- Bitmaps
- HyperLogLog
- GEO
- Redis Shell
- Pipeline
- 事务与Lua
- 将一个脚本script装入脚本缓存,但并不立即运行它
- 检查指定哈希校验和的脚本是否存在于脚本缓存, 不存在返回0, 存在返回1
- 清除所有脚本缓存
- 杀死当前正在运行的脚本. Redis提供了一个Lua脚本超时参数:lua-time-limit,默认值是5秒.
- 当Lua脚本执行时间超过lua-time-limit后,会向其他命令调用发送BUSY信号.
- 当达到lua-time-limit值后, 其他命令调用执行在时会收到”Busy Redis is busy
- running a script”的错误, 并提示使用script kill(推荐)或
- shutdown nosave杀掉该busy脚本.
- 发布订阅
Bitmaps
Redis中的Bitmaps是一个可以对位进行操作的字符串,Bitmaps类似于一个以位为单位的数组,数组中的每个单元只能存储0和1,下标叫偏移量。
命令
设置值:setbit key offset val
设置key的第offset个位置的值为val,offset从0开始,val取0或1。
注意: 在第一次初始化Bitmaps时,假如偏移量非常大,那么整个初始化过程执行会比较慢,可能会造成Redis的阻塞。
获取值:getbit key offset
获取键的第offset位的值(从0开始算),返回值是0或1。
获取指定范围值为1的个数:bitcount key [start] [end]
start和end代表起始和结束字节数,省略start和end则获取全部的1的个数。
Bitmaps间的运算
bitop op destkey key1 key2 [key3 ...]
bitop是个复合操作,它可以做多个Bitmaps间的and(交集)、or(并 集)、not(非)、xor(异或)操作并将结果保存在destkey中。
bitpos key targetBit [start] [end]
计算key中第start个字节到第end个字节中第一个值为targetBit的位置。targetBit的取值为0或1。
Bitmaps分析
可以将每个独立用户是否访问过网站存放在Bitmaps中,将访问的用户记做1,没有访问的用户记做0,用户的id减去某个固定值作为偏移量(这么做是为了减少空间浪费)。
对于活跃用户量巨大的场景,使用Bitmaps会比使用set节省很多内存。假设网站有1亿用户,每天独立访问的用户有5千万,如果每天用set类型和Bitmaps分别存储活跃用户可以得到表3-3 
假如该网站每天的独立访问用户很少,例如只有10万(大量的僵尸用户),那么两者的对比如表3-5所示 
HyperLogLog
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。
命令
添加元素:pfadd key ele1 [ele2 ...]
pfadd用于向HyperLogLog中添加元素,如果添加成功返回1。
计算独立用户数:pfcount key1 [key2 ...]
HyperLogLog内存占用量非常小,用HyperLogLog估算大量数据时,存在误差率,官方给出的失误率为:0.81%。
合并:pfmerge destkey sourcekey1 [sourcekey2 ...]
pfmerge可以求出多个HyperLogLog去掉重复元素的并集并赋值给destkey。
使用HyperLogLog有两点需要注意:
- 只为了计算独立总数,不需要获取单条数据。
- 可以容忍一定误差率,毕竟HyperLogLog在内存的占用量上有很大的优 势。
GEO
Redis3.2版本提供了GEO(地理信息定位)功能,支持存储地理位置信 息用来实现诸如附近位置、摇一摇这类依赖于地理位置信息的功能。
命令
增加位置信息:geoadd key lon lat member [lon lat member ...]
参数longitude、latitude、member分别是该地理位置的经度、纬度、成员名。如果集合中没有member则返回1,否则返回0。
删除位置信息:zrem key member
GEO没有提供删除成员的命令,但是因为GEO的底层实现是zset,所以 可以借用zrem命令实现对地理位置信息的删除。
d获取位置信息:geopos key member [member ...]
