1. 事务认知
1.1 本地事务
大多数场景下,我们的应用都只需要操作单一的数据库,这种情况下的事务称之为本地事务(Local Transaction)。本地事务的 ACID 特性是数据库直接提供支持。本地事务应用架构如下所示: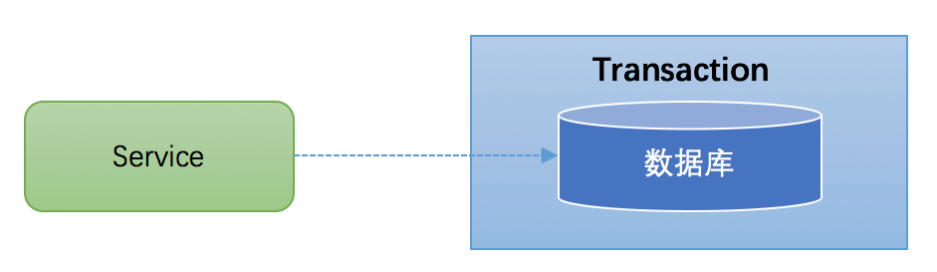
在JDBC编程中,我们通过 java.sql.Connection 对象来开启、关闭或者提交事务。代码如下所示:
Connection conn = ... //获取数据库连接conn.setAutoCommit(false); //开启事务try{//...执行增删改查sqlconn.commit(); //提交事务}catch (Exception e) {conn.rollback();//事务回滚}finally{conn.close();//关闭链接}
1.2 分布式事务使用场景
当下互联网发展如火如荼,绝大部分公司都进行了数据库拆分和服务化(SOA)。在这种情况下,完成某一个业务功能可能需要横跨多个服务,操作多个数据库。这就涉及到到了分布式事务,用需要操作的资源位于多个资源服务器上,而应用需要保证对于多个资源服务器的数据的操作,要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同资源服务器的数据一致性。
分布式事务场景:
跨库事务:指的是,一个应用某个功能需要操作多个库,不同的库中存储不同的业务数据。下图演示了一个服务同时操作2个库的情况: 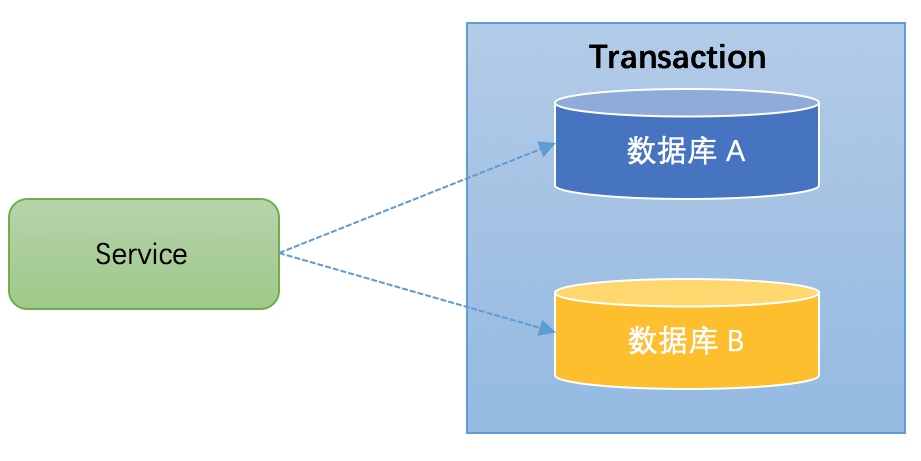
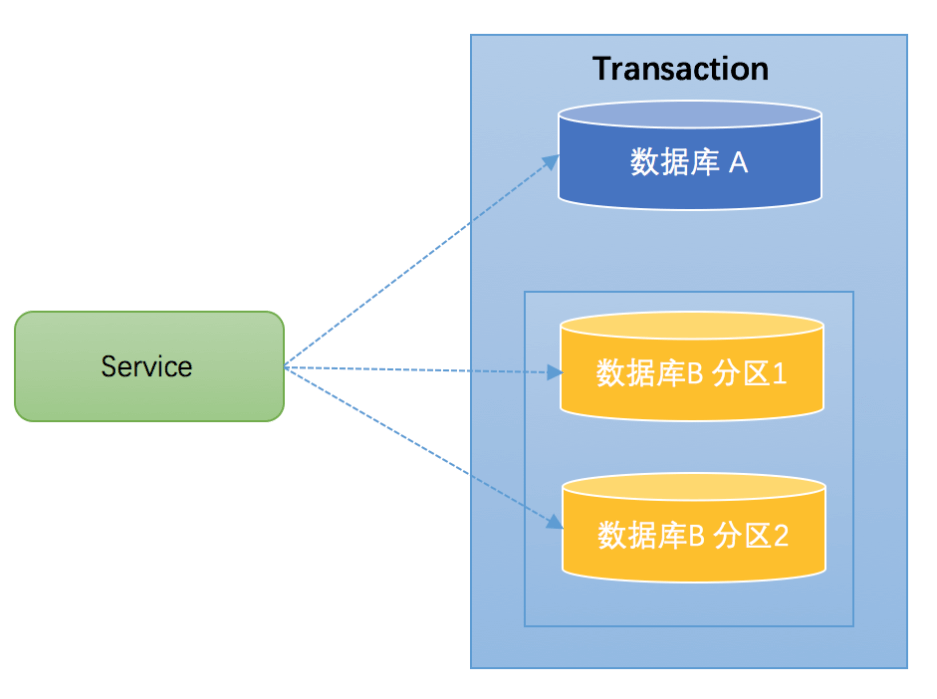
分库分表:通常一个库数据量比较大或者预期未来的数据量比较大,都会进行水平拆分,也就是分库分表。如下图,将数据库B拆分成了2个库:
