- 数据格式
- 基本操作
- JavaAPI整合
- 对文档进行操作
- 高级操作
- Elasticsearch环境
- 节点 1 的配置信息:
- 集群名称,节点之间要保持一致
- 节点名称,集群内要唯一
- ip 地址
- http 端口
- tcp 监听端口
- discovery.seed_hosts: [“localhost:9301”, “localhost:9302”,”localhost:9303”]
- discovery.zen.fd.ping_timeout: 1m
- discovery.zen.fd.ping_retries: 5
- 集群内的可以被选为主节点的节点列表
- cluster.initial_master_nodes: [“node-1”, “node-2”,”node-3”]
- 跨域配置
- action.destructive_requires_name: true
- 节点 2 的配置信息:
- 集群名称,节点之间要保持一致
- 节点名称,集群内要唯一
- ip 地址
- http 端口
- tcp 监听端口
- 集群内的可以被选为主节点的节点列表
- cluster.initial_master_nodes: [“node-1”, “node-2”,”node-3”]
- 跨域配置
- action.destructive_requires_name: true
- 节点 3 的配置信息:
- 集群名称,节点之间要保持一致
- 节点名称,集群内要唯一
- ip 地址
- http 端口
- tcp 监听端口
- 候选主节点的地址,在开启服务后可以被选为主节点
- 集群内的可以被选为主节点的节点列表
- cluster.initial_master_nodes: [“node-1”, “node-2”,”node-3”]
- 跨域配置
- action.destructive_requires_name: true
- Elasticsearch进阶
- Kibaba
1-尚硅谷项目课程系列之Elasticsearch.pdf
官方地址
elasticsearch在服务器安装
其他错误
配置完毕后需要在服务器开启9200端口并重启防火墙
安装后的目录结构如下
| 目录 | 含义 |
|---|---|
| bin | 可执行脚本目录 |
| config | 配置目录 |
| jdk | 内置JDK目录 |
| lib | 类库 |
| logs | 日志目录 |
| modules | 模块目录 |
| plugins | 插件目录 |
解压后,进入 bin 文件目录,点击 elasticsearch.bat 文件启动 ES 服务 注意:9300 端口为 Elasticsearch 集群间组件的通信端口,9200 端口为浏览器访问的 http协议 RESTful 端口。
REST 指的是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是 RESTful。Web 应用程序最重要的 REST 原则是,客户端和服务器之间的交互在请求之间是无状态的。从客户端到服务器的每个请求都必须包含理解请求所必需的信息。如果服务器在请求之间的任何时间点重启,客户端不会得到通知。此外,无状态请求可以由任何可用服务器回答,这十分适合云计算之类的环境。客户端可以缓存数据以改进性能。 在服务器端,应用程序状态和功能可以分为各种资源。资源是一个有趣的概念实体,它向客户端公开。资源的例子有:应用程序对象、数据库记录、算法等等。每个资源都使用 URI(Universal Resource Identifier) 得到一个唯一的地址。所有资源都共享统一的接口,以便在客户端和服务器之间传输状态。使用的是标准的 HTTP 方法,比如 GET、PUT、POST 和 DELETE。 在 REST 样式的 Web 服务中,每个资源都有一个地址。资源本身都是方法调用的目标,方法列表对所有资源都是一样的。这些方法都是标准方法,包括 HTTP GET、POST、PUT、DELETE,还可能包括 HEAD 和 OPTIONS。简单的理解就是,如果想要访问互联网上的资源,就必须向资源所在的服务器发出请求,请求体中必须包含资源的网络路径,以及对资源进行的操作(增删改查)
数据格式
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。为了方便大家理解, 我们将 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比ES 里的 Index 可以看做一个库,而 Types 相当于表,Documents 则相当于表的行。这里 Types 的概念已经被逐渐弱化,Elasticsearch 6.X 中,一个 index 下已经只能包含一个type,Elasticsearch 7.X 中, Type 的概念已经被删除了。
基本操作
索引操作
创建索引
创建索引:向 ES 服务器发 PUT 请求 :http://127.0.0.1:9200/shopping
{"acknowledged"【响应结果】: true, # true 操作成功"shards_acknowledged"【分片结果】: true, # 分片操作成功"index"【索引名称】: "shopping"}# 注意:创建索引库的分片数默认 1 片,在 7.0.0 之前的 Elasticsearch 版本中,默认 5 片
查看所有索引
查看所有索引:向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/_cat/indices?v
这里请求路径中的_cat 表示查看的意思,indices 表示索引,所以整体含义就是查看当前 ES 服务器中的所有索引,就好像 MySQL 中的 show tables 的感觉。
| 表头 | 含义 |
|---|---|
| health | 当前服务器的健康状态 green(集群完整)、 yellow(单点正常、集群不完整)、red(单点不正常) |
| status | 索引打开、关闭状态 |
| index | 索引名 |
| uuid | 索引统一编号 |
| pri | 主分片数量 |
| rep | 副本数量 |
| docs.count | 可用文档数量 |
| docs.deleted | 文档删除状态(逻辑删除) |
| store.size | 主分片和副分片整体占空间大小 |
| pri.store.size | 主分片占空间大小 |
查看单个索引
查看单个索引:向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/shopping
{
"shopping"【索引名】: {
"aliases"【别名】: {},
"mappings"【映射】: {},
"settings"【设置】: {
"index"【设置 - 索引】: {
"creation_date"【设置 - 索引 - 创建时间】: "1614265373911",
"number_of_shards"【设置 - 索引 - 主分片数量】: "1",
"number_of_replicas"【设置 - 索引 - 副分片数量】: "1",
"uuid"【设置 - 索引 - 唯一标识】: "eI5wemRERTumxGCc1bAk2A",
"version"【设置 - 索引 - 版本】: {
"created": "7080099"
},
"provided_name"【设置 - 索引 - 名称】: "shopping"
}
}
}
}
删除索引
删除索引:向 ES 服务器发 DELETE 请求 :http://127.0.0.1:9200/shopping
文档操作
创建文档
创建文档:向 ES 服务器发 POST 请求 :http://127.0.0.1:9200/shopping**/_doc**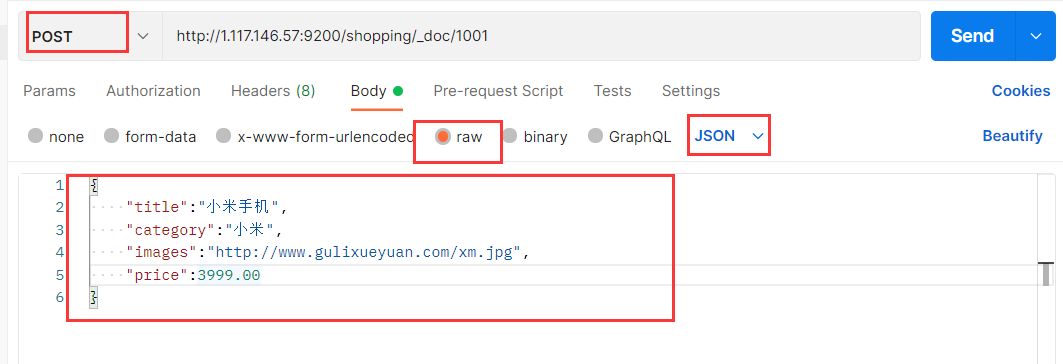
索引已经创建好了,接下来我们来创建文档,并添加数据。这里的文档可以类比为关系型数据库中的表数据,添加的数据格式为 JSON 格式.此处发送请求的方式必须为 POST,不能是 PUT,否则会发生错误
响应结果如下
{
"_index"【索引】: "shopping",
"_type"【类型-文档】: "_doc",
"_id"【唯一标识】: "1001", #可以类比为 MySQL 中的主键,随机生成,或者可以自己指定
