1. MyBatis-Plus入门
1.1 认识MyBatis-Plus
MyBatis-Plus(简称 MP)是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
- 润物无声
- 只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑。
- 效率至上
- 只需简单配置,即可快速进行 CRUD 操作,从而节省大量时间。
- 丰富功能
- 热加载、代码生成、分页、性能分析等功能一应俱全。
1.2 初体验
1、创建数据库:mybatis_plus。
2、创建 user 表,并插入一些数据。 ```sql CREATE TABLE user ( id BIGINT(20) NOT NULL COMMENT ‘主键ID’, name VARCHAR(30) NULL DEFAULT NULL COMMENT ‘姓名’, age INT(11) NULL DEFAULT NULL COMMENT ‘年龄’, email VARCHAR(50) NULL DEFAULT NULL COMMENT ‘邮箱’, PRIMARY KEY (id) );
- 热加载、代码生成、分页、性能分析等功能一应俱全。
INSERT INTO user (id, name, age, email) VALUES (1, ‘Jone’, 18, ‘test1@baomidou.com’), (2, ‘Jack’, 20, ‘test2@baomidou.com’), (3, ‘Tom’, 28, ‘test3@baomidou.com’), (4, ‘Sandy’, 21, ‘test4@baomidou.com’), (5, ‘Billie’, 24, ‘test5@baomidou.com’);
3、设置 Java 编译器为 1.8,项目和文件的编码为 UTF-8,maven 为自己本地的库。<br />4、创建 maven 项目,设置 springboot 版本为 2.2.1.RELEASE,引入 MyBatis-Plus 依赖(不要再次引入 MyBatis,避免版本差异问题)。```xml<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><!-- 防止springboot 启动就停止 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope><exclusions><exclusion><groupId>org.junit.vintage</groupId><artifactId>junit-vintage-engine</artifactId></exclusion></exclusions></dependency><!--mybatis-plus--><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.3.1</version></dependency><!--mysql运行时依赖--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><scope>runtime</scope></dependency><!--lombok用来简化实体类--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency></dependencies>
4、配置 application.yml 文件,注意:springboot2.0 内置 jdbc5 驱动,springboot2.1及以上 内置 jdbc8 驱动。
spring:datasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/mybatis_plus?serverTimezone=GMT%2B8username: rootpassword: 123456
?serverTimezone=GMT%2B8 解决服务器时间无法解析的问题
java.sql.SQLException: The server time zone value ‘Öйú±ê׼ʱ¼ä’ is unrecognized or represents more
5、在 SpringBoot 启动类中添加 @MapperScan 注解,扫描 Mapper 文件夹。
6、创建包 entity 编写实体类 User。
@Datapublic class User {private Long id;private String name;private Integer age;private String email;}
7、创建包 mapper 编写 Mapper 接口:UserMapper。
@Repositorypublic interface UserMapper extends BaseMapper<User> {}
8、添加测试类,进行功能测试,查看结果。