获取两个位置的距离:grodist key member1 member2 [unit]
其中unit代表返回结果的单位,包含以下四种:
- m(meters)代表米。
- km(kilometers)代表千米。
- mi(miles)代表英里。
- ft(feet)代表尺。
获取制定位置范围内的地理信息集合
```bash georadius key longitude latitude radiusm|km|ft|mi [withcoord] [withdist] [withhash] [COUNT count] [asc|desc] [store key] [storedist key]
georadiusbymember key member radiusm|km|ft|mi [withcoord] [withdist] [withhash] [COUNT count] [asc|desc] [store key] [storedist key]
georadisus和georadiusbymembers两个命令的作用都是以一个地理位置为中心计算指定半径内的其他地理位置信息,不同的是:- georadius给出了具体的经纬度;- georadiusbymembers只需给出成员。radiusm|km|ft|mi是必需参数,指定了半径(带单位)。其他可选参数含义如下:- withcoord:返回结果中包含经纬度。- withdist:返回结果中包含离中心节点位置的距离。- withhash:返回结果中包含geohash。- COUNT count:指定返回结果的数量。- asc|desc:返回结果按照离中心节点的距离做升序或者降序。- store key:将返回结果的地理位置信息保存到指定键。- storedist key:将返回结果离中心节点的距离保存到指定键。<a name="E60Nb"></a>### 获取geohash:`geohash key member [member ...]`geohash用于将二位经纬度转换为一位字符串。geohash的特点如下:- GEO的数据类型为`zset`,Redis将所有的地理位置信息的geohash存放在zet中。- 字符串越长,表示的位置越精确;- geohash编码和经纬度可以相互转换。<a name="i8g2o"></a># 慢查询分析慢查询日志:系统在命令执行前后计算每条命令的执行时间,当超过预设阀值,就将这条命令的相关信息(例如:发生时间,耗时,命令的详细信息)记录下来。<br />Redis客户端执行一条命令分为四个步骤:①发送命令;②命令排队;③命令执行;④返回结果。Redis慢查询只记录第三步的时间。<a name="GIQit"></a>## 慢查询相关的两个配置- `slowlog-log-slower-than` 该配置就是慢查询的时间阈值,单位为微秒(1/10^6秒)。默认值为1000。如果一条命令执行时间超过该阈值,就会被记录在慢查询日志中。- `slowlog-max-len` 慢查询日志最多存储多少条记录。 Redis使用了一个列表来存储慢查询日 志,`slowlog-max-len`就是列表的最大长度 。 当慢查询日志列表已处于其最大长度时,最早插入的 一个命令将从列表中移出。修改上述配置有两种方法:- 通过配置文件修改对应的项;- 通过下数命令修改```bash# 设置慢查询阈值config set slowlog-log-slower-than 20000# 设置慢查询最大长度config set slowlog-max-len 1000# 将配置持久化到本地配置文件config rewrite
慢查询日志的访问和管理
获取慢查询日志:slowlog get [n] # 参数n用于指定条数
# 慢查询日志的四个属性:# 标识id# 发生时间戳# 命令耗时# 执行的命令及参数127.0.0.1:6379> slowlog get 11) 1) (integer) 02) (integer) 16506195263) (integer) 1003694) 1) "migrate"2) "127.0.0.1"3) "6379"4) ""5) "1"6) "100"7) "copy"8) "keys"9) "key1"10) "key2"11) "key3"5) "127.0.0.1:8399"6) ""
获取慢查询日志列表当前长度:slowlog len
慢查询日志重置:slowlog reset。对列表进行清零,执行该命令后slowlog len为0.