"_version"【版本】: 1,
"result"【结果】: "created", #这里的 create 表示创建成功
"_shards"【分片】: {
"total"【分片 - 总数】: 2,
"successful"【分片 - 成功】: 1,
"failed"【分片 - 失败】: 0
},
"_seq_no": 0,
"_primary_term": 1
}
查看文档
查看文档单条:向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/shopping**/_doc/1001**
查看文档全部:向 ES 服务器发 GET 请求:http://1.117.146.57:9200/shopping/_search
根据字段进行查询:向 ES 服务器发 GET 请求 http://1.117.146.57:9200/shopping/_search?q=category:小米
在请求体中增加查询:向 ES 服务器发 GET 请求:http://1.117.146.57:9200/shopping/_search,同时添加请求体
查询全部数据
{
"query" :{
"match_all":{
}
}
}
分页查询,每页两条,只显示title属性,根据价格降序排序
{
"query" :{
"match_all":{
}
},
"from":0,
"size":2,
"_source":["title"],
"sort":{
"price":{
"order":"desc"
}
}
}
对条件查询、范围查询:向 ES 服务器发 GET 请求:http://1.117.146.57:9200/shopping/_search,同时添加请求体
直接使用match进行匹配时,es底层会进行分词,把匹配到的都查出来
可以使用match_parse精准匹配
{
"query": {
"bool": {
"should":[
{
"match": {
"category": "小米"
}
},
{
"match": {
"category": "华为"
}
}
],
"filter": {
"range": {
"price": {
"lt": 5000
}
}
}
}
}
}
聚合查询
{
"aggs": { //聚合操作
"price_group": { //名称,随意起名
"terms": { //分组,avg为平均值
"field": "price" //分组字段
}
}
},
"size": 0
}
{
"_index"【索引】: "shopping",
"_type"【文档类型】: "_doc",
"_id": "1001",
"_version": 2,
"_seq_no": 2,
"_primary_term": 2,
"found"【查询结果】: true, # true 表示查找到,false 表示未查找到
"_source"【文档源信息】: {
"title": "华为手机",
"category": "华为",
"images": "http://www.gulixueyuan.com/hw.jpg",
"price": 4999.00
}
}
修改文档
修改文档:向 ES 服务器发 POST 请求 :http://127.0.0.1:9200/shopping**/_doc/1001**
响应结果
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_version"【版本】: 2,
"result"【结果】: "updated", # updated 表示数据被更新
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 2
}
修改字段
修改字段:向 ES 服务器发 POST 请求 :http://127.0.0.1:9200/shopping/**_update/1001**
修改数据时,也可以只修改某一给条数据的局部信息
删除文档
删除文档:向 ES 服务器发 DELETE 请求 :http://127.0.0.1:9200/shopping**/_doc/1001**
删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)。
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_version"【版本】: 4, #对数据的操作,都会更新版本
"result"【结果】: "deleted", # deleted 表示数据被标记为删除
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 4,
"_primary_term": 2
}
条件删除文档
条件删除文档:向 ES 服务器发 POST 请求 :http://127.0.0.1:9200/shopping**/_delete_by_query**
一般删除数据都是根据文档的唯一性标识进行删除,实际操作时,也可以根据条件对多条数据进行删除
{
"query":{
"match":{
"price":4000.00
}
}
}
映射操作
有了索引库,等于有了数据库中的 database。接下来就需要建索引库(index)中的映射了,类似于数据库(database)中的表结构(table)。 创建数据库表需要设置字段名称,类型,长度,约束等;索引库也一样,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做映射(mapping)。如果自己创建文档,会自动生成映射。
创建映射
创建映射:向 ES 服务器发 PUT 请求 :http://127.0.0.1:9200/user**/_mapping**
请求体内容为
{
"properties": {
"name": {
"type": "text",
"index": true
},
"sex": {
"type": "keyword",//不能被分词
"index": true //可以被作为索引
},
"tel": {
"type": "keyword",
"index": false
}
}
}
插入数据:PUT请求 http://1.117.146.57:9200/user/_create/1001
{
"name": "小米",
"sex": "男生",
"tel": "111"
}
映射数据说明:
- 字段名:任意填写,下面指定许多属性,例如:title、subtitle、images、price
- type:类型,Elasticsearch 中支持的数据类型非常丰富,说几个关键的:
- String 类型,又分两种:
- text:可分词
- keyword:不可分词,数据会作为完整字段进行匹配
- Numerical:数值类型,分两类
- 基本数据类型:long、integer、short、byte、double、float、half_float
- 浮点数的高精度类型:scaled_float
- Date:日期类型
- Array:数组类型
- Object:对象
- String 类型,又分两种:
- index:是否索引,默认为 true,也就是说你不进行任何配置,所有字段都会被索引。
- true:字段会被索引,则可以用来进行搜索
- false:字段不会被索引,不能用来搜索
- store:是否将数据进行独立存储,默认为 false
- 原始的文本会存储在_source 里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source 里面提取出来的。当然你也可以独立的存储某个字段,只要设置”store”: true 即可,获取独立存储的字段要比从_source 中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置。
analyzer:分词器,这里的 ik_max_word 即使用 ik 分词器,后面会有专门的章节学习
查看映射
查看映射:向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/user**/_mapping**
索引映射关联
索引映射关联:向 ES 服务器发 PUT 请求 :http://127.0.0.1:9200/user
JavaAPI整合
导入依赖 ```json