@SpringBootTestclass MybatisPlusApplicationTests {//因为找不到注入的对象,类是动态创建的,但是程序可以运行,在 dao 层接口上添加 @Repository 注解@Autowiredprivate UserMapper userMapper;@Testvoid contextLoads() {//selectList中的参数是 MP 内置的条件封装器 WrapperList<User> users = userMapper.selectList(null);users.forEach(System.out::println);}}

9、查看 sql 输出日志。
#查看sql输出日志mybatis-plus:configuration:log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
1.3 插入操作
@SpringBootTestclass MybatisPlusApplicationTests {//因为找不到注入的对象,类是动态创建的,但是程序可以运行,在 dao 层接口上添加 @Repository 注解@Autowiredprivate UserMapper userMapper;@Testvoid contextLoads() {//selectList中的参数是 MP 内置的条件封装器 WrapperList<User> users = userMapper.selectList(null);users.forEach(System.out::println);User user = new User();user.setAge(12);user.setEmail("2343242@qq.com");user.setName("威少");int result = userMapper.insert(user);System.out.println("影响的行数:" + result);System.out.println("id:" + user); //id自动回填}}

注意: 数据库插入 id 值默认为:全局唯一 id,随机生成。
1.4 更新操作
@Testvoid updateUser() {User user = new User();user.setId(1L);user.setAge(23);int result = userMapper.updateById(user);System.out.println("影响的行数:" + result);}
注意:update 生成的 sql 是:update user set age = ? where id = ?;
2. 数据库分库分表策略
2.1 背景
随着业务规模的不断扩大,需要选择合适的方案去应对数据规模的增长,以应对逐渐增长的访问压力和数据量。数据库的扩展方式主要包括:业务分库、主从复制,数据库分表。
2.2 业务分库
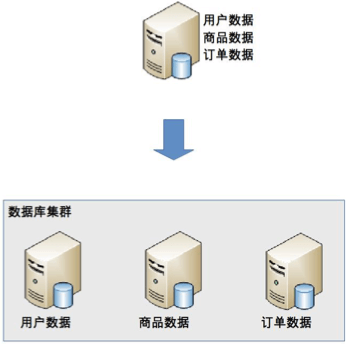
业务分库 就是根据业务模块将数据分散到不同的数据库服务器下。例如:一个简单的电商网站,包括用户、商品、订单三个业务模块,可以将用户数据、商品数据、订单数据分开放到三台不同的数据库服务器上,而不是将所有数据都放在一台数据库服务器上,这样的就变成了3个数据库同时承担压力,系统的吞吐量自然就提高了。
带来的问题
- 无法进行不同数据库的表 join 操作。
- 业务分库后,表分散到不同的数据库中,无法通过事务统一修改,考虑分布式事务等等。
- 成本变高了,本来 1 台服务器能搞定的事情变成了 3 台。
2.3 主从复制和读写分离
读写分离 的基本原理是将数据库读写操作分散到不同的节点上,其基本实现是:
- 数据库服务器搭建主从集群,一主一从、一主多从都可以。
- 数据库主机负责读写操作,从机只负责读操作。
- 数据库主机通过复制将数据同步到从机,每台数据库服务器都存储了所有的业务数据。
- 业务服务器将写操作发给数据库主机,将读操作发给数据库从机。

2.4 数据库分表
将不同业务数据分散存储到不同的数据库服务器,能够支撑百万甚至千万用户规模的业务,但如果业务继续发展,同一业务的单表数据也会达到单台数据库服务器的处理瓶颈。例如,淘宝的几亿用户数据,如果全部存放在一台数据库服务器的一张表中,肯定是无法满足性能要求的,此时就需要对单表数据进行拆分。单表数据拆分有两种方式:垂直分表和水平分表。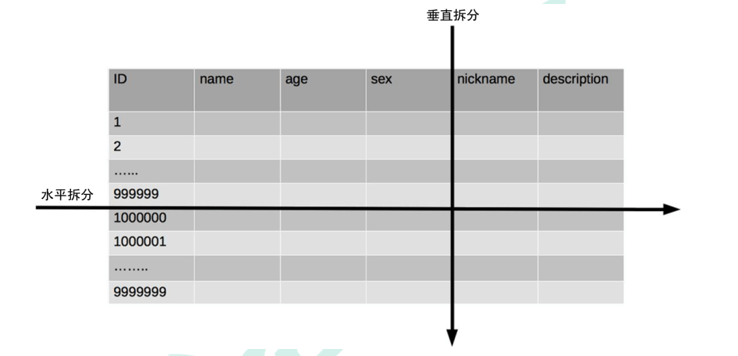
- 垂直分表:
- 分的是列。
- 垂直分表适合将表中某些不常用且占了大量空间的列拆分出去。
- 例如,前面示意图中的 nickname 和 description 字段,假设我们是一个婚恋网站,用户在筛选其他用户的时候,主要是用 age 和 sex 两个字段进行查询,而 nickname 和 description 两个字段主要用于展示,一般不会在业务查询中用到。description 本身又比较长,因此我们可以将这两个字段独立到另外一张表中,这样在查询 age 和 sex 时,就能带来一定的性能提升。
水平分表:
- 分的是行。
- 水平分表适合表行数特别大的表,有的公司要求单表行数超过 5000 万就必须进行分表,这个数字可以作为参考,但并不是绝对标准,关键还是要看表的访问性能。对于一些比较复杂的表,可能超过 1000 万就要分表了;而对于一些简单的表,即使存储数据超过 1 亿行,也可以不分表。
- 当看到表的数据量达到千万级别时,就要警惕了。
