numpy:
ndarry: n->多个 d->维度
矢量计算,广播功能 这是与列表最大的区别.
创建数组:
import numpy
import numpy as npnp.arange(start,end,step) # step可为浮点数,range为python下的np.array(列表|元组)np.zeros((元组-shape)) 行.列np.zeros_like(arr)np.ones()np.ones_like()np.empty(size)np.linspace(start,end,points,endpoint=True)# 均匀分布的线性数组,np.eye(size) #单位矩阵np.identily() 矩阵#随机数创建np.random.seed(种子号) 固定随机数,保持模型的稳定性,数据持久np.random.rand(shape|size). 形状np.random.random(size)左闭右开 0-1np.random.randn(size) #正态分布的随机数np.random.randint(start,end,size) size:数据个数

数组属性:
arr.dtype 数组元素类型 df.dtypes type()arr.itemsize 数组元素占用内存arr.size 数组元素个数arr.shape 数组形状(几行几列)arr.ndim 维度 (行.列-二维) 行-一维
数组方法:
arr.reshape(n,n1) 改变数组形状,n行n列arr.astype(np.int) 转变元素类型arr.transpose() arr.T 转置arr.dot(arr.T) 矩阵点乘 如上图arr.max() 数组最大值arr.argmax() 返回最大值的下标arr.min()arr.argmin()arr.mean(axis) 平均值arr.mode()众数arr.medain() 中位数arr.where((condition条件),为True的执行代码,为False | 符合条件元素的所在位置)arr.std() 标准差arr.var() 方差arr.sqrt()np.log()np.log10()np.unique() 去重np.cumsum() 累加函数np.sort(axis)np.vstack((arr1,arr2)) v-vertical 垂直叠加np.hstack((arr1,arr2)) h-horizontal 水平叠加np.insert()np. append()np.isnan()
pandas
一.series
` 1.创建series:
传入数据:字典
(列表,index,dtype)
import pandas as pd#创建pd.Series(data,dtype=np.int,index=[],dtype)
`2.属性:
ser.sizeser.indexser.values :->arrayser.dtype
3.方法:
pd.isnull(ser)ser.astype()ser.map(字典) :{key待映射数据: 映射值}serr.apply(函数)
4.索引切片:
#索引:ser[index]ser[index]=np.nan
#遍历1.for i in ser.values:2.for i in ser.index:3.for k,v in ser.items()4.for k,v in enumerate(ser4) #枚举
二. DataFrame
1.创建:
- frame=pd.DataFrame(数据, columns=[列索引], index=[行索引])
- 嵌套字典创建(外层key是列名,内层key是行名)
通过对列的索引位置交换可以改变排列:
pd.DataFrame(data, columns=[‘year’, ‘city’, ‘population’])
对于字典创建的数据在输入列索引columns时,可以添加多个索引,值为NaN
- 列索引多了不会报错,但是行索引多了会报错
1.1数据: dict{key:value} ; key—列索引 , value—数据值import numpy as npimport pandas as pd
dict{key:{key1:value}} 外层索引为列索引,内存索引为行索引
# 用字典创建dataframedata = {'city': ['北京', '北京', '北京', '上海', '上海', '上海'],'year': [2000, 2001, 2002, 2001, 2002, 2003],'population': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]}frame = pd.DataFrame(data)framecity year population0 北京 2000 1.51 北京 2001 1.72 北京 2002 3.63 上海 2001 2.44 上海 2002 2.95 上海 2003 3.2
2.属性
df.columnsdf.shapedf.dtypesdf.axes
3索引:
布尔索引:
一般根据下标索引,布尔索引可以按照真假来索引.
外层数据data[ bool值]传入的真假个数必须与外层数据个数相同.