org.elasticsearch elasticsearch 7.8.0 org.elasticsearch.client elasticsearch-rest-high-level-client 7.8.0 org.apache.logging.log4j log4j-api 2.8.2 org.apache.logging.log4j log4j-core 2.8.2 com.fasterxml.jackson.core jackson-databind 2.9.9 junit junit 4.12
<a name="kSvMZ"></a>
## 对索引进行操作
**导入模块**
```java
import org.apache.http.HttpHost;
import org.elasticsearch.action.admin.indices.create.CreateIndexRequest;
import org.elasticsearch.action.admin.indices.create.CreateIndexResponse;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.client.indices.GetIndexResponse;
import org.junit.Test;
import java.io.IOException;
public class ES_Test {
}
创建索引
@Test //创建索引
public void create() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("1.117.146.57", 9200, "http"))
);
// 创建索引 - 请求对象
CreateIndexRequest request = new CreateIndexRequest("user1");
// 发送请求,获取响应
CreateIndexResponse response = client.indices().create(request,
RequestOptions.DEFAULT);
boolean acknowledged = response.isAcknowledged();
// 响应状态
System.out.println("操作状态 = " + acknowledged);
// 关闭客户端连接
client.close();
}
查询索引
@Test //查询索引
public void select() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("1.117.146.57", 9200, "http"))
);
// 查询索引 - 请求对象
GetIndexRequest request = new GetIndexRequest("user");
// 发送请求,获取响应
GetIndexResponse response = client.indices().get(request,RequestOptions.DEFAULT);
System.out.println("aliases:"+response.getAliases()); //别名
System.out.println("mappings:"+response.getMappings()); //映射信息
System.out.println("settings:"+response.getSettings()); //设置
}
删除索引
@Test //删除索引
public void delete() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("1.117.146.57", 9200, "http"))
);
// 删除索引 - 请求对象
DeleteIndexRequest request = new DeleteIndexRequest("user1");
// 发送请求,获取响应
AcknowledgedResponse response = client.indices().delete(request,RequestOptions.DEFAULT);
// 操作结果
System.out.println("操作结果 : " + response.isAcknowledged());
}
对文档进行操作
导入模块
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.http.HttpHost;
import org.elasticsearch.action.admin.indices.create.CreateIndexRequest;
import org.elasticsearch.action.admin.indices.create.CreateIndexResponse;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.Test;
import java.io.IOException;
public class ES_doc {
}
插入数据
@Test //插入数据
public void Insert() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("1.117.146.57", 9200, "http")));
// 新增文档 - 请求对象
IndexRequest request = new IndexRequest();
// 设置索引及唯一性标识
request.index("user").id("1001");
// 创建数据对象
User user = new User("zhangsan","男",20);
ObjectMapper objectMapper = new ObjectMapper();
String productJson = objectMapper.writeValueAsString(user);
// 添加文档数据,数据格式为 JSON 格式
request.source(productJson, XContentType.JSON);
// 客户端发送请求,获取响应对象
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
//3.打印结果信息
System.out.println("_index:" + response.getIndex());
System.out.println("_id:" + response.getId());
System.out.println("_result:" + response.getResult());
// 关闭客户端连接
client.close();
}
查询数据
@Test //查询数据
public void select() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("1.117.146.57", 9200, "http")));
//1.创建请求对象
GetRequest request = new GetRequest().index("user").id("1002");
//2.客户端发送请求,获取响应对象
GetResponse response = client.get(request, RequestOptions.DEFAULT);
//3.打印结果信息
System.out.println("_index:" + response.getIndex());
System.out.println("_type:" + response.getType());
System.out.println("_id:" + response.getId());
System.out.println("source:" + response.getSourceAsString());
// 关闭客户端连接
client.close();
}
修改数据
@Test //修改数据
public void update() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("1.117.146.57", 9200, "http")));
UpdateRequest request = new UpdateRequest();