水平分表相比垂直分表,引入更多的复杂性:
主键自增:
- 以最常见的用户 ID 为例,可以按照 1000000 的范围大小进行分段,1 ~ 999999 放到表 1中,1000000 ~ 1999999 放到表2中,以此类推。
- 复杂点:分段大小的选取。分段太小会导致切分后子表数量过多,增加维护复杂度;分段太大可能会导致单表依然存在性能问题,一般建议分段大小在 100 万至 2000 万之间,具体需要根据业务选取合适的分段大小。
- 优点:可以随着数据的增加平滑地扩充新的表。例如,现在的用户是 100 万,如果增加到 1000 万,只需要增加新的表就可以了,原有的数据不需要动。
- 缺点:分布不均匀,假如按照 1000 万来进行分表,有可能某个分段实际存储的数据量只有 1000 条,而另外一个分段实际存储的数据量有 900 万条。
- Hash:
- 同样以用户 ID 为例,假如我们一开始就规划了 10 个数据库表,路由算法可以简单地用 user_id % 10 的值来表示数据所属的数据库表编号,ID 为 985 的用户放到编号为 5 的子表中,ID 为 10086 的用户放到编号为 6 的子表中。
- 复杂点:初始表数量的选取。表数量太多维护比较麻烦,表数量太少又可能导致单表性能存在问题。
- 优点:表分布比较均匀。
- 缺点:扩充新的表很麻烦,所有数据都要重分布。
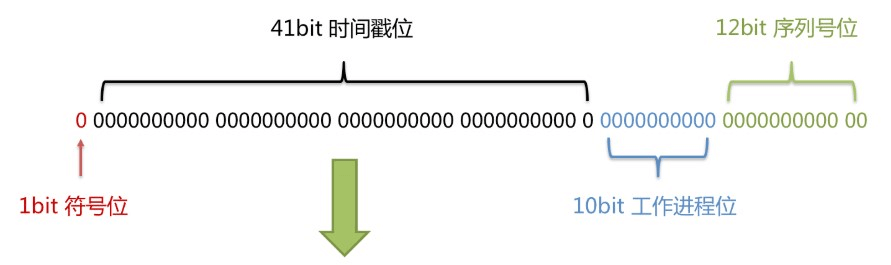
- 雪花算法:分布式 ID 生成器
- 雪花算法是由 Twitter 公布的分布式主键生成算法,它能够保证不同表的主键的不重复性,以及相同表的主键的有序性。
- 核心思想:
- 长度共 64bit(一个 long 型)。
- 首先是一个符号位,1bit标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0。
- 41bit 时间截(毫秒级),存储的是时间截的差值(当前时间截 - 开始时间截),结果约等于 69.73 年。
- 10bit 作为机器的ID(5个bit是数据中心,5个 bit 的机器ID,可以部署在 1024 个节点)。
- 12bit 作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID)。
- 优点:整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞,并且效率较高。
3. MP的主键策略
3.1 ASSIGN_ID
默认主键策略是:ASSIGN_ID(使用了雪花算法)
@TableId(type = IdType.ASSIGN_ID)private String id;
3.2 AUTO 自增策略
- 需要在创建数据表的时候设置 主键自增
- 实体字段中配置 @TableId(type = IdType.AUTO)
@TableId(type = IdType.AUTO)private Long id;
要想影响所有实体的配置,可以设置全局主键配置
mybatis-plus:configuration:log-impl: org.apache.ibatis.logging.stdout.StdOutImpl #查看sql输出日志global-config:db-config:id-type: assign_id #所有实体主键策略
4. 自动填充
4.1 需求
项目中经常会用到的一些数据,比如 创建时间、更新时间等等,不需要我们自己写,就可以使用 MyBatis Plus 的自动填充功能。
4.2 具体步骤
1、在 user 表中添加 datetime 类型的新字段 create_time、update_time。
2、在实体类上增加字段并添加自动填充注解。
@Datapublic class User {@TableId(type = IdType.ASSIGN_ID) //默认主键策略,使用雪花算法private Long id;private String name;private Integer age;private String email;@TableField(fill = FieldFill.INSERT)private Date createTime;@TableField(fill = FieldFill.INSERT_UPDATE)private Date updateTime;}
3、实现元对象处理器接口。
//MyMetaObjectHandler会被Spring的上下文自动调用@Slf4j@Component //spring一启动,所表示的这个类的对象会被spring初始化出来public class MyMetaObjectHandler implements MetaObjectHandler {@Overridepublic void insertFill(MetaObject metaObject) {log.info("start insert fill ....");this.setFieldValByName("createTime", new Date(), metaObject);this.setFieldValByName("updateTime", new Date(), metaObject);}@Overridepublic void updateFill(MetaObject metaObject) {log.info("start update fill ....");this.setFieldValByName("updateTime", new Date(), metaObject);}}

