一、数据仓库简介
1.1 场景分析
场景一:面向业务的、低延迟。
场景二、面向数据分析、数据挖掘的、高延迟。


1.2 数据仓库诞生原因
- 历史数据积存:历史数据使用频率低,堆积在业务数据库中,导致性能下降。
- 企业数据分析需要:通过数据抽取和清洗,将各个业务系统的数据整合落地到一个系统(数仓),规范化数据。
1.3 什么是数据仓库
数据仓库(Data Warehouse),简称DW。数据仓库顾名思义,是一个很大的数据存储集合,出于历史数据积存或企业数据分析目的而创建的,可以对多样的业务数据进行筛选和整合,为企业提供了一定的BI(商业智能)能力。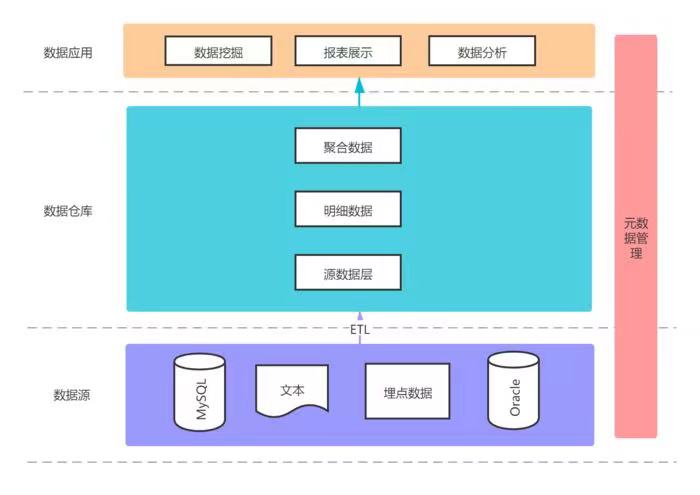
二、Hive数据仓库
2.1 什么是Hive
Hive是构建在Hadoop之上的一个开源的数据仓库分析系统,主要用于存储和处理海量结构化数据。这些海量数据一般存储在Hadoop的分布式文件系统HDFS之上,Hive可以将结构化的数据文件映射为一张数据库表,并提供类SQL(简称HQL)查询功能。
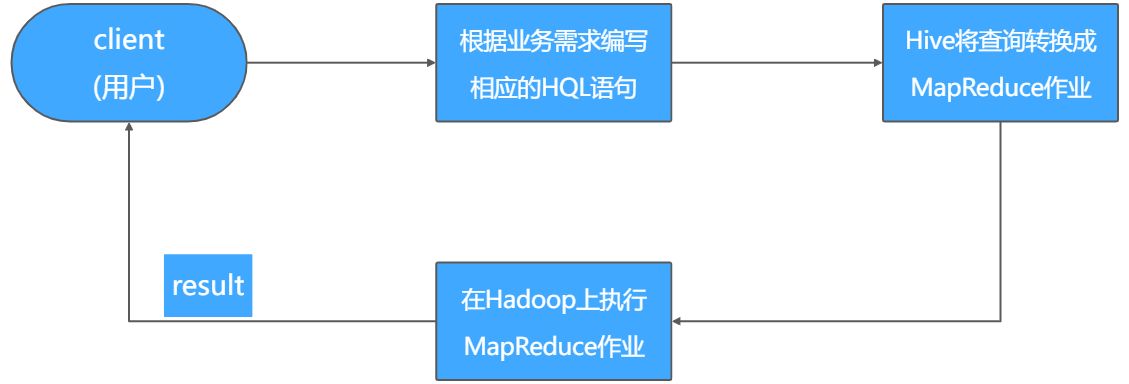
图1-1 Hive运行流程图
2.2 Hive的优缺点
优点:
1)适合大数据的批量处理,解决了传统关系型数据库在大数据处理上的瓶颈。
2)构建在Hadoop之上,充分利用了集群的存储资源、计算资源,最终实现并行计算。
3)学习使用成本低,对于企业中的非开发人员非常友好。
4)具有良好的扩展性,且能够实现和其他组件的结合使用。
缺点:
1)HQL的表达能力依然有限,不支持迭代计算,有些复杂的运算用HQL不易表达,还需要单独编写MapReduce来实现。
2)运行效率低、延迟高。
3)调优困难。由于Hive是构建在Hadoop之上的,Hive的调优还要考虑MapReduce层面,所以Hive的整体调优会比较困难。
2.3 Hive架构
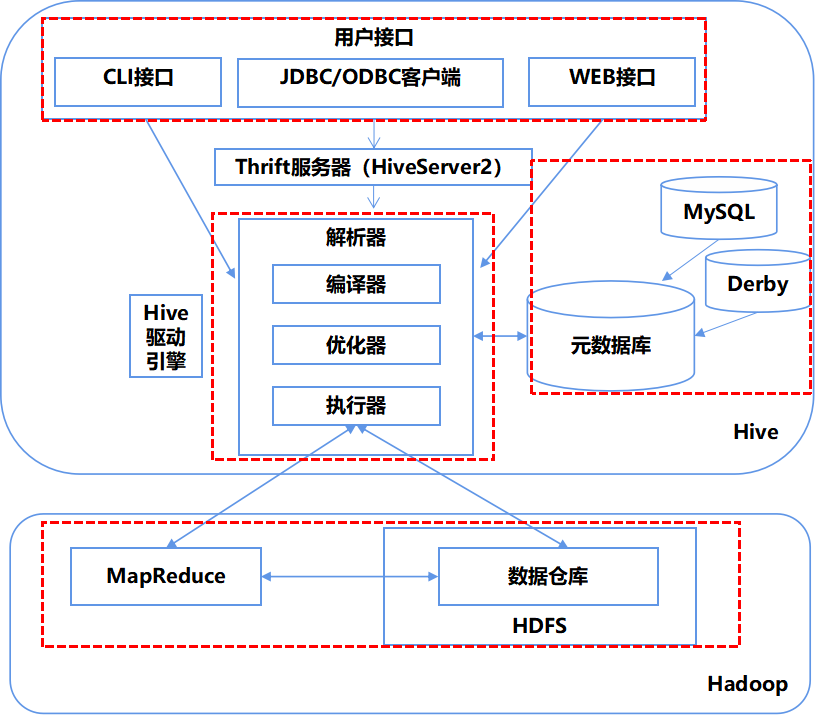
图1-2 Hive架构图
1)用户接口
- CLI接口:命令行接口
- JDBC/ODBC客户端:通过JAVA访问Hive
- Web接口:通过Web浏览器访问
图1-3 Hive-web界面图
2)Hive驱动引擎
Hive的核心是Hive驱动引擎,由4部分组成。
- 解析器:将HQL语句转换为抽象语法树,对抽象语法树进行语法分析,比如表是否存在,字段是否存在,SQL语义是否有误。
- 编译器:将语法树编译为逻辑执行计划。
- 优化器:对逻辑执行计划进行优化。
- 执行器:调用底层的运行框架执行逻辑执行计划。
3)元数据库