// 配置修改参数
request.index("user").id("1001");
// 设置请求体,对数据进行修改
request.doc(XContentType.JSON, "sex", "女");
// 客户端发送请求,获取响应对象
UpdateResponse response = client.update(request, RequestOptions.DEFAULT);
System.out.println("_index:" + response.getIndex());
System.out.println("_id:" + response.getId());
System.out.println("_result:" + response.getResult());
// 关闭客户端连接
client.close();
}
删除数据
@Test //删除数据
public void delete() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("1.117.146.57", 9200, "http")));
//创建请求对象
DeleteRequest request = new DeleteRequest().index("user").id("1001");
//客户端发送请求,获取响应对象
DeleteResponse response = client.delete(request, RequestOptions.DEFAULT);
//打印信息
System.out.println(response.toString());
// 关闭客户端连接
client.close();
}
批量插入
/////////////////////批量操作/////////////////////////////
@Test //批量新增
public void banchInsert() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("1.117.146.57", 9200, "http")));
//创建批量新增请求对象
BulkRequest request = new BulkRequest();
request.add(new IndexRequest().index("user").id("1001").source(XContentType.JSON, "name","zhangsan","age",18));
request.add(new IndexRequest().index("user").id("1002").source(XContentType.JSON, "name","lisi","sex","女"));
request.add(new IndexRequest().index("user").id("1003").source(XContentType.JSON, "name","wangwu"));
//客户端发送请求,获取响应对象
BulkResponse responses = client.bulk(request, RequestOptions.DEFAULT);
//打印结果信息
System.out.println("took:" + responses.getTook());
System.out.println("items:" + responses.getItems());
// 关闭客户端连接
client.close();
}
批量删除
@Test //批量删除
public void banchDelete() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("1.117.146.57", 9200, "http")));
//创建批量删除请求对象
BulkRequest request = new BulkRequest();
request.add(new DeleteRequest().index("user").id("1001"));
request.add(new DeleteRequest().index("user").id("1002"));
request.add(new DeleteRequest().index("user").id("1003"));
//客户端发送请求,获取响应对象
BulkResponse responses = client.bulk(request, RequestOptions.DEFAULT);
//打印结果信息
System.out.println("took:" + responses.getTook());
System.out.println("items:" + responses.getItems());
// 关闭客户端连接
client.close();
}
高级操作
导入模块
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.unit.Fuzziness;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.RangeQueryBuilder;
import org.elasticsearch.index.query.TermsQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.SortOrder;
import org.junit.Test;
import java.io.IOException;
import java.util.Map;
public class ES_Senior {
}
查询所有数据
@Test //查询所有
public void select() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("1.117.146.57", 9200, "http")));
// 创建搜索请求对象
SearchRequest request = new SearchRequest();
request.indices("user");
// 构建查询的请求体
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 查询所有数据
sourceBuilder.query(QueryBuilders.matchAllQuery());
//加入请求体
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 查询匹配
SearchHits hits = response.getHits();
System.out.println("took:" + response.getTook());
System.out.println("timeout:" + response.isTimedOut());
System.out.println("total:" + hits.getTotalHits());
System.out.println("MaxScore:" + hits.getMaxScore());
System.out.println("hits========>>");
for (SearchHit hit : hits) {
//输出每条查询的结果信息
System.out.println(hit.getSourceAsString());
}
System.out.println("<<========");
}
关键字查询
@Test //关键字查询
public void term() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("1.117.146.57", 9200, "http")));
// 创建搜索请求对象
SearchRequest request = new SearchRequest();
request.indices("user");
// 构建查询的请求体
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.termQuery("age", "18"));
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 查询匹配
