RabbitMQ集群脑裂
- 问题:
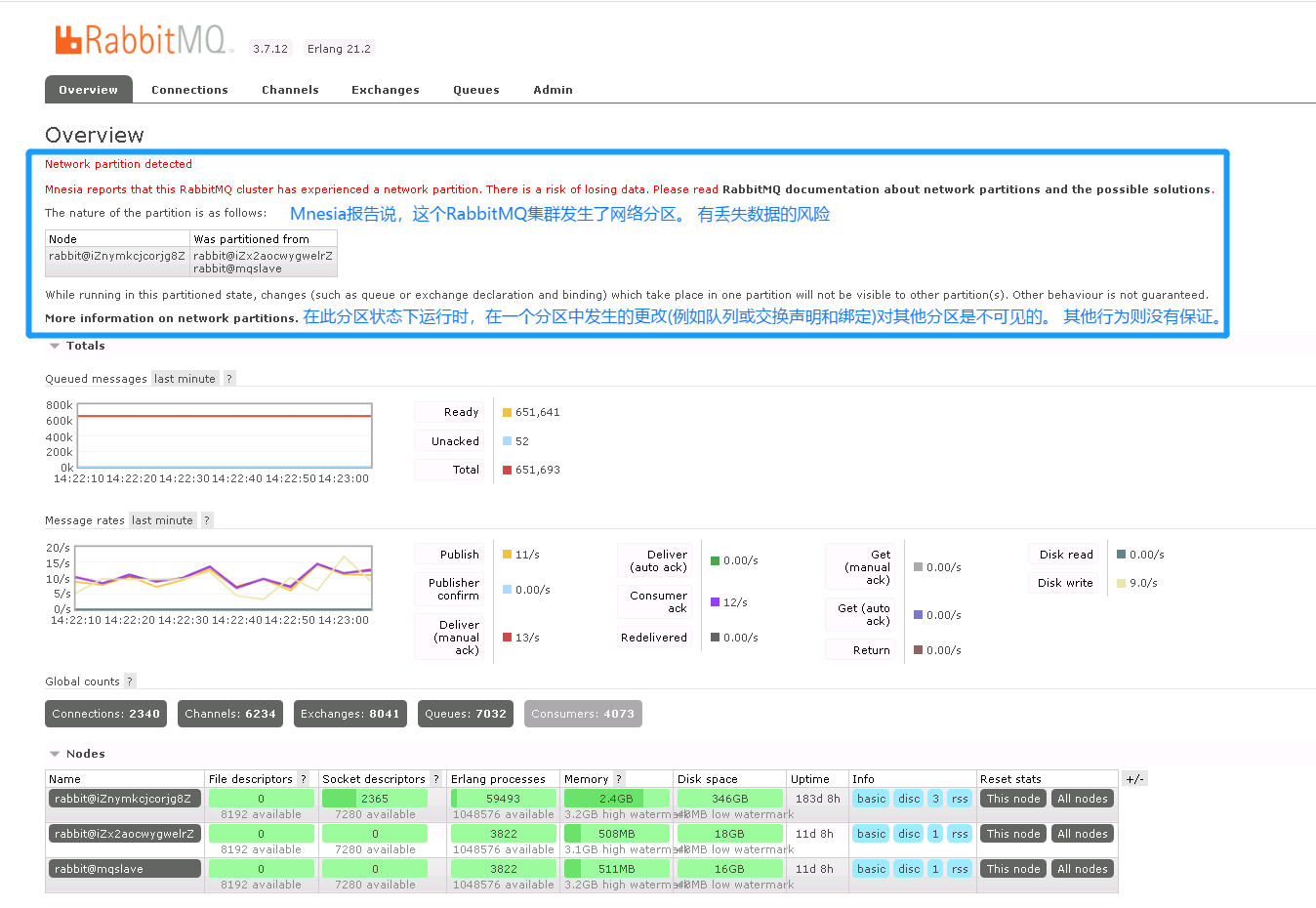
Mnesia reports that this RabbitMQ cluster has experienced a network partition. There is a risk of losing data
什么是脑裂?
