什么是cgo
C/C++经过几十年的发展,已经积累了庞大的软件资产,它们很多久经考验而且性能已经足够优化。Go语言必须能够站在C/C++这个巨人的肩膀之上,有了海量的C/C++软件资产兜底之后,我们才可以放心愉快地用Go语言编程。C语言作为一个通用语言,很多库会选择提供一个C兼容的API,然后用其他不同的编程语言实现。Go语言通过自带的一个叫CGO的工具来支持C语言函数调用,同时我们可以用Go语言导出C动态库接口给其它语言使用。本章主要讨论CGO编程中涉及的一些问题。
案例
hello word
调用C语言标准io打印字符串
package main//#include <stdio.h>import "C"func main() {C.puts(C.CString("Hello, World\n"))}
go run main.go
简单调用自己的C语言函数
package main
/*
#include <stdio.h>
static void SayHello(const char* s) {
puts(s);
}
*/
import "C"
func main() {
C.SayHello(C.CString("Hello, World\n"))
}
调用一个C语言源文件的函数
将SayHello函数放到当前目录下的一个C语言源文件中(后缀名必须是.c)。因为是编写在独立的C文件中,为了允许外部引用,所以需要去掉函数的static修饰符
#include <stdio.h>
void SayHello(const char* s) {
puts(s);
}
package main
//void SayHello(const char* s);
import "C"
func main() {
C.SayHello(C.CString("Hello, World\n"))
}
注意,如果之前运行的命令是go run hello.go或go build hello.go的话,此处须使用go run “your/package”或go build “your/package”才可以。若本就在包路径下的话,也可以直接运行go run .或go build
调用静态库或者动态库
int number_add(int a, int b);
#include "number.h"
int number_add(int a, int b) {
return a+b;
}
生成静态库
$ pushd number
$ gcc -c -o number.o number.c
$ ar rcs libnumber.a number.o
$ popd
cgo代码
package main
//#cgo CFLAGS: -I./number
//#cgo LDFLAGS: -L${SRCDIR}/number -lnumber
//
//#include "number.h"
import "C"
import "fmt"
func main() {
fmt.Println(C.number_add(11,10))
}
编译运行
go run .
用cgo 重写C函数
现在我们创建一个hello.go文件,用Go语言重新实现C语言接口的SayHello函数:
void SayHello(/*const*/ char* s);
通过CGO的//export SayHello指令将Go语言实现的函数SayHello导出为C语言函数。为了适配CGO导出的C语言函数,我们禁止了在函数的声明语句中的const修饰符。需要注意的是,这里其实有两个版本的SayHello函数:一个Go语言环境的;另一个是C语言环境的。cgo生成的C语言版本SayHello函数最终会通过桥接代码调用Go语言版本的SayHello函数。
package main
import "C"
import "fmt"
//export SayHello
func SayHello(s *C.char) {
fmt.Printf("go::SayHello() %s",C.GoString(s))
}
package main
//#include <hello.h>
import "C"
func main() {
C.SayHello(C.CString("Hello, World\n"))
}

go编译生成兼容C标准的so
package main
import "C"
//export add
func add(x, y int) int {
return x + y
}
//export remove_int
func remove_int(x, y int) int {
return x - y
}
func main() {
}
/*
这里有几点要注意
package 一定要是 main(强制规定)
一定要包含 main 函数(强制规定)
import “C”, 不能少, 因为要编译出 c(c++)的头文件
每个方法前要加//export 方法名, 这里要注意
// 和 export间不能有空格
方法名和 go 的方法名必须完全一样
方法名不能是 c 内置的方法名, 比如remove就不行