实践建议
slowlog-max-len配置建议:生产环境建议调大慢查询列表,减缓慢查询命令被剔除的可能。slowlog-log-slower-than配置建议: 需要根据Redis并发量调整该值,对于高OPS场景的Redis建议设置该参数为1ms。慢查询是一个队列,在慢查询较多的情况下可能会丢失部分慢查询命令,为防止该情况发生,可以定期执行
slow get命令将慢查询日志持久化到其他存储中(如MySQL)。Redis Shell
redis-cli
redis-server
redis-benchmark
Pipeline
Redis客户端执行一条命令分为四个步骤:①发送命令;②命令排队;③命令执行;④返回结果。其中①+④称为
Round Trip Time(RTT)(往返时间)。
Redis中的批量操作命令(如mget、mset等)能有效节约RTT,但对于不支持批量操作的命令(如hgetall)执行n次需要耗时n次RTT,这会对Redis的高并发产生影响。
Pipeline(流水线)机制能将一组redis-cli命令进行组装,通过依次RTT传输给redis-server,再将这组Redis命令的执行结果按顺序返回给客户端。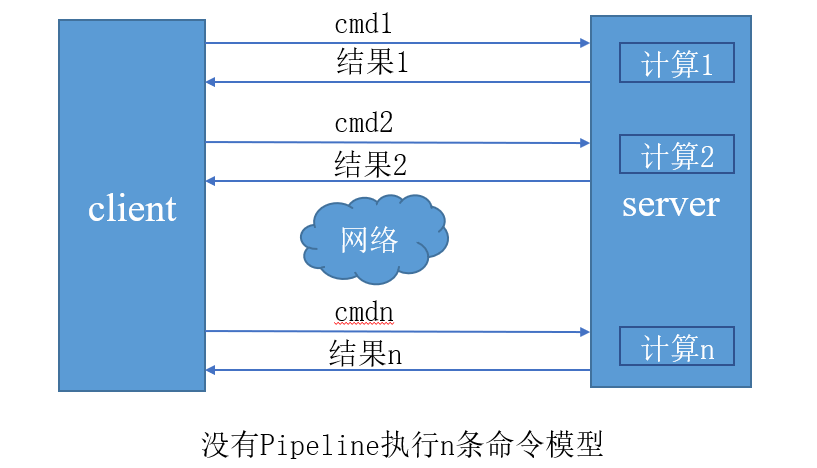
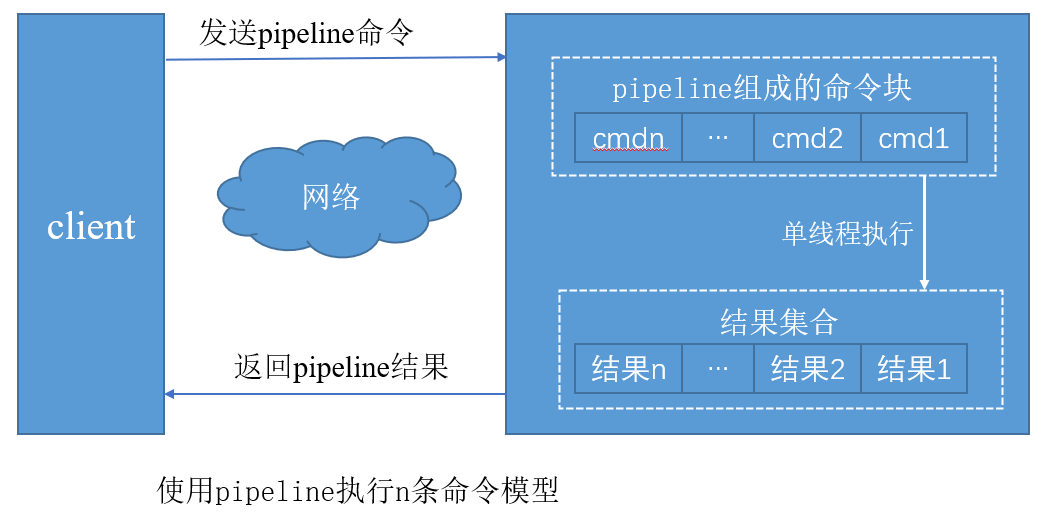
原生批量命令与Pipeline对比
原生批量命令是原子的,Pipeline是非原子的。
- 原生批量命令是一个命令对应多个key,Pipeline支持多个命令。
原生批量命令是服务端支持实现的,而Pipeline需要服务端和客户端的共同实现。
实践建议
Pipeline组装的命令个数不能没有限制,一次组装Pipeline数据量过大,一方面会增加客户端的等待时间,另一方面会造成一定的网络阻塞。可以将一次包含大量命令的Pipeline拆分成多次较小的Pipeline来完成。
Pipeline只能操作一个Redis实例,但是即使在分布式Redis场景中,也可以作为批量操作的重要优化手段。事务与Lua
Redis事务
事务表示一组动作要么全部执行,要么全部不执行。 Redis提供了简单的事务功能(不支持回滚,不支持多个命令间的逻辑关系运算),将一组需要一起执行的命令放到
multi和exec两个命令之间。multi命令代表事务开始,exec命令代表事务结束,它们之间的命令是原子顺序执行的。127.0.0.1:6379> multi # 开始事务OK127.0.0.1:6379> sadd user:a:follow user:b # 命令入队QUEUED127.0.0.1:6379> sadd user:b:fans: user:a # 命令入队QUEUED127.0.0.1:6379> sismember user:a:follow user:b # 命令入队QUEUED# 127.0.0.1:6379> discard # 放弃执行事务127.0.0.1:6379> exec # 执行事务1) (integer) 12) (integer) 13) (integer) 1
