常见数据库对象
| 对象 | 描述 |
|---|---|
| 表(TABLE) | 表是存储数据的逻辑单元,以行和列的形式存在,列就是字段,行就是记录 |
| 数据字典 | 就是系统表,存放数据库相关信息的表。系统表的数据通常由数据库系统维护,程序员通常不应该修改,只能查看 |
| 约束(CONSTRAINT) | 执行数据校验的规则,用于保证数据完整性的规则 |
| 视图(VIEW) | 一个或者多个数据表里的数据的逻辑显示,视图并不存储数据 |
| 索引(INDEX) | 用于提高查询性能,相当于书的目录 |
| 存储过程(PROCEDURE) | 用于完成一次完整的业务处理,没有返回值,但可通过传出参数将多个值传给调用环境 |
| 存储函数(FUNCTION) | 用于完成一次特定的计算,具有一个返回值 |
| 触发器(TRIGGER) | 相当于一个事件监听器,当数据库发生特定事件后,触发器被触发,完成相应的处理 |
视图概述
- 视图是虚拟的表,与包含数据的表不一样,视图只包含使用时动态检索数据的查询。
- 视图建立在已有表(基表)的基础上。
- 视图的创建和删除只影响视图本身,不影响对应的基表。但是当对视图中的数据进行增加、删除和修改操作时,数据表中的数据会相应地发生变化,反之亦然。
- SELECT语句向视图提供数据内容, 可以将视图理解为存储起来的SELECT语句。
- 视图是向用户提供基表数据的另一种表现形式。大型项目中,以及数据表比较复杂的情况下,试图可以帮助我们把经常查询的结果集放到虚拟表中,提升使用效率。使用视图的主要目的是为了简化复杂数据处理。
视图的一些常见应用:①重用SQL语句;②简化复杂的SQL操作:在编写查询后,可以方便地重用它而不必知道它的基本查询细节;③使用表的组成部分而不是整个表;④保护数据:可以给用户授予表的特定部分的访问权限而不是整个表的访问权限;⑤更改数据格式和表示:视图可返回与底层表的表示和格式不同的数据。
在视图创建之后,可以用与表基本相同的方式利用它们。可以对视图执行SELECT操作,过滤和排序数据,将视图联结到其他视图或表,甚至能添加和更新数据。但视图仅仅是用来查看存储在别处的数据的一种设施。 视图本身不包含数据,因此它们返回的数据是从其他表中检索出来的。 在添加或更改这些表中的数据时,视图将返回改变过的数据。
创建视图
-- 在CREATE VIEW语句中嵌入子查询CREATE [OR REPLACE][ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]VIEW 视图名称 [(字段列表)]AS 查询语句[WITH [CASCADED|LOCAL] CHECK OPTION]-- 精简版CREATE VIEW 视图名称AS 查询语句
视图创建和使用的一些最常见的规则和限制:
- 在创建视图时,没有在视图名后面指定字段列表,则视图中字段列表默认和SELECT语句中的字段列表一致。如果SELECT语句中给字段取了别名,那么视图中的字段名和别名相同。
- 与表一样,视图必须唯一命名(不能给视图取与别的视图或表相同的名字)。
- 对于可以创建的视图数目没有限制。
- 为了创建视图,必须具有足够的访问权限。这些限制通常由数据库管理人员授予。
- 视图可以嵌套,即可以利用从其他视图中检索数据的查询来构造一个视图。
- ORDER BY可以用在视图中,但如果从该视图检索数据SELECT中也含有ORDER BY,那么该视图中的ORDER BY将被覆盖。
- 视图不能索引,也不能有关联的触发器或默认值。
- 视图可以和表一起使用。例如,编写一条联结表和视图的SELECT语句。
创建单视图
```sql — 示例1 CREATE VIEW empvu80 AS SELECT employee_id, last_name, salary FROM employees WHERE department_id = 80;
