- 没有聚合函数(sum)无法查看,可以通过遍历来直接看
遍历查看: ```python for (method,group) in planets.groupby([‘method’])[‘orbital_period’]: print(“{0:30s} shape={1}”.format(method,group.shape))planets.groupby('method')['orbital_period']<pandas.core.groupby.generic.SeriesGroupBy object at 0x000001C7C03045C8>
for (_,group) in planets.groupby(‘method’): print(group)
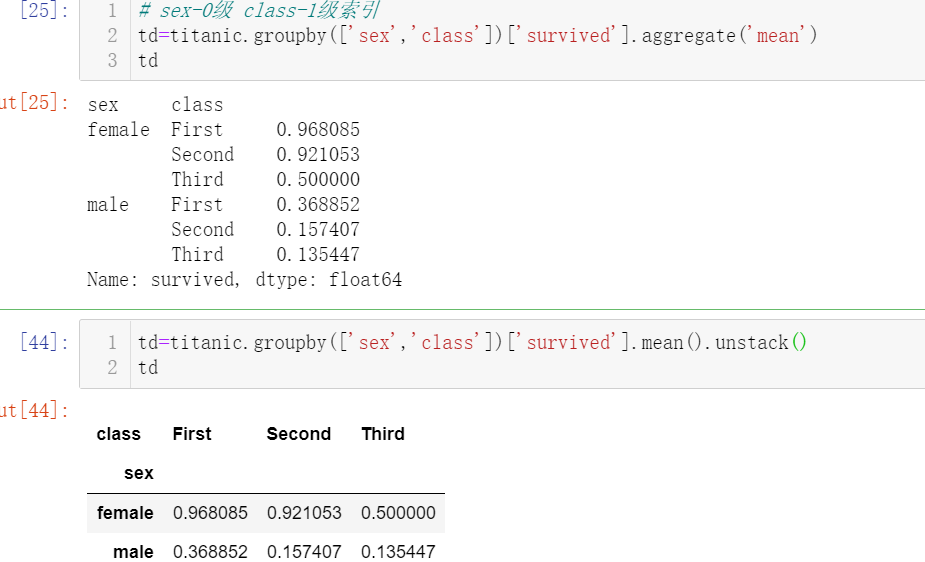
<a name="0iuH7"></a># 透视表可以做groupby可以做到的任何事<a name="cAB0Y"></a>#### 1.透视表查看不同性别的生存率:pivot_table()[¶](http://localhost:8888/notebooks/%E6%B3%B0%E5%9D%A6%E5%B0%BC%E5%85%8B%E5%8F%B7%E5%A4%84%E7%90%86%E6%95%B0%E6%8D%AE.ipynb#1.%E9%80%8F%E8%A7%86%E8%A1%A8%E6%9F%A5%E7%9C%8B%E4%B8%8D%E5%90%8C%E6%80%A7%E5%88%AB%E7%9A%84%E7%94%9F%E5%AD%98%E7%8E%87:pivot_table())```pythonpd.pivot_table(data=titanic,values='survived',index='sex',columns='class',aggfunc='mean')
columns=[1,2] 多一列谁先写谁是外层
aggfunc() 传函数,列表(多层索引),字典
1.当aggfunc传入字典俩个key时,
pt=titanic.pivot_table(values=['survived','age'],index='sex',columns=['class'],aggfunc={'survived':'mean','age':'median'})pt
2.groupby:aggregate(函数)聚合按那种方法聚合
df.agg({‘A’ : [‘sum’, ‘min’], ‘B’ : [‘min’, ‘max’]})
A B
max NaN 8.0
min 1.0 2.0
sum 12.0 NaN
stack() 列转 行,行向堆叠
unstack(level=-1) 行转列
td1=titanic.groupby(['sex','class'])[['survived','age']].aggregate({'survived':'mean','age':'max'}).unstack(level=-1)
分桶: 将连续 值离散化.
将
写函数
等距分桶
pd.cut( series,bins= ):
bins=int 桶数 | [ 0,4,6] 区间 -桶左开右闭,包头不包尾
-
- labels= [ ‘’,’’] 区间别名
pd.cut(titanic['age'],bins=5)
等频分桶:
pd.qcut()
四分位数等频分.
q= int 等频分几个桶
q=[0,0.25,0.5,0.75,1] : 分为10 份,等频的放入这几个桶,
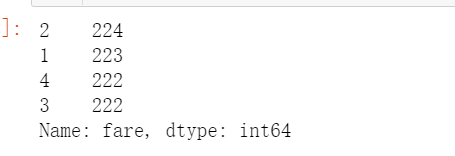
# 等频分为10份将其放入4个四分位桶.频数有一些小差距,不计算空值,fare=pd.qcut(titanic['fare'],q=[0,0.25,0.5,0.75,1],labels=['1','2','3','4']).value_counts()fare

若有收获,就点个赞吧
0 人点赞
