一、任务讲解
点击查看【music163】
基于泰坦尼克号乘客数据,做各种任务的分析。
- 创建乘客信息表
- 导入数据到表中
- 统计获救与死亡的分布情况
- 统计舱位分布情况
- 统计港口登船人员分布情况
- 统计存活人数中不同性别的比例
- 统计存活人数中不同客舱等级的比例
undefined.undefined
tidanic.csv
二、数据库定义
2.1 Hive表定义
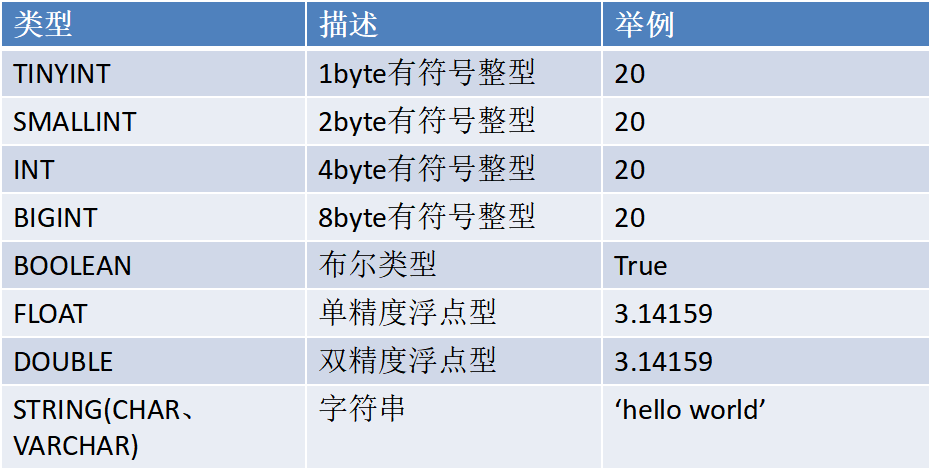
2.2.1 基础数据类型
2.2.2 创建与查看数据库
#启动hivestart-dfs.shservice mysql starthive#查看所有数据库show databases;#创建数据库'test'create database test;#删除数据库'test'drop database test;#查看数据库'test'desc database test;#切换至数据库'test'use test;#设置显示当前数据库set hive.cli.print.current.db=true;
set语句是对参数值进行设定,这种设置只能是在本次会话有效,退出Hive就会失效;想要永久性设置,需要进行以下操作:
cd /usr/local/hive/conf #配置文件所在目录
vim hive-site.xml #修改配置文件
在hive-site.xml后面补充配置信息。
补充的配置信息如下:
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>Whether to print the names of the columns in query output.</description>
</property>
2.2.2 创建表
语法:
[]里面的都是可选项
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
(col_name data_type [COMMENT col_comment], ...)
[PARTITIONED BY (col_name data_type, ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
2.2.2.1 创建内部表
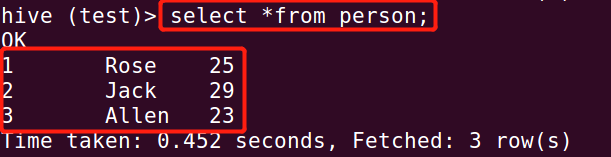
[x] 在test数据库下创建表person:
create table person( id int, name string, age int) row format delimited fields terminated by ',';[x] 插入数据可以通过上传内容到hdfs的方式。(先编辑好文件内容)
cd ~ vim person.txt hdfs dfs -put person.txt /user/hive/warehouse/test.db/person/
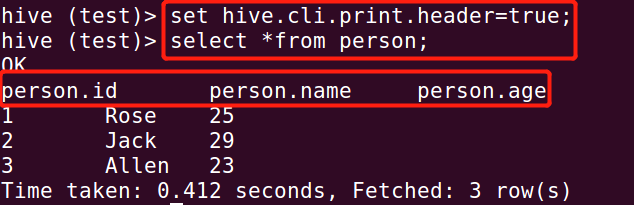
另外,可以通过设置,在查询数据的时候显示字段名称:
set hive.cli.print.header=true;
2.2.2.1 创建外部表
- 创建Hive外部表external_person,指定HDFS的路径为/user/root/external/person
插入数据:create external table external_person( id int, name string, age int) row format delimited fields terminated by ',' location '/user/root/external/external_person';hdfs dfs -put person.txt /user/root/external/external_person/
作业1:内部表和外部表的区别?
