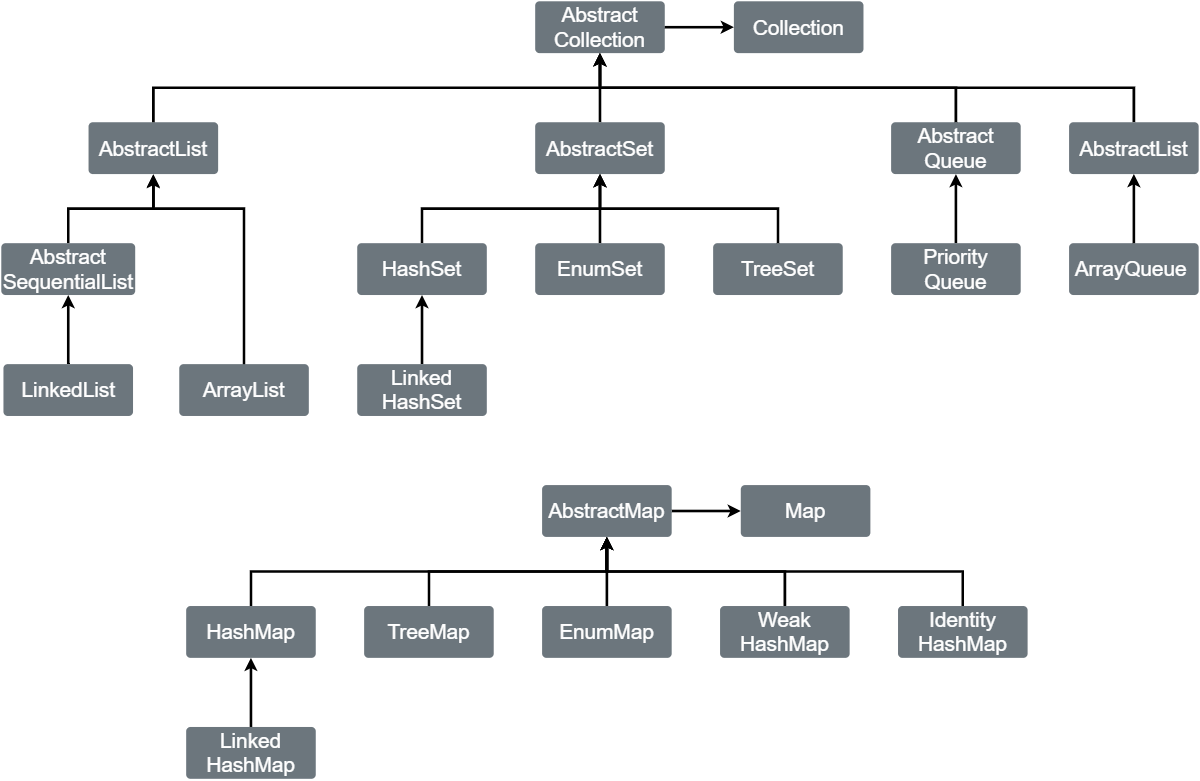
Java 库中的具体集合:
- ArrayList, 可以动态增长和缩减的索引序列
- LinkedList, 可以在任何位置高效的插入和删除操作的有序集合(ordered collection),这里有序指的时记住插入的顺序
- ArrayDeque, 用循环数组实现的双端队列
- HashSet, 没有重复元素的无序集合
- TreeSet, 有序集合(sorted collection),这个有序是指排序有序
- EnumSet, 包含枚举类型值得集
- LikedHashSet, 可以记住插入次序的
Set - PriorityQueue, 搞笑删除最小或最大元素的集合
- HashMap, 存储 Key/Value 关联的数据结构
- TreeMap, Key 有序排列的
Map - EnumMap, Key 为枚举类型的
Map - LinkedHashMap, 可以记住 Key/Value 项添加次序的
Map - WeakHashMap, Key 无用武之地后可以被垃圾回收器回收的
Map - IdentityHashMap, 用
==而不是用equlas比较的Map
链表
在Java程序设计语言中,所有链表实际上都是双向链接的(doubly linked)。
所以在链表的 ListIterator 中有两个方法用来反向遍历链表:
E previous();boolean hasPrevious();
需要注意的是,使用迭代器时要特别注意 remvoe() 的删除对象:
List<String> list = new LinkedList<>();list.add("Amy");list.add("Bob");list.add("Carl");ListIterator<String> iter = list.listIteraotr();iterator.next(); iterator.next(); iterator.next();iterator.previous();iterator.remove(); // remove Carl
上述过程可以看成这样:
*-[Amy]--[Bob]--[Carl]- iter init-[Amy^]-*-[Bob]--[Carl]- iter.next()-[Amy]--[Bob^]-*-[Carl]- iter.next()-[Amy]--[Bob]--[Carl^]-* iter.next()-[Amy]--[Bob]-*-[Carl^]- iter.previous()-[Amy]--[Bob]-* iter.remove()
*代表当前迭代器的位置,^代表remove()将要删除的值
可以看到,在 iter 初始化和调用 iter.remove() 时,整个 list 中是没有 ^ 的,可见当删除操作会将迭代器返回的元素删除,并且标记也会被删掉。这也是为什么不能连续两次调用 remove() 的原因。
数组列表
链表在进行增加和删除操作都非常有优势,但是如果你有随机访问每个元素的需求,LinkedList 可能就有点吃力。ArrayList 可以很好的解决这个问题,它封装了一个动态再分配的对象数组。
比较一下两者区别:
|
| ArrayList | LinkedList | | —- | —- | —- |
| 获取指定元素 | 速度很快 | 需要从头开始查找元素 |
| 添加元素到末尾 | 速度很快 | 速度很快 |
| 在指定位置添加/删除 | 需要移动元素 | 不需要移动元素 |
| 内存占用 | 少 | 较大 |
HashSet
如果想快速的访问指定元素,又对元素的循序没有要求,你可以使用散列表。散列表为每个对象计算一个整数,称为散列码(hash code)。
在 Java 中,散列表用数组+链表+红黑树实现。每个列表被称为桶(bucket)。当对象存入散列表时,先要计算它的散列码,在对桶数取余。
Java 中有了一些很巧妙的运算,来提高求得索引的速度。比如:显示桶的数量永远为 2 的幂。
我们知道求一个 2 次幂的余数非常简单:
int index = hash & leng - 1;
这也是 Java 为何要将桶的值设为 2 次幂的原因。理论上来说,最好的桶值应该是一个素数。但是为了方便扩容和取余,使用了效果稍微差一点的 2 次幂。
在 Java 中发生 hash 碰撞后,就会在当前桶上创建链表,当链表长度大于等于 8 之后,会将链表转换成红黑树。