通过比较运算符得到bool值,
df['列名'] -seriesdf.列名 #只能提取列,不能用它创建新列 -seriesdf[['列名']] -dataframedf.loc[行,列] 字符串索引df.iloc[] #integer 数字索引
4.方法:
删除列labels=columns,写了columns可以不用axisdf.drop(columns=['列名','列名'],axis=1 inplace=,errors='raise']df.drop(labels=['列名','列名'],axis=1 inplace=,errors='raise']##1.信息查看:-----------df.dtypesdf.info() #对象类型, 行数据量,列数,每列的非空数据, 数据类型,各种类型的个数,占用空间的大小df.describe(include=object) #默认数值型数据.加上include字符串也可以描述##2.空值:--------------df.isnull()df.dropna(subset=['a','b'],how=any|all,axis=0|1) #subset:子系删除df.fillna(value|dict,axis=0|1) # 值填充可定位空值,或者字典KeyValue对应单个空值定位填充df.fillna(method="ffill/bfill",limit=n) # method:向前/向后填充,limit:限制个数##3.重复值--------------df.duplicated()#判断重复值df.drop_duplicates([列名],subset=['a','b'],keep=last|first)# keep:保留第一个和最后一个## 排序-----------------df.sort_index()df.sort_values(by=''|[],ascending=False)##设置索引--------------df.set_index(keys=str) 把某一列作为索引df.reset_index(drop=) 把索引重置(0-n),drop参数:是否把现在的索引当成你的列,相当于多了一个列.##读取----------------df.head()df.tail()pd.read_csv(文件路径)pd.read_excel()pd.read_sql
5.分组:
groupby(by=[],as_index=Faelse,group_keys=False)
group_keys=”” : 将聚合的组字段是否做为分组的字段.会出来索引套索引的相同的列
在索引的基础上让他不重复出现
as_index=False :将聚合的字段是否作为索引.,变为dataframe
去掉索引
应用场景:
分组排序,填充空值,列计算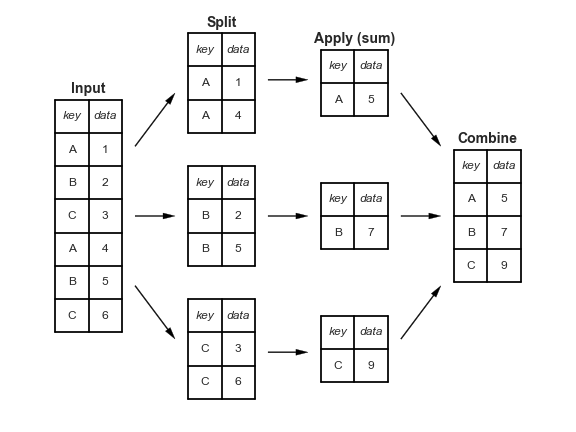
groupby(by=[],as_index=Faelse,group_keys=False)['str'].aggregate('sum'|[]|{}) #函数功能.apply() #函数.nlargest() #取前几个最大的.transform('sum') # 值计算,聚合后个数与行数相同.unstack(level=-1) 行转列,不堆.stack() 列转行,堆level,默认倒数第一层索引-1,行:最右边为最后一层,列.最下边为最后一层
5.1多个索引分组聚合,求和在排序
#计算每年销量的top3s1.groupby(['销售年份','销售代表ID'],as_index=False]).sum()['销售额'].groupby('销售年份',group_keys=False).nlargest(5).apply(lambda x:x.sort_values(by='',ascending=True)[:n])
5.2transfrom(sum)的利用
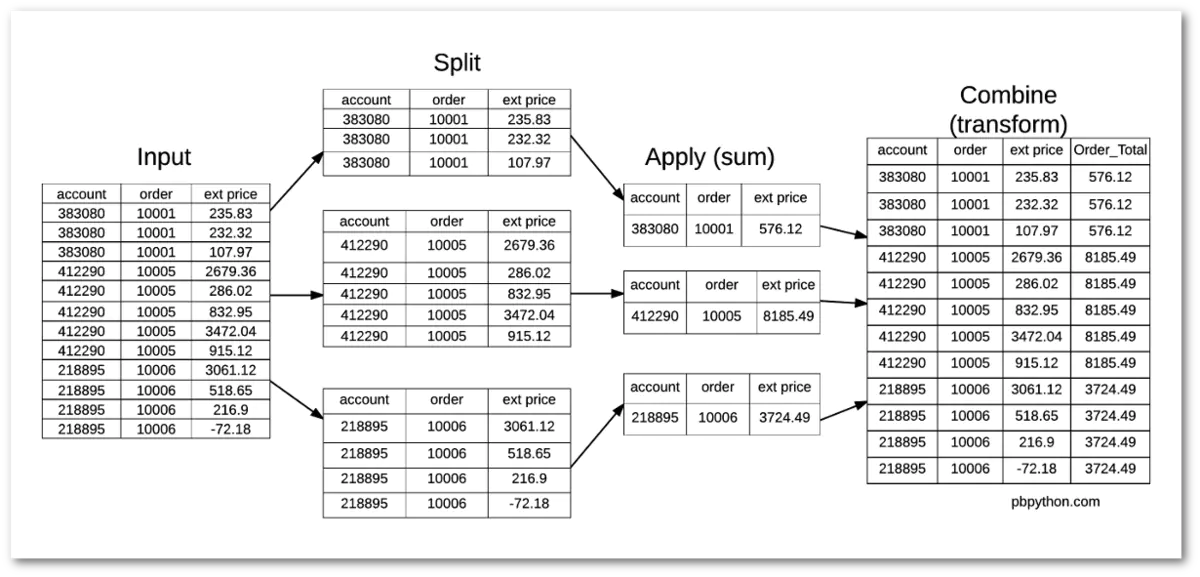
解决聚合求值后生成个数与行数不同
# transform () 对每一个数据都进行转化,传入需要的结果df1.groupby('order')[['ext price']].transform('sum')df1['percent_of_total']=df1['ext price']/df1.groupby('order')['ext price'].transform('sum')df1
apply()方法求值
total=df2.groupby('order')['ext price_y'].sum().rename('order_total')df3=pd.merge(df1,total,how='left',on='order')df3['parenr_of_total']=df3['ext price']/df3['order_total']