判定条件
如果另一个节点在一段时间内(默认为 60 秒)无法与其联系,则节点会确定其对等方是否关闭。如果两个节点重新接触,并且都认为另一个节点已关闭,则节点将确定发生了分区。
当网络分区就位时,集群的两个(或更多!)方可以独立发展,双方都认为对方已经崩溃。这种情况被称为裂脑。队列、绑定、交换可以单独创建或删除。
- 跨分区拆分的经典镜像队列最终将在分区的每一侧都有一个领导者,同样双方独立行动。仲裁队列将在多数方选举一个新的领导者。少数方的仲裁队列副本将不再有进展(即接受新消息、交付给消费者等),所有这些工作都将由新的领导者完成。
- 除非将分区处理策略(例如pause_minority)配置为使用,否则即使在网络连接恢复后,拆分仍将继续
脑裂现象
rabbitmq集群的网络分区容错性不好,在网络比较差的情况下容易出错,最明显的就是脑裂问题了 不要将你的rabbitmq集群建立在广域网上,除非你使用federation或者shovel等插件 所谓的脑裂问题,就是在多机集群中节点与节点之间失联,都认为对方出现故障,而自身裂变为独立的个体,各自为政,那么就出现了抢夺对方的资源,争抢启动,至此就发生了事故。
举个栗子:
- A和B是集群上的两个节点,分别拥有一部分集群的数据a,b, 如果这时发生分区问题,两个节点无法通信,A以为B宕机,B以为A宕机,于是就出现了:
- 如果A存在B的备份,那就以完整数据运行,B存在A的数据备份,也是同样, 那这里就造成共享数据损坏
- 如果 A,B 各自仅拥有a,b 的数据,那要么都无法恢复/启动,要么就瓜分数据运行。
什么原因造成脑裂,怎样查看
原因:由于网络问题导致集群出现了脑裂。
正常情况下,通过rabbitmqctl cluster_status命令查看到的信息中partitions那一项是空的,就像这样:
# rabbitmqctl cluster_statusCluster status of node rabbit@smacmullen ...[{nodes,[{disc,[hare@smacmullen,rabbit@smacmullen]}]},{running_nodes,[rabbit@smacmullen,hare@smacmullen]},{partitions,[]}]...done.
然而当网络分区发生时,会变成这样:
# rabbitmqctl cluster_statusCluster status of node rabbit@smacmullen ...[{nodes,[{disc,[hare@smacmullen,rabbit@smacmullen]}]},{running_nodes,[rabbit@smacmullen,hare@smacmullen]},# 参数增加{partitions,[{rabbit@smacmullen,[hare@smacmullen]},{hare@smacmullen,[rabbit@smacmullen]}]}]...done.
解决脑裂
原因是rabbitmq集群在配置时未设置出现网络分区处理策略,先要将集群恢复正常,再设置出现网络分区处理策略,步骤如下:
- (1)首先需要挑选一个信任的分区,这个分区才有决定Mnesia内容的权限,发生在其他分区的改变将不被记录到Mnesia中而直接丢弃。
(2)停止(stop)其他分区的节点,然后启动(start)这些节点,之后重新将这些节点加入到当前信任的分区之中。
rabbitmqctl stop_apprabbitmqctl start_app
(3)最后,你应该重启(restart)信任的分区中所有的节点,以去除告警。你也可以简单的关闭整个集群的节点,然后再启动每一个节点,当然,你要确保你启动的第一个节点在你所信任的分区之中。
注意:mq集群不能采用kill -9 杀死进程,否则生产者和消费者不能及时识别mq的断连,会影响生产者和消费者正常的业务处理
(4)设置出现网络分区处理策略,这里设置为autoheal,下面会详细说明其它策略
在/etc/rabbitmq下新建rabbitmq.conf,加入:
[{rabbit,[{tcp_listeners,[5672]},{cluster_partition_handling, autoheal}]}].