事务中的命令出现错误的处理机制
命令错误:整个事务无法执行;
- 运行时错误:由于Redis不支持回滚功能,该类问题需要开发人员修复。
某些应用场景需要在事务执行前确保事务中使用的key没有被其他客户端修改过才执行事务,否则不执行事务(类似乐观锁)。Redis中提供watch命令解决该类问题。
# T1: 客户端1127.0.0.1:6379> set key "java"OK# T2: 客户端1127.0.0.1:6379> watch keyOK# T3: 客户端1127.0.0.1:6379> multiOK# T4: 客户端2127.0.0.1:6379> append key python(integer) 13# T5: 客户端1127.0.0.1:6379> append key jedisQUEUED# T6: 客户端1127.0.0.1:6379> exec(nil)# T7: 客户端1127.0.0.1:6379> get key"javapython"
Redis与Lua
在Redis中使用Lua有eval、evalsha两种方式。eval方式直接对Lua脚本进行求值,使用方式如下:eval script numkeys key1 [key2 ...] arg1 [arg2 ...]
script:待执行的脚本;numkeys:键参数个数;key1 [key2 ...]:键名,通过KEYS[1] KEYS[2]...的形式访问;arg1 [arg2 ...]:键值,通过ARGV[1] ARGV[2]...的形式访问。# 通过KEYS数组形式和ARGV数组形式访问键、值, 数组下标从1开始127.0.0.1:6379> eval "return redis.call('mset', KEYS[1], ARGV[1], KEYS[2], ARGV[2])" 2 namekey1 namekey2 val1 val2OK127.0.0.1:6379> get namekey1"val1"127.0.0.1:6379> get namekey2"val2"
evalsha方式首先要通过script命令将Lua脚本加载到Redis服务端,得到该脚本的SHA1校验和。evalsha命令使用SHA1作为参数可以直接执行对应Lua脚本,避免每次发送 Lua脚本的开销。这样客户端就不需要每次执行脚本内容,而脚本也会常驻在服务端,脚本功能得到了复用。evalsha的使用格式:evalsha sha1 numkeys key1 [key2 ...] arg1 [arg2 ...]```bash将一个脚本script装入脚本缓存,但并不立即运行它
SCRIPT LOAD script
检查指定哈希校验和的脚本是否存在于脚本缓存, 不存在返回0, 存在返回1
SCRIPT EXISTS sha1 [sha1 …]
清除所有脚本缓存
SCRIPT FLUSH
杀死当前正在运行的脚本. Redis提供了一个Lua脚本超时参数:lua-time-limit,默认值是5秒.