- 对于分库分表的情况,一般开发人员都会使用一些数据库中间件来降低 sql 操作的复杂性。如对于sql:insert into user(id,name) values (1,”张三”),(2,”李四”)。这条sql是操作单库的语法,单库情况下,可以保证事务的一致性。
- 但是由于现在进行了分库分表,开发人员希望将1号记录插入分库1,2号记录插入分库2。所以数据库中间件要将其改写为2条sql,分别插入两个不同的分库,此时要保证两个库要不都成功,要不都失败,因此基本上所有的数据库中间件都面临着分布式事务的问题。
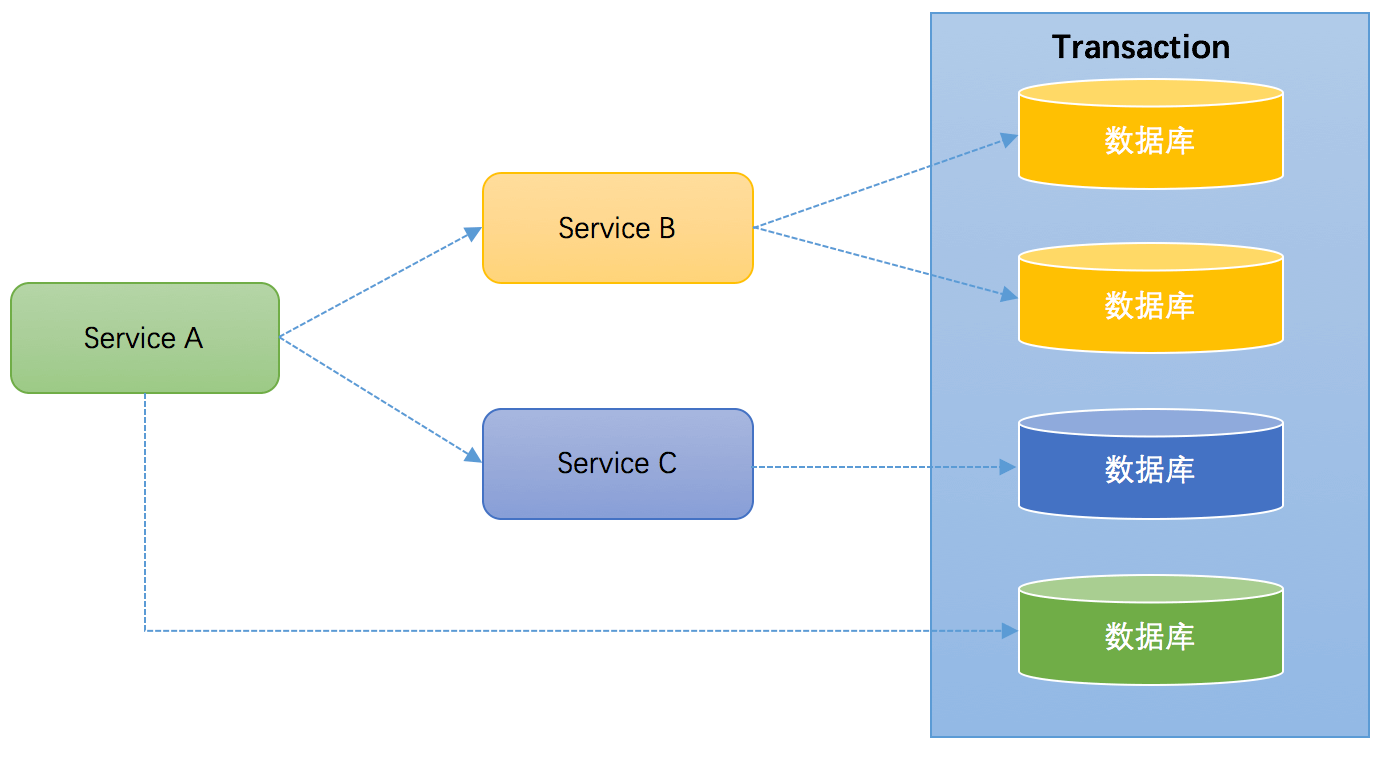
服务化:对于业务逻辑复杂的应用,应该拆分成不同的独立服务。拆分后,独立服务之间通过RPC框架来进行远程调用,实现彼此的通信。下图演示了一个3个服务之间彼此调用的架构:
- Service A完成某个功能需要直接操作数据库,同时需要调用Service B和Service C,而Service B又同时操作了2个数据库,Service C也操作了一个库。需要保证这些跨服务的对多个数据库的操作要不都成功,要不都失败,实际上这可能是最典型的分布式事务场景。
1.3 分布式事务解决方案
解决方案:seata 阿里分布式事务框架、消息队列、saga、XA
他们有一个共同点,都是“两阶段(2PC)”。“两阶段”是指完成整个分布式事务,划分成两个步骤完成。实际上,这四种常见的分布式事务解决方案,分别对应着分布式事务的四种模式:AT、TCC、Saga、XA;四种分布式事务模式,都有各自的理论基础,分别在不同的时间被提出;每种模式都有它的适用场景,同样每个模式也都诞生有各自的代表产品;而这些代表产品,可能就是我们常见的(全局事务、基于可靠消息、最大努力通知、TCC)。

若有收获,就点个赞吧
0 人点赞