网络分区处理策略
有以下3种处理策略:
- (1)ignore
默认类型,不处理。
要求你所在的网络环境非常可靠。例如,你的所有 node 都在同一个机架上,通过交换机互联,并且该交换机还是与外界通信的必经之路。
- (2)pause_minority
rabbitmq节点感知集群中其他节点down掉时,会判断自己在集群中处于多数派还是少数派,也就是判断与自己形成集群的节点个数在整个集群中的比例是否超过一半。如果是多数派,则正常工作,如果是少数派,则会停止rabbit应用并不断检测直到自己成为多数派的一员后再次启动rabbit应用。
注意:这种处理方式集群通常由奇数个节点组成。在CAP中,优先保证了CP。
注意:pause_minority适用情形有限制,如3个节点集群,每次只down1个时,此模式适用。但如果网络都出问题,3节点会独立形成3个集群。
- (3)autoheal
你的网络环境可能是不可靠的。你会更加关心服务的可持续性,而非数据完整性。你可以构建一个包含2个node的集群。
当网络分区恢复后,rabbitmq各分区彼此进行协商,分区中客户端连接数最多的为胜者,其余的全部会进行重启,恢复到同步状态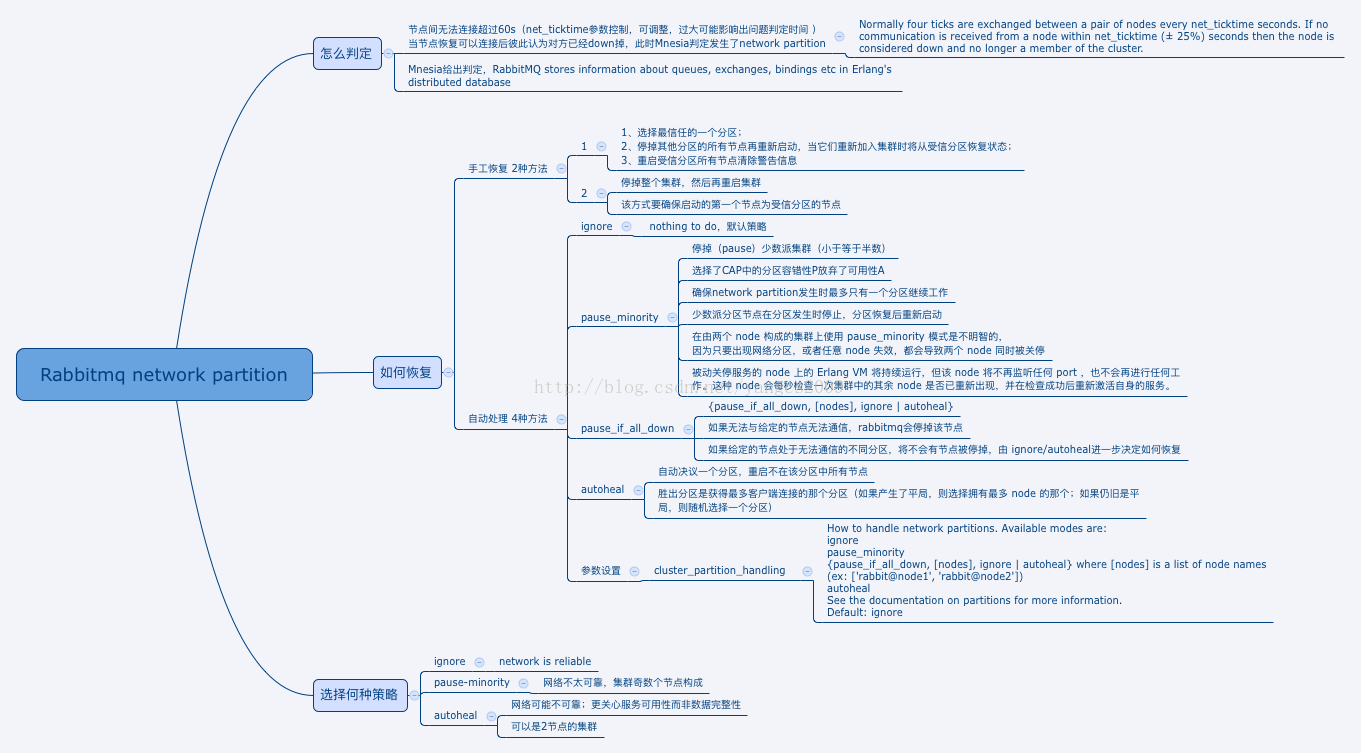

若有收获,就点个赞吧
0 人点赞