SearchHits hits = response.getHits();
System.out.println("took:" + response.getTook());
System.out.println("timeout:" + response.isTimedOut());
System.out.println("total:" + hits.getTotalHits());
System.out.println("MaxScore:" + hits.getMaxScore());
System.out.println("hits========>>");
for (SearchHit hit : hits) {
//输出每条查询的结果信息
System.out.println(hit.getSourceAsString());
}
System.out.println("<<========");
}
分页查询
@Test //分页查询
public void page() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("1.117.146.57", 9200, "http")));
// 创建搜索请求对象
SearchRequest request = new SearchRequest();
request.indices("user");
// 构建查询的请求体
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.matchAllQuery());
// 分页查询
// 当前页其实索引(第一条数据的顺序号),from
sourceBuilder.from(0);
// 每页显示多少条 size
sourceBuilder.size(2);
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 查询匹配
SearchHits hits = response.getHits();
System.out.println("took:" + response.getTook());
System.out.println("timeout:" + response.isTimedOut());
System.out.println("total:" + hits.getTotalHits());
System.out.println("MaxScore:" + hits.getMaxScore());
System.out.println("hits========>>");
for (SearchHit hit : hits) {
//输出每条查询的结果信息
System.out.println(hit.getSourceAsString());
}
System.out.println("<<========");
}
查询排序
@Test //查询排序
public void sort() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("1.117.146.57", 9200, "http")));
// 构建查询的请求体
SearchRequest request= new SearchRequest();
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.matchAllQuery());
// 排序
sourceBuilder.sort("age", SortOrder.ASC);
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 查询匹配
SearchHits hits = response.getHits();
System.out.println("took:" + response.getTook());
System.out.println("timeout:" + response.isTimedOut());
System.out.println("total:" + hits.getTotalHits());
System.out.println("MaxScore:" + hits.getMaxScore());
System.out.println("hits========>>");
for (SearchHit hit : hits) {
//输出每条查询的结果信息
System.out.println(hit.getSourceAsString());
}
System.out.println("<<========");
}
字段过滤
@Test //字段过滤
public void filter() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("1.117.146.57", 9200, "http")));
// 创建搜索请求对象
SearchRequest request = new SearchRequest();
request.indices("user");
// 构建查询的请求体
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.matchAllQuery());
//查询字段过滤
String[] excludes = {}; //排除
String[] includes = {"name", "age"}; //包含
sourceBuilder.fetchSource(includes, excludes);
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 查询匹配
SearchHits hits = response.getHits();
System.out.println("took:" + response.getTook());
System.out.println("timeout:" + response.isTimedOut());
System.out.println("total:" + hits.getTotalHits());
System.out.println("MaxScore:" + hits.getMaxScore());
System.out.println("hits========>>");
for (SearchHit hit : hits) {
//输出每条查询的结果信息
System.out.println(hit.getSourceAsString());
}
System.out.println("<<========");
}
布尔查询
@Test //布尔查询
public void bool() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("1.117.146.57", 9200, "http")));
// 创建搜索请求对象
SearchRequest request = new SearchRequest();
request.indices("user");
// 构建查询的请求体
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 必须包含
boolQueryBuilder.must(QueryBuilders.matchQuery("age", "18"));
// 一定不含
boolQueryBuilder.mustNot(QueryBuilders.matchQuery("name", "lisi"));
// 可能包含
boolQueryBuilder.should(QueryBuilders.matchQuery("sex", "男"));
sourceBuilder.query(boolQueryBuilder);
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 查询匹配
SearchHits hits = response.getHits();
System.out.println("took:" + response.getTook());
System.out.println("timeout:" + response.isTimedOut());