5. 乐观锁
5.1 场景
一件商品,成本价是 80 元,售价是 100 元。老板先是通知小李,说你去把商品价格增加 50 元。小李正在玩游戏,耽搁了一个小时。正好一个小时后,老板觉得商品价格增加到 150 元,价格太高,可能会影响销量。又通知小王,你把商品价格降低30元。
此时,小李和小王同时操作商品后台系统。小李操作的时候,系统先取出商品价格 100 元;小王也在操作,取出的商品价格也是100 元。小李将价格加了 50 元,并将 100+50=150 元存入了数据库;小王将商品减了30元,并将 100-30=70 元存入了数据库。是的,如果没有锁,小李的操作就完全被小王的覆盖了。现在商品价格是 70 元,比成本价低 10 元。几分钟后,这个商品很快出售了1千多件商品,老板亏1多万。
- 如果是乐观锁,小王保存价格前,会检查下价格是否被人修改过了。如果被修改过了,则重新取出的被修改后的价格,150元,这样他会将120元存入数据库。
如果是悲观锁,小李取出数据后,小王只能等小李操作完之后,才能对价格进行操作,也会保证最终的价格是120元。
5.2 模拟修改冲突
1、数据库增加商品表并添加数据。
CREATE TABLE product(id BIGINT(20) NOT NULL COMMENT '主键ID',name VARCHAR(30) NULL DEFAULT NULL COMMENT '商品名称',price INT(11) DEFAULT 0 COMMENT '价格',version INT(11) DEFAULT 0 COMMENT '乐观锁版本号',PRIMARY KEY (id));INSERT INTO product (id, NAME, price) VALUES (1, '外星人笔记本', 100);
2、创建对应实体类。
@Datapublic class Product {private Long id;private String name;private Integer price;private Integer version;}
3、创建对应 Mapper。
@Repositorypublic interface ProductMapper extends BaseMapper<Product> {}
4、测试,模拟冲突。
@Testvoid testConcurrentUpdate() {//1.小李Product p1 = productMapper.selectById(1L);System.out.println("小李取出的价格:" + p1.getPrice());//2.小王此时也取数据Product p2 = productMapper.selectById(1L);System.out.println("小王取出的价格:" + p2.getPrice());//3.小李将价格加了50元,存入了数据库p1.setPrice(p1.getPrice() + 50);productMapper.updateById(p1);//4.小王将价格减了30元,存入了数据库p2.setPrice(p2.getPrice() - 30);int result = productMapper.updateById(p2);//5.查看结果if (result == 0) { //更新失败,重试//重新获取数据p2 = productMapper.selectById(1L);//更新p2.setPrice(p2.getPrice() - 30);productMapper.updateById(p2);}//6.输出最终结果Product p3 = productMapper.selectById(1L);System.out.println("最后的结果:" + p3.getPrice());}
5.3 解决方案
1、数据库添加 version 字段。
2、取出记录时,获取当前 version。SELECT id,`name`,price,`version` FROM product WHERE id=1
3、更新时,version + 1,如果where语句中的version版本不对,则更新失败。
UPDATE product SET price=price+50, `version`=`version` + 1 WHERE id=1 AND `version`=1
5.4 乐观锁实现流程
1、修改实体类,添加
@Version注解。@Versionprivate Integer version;
2、创建配置文件,在 config 目录下创建 MyBatisPlusConfig,注册乐观锁插件。
@EnableTransactionManagement@Configuration@MapperScan("com.xuwei.mapper")public class MyBatisPlusConfig {/*** 乐观锁插件* @return*/@Beanpublic OptimisticLockerInterceptor optimisticLockerInterceptor() {return new OptimisticLockerInterceptor();}}
