程序的指令
Hello World
现在我们来创建第一个Go项目——hello。在我们桌面创建一个hello目录。
在该目录中创建一个main.go 入口文件:
// 声明包(main包打包之后是一个可执行文件;其他包就是第三方包-工具类)package main// 依赖模块-切记双引号import "fmt"// 函数外只能放置标识符(变量、常量、函数、类型)的声明// 程序入口:无参无返回值func main() {fmt.Println("hello")fmt.Printf("sss")}// go fmt main.go保存时自动执行格式化;注释也会格式化;// 不需要写分号结束编译时自动添加,但是如果语句想写在一行则手动添加分号
go run
go install
go install表示安装的意思:
- 先编译源代码得到可执行文件
- 然后将生成的可执行文件移动到
GOPATH的bin目录下。
因为我们的环境变量中配置了GOPATH下的bin目录,所以我们就可以在任意地方直接访问/执行可执行文件了。
go build
go build表示将源代码编译成可执行文件。生成的执行文件都在当前执行命令的目录下。
在hello目录下执行:
go build
或者在其他目录执行以下命令:
go build github.com/topaz-h/helloworld# go编译器会去 GOPATH的src目录下查找你要编译的hello项目# 编译得到的可执行文件会保存在执行编译命令的当前目录下,如果是windows平台会在`当前目录下`找到hello.exe可执行文件。
可在终端直接执行该
hello.exe文件:c:\desktop\hello>hello.exeHello World!
我们还可以使用
-o参数来指定编译后得到的可执行文件的名字。否则默认名字是程序项目目录名。go build -o heihei.exe
跨平台(交叉)编译
默认我们go build的可执行文件都是当前操作系统可执行的二进制文件,如果我想在windows下编译一个linux下可执行文件,那需要怎么做呢?
只需要指定目标操作系统的平台和处理器架构即可:
SET CGO_ENABLED=0 // 禁用CGOSET GOOS=linux // 目标平台是linuxSET GOARCH=amd64 // 目标处理器架构是amd64
使用了cgo的代码是不支持跨平台编译的
然后再执行go build命令,得到的就是能够在Linux平台运行的可执行文件了。
Mac 下编译 Linux 和 Windows平台 64位 可执行程序:
CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go buildCGO_ENABLED=0 GOOS=windows GOARCH=amd64 go build
Linux 下编译 Mac 和 Windows 平台64位可执行程序:
CGO_ENABLED=0 GOOS=darwin GOARCH=amd64 go buildCGO_ENABLED=0 GOOS=windows GOARCH=amd64 go build
Windows下编译Mac平台64位可执行程序:
SET CGO_ENABLED=0SET GOOS=darwinSET GOARCH=amd64go build
现在,开启你的Go语言学习之旅吧。人生苦短,let’s Go.
go-lint
标识符大写,需要外部包使用时。上一行添加注释
格式为 // 标识符名+空格+文字说明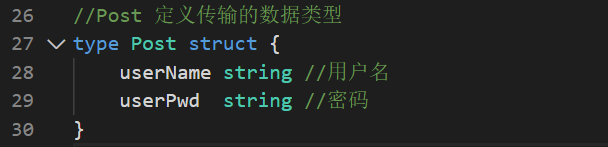
- 我们要在结构体的上一行编写函数注释文件,而且一定要用这个函数名称开头,注意外部需要调用的话,函数名/结构体名大写
- 尽量不要使用在golang语言中使用下划线命名,改user_name为userName.