当Lua脚本执行时间超过lua-time-limit后,会向其他命令调用发送BUSY信号.
当达到lua-time-limit值后, 其他命令调用执行在时会收到”Busy Redis is busy
running a script”的错误, 并提示使用script kill(推荐)或
shutdown nosave杀掉该busy脚本.
SCRIPT KILL
```bash127.0.0.1:6379> script load "redis.pcall('set', KEYS[1], ARGV[1]);""7b1d5b9c8a10de4d1ceacbd26319d7c6bd608110"127.0.0.1:6379> evalsha 7b1d5b9c8a10de4d1ceacbd26319d7c6bd608110 2 namekey1 namekey2 newval1 newval2(nil)127.0.0.1:6379> get namekey1"newval1"127.0.0.1:6379> script exists 7b1d5b9c8a10de4d1ceacbd26319d7c6bd6081101) (integer) 1
redis.call和redis.pcall的不同在于:如果redis.call执行失败,那么脚本执行结束会直接返回错误,而redis.pcall会忽略错误继续执行脚本。
Lua可以使用redis.log函数将Lua脚本的日志输出到Redis的日志文件中, 但是需要控制日志级别。
Redis中使用Lua脚本的好处:
- Lua脚本在Redis中是原子执行的,执行过程中间不会插入其他命令。
- Lua脚本可以帮助开发和运维人员创造出自己定制的命令,并可以将这 些命令常驻在Redis内存中,实现复用的效果。
- Lua脚本可以将多条命令一次性打包,有效地减少网络开销。
Redis中使用Lua的注意事项:
- 由于Redis的单线程特点,一旦Lua脚本出现不会返回(不是返回值)的问题,那么这个脚本就会阻塞整个redis实例;因此使用Lua脚本应该首先排除脚本的Bug,另外脚本应该尽量短小,实现关键步骤即可;