6. 查询
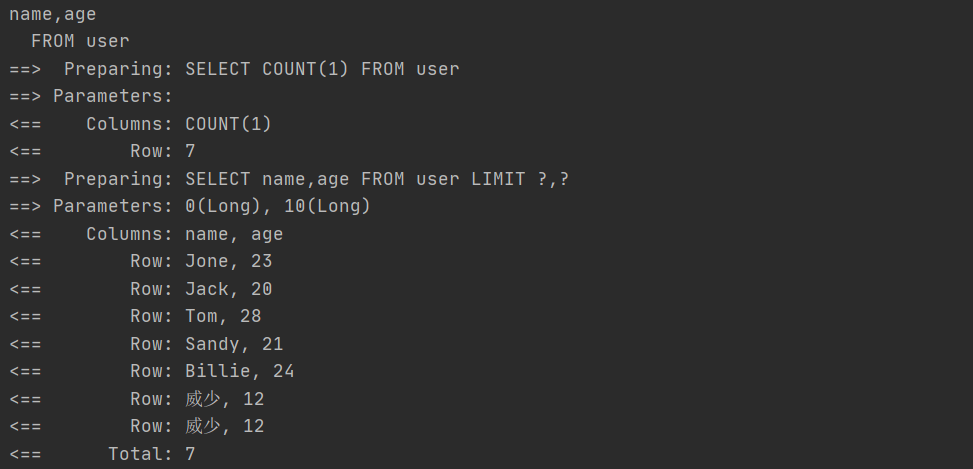
6.1 通过多个id批量查询
//通过多个id批量查询@Testvoid testSelectBatchIds() {List<User> users = userMapper.selectBatchIds(Arrays.asList(1, 2, 3));users.forEach(System.out::println);}
6.2 通过map封装查询条件
//通过map封装查询@Testvoid testSelectByMap() {HashMap<String, Object> map = new HashMap<>();map.put("name", "hello");map.put("age", 18);List<User> users = userMapper.selectByMap(map);users.forEach(System.out::println);}
6.3 分页
1、MyBatis-Plus 自带分页插件,在配置类中添加
@Bean配置。/*** 分页插件* @return*/@Beanpublic PaginationInterceptor paginationInterceptor() {return new PaginationInterceptor();}
2、测试 selectPage 分页,通过 page 对象获取相关数据。
//测试分页@Testvoid testselectPage() {Page<User> page = new Page<>(1,5);Page<User> pageParam = userMapper.selectPage(page, null); //获取分页对象pageParam.getRecords().forEach(System.out::println);System.out.println(pageParam.getCurrent());System.out.println(pageParam.getPages());System.out.println(pageParam.getSize());System.out.println(pageParam.getTotal());System.out.println(pageParam.hasNext());System.out.println(pageParam.hasPrevious());}

3、返回特定的列,而不是很多 null 值。//返回特定的列@Testvoid testselectMapsPage() {Page<Map<String, Object>> page = new Page<Map<String, Object>>(); //默认每页显示10条数据QueryWrapper<User> queryWrapper = new QueryWrapper<>();queryWrapper.select("name", "age");Page<Map<String, Object>> pageParam = userMapper.selectMapsPage(page, queryWrapper);List<Map<String, Object>> records = pageParam.getRecords();records.forEach(System.out::println);System.out.println(pageParam.getCurrent());System.out.println(pageParam.getPages());System.out.println(pageParam.getSize());System.out.println(pageParam.getTotal());System.out.println(pageParam.hasNext());System.out.println(pageParam.hasPrevious());}
7. 删除
7.1 通过id删除
//通过id删除@Testvoid testDeleteById() {int result = userMapper.deleteById(5L);System.out.println(result);}
7.2 批量删除
//批量删除@Testvoid testDeleteBatchIds() {int result = userMapper.deleteBatchIds(Arrays.asList(8,9,10));System.out.println(result);}
7.3 通过map删除
//通过map条件删除@Testvoid testDeleteByMap() {HashMap<String, Object> map = new HashMap<>();map.put("name", "Helen");map.put("age", 18);int result = userMapper.deleteByMap(map);System.out.println(result);}