Hive的数据由两部分组成:数据文件和元数据。
元数据用于存放Hive的基础信息,它存储在关系型数据库中,如Derby(默认)、MySQL中。
元数据包括:数据库信息、表名、表的列和分区及其属性,表的属性,表的数据所在目录等。
4)Hadoop
Hive是构建在Hadoop之上的。Hive的数据文件存储在HDFS中,大部分查询由MapReduce完成。(简单的查询,就是只是select,不带count,sum,group by这样的,都不走MapReduce,直接读取hdfs文件进行filter过滤。)
2.4 Hive和普通关系数据库的对比
Hive用于海量数据的离线分析,具有sql数据库的外表,但是应用场景完全不同,只适合用于批量数据统计分析。
表1-1 Hive&RDBMS对比
| 类别 | Hive | RDBMS |
|---|---|---|
| 查询语言 | HiveQL | SQL |
| 数据存储位置 | HDFS | 本地FS |
| 数据更新 | 不支持 | 支持 |
| 索引 | 新版本支持,但是支持较弱 | 有 |
| 执行 | MapReduce | Executor |
| 执行延迟 | 高 | 低 |
| 可扩展性 | 高 | 低 |
| 数据规模 | 大 | 小 |
2.5 Hive数据模型
Hive中数据模型主要包括:表(Table)、分区(Partition)和桶(Bucket)。
表 |
表 | 表 | 表 | |||
|---|---|---|---|---|---|---|
| 分区 | 分区 | 分桶 | 分桶 | 分桶 | 分桶 | |
| 分桶 |
1)表(Table)
Hive中的表和数据库中的表在概念上是类似的,每个表在Hive中都有一个对应的存储目录。
例如:
一个名为user的表在HDFS中的存储路径为:/warehouse/user
2)分区(Partition)
Hive中,表中的一个Partition对应于表下的一个目录,所有的Partition的数据都存储在对应的目录中。
例如:
user表中包含dt和city两个Partition:
对应于dt=20211101,city=zhuhai的HDFS子目录为:/warehouse/user/dt=20211101/city=zhuhai;
对应于dt=20211101,city=guangzhou的HDFS子目录为:/warehouse/user/dt=20211101/city=guangzhou;
3)分桶(Bucket)
对指定列计算Hash,根据Hash值切分数据。

若有收获,就点个赞吧
0 人点赞