2.2.2.1 课堂任务1:创建泰坦尼克乘客信息表
创建一个新的数据库'taitan';
在'taitan'数据库中,创建一个内部表'titanic'。
把tidanic.csv的数据写入到第二步创建的表里。
2.2.2.1 创建静态分区表
- 创建静态分区表tidanic_part,插入tidanic表中的数据,其中字段为:passengerid、survived、pclass、name,分区字段为gender,按照tidanic表中的性别字段sex分区。
插入数据 ```plsql insert overwrite table tidanic_part partition(gender=’female’) select passengerid,survived,pclass,name from tidanic where sex=’female’;create table tidanic_part( passengerid int, survived int, pclass int, name string) partitioned by(gender string) row format delimited fields terminated by ',';
insert overwrite table tidanic_part partition(gender=’male’) select passengerid,survived,pclass,name from tidanic where sex=’male’;
<a name="GTLpy"></a>
#### 2.2.2.1 创建动态分区表
- [x] 创建动态分区表tidanic_dynameic_part,插入tidanic表中的数据,其中字段为:passengerid、survived、name,分区字段为passenderclass,按照tidanic表中的pclass值进行分区
1)创建表
```plsql
create table tidanic_dynameic_part(
passengerid int,
survived int,
name string)
partitioned by(passenderclass string)
row format delimited fields terminated by ',';
2)修改设置
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nostrict;
3)插入数据
insert overwrite table tidanic_dynameic_part partition(passenderclass) select passengerid,survived,name,pclass from tidanic;
2.2 Hive导入及导出数据
- 通过HDFS直接导入导出(前面章节已讲)
- 通过Hive命令导入导出
2.2.1 导入文件数据
语法: ```plsql LOAD DATA [LOCAL] INPATH ‘filepath’ [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 …)]
LOCAL:导入语句带有LOCAL,说明是导入Linux本地的数据,若是从HDFS上导入数据,则导入语句不加LOCAL;
filepath:数据的路径
OVERWRITE:指定覆盖表之前的数据,如果是追加,则去掉OVERWRITE关键字即可。
PARTITON:如果是分区表,指定分区字段的名称。
<a name="iJ6Tb"></a>
### 2.2.2 课堂任务2:用hive命令导入数据到泰坦尼克乘客表中
先把任务1上传到hdfs上的文件删除:
```plsql
hdfs dfs -rm /user/hive/warehouse/taitan.db/tidanic/tidanic.csv
用hive命令导入数据本地数据:
load data local inpath '/home/hadoop/tidanic.csv' into table tidanic;
练习:用hive命令,把hdfs的数据上传至tidanic表中
2.2.2 导入表数据
单表插入语法:
INSERT OVERITE|INTO table 表1
[PARTITION(part1=val1,part2=val2)] SELECT字段1, 字段2, 字段3 FROM 表2 ;
- 查询tidanic的10条数据到tidanic_10 ```plsql create table tidanic_10 like tidanic;
insert into tidanic_10 select * from tidanic limit 10;
多表插入语法
```plsql
FROM 表1
INSERT INTO TABLE 表2 SELECT 字段 LIMIT N
INSERT INTO TABLE 表3 SELECT 字段 WHERE … ;
- 查询tidanic表中的存活乘客数据到tidanic_save
- 查询tidanic表中的死亡乘客数据到tidanic_died ```plsql create table tidanic_save like tidanic; create table tidanic_died like tidanic;