6.透视表
- 透视表参数利用笔记
当aggfunc 传列表时:出现多层索引的列,外层是函数,内层是列索引pd.pivot_table(data=titanic,values='survived',index='sex',columns='class',aggfunc='mean')
传字典时,对value进行操作:每一个把value 对应一个函数7.连接表
df.concat(df1,axis=)###ignore_index==reset_index(drop=True)pd.concat([df1,df2],axis=,ignore_index=True)#ignore_index,重设索引,忽略原来的索引.横向连不需要,纵向连需要,df.merge(df1)pd.merge(df1,df2,on='',left_on='',right_on='',right_index='',left_index=''/how='left'/'right'/'inner'/'outer',Suffixes=('str','str'))suffixes: 防止列重名
8.值计数:
df[ ‘’].value_counts() 排序的Series9.分桶
等距分桶
pd.cut( series,bins= ):
bins=int 桶数 | [ 0,4,6] 区间 -桶左开右闭,包头不包尾
等频分桶:#bins:分桶个数|桶界限,labels:桶区间名字pd.cut(titanic['age'],bins=n|[0,10,18] ,labels=['''''])
10.统计学异常值检测:q: 四分位数等频,分割成10份pd.qcut(titanic['age'],q=n|[0,0.25,0.5,0.75,1] ,labels=['''''])
1.正态分布数据三西格玛:
2.四分位检测
11.读取文件:
11.1 csv文件
11.2 sql 文件pd.read_csv(path)##参数-------------sep=',' 分割符,默认','enconding=utf8 编码乱码parse_date={新列名:[0,1,2]} #合并旧列为新列comment='#',删除数据中的带# 的数据skiprow=n 删除头部n行skipfooter=n 删除尾部n行
直接读取
配置环境读取直接读取:import pymysqlimport pandas as pd#创建连接con=pymysql.connect(host='localhost',user='root',password='password',db='train')# 读取数据,执行SQL语句data=pd.read_sql('select * from distribute',con)data.head()
11.3 json 文件:def function(sqli):import pymysqlimport pandas as pdconfig={'host':'localhost', #默认localhost==127.0.0.1'user':'root', # 用户名'password':'password', #密码'port':3306, #端口.默认3306'database':'train', #数据库名字'charset':'utf8' #字符编码}# 查询语句sql='SELECT * FROM %s'%(sqli)# 使用配置参数创建连接conn=pymysql.connect(**config)#用连接获得游标cursor=conn.cursor()#用游标执行SQL语句cursor.execute(sql)#通过fetchall获取数据data=cursor.fetchall()# 获取字段属性col=cursor.description#遍历数据的前5条df=pd.DataFrame(list(data))col_name=[]for i in range(len(col)):col_name.append(col[i][0])df.columns=col_nameprint(df)#关闭游标cursor.close()#关闭连接conn.close()function('distribute')
json.loads(data)
11.4 xml文件解析import requests #倒入库import json#定义地址add='九王坟'#创建访问应用时获取的AK(秘钥)mykey='DdOyOKo0VZBgdDFQnyhINKYDGkzBkuQr'#请求地址api应用程序接口 geocoder 地理url = 'http://api.map.baidu.com/geocoder/v2/?address=%s&output=json&ak=%s'# 获取返回请求res=requests.get(url% (add,mykey))#返回文本信息add_info=res.textprint(add_info)add_json=json.loads(add_info)add_json