— 示例2 CREATE VIEW salvu50 AS SELECT employee_id ID_NUMBER, last_name NAME,salary*12 ANN_SALARY FROM employees WHERE department_id = 50;
<a name="VrNZf"></a>## 创建多表联合视图```sql-- 示例1CREATE VIEW emp_deptASSELECT ename,dnameFROM t_employee LEFT JOIN t_departmentON t_employee.did = t_department.did;-- 示例2CREATE VIEW dept_sum_vu(name, minsal, maxsal, avgsal)ASSELECT d.department_name, MIN(e.salary), MAX(e.salary),AVG(e.salary)FROM employees e, departments dWHERE e.department_id = d.department_idGROUP BY d.department_name;-- 示例3-- 格式化数据: 对于经常需要的固定格式的查询结果可以使用视图CREATE VIEW emp_departASSELECT CONCAT(last_name,'(',department_name,')') AS emp_deptFROM employees e JOIN departments dWHERE e.department_id = d.department_id
基于视图创建视图
-- 联合emp_dept视图和emp_year_salary视图查询员工姓名、部门名称、年薪信息-- 创建emp_dept_ysalary视图。CREATE VIEW emp_dept_ysalaryASSELECT emp_dept.ename,dname,year_salaryFROM emp_dept INNER JOIN emp_year_salaryON emp_dept.ename = emp_year_salary.ename;
查看视图
查看数据库的表对象、视图对象:SHOW TABLES;
查看视图的结构:DESC/DESCRIBE 视图名;
查看视图属性信息:SHOW TABLE STATUS LIKE '视图名';执行结果显示,注释Comment为VIEW,说明该表为视图,其他的信息为NULL,说明这是一个虚表。
查看视图的详细定义信息:SHOW CREATE VIEW 视图名;
更新视图
视图是可更新的(即,可以对它们使用INSERT、UPDATE和 DELETE)。由于视图本身没有数据,更新一个视图将更新其基表,如果对视图增加或删除行,实际上是对其基表增加或删除行。
但要使视图可更新,视图中的行和底层基本表中的行之间必须存在一对一的关系。当视图定义出现如下情况时,视图不支持更新操作:
- 在定义视图的时候指定了
ALGORITHM = TEMPTABLE,视图将不支持INSERT和DELETE操作; - 视图中不包含基表中所有被定义为非空又未指定默认值的列,视图将不支持INSERT操作;
- 在定义视图的SELECT语句中使用了JOIN联合查询,视图将不支持INSERT和DELETE操作;
- 在定义视图的SELECT语句后的字段列表中使用了数学表达式或子查询,视图将不支持INSERT,也不支持UPDATE使用了数学表达式、子查询的字段值;
- 在定义视图的SELECT语句后的字段列表中使用DISTINCT、聚合函数、GROUP BY、HAVING、UNION等,视图将不支持INSERT、UPDATE、DELETE;
