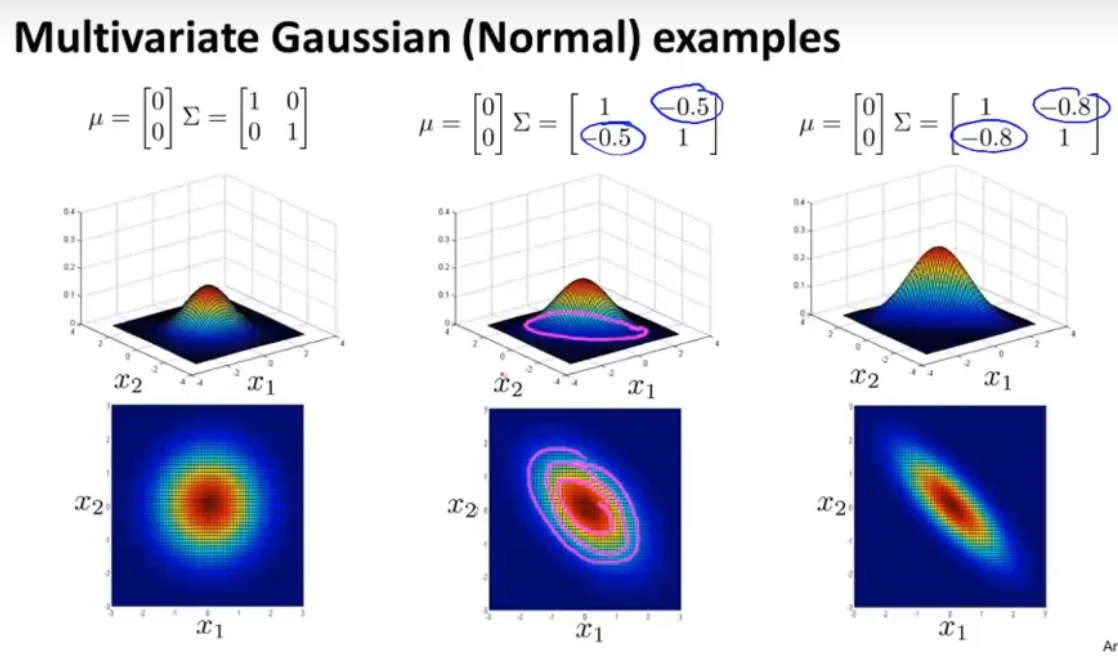
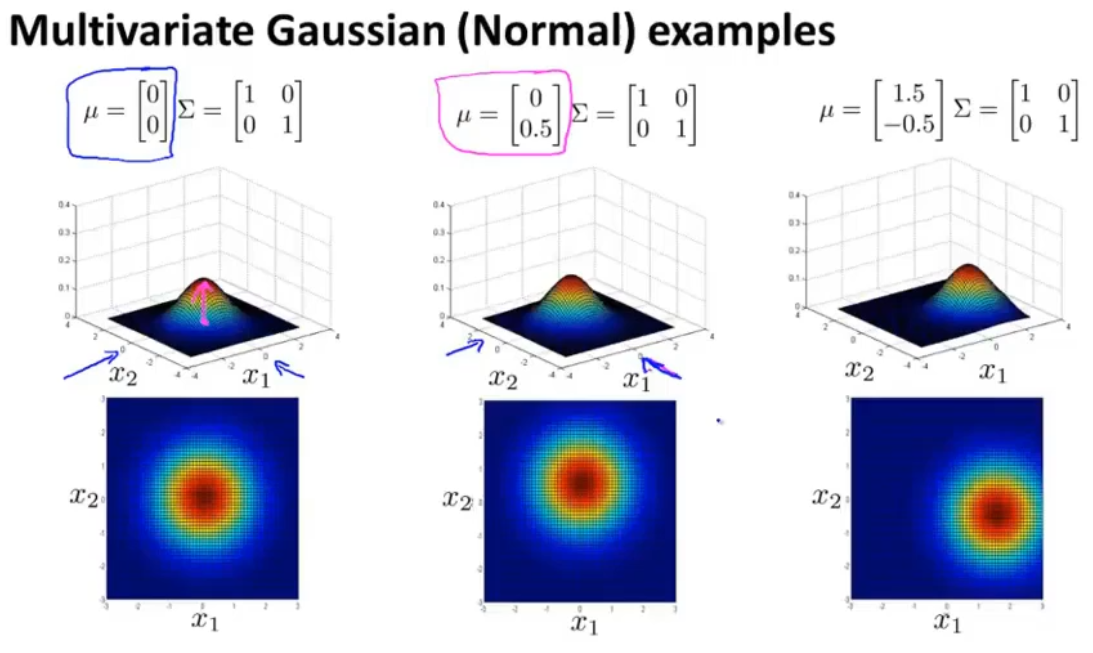
当正样本比较多,负样本比较少时,使用监督学习比较好。(11)多变量高斯分布
14、推荐系统
(1).基于内容的推荐算法
(2).协同过滤算法
15、训练大数据集
二、浙江大学-机器学习
1、机器学习概述
a、机器学习的定义:
- 非显著式的编程(让计算机自己总结规律)
-
b、机器学习的分类:
监督学习(经验E由人工主动加入计算机,并已打上标签)
非监督学习(收益函数——奖励、惩罚,经验E是由计算机与环境互动获得的) :::info 大纲:
1、传统的监督学习(所有训练数据都有对应的标签)
a、支持向量机
b、人工神经网络
c、深度神经网络
2、非监督学习(所有训练数据都没有对应的标签)
a、聚类
b、EM算法
c、主成分分析
3、半监督学习(训练数据中一部分有标签,一部分没有标签) :::

c、机器学习的实现过程
特征提取
通过训练样本,获得对机器学习有帮助的多维度数据

特征选择
选择有区分度的特征

特征空间

- 步骤


d、总结
人脸识别、人脸性别年龄估计、五子棋对战程序、水果识别、语种识别等。
2、支持向量机
a、线性可分与线性不可分



b、支持向量机解决线性可分问题


c、支持向量机(凸优化问题/存在唯一极值——梯度下降)





d、支持向量机解决线性可分问题




若有收获,就点个赞吧
0 人点赞