from tidanic insert into tidanic_save select where survived=1 insert into tidanic_died select where survived=0;
<a name="TDCYc"></a>
### 2.2.2 导出表数据
语法:
```plsql
INSERT OVERWRITE [LOCAL] DIRECTORY '路径’
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',’
SELECT 字段1, 字段2, 字段3 FROM 表名 ;
#如果添加LOCAL关键字,那么导出的是本地目录,如果没有该关键字,那么导出的是HDFS目录;
#ROW FORMAT DELIMITED FIELDS TERMINATED BY ','在这里指定导出数据的分隔符为‘,’。
#OVERWRITE LOCAL DIRECTORY 查询结果将覆盖本地目录
- 导出死亡名单到Linux本地,字段之间用”:”分割。
insert overwrite local directory '/home/hadoop/tidanic_save' row format delimited fields terminated by ':' select *from tidanic_save;2.3 Hive查询
2.3.1 数据准备
现有三张表dept、salgrade、emp表,基于这些数据实现相关查询,完成语法的学习。

- 在’test’数据库中,创建dept、salgrade、emp表,并且分别导入对应的txt数据。
select 语法
SELECT [ALL|DISTINCT] 字段列表(字段1 别名,....)
FROM 表1 别名, 表2 别名, ....
WHERE 条件 ….
GROUP BY 分组字段 HAVING(组约束条件)
ORDER BY 排序字段1 Asc | Desc, 字段2 Asc|Desc, .....
[CLUSTER BY 字段 | [DISTRIBUTE BY字段] [SORT BY字段]]
LIMIT M,N;
2.3.2 distinct
- 查询emp中所有的部门编号
- 查询emp中所有部门编号+职位信息的组合
select distinct deptno from emp;
select distinct deptno,job from emp;
2.3.3 order by
- 将部门编号不为10的所有员工按员工编号升序排列,并列出员工编号、员工姓名、部门编号的信息。
- 将所有员工按部门编号升序,当部门一样时,再按姓名降序排序。
select empno,ename,deptno from emp where deptno <> 10 order by empno asc; select empno,ename,deptno from emp order by deptno asc,ename desc;
2.3.4 内置函数
例如:min、max、count、avg、round等
- 查看emp表中平均薪水是多少并对其四舍五入保留两位小数显示
[x] 统计emp表中有多少个不重复部门
select round(avg(sal),2) from emp; select count(distinct deptno) from emp;[x] 查询emp表平均薪水大于2000的部门编号、平均薪水 ```plsql
group by …having 分组查询
select deptno,avg(sal) as avg_sal from emp group by deptno having avg(sal)>2000;
<a name="cbZ76"></a>
### 2.3.5 join连接查询
---
- join:对左表和右边都存在的记录进行关联。
- left join/left outer join:左边表的所有记录连接结果会被返回,右边表没有符合on条件的,连接的右边的列为Null
- right join/right outer join:右边表的所有记录连接结果会被返回,左边表没有符合on条件的,连接的左边的列为Null
---
- [x] 查询emp表薪水大于2500的员工姓名及所在部门名称
```plsql
select ename,dname from emp join dept on emp.deptno = dept.deptno where emp.sal > 2500;
2.3.6 子查询
- 在emp表中,工资最高的员工姓名、薪水
- 在emp表中,工资高于平均工资员工姓名、薪水 ```plsql select ename,sal from emp where sal = (select max(sal) from emp); select ename,sal from emp,(select max(sal) max_sal from emp) b where emp.sal = b.max_sal;
select ename,sal from emp where sal > (select max(sal) from emp); select ename,sal from emp,(select avg(sal) avg_sal from emp) b where emp.sal > b.avg_sal;