- 在定义视图的SELECT语句中包含了子查询,而子查询中引用了FROM后面的表,视图将不支持INSERT、UPDATE、DELETE;
- 视图定义基于一个不可更新视图;
- 常量视图。
视图主要是用于检索(SELECT)数据,所以一般不更新(INSERT、UPDATE、DELETE)视图。
修改、删除视图
修改视图
方式一:使用CREATE **OR REPLACE** VIEW子句修改视图
-- 原视图empvu80CREATE VIEW empvu80ASSELECT employee_id, last_name, salaryFROM employeesWHERE department_id = 80;-- 修改empvu80: CREATE VIEW 子句中各列的别名应和子查询中各列相对应。CREATE OR REPLACE VIEW empvu80(id_number, name, sal, department_id)ASSELECT employee_id, first_name || ' ' || last_name, salary, department_idFROM employeesWHERE department_id = 80;
方式二:使用ALTER VIEW修改视图
ALTER VIEW 视图名称AS查询语句
删除视图
删除视图只是删除视图的定义,并不会删除其基表的定义。删除视图的语法如下:
DROP VIEW IF EXISTS 视图1 [, 视图2, 视图3 ...];
说明:基于视图a、b创建了新的视图c,如果将视图a或者视图b删除,会导致视图c的查询失败。这样的视图c需要手动删除或修改,否则影响使用。
总结
视图优点
1. 操作简单
将经常使用的查询操作定义为视图,可以使开发人员不需要关心视图对应的数据表的结构、表与表之间的关联关系,也不需要关心数据表之间的业务逻辑和查询条件,而只需要简单地操作视图即可,极大简化了开发人员对数据库的操作。
2. 减少数据冗余
视图跟实际数据表不一样,它存储的是查询语句。所以,在使用的时候,我们要通过定义视图的查询语句来获取结果集。而视图本身不存储数据,不占用数据存储的资源,减少了数据冗余。
3. 数据安全
MySQL将用户对数据的访问限制在某些数据的结果集上,而这些数据的结果集可以使用视图来实现。用户不必直接查询或操作数据表。这也可以理解为视图具有隔离性。视图相当于在用户和实际的数据表之间加了一层虚拟表。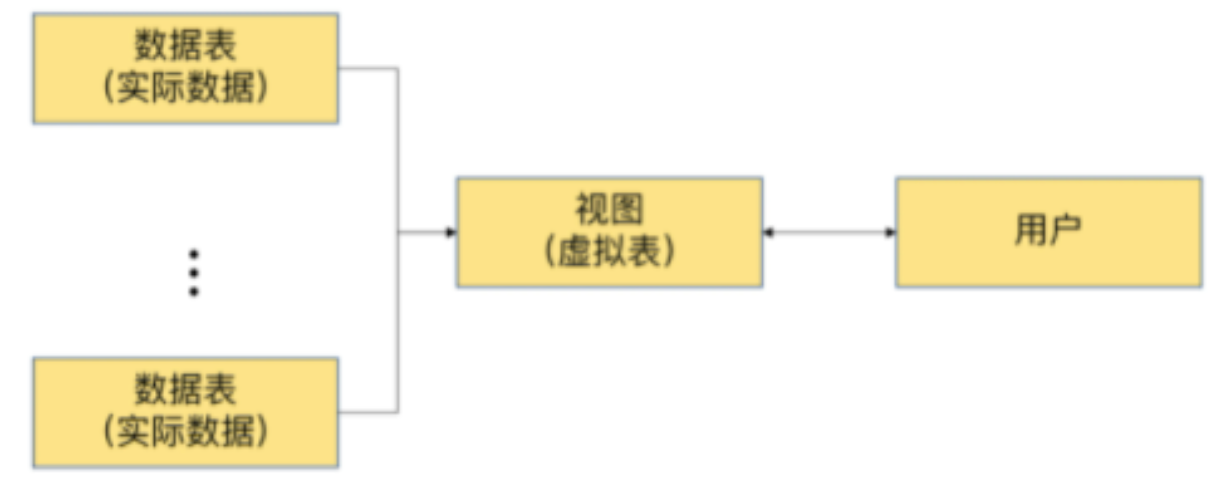
同时,MySQL可以根据权限将用户对数据的访问限制在某些视图上,用户不需要查询数据表,可以直接通过视图获取数据表中的信息。这在一定程度上保障了数据表中数据的安全性。
4. 适应灵活多变的需求当业务系统的需求发生变化后,如果需要改动数据表的结构,则工作量相对较大,可以使用视图来减少改动的工作量。这种方式在实际工作中使用得比较多。
5. 能够分解复杂的查询逻辑数据库中如果存在复杂的查询逻辑,则可以将问题进行分解,创建多个视图获取数据,再将创建的多个视图结合起来,完成复杂的查询逻辑。
视图缺点
如果我们在实际数据表的基础上创建了视图,那么,如果实际数据表的结构变更了,就需要及时对相关的视图进行相应的维护。特别是嵌套的视图(就是在视图的基础上创建视图),维护会变得比较复杂,可读性不好,容易变成系统的潜在隐患。因为创建视图的 SQL 查询可能会对字段重命名,也可能包含复杂的逻辑,这些都会增加维护的成本。
实际项目中,如果视图过多,会导致数据库维护成本的问题。
所以,在创建视图的时候,你要结合实际项目需求,综合考虑视图的优点和不足,这样才能正确使用视图,使系统整体达到最优。

若有收获,就点个赞吧
0 人点赞