System.out.println("total:" + hits.getTotalHits());
System.out.println("MaxScore:" + hits.getMaxScore());
System.out.println("hits========>>");
for (SearchHit hit : hits) {
//输出每条查询的结果信息
System.out.println(hit.getSourceAsString());
}
System.out.println("<<========");
}
区域查询
@Test //区域查询
public void area() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("1.117.146.57", 9200, "http")));
// 创建搜索请求对象
SearchRequest request = new SearchRequest();
request.indices("user");
// 构建查询的请求体
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
RangeQueryBuilder rangeQuery = QueryBuilders.rangeQuery("age");
// 大于等于
rangeQuery.gte("15");
// 小于等于
rangeQuery.lte("40");
sourceBuilder.query(rangeQuery);
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 查询匹配
SearchHits hits = response.getHits();
System.out.println("took:" + response.getTook());
System.out.println("timeout:" + response.isTimedOut());
System.out.println("total:" + hits.getTotalHits());
System.out.println("MaxScore:" + hits.getMaxScore());
System.out.println("hits========>>");
for (SearchHit hit : hits) {
//输出每条查询的结果信息
System.out.println(hit.getSourceAsString());
}
System.out.println("<<========");
}
模糊查询
@Test //模糊查询
public void like() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("1.117.146.57", 9200, "http")));
// 创建搜索请求对象
SearchRequest request = new SearchRequest();
request.indices("user");
// 构建查询的请求体
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.fuzzyQuery("name","zhangsan").fuzziness(Fuzziness.ONE));
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 查询匹配
SearchHits hits = response.getHits();
System.out.println("took:" + response.getTook());
System.out.println("timeout:" + response.isTimedOut());
System.out.println("total:" + hits.getTotalHits());
System.out.println("MaxScore:" + hits.getMaxScore());
System.out.println("hits========>>");
for (SearchHit hit : hits) {
//输出每条查询的结果信息
System.out.println(hit.getSourceAsString());
}
System.out.println("<<========");
}
高亮查询
@Test //高亮查询
public void higtlight() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("1.117.146.57", 9200, "http")));
// 高亮查询
SearchRequest request = new SearchRequest().indices("user");
//2.创建查询请求体构建器
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//构建查询方式:高亮查询
TermsQueryBuilder termsQueryBuilder =QueryBuilders.termsQuery("name","zhangsan");
//设置查询方式
sourceBuilder.query(termsQueryBuilder);
//构建高亮字段
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("<font color='red'>");//设置标签前缀
highlightBuilder.postTags("</font>");//设置标签后缀
highlightBuilder.field("name");//设置高亮字段
//设置高亮构建对象
sourceBuilder.highlighter(highlightBuilder);
//设置请求体
request.source(sourceBuilder);
//3.客户端发送请求,获取响应对象
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.打印响应结果
SearchHits hits = response.getHits();
System.out.println("took::"+response.getTook());
System.out.println("time_out::"+response.isTimedOut());
System.out.println("total::"+hits.getTotalHits());
System.out.println("max_score::"+hits.getMaxScore());
System.out.println("hits::::>>");
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
//打印高亮结果
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
System.out.println(highlightFields);
}
System.out.println("<<::::");
}
聚合查询
@Test //聚合查询
public void arr() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("1.117.146.57", 9200, "http")));
// 高亮查询
SearchRequest request = new SearchRequest().indices("user");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.aggregation(AggregationBuilders.avg("avgAge").field("age")); //查询平均值
//设置请求体
request.source(sourceBuilder);
//3.客户端发送请求,获取响应对象
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.打印响应结果
SearchHits hits = response.getHits();