方法名需要和导出名一样,不受Golang大小写控制作用域
方法的入参出参数据类型遵循类型映射规则,如使用string做入参, C语言代码就需要传入GoString,
GoString str = {"Hi JXES", 7}; 还不如用 *C.char 作为参数
编译命令:
go build -buildmode=c-shared -o libdemo.so libdemo.go
编译成功会生成 libdemo.so 和 libdemo.h
*/
用C来调用
#include<stdio.h>
#include"libdemo.h" //生成的头文件
void main(){
printf("\n2+3=%lld\n",add(2,3));
}
/*
gcc goso.c -L ./ -ldemo -o goso
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$(pwd)
./goso
*/


cgo 核心
预编译注释
在import “C”语句前的注释中可以通过#cgo语句设置编译阶段和链接阶段的相关参数。编译阶段的参数主要用于定义相关宏和指定头文件检索路径。链接阶段的参数主要是指定库文件检索路径和要链接的库文件。
// #cgo CFLAGS: -DPNG_DEBUG=1 -I./include
// #cgo LDFLAGS: -L/usr/local/lib -lpng
// #include <png.h>
import "C"
- CFLAGS部分
- -D部分定义了宏PNG_DEBUG,值为1;
- -I定义了头文件包含的检索目录;
- DFLAGS部分
- -L指定了链接时库文件检索目录;
- -l指定了链接时需要链接png库;
因为C/C++遗留的问题,C头文件检索目录可以是相对目录,但是库文件检索目录则需要绝对路径。在库文件的检索目录中可以通过${SRCDIR}变量表示当前包目录的绝对路径:
// #cgo LDFLAGS: -L${SRCDIR}/libs -lfoo
上面的代码在链接时将被展开为:
// #cgo LDFLAGS: -L/go/src/foo/libs -lfoo
cgo语句主要影响CFLAGS、CPPFLAGS、CXXFLAGS、FFLAGS和LDFLAGS几个编译器环境变量。
- LDFLAGS用于设置链接时的参数,除此之外的几个变量用于改变编译阶段的构建参数(CFLAGS用于针对C语言代码设置编译参数)。
- 对于在cgo环境混合使用C和C++的用户来说,可能有三种不同的编译选项:
- 其中CFLAGS对应C语言特有的编译选项、CXXFLAGS对应是C++特有的编译选项、CPPFLAGS则对应C和C++共有的编译选项。
- 但是在链接阶段,C和C++的链接选项是通用的,因此这个时候已经不再有C和C++语言的区别,它们的目标文件的类型是相同的。
cgo指令还支持条件选择,当满足某个操作系统或某个CPU架构类型时后面的编译或链接选项生效。比如下面是分别针对windows和非windows下平台的编译和链接选项:
// #cgo windows CFLAGS: -DX86=1
// #cgo !windows LDFLAGS: -lm
其中在windows平台下,编译前会预定义X86宏为1;在非widnows平台下,在链接阶段会要求链接math数学库。这种用法对于在不同平台下只有少数编译选项差异的场景比较适用。
如果在不同的系统下cgo对应着不同的c代码,我们可以先使用#cgo指令定义不同的C语言的宏,然后通过宏来区分不同的代码:
package main
/*
#cgo windows CFLAGS: -DCGO_OS_WINDOWS=1
#cgo darwin CFLAGS: -DCGO_OS_DARWIN=1
#cgo linux CFLAGS: -DCGO_OS_LINUX=1
#if defined(CGO_OS_WINDOWS)
const char* os = "windows";
#elif defined(CGO_OS_DARWIN)
static const char* os = "darwin";
#elif defined(CGO_OS_LINUX)
static const char* os = "linux";
#else
# error(unknown os)
#endif
*/
import "C"
func main() {
print(C.GoString(C.os))
}
这样我们就可以用C语言中常用的技术来处理不同平台之间的差异代码。
golang 预编译参数
// +build debug
package main
var buildMode = "debug"
使用如下命令构建
go build -tags="debug"
go build -tags="windows debug"
我们可以通过-tags命令行参数同时指定多个build标志,它们之间用空格分隔。
当有多个build tag时,我们将多个标志通过逻辑操作的规则来组合使用。比如以下的构建标志表示只有在”linux/386“或”darwin平台下非cgo环境“才进行构建。
