1.在IDEA里面新建maven工程
2..在IDEA中编写
package com.ligong.helloimport org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object WordCount {def main(args: Array[String]): Unit = {if(args.length < 2){println("请指定input和output路径");System.exit(1)}//1.准备spark上下文val conf: SparkConf = new SparkConf().setAppName("WordCount")val sc: SparkContext = new SparkContext(conf);//2.读取文件生成RDDval lines: RDD[String] = sc.textFile("")//3.调用transformation算子进行RDD转换val words: RDD[String] = lines.flatMap(_.split(args(0)))//4.将RDD转化为键值对val wordAndOnes: RDD[ (String,Int) ] = words.map((_,1))//5.聚合操作val result: RDD[(String, Int)] = wordAndOnes.reduceByKey(_+_)System.setProperty("HADOOP_USER_NAME","root")result.repartition(1).saveAsTextFile(args(1))sc.stop()}}
3.打包成jar包
4.上传到 /export/spark-jar/ 
5.赋予权限:
chmod -R 777 wc.jar
6.提交运行:
spark-submit \--master yarn \--deploy-mode cluster \--driver-memory 512m \--executor-memory 512m \--num-executors 1 \--class com.ligong.hello.WordCount \/export/spark-jar/wc.jar \hdfs://node1:8020/wordcount/input/words.txt \hdfs://node1:8020/wordcount/output
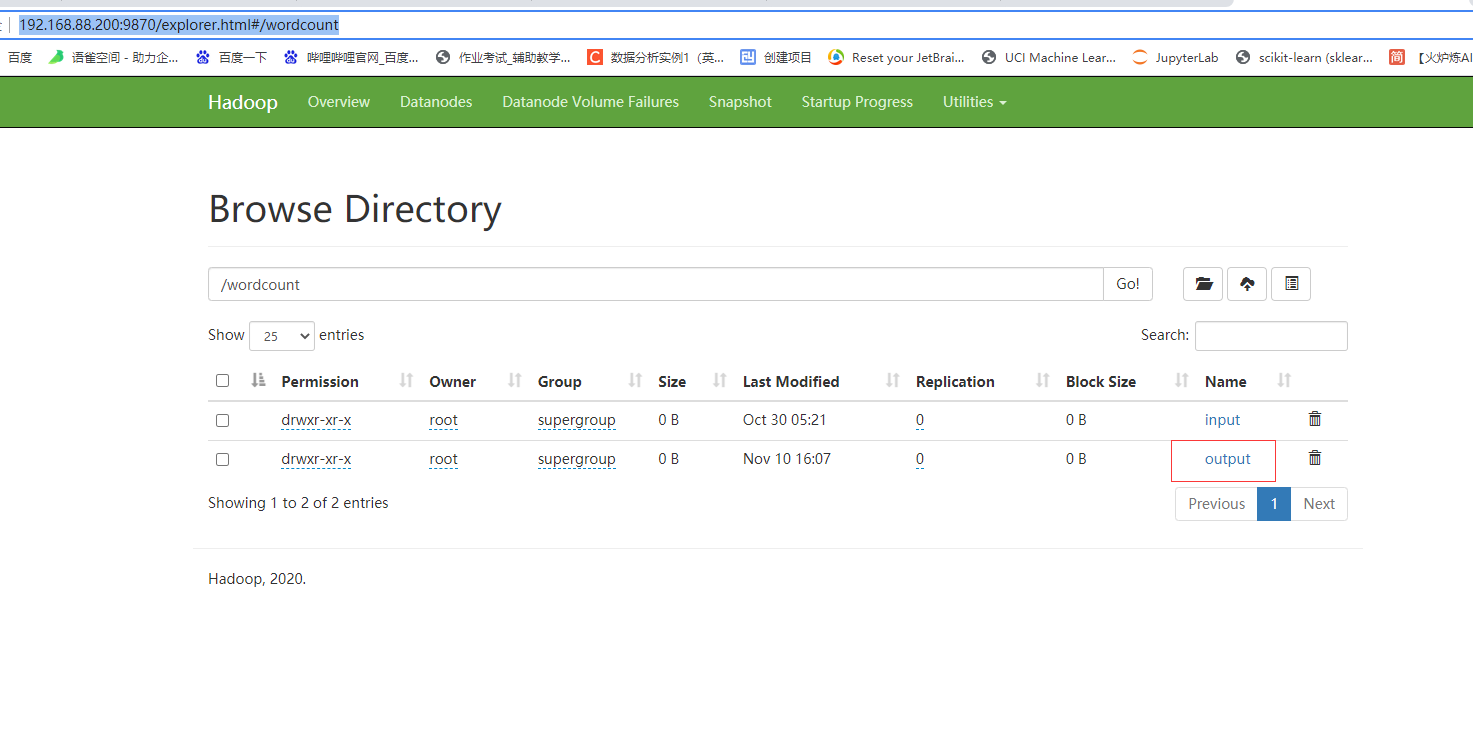
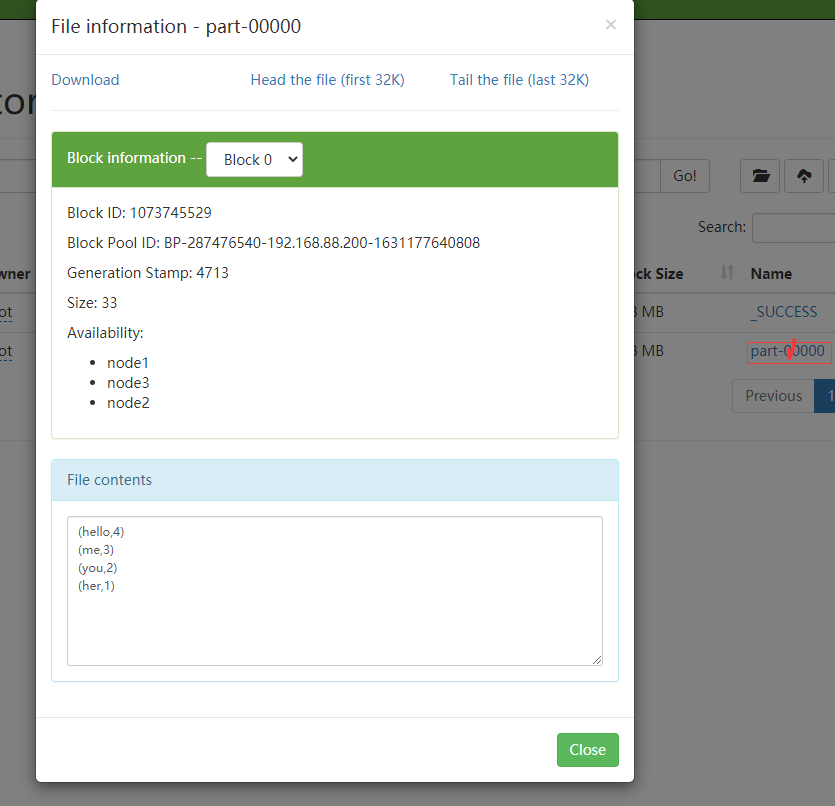
7.

若有收获,就点个赞吧
0 人点赞