7.4 逻辑删除
物理删除:真实删除,将对应数据从数据库中删除,之后查询不到此条被删除数据。
- 逻辑删除:假删除,将对应数据中代表是否被删除字段状态修改为“被删除状态”,之后在数据库中仍旧能看到此条数据记录。
- 可以进行数据恢复。
- 有关联数据,不便删除。



1、数据库修改,添加 deleted 字段。
ALTER TABLE `user` ADD COLUMN `deleted` boolean DEFAULT false
2、实体类添加 deleted 字段,并加上 @TableLogic 注解。
@TableLogicprivate Integer deleted;
3、测试删除语句。
@Testpublic void testLogicDelete() {int result = userMapper.deleteById(1L);System.out.println(result);}
4、测试逻辑删除后的查询。
@Testpublic void testLogicDeleteSelect() {List<User> users = userMapper.selectList(null);users.forEach(System.out::println);}


8. 条件构造器
8.1 wapper入门

Wrapper : 条件构造抽象类,最顶端父类 。
- AbstractWrapper : 用于查询条件封装,生成 sql 的 where 条件。
- QueryWrapper : 查询条件封装。
- UpdateWrapper : Update 条件封装。
AbstractLambdaWrapper : 使用Lambda 语法。
- LambdaQueryWrapper :用于Lambda语法使用的查询Wrapper。
- LambdaUpdateWrapper : Lambda 更新封装Wrapper。
8.2 ge、gt、le、lt、isNull、isNotNull
//ge、gt、le等@Testvoid testDeleteWrapper() {QueryWrapper<User> queryWrapper = new QueryWrapper<>();queryWrapper.isNull("name").ge("age", 12).isNotNull("email"); //ge表示大于等于,le表示小于等于int result = userMapper.delete(queryWrapper);System.out.println("delete return count = " + result);}
8.3 eq、ne
//eq、ne@Testvoid testselectOne() { //selectOne返回的是一条实体记录,出现多条会报错QueryWrapper<User> queryWrapper = new QueryWrapper<>();queryWrapper.eq("name", "Tom");User user = userMapper.selectOne(queryWrapper);System.out.println(user);}

8.4 between、notBetween
@Testvoid testselectCount() { //selectOne返回的是一条实体记录,出现多条会报错QueryWrapper<User> queryWrapper = new QueryWrapper<>();queryWrapper.between("age", 10, 30);int result = userMapper.selectCount(queryWrapper);System.out.println(result);}
8.5 like、notLike、likeLeft、likeRight
@Testvoid testselectMaps() { //selectOne返回的是一条实体记录,出现多条会报错QueryWrapper<User> queryWrapper = new QueryWrapper<>();queryWrapper.select("name", "age").like("name","e").likeRight("email", "5");List<Map<String, Object>> maps = userMapper.selectMaps(queryWrapper);maps.forEach(System.out::println);}
8.6 in、notIn、inSql、notinSql、exists、notExists
```java @Test public void testSelectObjs() {
QueryWrapper
queryWrapper = new QueryWrapper<>(); // queryWrapper.in(“id”, 1, 2, 3); queryWrapper.inSql(“id”, “select id from user where id <= 3”); List
- AbstractWrapper : 用于查询条件封装,生成 sql 的 where 条件。

若有收获,就点个赞吧
0 人点赞