// +build linux,386 darwin,!cgo
其中linux,386中linux和386用逗号链接表示AND的意思;而linux,386和darwin,!cgo之间通过空白分割来表示OR的意思。
类型映射
详见 这篇文章
| C语言类型 | CGO类型 | Go语言类型 | C语言类型 | CGO类型 | Go语言类型 |
|---|---|---|---|---|---|
| char | C.char | byte | float | C.float | float32 |
| singed char | C.schar | int8 | double | C.double | float64 |
| unsigned char | C.uchar | uint8 | size_t | C.size_t | uint |
| short | C.short | int16 | int8_t | C.int8_t | int8 |
| unsigned short | C.ushort | uint16 | uint8_t | C.uint8_t | uint8 |
| int | C.int | int32 | int16_t | C.int16_t | int16 |
| unsigned int | C.uint | uint32 | uint16_t | C.uint16_t | uint16 |
| long | C.long | int32 | int32_t | C.int32_t | int32 |
| unsigned long | C.ulong | uint32 | uint32_t | C.uint32_t | uint32 |
| long long int | C.longlong | int64 | int64_t | C.int64_t | int64 |
| unsigned long long int | C.ulonglong | uint64 | uint64_t | C.uint64_t | uint64 |
虽然在C语言中int、short等类型没有明确定义内存大小,但是在CGO中它们的内存大小是确定的
结构体
/*
struct A {
int i;
float f;
};
*/
import "C"
import "fmt"
func main() {
var a C.struct_A
fmt.Println(a.i) // 引用结构体成员
fmt.Println(a.f)
}
func CArrayToGoArray(cArray unsafe.Pointer, size int) (goArray []uint64) {
p := uintptr(cArray)
for i :=0; i < size; i++ {
j := *(*uint64)(unsafe.Pointer(p))
goArray = append(goArray, j)
p += unsafe.Sizeof(j)
}
return
}
CGO的C虚拟包提供了以下一组函数,用于Go语言和C语言之间数组和字符串的双向转换:
// Go string to C string
// The C string is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CString(string) *C.char
// Go []byte slice to C array
// The C array is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CBytes([]byte) unsafe.Pointer
// C string to Go string
func C.GoString(*C.char) string
// C data with explicit length to Go string
func C.GoStringN(*C.char, C.int) string
// C data with explicit length to Go []byte
func C.GoBytes(unsafe.Pointer, C.int) []byte
Go 中切片的使用方法类似 C 中的数组,但是内存结构并不一样。C 中的数组实际上指的是一段连续的内存,而 Go 的切片在存储数据的连续内存基础上,还有一个头结构体,其内存结构如下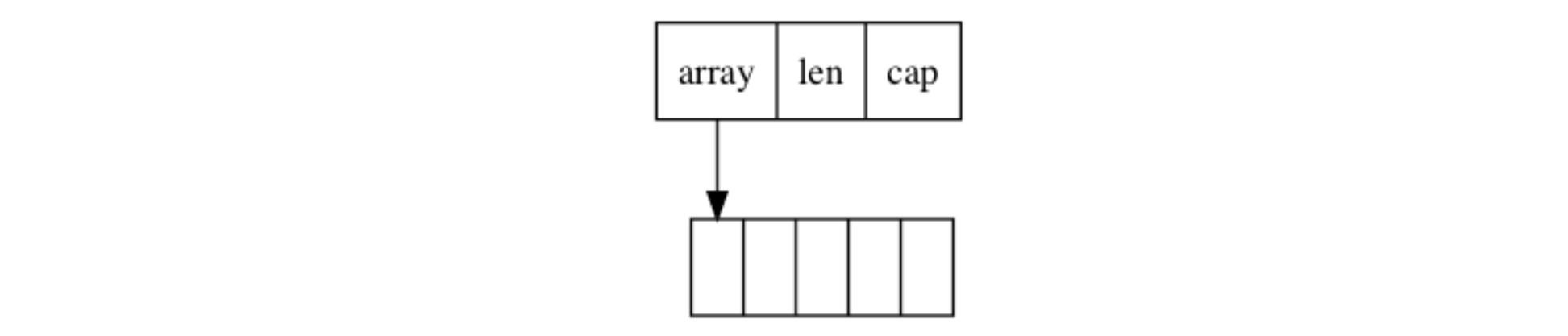
因此 Go 的切片不能直接传递给 C 使用,而是需要取切片的内部缓冲区的首地址(即首个元素的地址)来传递给 C 使用。使用这种方式把 Go 的内存空间暴露给 C 使用,可以大大减少 Go 和 C 之间参数传递时内存拷贝的消耗。
package main
/*
int SayHello(char* buff, int len) {
char hello[] = "Hello Cgo!";
int movnum = len < sizeof(hello) ? len:sizeof(hello);