Go语言基础之变量
变量
标识符
在编程语言中标识符就是程序员定义的具有特殊意义的词,比如变量名、常量名、函数名等等。 Go语言中标识符由字母数字和_(下划线)组成,并且只能以字母和_开头。 举几个例子:abc,_,_123,a123。关键字和保留字
关键字是指编程语言中预先定义好的具有特殊含义的标识符。 关键字和保留字都不建议用作变量名。
Go语言中有25个关键字:
此外,Go语言中还有37个保留字。break default func interface selectcase defer go map structchan else goto package switchconst fallthrough if range typecontinue for import return var
Constants: true false iota nilTypes: int int8 int16 int32 int64uint uint8 uint16 uint32 uint64 uintptrfloat32 float64 complex128 complex64bool byte rune string errorFunctions: make len cap new append copy close deletecomplex real imagpanic recover
声明及初始化、批量声明(两种)、类型推导、三种打印
同一个作用域不能重复声明同名变量
package mainimport "fmt"// 1. 声明变量:关键字var && 变量的初始化:`var 变量名 类型 = 表达式`var s1 string = "声明时就赋值"// 2. 批量声明(简化多个声明时的写法)var name, age = "Q1mi", 20var (// 推荐使用小驼峰stu_name string // ×stuName string // √StuName string // ×)// 3. 类型推导var s2 = "根据第一次赋值类型确定类型,后续不能赋值为其他类型"func main() {s1 = "声明"/* GO语言中非全局变量声明后必须使用,苟泽编译不过去(比如函数内部);全局为什么没事?因为在当前没有使用,可能作为第三方包,被其他文件引入使用 */fmt.Println(s1) // 打印加换行fmt.Printf("s1:%s\n", s1) // %s占位符-格式化打印;\n手动换行fmt.Print(s1) // 终端输出不换行}
短变量声明和匿名变量
- 在函数内部,可以使用更简略的
:=方式声明并初始化变量。 - 在使用多重赋值时,如果想要忽略某个值,可以使用
匿名变量(anonymous variable)。 匿名变量用一个下划线_表示。匿名变量不占用命名空间,不会分配内存,所以匿名变量之间不存在重复声明。 (在Lua等编程语言里,匿名变量也被叫做哑元变量。) - 原因:因为函数内部声明的变量必须使用,但是有的不会使用则使用_占位,并且可以重复使用,不会分配内存。 ```go package main import ( “fmt” )// 导入多个
func foo() (int, string) { return 10, “Q1mi” } // 全局变量m var m = 100 func main() { n := 200 // 此处声明局部变量m fmt.Println(m, n) x, := foo(); , y := foo(); // 忽略不会使用的值 fmt.Println(“x=”, x) }
<a name="noja6"></a>## 常量相对于变量,常量是恒定不变的值,多用于定义程序运行期间不会改变的那些值。 常量的声明和变量声明非常类似,只是把`var`换成了`const`,常量在定义的时候必须赋值。```go// 单独声明const pi = 3.1415const e = 2.7182// 批量声明const (pi = 3.1415; e = 2.7182;)// const同时声明多个常量时,如果省略了值则表示和上面一行的值相同。 例如:const (n1 = 100; n2; n3;)上面示例中,常量n1、n2、n3的值都是100
iota
iota是go语言的常量计数器,只能在常量的表达式中使用。
iota在const关键字出现时将被重置为0。const中每新增一行常量声明将使iota计数一次(iota可理解为const语句块中的行索引)。 使用iota能简化定义,在定义枚举时很有用。- 跳过和插队只要是新增了一行都会计数。
- 多个常量定义在一行(iota的值是相等的)。
- 注意:省略了值则表示和上面一行的值相同,只是增一行会记一次数。
举个例子:
const (n1 = iota // 0 - 被重置为0n2 // 1 - 后续开始计数_ // 使用_跳过某些值n4 // 3n5 = 100 // n5为100是中间插队n6 = iota // 5n7, n8 = iota + 8 // 6, 14 - 多个常量定义在一行(iota的值是相等的))/* 定义数量级 (这里的<<表示左移操作,1<<10表示将1的二进制表示向左移10位,也就是由1变成了10000000000,也就是十进制的1024。同理2<<2表示将2的二进制表示向左移2位,也就是由10变成了1000,也就是十进制的8。)*/const (_ = iota // iota=0; 值为0 - 不存入内存KB = 1 << (10 * iota) // iota=1; 值为1左移10位(二进制1后面加10个零 转为十进制为1024)MB = 1 << (10 * iota) // iota=2; 值为1左移20位(二进制1后面加20个零 转为十进制为1024的2次方)GB = 1 << (10 * iota) // iota=3; 值为1左移30位(二进制1后面加30个零 转为十进制为1024的3次方)TB = 1 << (10 * iota) // iota=4; 值为1左移40位(二进制1后面加40个零 转为十进制为1024的4次方)PB = 1 << (10 * iota) // iota=5; 值为1左移50位(二进制1后面加50个零 转为十进制为1024的5次方))

若有收获,就点个赞吧
0 人点赞