在创建一个散列表时,可以指定散列表的长度,还可以指定装填因子的值。但一般情况,我们不会更改装填因子的值。可以根据自己的实际情况确定散列表的长度。这是因为,初始化散列表的长度为 16,但散列表中的元素超过 长度 * 装填因子 的值,散列表就要进行扩容,扩容为当前长度的两倍,其中,散列表中的所有元素都要重新 hash,以防止键的聚集。
一下可以快速算除一个数最接近的 2 次幂:
static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1; // 注意这里是无符号右移n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;}
散列表可以用于实现几个重要的数据结构。其中最简单的是 Set 类型。Set 是没有重复元素的元素集合。
set 主要提供以下方法:
- 将元素添加进
Set:boolean add(E e) - 将元素从
Set删除 :boolean remove(Object e) - 判断是否包含元素 :
boolean contains(Object e)``` public class Main { public static void main(String[] args) {
} }Set<String> set = new HashSet<>();System.out.println(set.add("abc")); // trueSystem.out.println(set.add("xyz")); // trueSystem.out.println(set.add("xyz")); // false,添加失败,因为元素已存在System.out.println(set.contains("xyz")); // true,元素存在System.out.println(set.contains("XYZ")); // false,元素不存在System.out.println(set.remove("hello")); // false,删除失败,因为元素不存在System.out.println(set.size()); // 2,一共两个元素
`Set` 实际上就是一个存储 key ,不存储 value 的 `Map`。value 就是空的 `Object()`。<br />因为 `Set` 重写了 `contains()`,而 `contains()` 中是用 `equlas()` 来比较,所以当你要使用 `Set` 的时候,务必要重写 `equlas()` 和 `hashCode()` 这两个方法。### TreeSet`TreeSet` 类与散列集十分类似,不过,它比散列集有所改进。树集是一个**有序集合**(sorted collection)。可以以任意顺序将元素插入到集合中。在对集合进行遍历时,每个值将自动地按照排序后的顺序呈现。<br />例如,随机插入三个乱序的字符串:
SortedSet
`TreeSet` 使用的是树结构(红黑树)来达到排序的效果。正因为如此,将一个元素添加到树中要比添加到散列表中要慢。> 注意:由于 `TreeSet` 需要排序,必须能够比较元素。所以实现类必须实现 `Comparable` 接口,或构造是提供一个 `Comparator`。可以根据自己的需求选择 `TreeSet` 和 `HashSet` ,如果有排序需求,一般而言使用 `TreeSet` ,其他情况优先考虑 `HashSet` ,毕竟 `TreeSet` 的树结构比较费时。### 队列与双端队列队列(I:Queue, C:ArrayQueue, C:LinkedList)可以让人们有效地在尾部添加一个元素,在头部删除一个元素。<br />有两个端头的队列,即双端队列(I:Deque, C:ArrayDeque),可以让人们有效地在头部和尾部同时添加或删除元素。<br />可以通过面对接口编程,来提高代码质量:
List
```
优先队列
优先队列(priority queue)中的元素可以按照任意的顺序插入,却总是按照排序的顺序进行检索。也就是说,无论何时调用remove方法,总会获得当前优先级队列中最小的元素。
然而,优先队列并没有对所有的元素进行排序。如果用迭代的方式处理这些元素,并不需要对它们进行排序。优先队列使用了一个优雅且高效的数据结构,称为堆(heap)。堆是一个可以自我调整的二叉树,对树执行添加(add)和删除(remore)操作,可以让最小的元素移动到根,而不必花费时间对元素进行排序。
与 TreeSet 一样,一个优先队列既可以保存实现了 Comparable 接口的类对象,也可以保存在构造器中提供的 Comparator 对象。

若有收获,就点个赞吧
0 人点赞