System.out.println(response);
}
分组统计
@Test //分组统计
public void group() throws IOException {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("1.117.146.57", 9200, "http")));
// 高亮查询
SearchRequest request = new SearchRequest().indices("user");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.aggregation(AggregationBuilders.terms("age_groupby").field("age"));
//设置请求体
request.source(sourceBuilder);
//3.客户端发送请求,获取响应对象
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.打印响应结果
SearchHits hits = response.getHits();
System.out.println(response);
}
Elasticsearch环境
windows部署集群
1. 创建 elasticsearch-cluster 文件夹,在内部复制三个 elasticsearch 服务
2. 修改集群文件目录中每个节点的 config/elasticsearch.yml 配置文件
3. 启动集群
4. 测试集群,发送get请求 http://localhost:1003/_cluster/health
 ```yaml
```yaml######node-1001节点
节点 1 的配置信息:
集群名称,节点之间要保持一致
cluster.name: my-elasticsearch节点名称,集群内要唯一
node.name: node-1001 node.master: true node.data: trueip 地址
network.host: localhosthttp 端口
http.port: 1001tcp 监听端口
transport.tcp.port: 9301discovery.seed_hosts: [“localhost:9301”, “localhost:9302”,”localhost:9303”]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
集群内的可以被选为主节点的节点列表
cluster.initial_master_nodes: [“node-1”, “node-2”,”node-3”]
跨域配置
action.destructive_requires_name: true
http.cors.enabled: true http.cors.allow-origin: “*”
######node-1002节点
节点 2 的配置信息:
集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
节点名称,集群内要唯一
node.name: node-1002 node.master: true node.data: true
ip 地址
尚硅谷技术之 Elasticsearch ————————————————————————————— 更多 Java –大数据 –前端 –python 人工智能资料下载,可百度访问:尚硅谷官网 network.host: localhost
http 端口
http.port: 1002
tcp 监听端口
transport.tcp.port: 9302 discovery.seed_hosts: [“localhost:9301”] discovery.zen.fd.ping_timeout: 1m discovery.zen.fd.ping_retries: 5
集群内的可以被选为主节点的节点列表
cluster.initial_master_nodes: [“node-1”, “node-2”,”node-3”]
跨域配置
action.destructive_requires_name: true
http.cors.enabled: true http.cors.allow-origin: “*”
######node-1002节点
节点 3 的配置信息:
集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
节点名称,集群内要唯一
node.name: node-1003 node.master: true node.data: true
ip 地址
network.host: localhost
http 端口
http.port: 1003
tcp 监听端口
transport.tcp.port: 9303
候选主节点的地址,在开启服务后可以被选为主节点
discovery.seed_hosts: [“localhost:9301”, “localhost:9302”] discovery.zen.fd.ping_timeout: 1m discovery.zen.fd.ping_retries: 5
集群内的可以被选为主节点的节点列表
cluster.initial_master_nodes: [“node-1”, “node-2”,”node-3”]
跨域配置
action.destructive_requires_name: true
http.cors.enabled: true http.cors.allow-origin: “*”
3. ①启动前先删除每个节点中的data目录中的所有内容,②分别双击执行 bin/elasticsearch.bat, 启动节点服务器,启动后,会自动加入指定名称的集群
<a name="DSft2"></a>
## Linux中安装es
```java
1.解压文件夹
tar -zxvf elasticsearch-7.8.0-linux-x86_64.tar.gz -C /opt/module
2.改名
mv elasticsearch-7.8.0 es
3.创建用户,因为安全问题,Elasticsearch 不允许 root 用户直接运行,所以要创建新用户,在 root 用户中创建新用户
useradd es #新增 es 用户
passwd es #为 es 用户设置密码
userdel -r es #如果错了,可以删除再加
chown -R es:es /opt/module/es #文件夹所有者
4. 修改配置文件
修改/opt/module/es/config/elasticsearch.yml 文件
# 加入如下配置
cluster.name: elasticsearch
node.name: node-1
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["node-1"]
修改/etc/security/limits.conf
# 在文件末尾中增加下面内容
# 每个进程可以打开的文件数的限制
es soft nofile 65536
es hard nofile 65536
修改/etc/security/limits.d/20-nproc.conf
# 在文件末尾中增加下面内容
# 每个进程可以打开的文件数的限制
es soft nofile 65536
es hard nofile 65536
# 操作系统级别对每个用户创建的进程数的限制
* hard nproc 4096
# 注:* 带表 Linux 所有用户名称
修改/etc/sysctl.conf
# 在文件中增加下面内容
# 一个进程可以拥有的 VMA(虚拟内存区域)的数量,默认值为 65536
vm.max_map_count=655360
重新加载
sysctl -p
5.启动软件,使用es账户启动
cd /opt/module/es/
#启动
bin/elasticsearch
#后台启动
bin/elasticsearch -d
集群搭建
详见文章顶部的word文件
Elasticsearch进阶
核心概念
索引 Index
