yolo基本原理
对图形进行SS的方格切分,每个区域都会浓缩成一个11N维的点,yolo会根据这个点生成B个锚框(bbox)。每个锚框固定有五个属性:中心位置(x,y),宽高(w,h)和是否有目标的置信度。同时锚框还需要携带所有C个分类指标的信息。为此整个yolo的输入ground truth维度为:`SS*(B+(5+C))`,预测结果也为这个维度。之后通过预测结果和GT进行loss计算,同时对网络进行传播更新。
yolo的网络结构如下图所示,分为三个部分(和大部分目标监测相似):backbone -> neck -> head,最后生成feature map,再通过fc层和激活函数来进行分类。back部分主要对图像进行特征提取,例如把图像成1/8,1/16,1/32三个部分,其被称为feature map。yolov3采用的backbone网络是DarkNet53的方法。neck部分主要对back的不同特征进行图像融合,同时针对大中小的目标采用不同输出。最后接head层输出分类结果。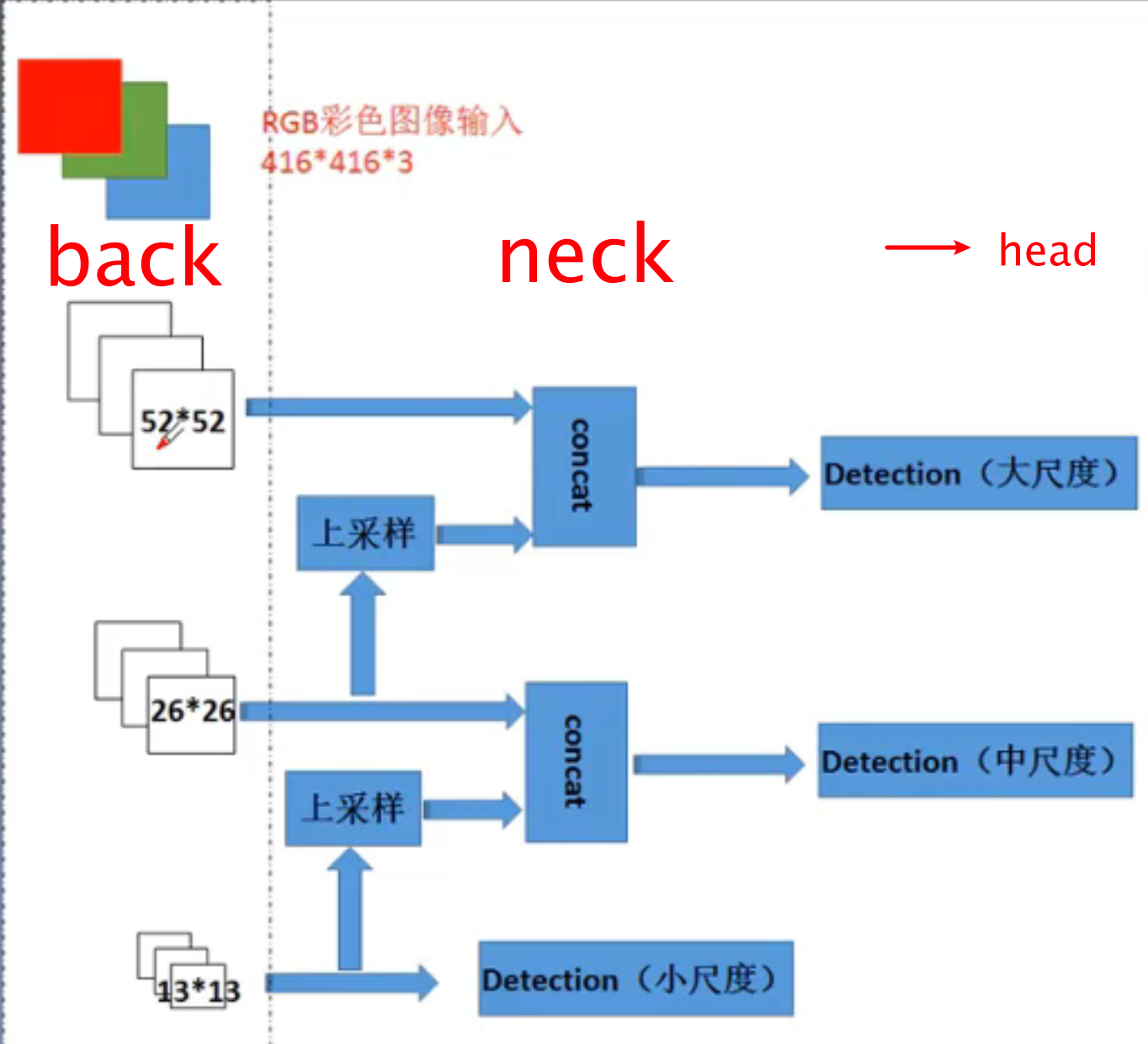
Detail
Yolov3会生成3个尺度的预测框(参考FPN,并加上了一些卷积层),并且为每个预测生成一个三维的数据框,分别编码了bounding box,objectness和class predictions。

若有收获,就点个赞吧
0 人点赞