<a name="nByni"></a>
### 2.3.7 case when...then..
- [x] 查询emp表中的员工姓名,薪水,如果薪水小于2000标记为low,如果薪水在2000和5000之间标记为middle,如果薪水大于5000标记为high
```plsql
select ename,sal,case when sal < 2000 then 'low' when sal between 2000 and 5000 then 'middle' else 'high' end as label from emp;
课堂任务3:泰坦尼克号存活率统计
- 统计存活人数中不同性别的比例
- 统计存活人数中不同客舱等级的比例 ```plsql select sex,s_count/allcount as s_percent from (select sex,count(distinct passengerid) as s_count from tidanic where survived=1 group by sex) a left join (select count(distinct passengerid) as allcount from tidanic where survived=1)b on 1=1;
暴力解决: select sex,a.s_count/b.allcount as s_percent from (select sex,count(distinct passengerid) as s_count from tidanic where survived=1 group by sex)a,(select count(distinct passengerid) as allcount from tidanic where survived=1)b;
select pclass,p_count/allcount as p_percent from (select pclass,count() as p_count from tidanic where survived=1 group by pclass) a left join (select count() as allcount from tidanic where survived=1)b on 1=1;
`<br />`
<a name="nRZyl"></a>
### 2.3.8 开窗函数
语法:
分析函数(sum(),max(),min(),排序函数…)+窗口子句(over函数)
over函数(指定分析函数的数据窗口大小)
over()内部参数: 1.partiton by col_name 2.order by col_name asc|desc 3.rows between 窗口子句 and 窗口子句
group by 聚合函数每组只有一条记录,而开窗函数则可以为原数据的每行都返回一个值
```plsql
select sex,count(distinct passengerid) over() from tidanic where survived=1;
select sex,count(distinct passengerid) over(partition by sex) from tidanic where survived=1;
select distinct sex,count(distinct passengerid) over(partition by sex)/count(distinct passengerid) over() from tidanic where survived=1;
窗口子句:
| preceding | 往前 (n preceding 从当前行向前n行) |
|---|---|
| following | 往后 (n following 从当前行向后n行) |
| current row | 当前行 |
| unbounded preceding | 第一行 |
| unbounded flollowing | 最后一行 |
对年龄累计求和,对每一行计算从第一行到当前行的累计年龄
insert overwrite table tidanic_10 select * from tidanic where age is not null limit 10;
select passengerid,age From tidanic_10 order by passengerid;
select passengerid,age,sum(age) over(rows between unbounded preceding and current row) From tidanic_10 order by passengerid;
对年龄累计求和,对每一行计算当前行的前一行到当前行的累计年龄
select passengerid,age,sum(age) over(rows between 1 preceding and current row) From tidanic_10 order by passengerid;
对年龄累计求和,对每一行计算前后三行的累计年龄
select passengerid,age,sum(age) over (rows between 1 preceding and 1 following) from tidanic_10;
排序函数
| row_number() | 从1开始,按照顺序,生成分组内记录的序列 |
|---|---|
| rank() | 生成数据项在分组中的排名,排名相等会在名次中留下空位 |
| dense_rank() | 生成数据项在分组中的排名,排名相等不会在名次中留下空位 |
对于乘客数据,按照年龄降序排序标号。
select passengerid,age,row_number() over(order by age desc) from tidanic_10;
select age,rank() over(order by age desc) from tidanic_10;
select age,dense_rank() over(order by age desc) from tidanic_10;
课堂练习任务4:开窗函数的应用
数据:
| 月份 | 销售额(万) |
|---|---|
| 1 | 20 |
| 2 | 10 |
| 3 | 25 |
| 4 | 30 |
| 5 | 30 |
| 6 | 35 |
| 7 | 30 |
| 8 | 25 |
| 9 | 25 |
| 10 | 30 |
| 11 | 40 |
| 12 | 30 |
创建sale表,完成下列任务:
- 统计截止到每个月的累计销售额
- 统计当月以及前后两个月(共计3个月)的平均销售额
- 对销售额进行排序标号,销量越大序号越大

若有收获,就点个赞吧
0 人点赞