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的 索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必 须全部是小写字母),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时 候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。 能搜索的数据必须索引,这样的好处是可以提高查询速度,比如:新华字典前面的目录 就是索引的意思,目录可以提高查询速度。Elasticsearch 索引的精髓:一切设计都是为了提高搜索的性能。
类型 Type
在一个索引中,你可以定义一种或多种类型。 一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具 有一组共同字段的文档定义一个类型。不同的版本,类型发生了不同的变化
| 版本 | Type |
|---|---|
| 5.x | 支持多种type |
| 6.x | 只能有一种type |
| 7.x | 默认不再支持自定义索引类型(默认类型为:_doc) |
文档 Document
一个文档是一个可被索引的基础信息单元,也就是一条数据 。比如:你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以 JSON(Javascript Object Notation)格式来表示,而 JSON 是一个到处存在的互联网数据交互格式。在一个 index/type 里面,你可以存储任意多的文档。
字段 Field
映射 Mapping
mapping 是处理数据的方式和规则方面做一些限制,如:某个字段的数据类型、默认值、 分析器、是否被索引等等。这些都是映射里面可以设置的,其它就是处理 ES 里面数据的一 些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射, 并且需要思考如何建立映射才能对性能更好。
分片 Shards
一个索引可以存储超出单个节点硬件限制的大量数据。比如,一个具有 10 亿文档数据的索引占据 1TB 的磁盘空间,而任一节点都可能没有这样大的磁盘空间。或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch 提供了将索引划分成多份的能力,每一份就称之为分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片很重要,主要有两方面的原因:
1)允许你水平分割 / 扩展你的内容容量。
2)允许你在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合和搜索请求,是完全由 Elasticsearch 管理的,对于作为用户的你来说,这些都是透明的,无需过分关心。 被混淆的概念是,一个 Lucene 索引 我们在 Elasticsearch 称作 分片 。 一个 Elasticsearch 索引 是分片的集合。 当 Elasticsearch 在索引中搜索的时候, 他发送查询
到每一个属于索引的分片(Lucene 索引),然后合并每个分片的结果到一个全局的结果集。
副本 Replicas
在一个网络 / 云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch 允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片(副本)。
复制分片之所以重要,有两个主要原因:
- 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。
- 扩展你的搜索量/吞吐量,因为搜索可以在所有的副本上并行运行。
总之,每个索引可以被分成多个分片。一个索引也可以被复制 0 次(意思是没有复制) 或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。默认情况下,Elasticsearch 中的每个索引被分片 1 个主分片和 1 个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有 1 个主分片和另外 1 个复制分片(1 个完全拷贝),这样的话每个索引总共就有 2 个分片,我们需要根据索引需要确定分片个数。
分配 Allocation
将分片分配给某个节点的过程,包括分配主分片或者副本。如果是副本,还包含从主分片复制数据的过程。这个过程是由 master 节点完成的。
系统架构

一个运行中的 Elasticsearch 实例称为一个节点,而集群是由一个或者多个拥有相同cluster.name 配置的节点组成,它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。 当一个节点被选举成为主节点时, 它将负责管理集群范围内的所有变更,例如增加、 删除索引,或者增加、删除节点等。 而主节点并不需要涉及到文档级别的变更和搜索等操 作,所以当集群只拥有一个主节点的情况下,即使流量的增加它也不会成为瓶颈。 任何节 点都可以成为主节点。我们的示例集群就只有一个节点,所以它同时也成为了主节点。 作为用户,我们可以将请求发送到集群中的任何节点 ,包括主节点。 每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。 无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。 Elasticsearch 对这一切的管理都是透明的。
分布式集群
单节点集群
我们在包含一个空节点的集群内创建名为 users 的索引,为了演示目的,我们将分配 3个主分片和一份副本(每个主分片拥有一个副本分片)
向ES发送Put请求 http://localhost:1003/users
{
"settings" : {
"number_of_shards" : 3, //设置分片数量
"number_of_replicas" : 1 //每一个分片对应副本
}
}
可以修改副本的数量
向ES发送Put请求 http://localhost:1003/users/_settings
{
"number_of_replicas" : 2
}
路由计算
当索引一个文档的时候,文档会被存储到一个主分片中。 Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片1 还是分片 2 中呢?首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了。实际上,这个过程是根据下面这个公式决定的:
routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。 routing 通过hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量后得到余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。这就解释了为什么我们要在创建索引的时候就确定好主分片的数量 并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。所有的文档 API( get 、 index 、 delete 、 bulk 、 update 以及 mget )都接受一个叫做 routing 的路由参数 ,通过这个参数我们可以自定义文档到分片的映射。一个自定义的路由参数可以用来确保所有相关的文档——例如所有属于同一个用户的文档——都被存储到同一个分片中。
Kibaba
Kibana 是一个免费且开放的用户界面,能够让你对 Elasticsearch 数据进行可视化,并让你在 Elastic Stack 中进行导航。你可以进行各种操作,从跟踪查询负载,到理解请求如何流经你的整个应用,都能轻松完成。
下载地址
1. 下载解压后修改配置文件(windows版)
# 默认端口
server.port: 5601
# ES 服务器的地址
elasticsearch.hosts: ["http://localhost:9200"]
# 索引名
kibana.index: ".kibana"
# 支持中文
i18n.locale: "zh-CN"
2. Windows 环境下执行 bin/kibana.bat 文件
3. 通过浏览器访问 : http://localhost:5601

若有收获,就点个赞吧
0 人点赞