memcpy(buff, hello, movnum); // go字符串没有'\0',所以直接内存拷贝, 而不是strcpy()
return movnum;
}
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
buff := make([]byte, 8)
C.SayHello((*C.char)(unsafe.Pointer(&buff[0])), C.int(len(buff)))
a := string(buff)
fmt.Println(a)
}
package main
//#cgo CFLAGS: -I./
//#cgo LDFLAGS: -L./ -ldemo
//#include <demo.h>
//#include <string.h>
import "C"
import (
"log"
"unsafe"
)
func main() {
var info = C.ai_string_t(C.CString(""))
rcode := C.ai_get_engine_info(&info)
log.Println(C.GoString(info))
log.Println(rcode)
log.Println(info)
var info2 C.ai_string_t
rcode = C.ai_get_engine_info(&info2)
log.Println(C.GoString(info2))
log.Println(rcode)
log.Println(info2)
var str = ""
strSlice := (*String)(unsafe.Pointer(&str))
strSlice.Array = unsafe.Pointer(info2)
strSlice.Len = int(C.strlen(info2))
log.Println(str)
}
type slice struct {
Array unsafe.Pointer
Len int
Cap int
}
type String struct {
Array unsafe.Pointer
Len int
}
/*
go build demo.go
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$(pwd)
./demo
*/
cgo开发通常进行的是类型、方法绑定(bindings)工作,如
https://github.com/krig/go-sox
https://github.com/u2takey/ffmpeg-go
使得开发者调用go的库不必关系so或者c的细节,完成了指针的操作
如下示例:
/*
struct A {
int i;
float f;
};
int printA(A a);
int getA(A *a);
*/
import "C"
import "fmt"
type StructA C.struct_A
func PrintA(a StructA) {
C.printA(C.struct_A(unsafe.Pointer(a)))
}
func GetA() StructA {
var out C.struct_A{}
C.getA(&out)
return *((*StructA)(unsafe.Pointer(&out)))
}
动态库和静态库
CGO在使用C/C++资源的时候一般有三种形式:
- 直接使用源码;
- 链接静态库;
- 链接动态库。
直接使用源码就是在import “C”之前的注释部分包含C代码,或者在当前包中包含C/C++源文件。
链接静态库和动态库的方式比较类似,都是通过在LDFLAGS选项指定要链接的库方式链接。
技巧
防止内存泄漏
package main
/*
#include <stdio.h>
#include <stdlib.h>
void say(const char *s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
for {
hello()
}
}
func hello() {
s := C.CString("Hello, World\n")
defer C.free(unsafe.Pointer(s))
C.say(s)
}
https://www.cnblogs.com/guochaoxxl/p/6960854.html
结构体内有指针,则需要先释放内部指针,再释放结构体,文章中能看懂内存对齐的规则
小知识,通常(部分场景go编译器会优化)string 和[]byte 之间的转化也会发生内存拷贝,因为在语义上,string内容是不可变的,slice内容是可变的。
type slice struct {
array unsafe.Pointer
len int
cap int
}
type stringStruct struct {
str unsafe.Pointer
len int
}
多lib里的同名函数
对于不同share lib中出现同名函数,如何同时使用?