root=Etree.fromstring(add_info)import requestsimport xml.etree.ElementTree as Etreeurl='http://api.map.baidu.com/geocoder/v2/?address=%s&output=xml&ak=%s'res=requests.get(url %(add,mykey))add_info=res.textroot=Etree.fromstring(add_info)print(add_info)
12.转数据格式:
提起年月日
.dt.year|month|day ```sql from datetime import datetime from dateutil import parser data[‘’].astype(‘datetime64[ns]’) pd.to_datetime(数据,format=’%Y%m%d%H%M%S’,errors=’coerce’) df[].apply(lambda x:parser.parse(x) df[].apply(lambda x:datetime.strptime(x,%Y%m%d%H%M%S) 将字符串转化为时间 strftime() 将时间固定为字符串
<a name="vdFcP"></a>#### 13.画图:pandas下画图:<br />import matplotlib.pyplot as plt```sql#导入画图包mat-matlab软件的一部分库import matplotlib.pyplot as plt# 换字体plt.rcParams['font.sans-serif']=['SimHei'] #plt是matplotlip包的缩写,他修改了参数# kind是图表类型a.season.value_counts().plot(kind='bar')#python的画图函数(plot)#对季度的值的个数进行统计绘图a.season.value_counts().plot(kind='pie',figsize=(10,10)) # 规定图表类型,画布大小plt.rcParams['axes.unicode_minus']=False #解决负号不出现的问题plt.show()# 图显示
matplotlib 下画图:
# 线图===============plt.plot(x,y,fmt,lw,label=)ftm- 线型,颜色,标记形状 linestyle,marker colorlw=0~1 线宽label=' ' 图例#散点图 plt.scatter 看俩个变量中间的关系========x=2*np.random.rand(100,1)y=4+3*x+np.random.randn(100,1)# 传x,y轴# c是标记点颜色,edgecolors是外层膜的颜色.lw是外层膜的厚度,s标记点大小,alpha透明度plt.scatter(x,y,alpha=0.21,s=1000,c='red',linewidths=10,edgecolors='blue')##柱状图看数据分布plt.hist()=========np.random.seed(2)data=np.random.randn(10000)# 直接传数据,bins是条个数plt.hist(data,bins=1000,alpha=0.4)plt.show()#t条形图:plt.bar()计数data=[5,20,15,25,10]# 第二个参数是高度,plt.bar(['a','b','c','d','e'],data)# [a,b,c,d]为横坐标点,data为纵坐标#饼图plt.pie([],[])========
子图的创建:
fig,ax=plt.subplots(3,3,sharex='col',sharey='row',figsize=())#返回画布和子图plt.add_subplot()plt.subplot()定义索引位置: ax=0
核密度图:kde
sns.kdeplot()#分布图:sns.displot(列)俩变量图:sns.joinplot(x,y,数据,kind='kde,hex,reg")#多变量图sns.pairplot(data,hue='spices',height=1,kind=kde) hue:分成不同的数据/系列,增加一个维度(变量),用不同颜色标记处理#热力图sns.heatmap(data.corr(),annot=True,camp='summer) 相关系数比较
=.

若有收获,就点个赞吧
0 人点赞