- Lua脚本中不应该出现常量key,这样会导致每次执行时都会在脚本字典中新建一个条目,应该使用全局变量数组
KEYS和ARGV, KEYS和ARGV的索引都从1开始; - 传递给lua脚本的键列表应该包括可能会读取或者写入的所有键。传入全部的键使得在使用各种分片或者集群技术时,其他软件可以在应用层检查所有的数据是不是都在同一个分片里面。另外集群版redis也会对将要访问的key进行检查,如果不在同一个服务器里面,那么redis将会返回一个错误。决定使用集群版之前应该考虑业务拆分,参数列表无所谓。
发布订阅
Redis提供了基于”发布/订阅”模式的消息机制,此种模式下,消息发布者和订阅者不进行直接通信,发布者客户端向指定的频道(channel)发布消息,订阅该频道的每个客户端都可以收到该消息,如图3-16所示。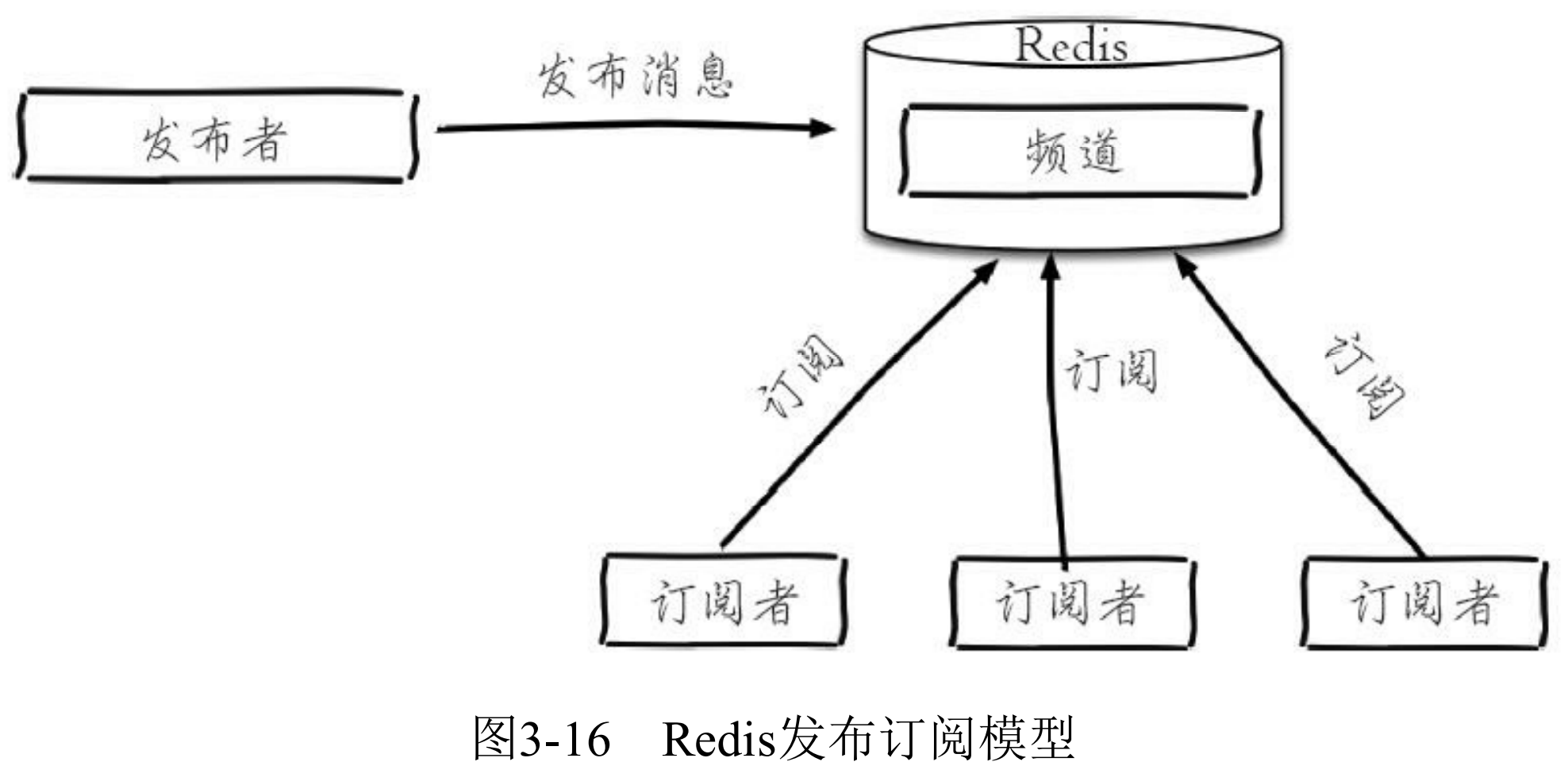
命令
发布消息:publish channel message
pushlish命令向频道channel发布一条消息messgae,返回结果是订阅该频道的用户个数,无订阅则返回0。
订阅消息:subscribe channel [channel ...]
订阅者可以订阅一个或多个频道。订阅频道需要注意:
- 客户端在执行订阅命令之后进入了订阅状态,只能接收subscribe、 psubscribe、unsubscribe、punsubscribe的四个命令。
新开启的订阅客户端,无法收到该频道之前的消息,因为Redis不会对发布的消息进行持久化。
取消订阅:
unsubscribe [channel [channel ...]]按照模式订阅和取消订阅
psubscribe pattern [pattern ..]punsubscribe [pattern [pattern ...]]查询订阅
查询活跃(至少有一个订阅者)频道:
pubsub channels [pattern]- 查询频道订阅数:
pubsub numsub [channel ...] - 查看模式订阅数:
pubsub numpat

若有收获,就点个赞吧
0 人点赞