背景是,当两个 so包中有同名函数,然后在cgo中引入,大概率不会出现编译错误,但是运行时就会发现,同名函数只有一个被引入了,同名抢占 github-go-issue
- excutable so(shared object) https://gcc.gnu.org/legacy-ml/gcc-help/2003-07/msg00232.html
- openld
go plugin
利用同名抢占机制,可以进行hook,详见: 基于LD_PRELOAD的动态库函数hook
如何定位内存泄漏
- c代码中的内存泄漏,依然可以使用valgrind检查。但是需要注意,像C.CString这种泄漏,valgrind无法给出泄漏的准确位置。bcc套件也内存分析的重要工具。
- go pprof无法检查c代码中的内存泄漏。
- nmap 命令可以比top看到更多内存细节信息
详见:https://zhuanlan.zhihu.com/p/368567370
go程序内存泄露问题快速定位
CoreDump捕获
core文件会包含了程序运行时的内存,寄存器状态,堆栈指针,内存管理信息还有各种函数调用堆栈信息等,我们可以理解为是程序工作当前状态存储生成第一个文件,许多的程序出错的时候都会产生一个core文件,通过工具分析这个文件,我们可以定位到程序异常退出的时候对应的堆栈调用等信息,找出问题所在并进行及时解决。
操作系统打开coredump
ulimit –c [size] , size的单位是blocks,一般1block=512bytes, size太小则不能产生core文件,如取值1,2,3
在/etc/profile中加入以下一行,这将允许生成coredump文件
ulimit-c unlimited
core文件位置:
core文件默认的存储位置与对应的可执行程序在同一目录下,文件名是core,大家可以通过下面的命令看到core文件的存在位置:
cat /proc/sys/kernel/core_pattern
缺省值是core
cgo简明教程
http://westfly.github.io/post/cpp/cgo-with-cpp/
通常是gdb工具读core文件定位错误位置
https://blog.csdn.net/tenfyguo/article/details/8159176
make教程
https://www.ruanyifeng.com/blog/2015/02/make.html
cmake教程
https://github.com/chaneyzorn/CMake-tutorial
undifiend reference to xxxxx
https://zhuanlan.zhihu.com/p/81681440
链接参数意义
https://zhuanlan.zhihu.com/p/450986377
gcc变异参数记录
https://blog.csdn.net/xiaoyan_yt/article/details/103718487
gcc编译命令简单命令
https://www.cnblogs.com/ibyte/p/5828445.html
gcc编译命令详解
https://zhuanlan.zhihu.com/p/380180101
https://getiot.tech/linux-command/gcc.html
# cmake对大小写不敏感
include_Directories(/root/include) # 添加头文件目录,多个可用空格分割,相当于g++的-I
link_directories(/root/lib /usr/lib /usr/share/lib) # 相当于g++命令的-L选项的作用,
# 也相当于环境变量中增加LD_LIBRARY_PATH的路径的作用
set(vara "Hello World") # 设置一个普通变量
set(ENV{PATH} "$ENV{PATH}:${torch_home}/bin") # 设置环境变量
# 获得一个目录的绝对路径, 内置常量CMAKE_CURRENT_SOURCE_DIR 代表 CMakeLists.txt所在目录
# CMAKE_CURRENT_BINARY_DIR 代表 cmake命令所在目录
get_filename_component(project_home "${CMAKE_CURRENT_SOURCE_DIR}/../.."
ABSOLUTE DIRECTORY)
message($ENV{PATH} ${vara}) # 相当于 println
find_package(Protobuf) # 检查Protobuf 这个库是否存在
add_library(targert_libname source1.c header1.c source2.c) # 生成 静态库
add_executable(main main.c) # 编译可执行文件
target_link_libraries(target_hello liba.so libb.a lc) # 给目标链接制定的库
target_include_directories(target_hello hello.c) # 给目标库指定的头文件
add_custom_command() # 设置一个【目标文件】的生成命令,看明白make教程会有助于理解
find_program() # 查找一个命令

若有收获,就点个赞吧
0 人点赞
