参考:
主要概念
Cluster (集群)
Cluster 是计算、存储和网络资源的集合,Kubernetes 利用这些资源运行各种基于容器的应用。
Namespace (命名空间):可以将一个物理的 Cluster 逻辑上划分成多个虚拟 Cluster,每个 Cluster 就是一个 Namespace。不同 Namespace 里的资源是完全隔离的。
https://mp.weixin.qq.com/s/DNJaeprdbXuXu4Wxgz7tbA
Master(管理节点)
Master 是 Cluster 的大脑,它的主要职责是调度,即决定将应用放在哪里运行。Master 运行 Linux 操作系统,可以是物理机或者虚拟机。为了实现高可用,可以运行多个 Master。Master中运行着如下 Daemon 服务:kube-apiserver、kube-scheduler、kube-controller-manager、etcd 和 Pod 网络(例如 flannel)
Node(工作节点)
Node 的职责是运行容器应用。Node 由 Master 管理,Node 负责监控并汇报容器的状态,并根据 Master 的要求管理容器的生命周期。Node 运行在 Linux 操作系统,可以是物理机或者是虚拟机。
Node是Kubernetes集群操作的单元,用来承载被分配Pod的运行,是Pod运行的宿主机。
Label(标签)是Kubernetes系统中另外一个核心概念。一个Label是一个key=value的键值对,其中key与
value由用户自己指定。Label可以被附加到各种资源对象上,例如Node、Pod、Service、RC等,一个资源对
象可以定义任意数量的Label,同一个Label也可以被添加到任意数量的资源对象上。Label通常在资源对象
定义时确定,也可以在对象创建后动态添加或者删除。
给某个资源对象定义一个Label,就相当于给它打了一个标签,随后可
以通过Label Selector(标签选择器)查询和筛选拥有某些Label的资源对象,Kubernetes通过这种方式实现了
类似SQL的简单又通用的对象查询机制。Label Selector可以被类比为SQL语句中的where查询条件,例如,name=redis-slave这个Label Selector作用于Pod时,可以被类比为select * from pod where pod’s name =‘redis-slave’这样的语句
Service: 定义一组pod的访问规则
核心架构
架构图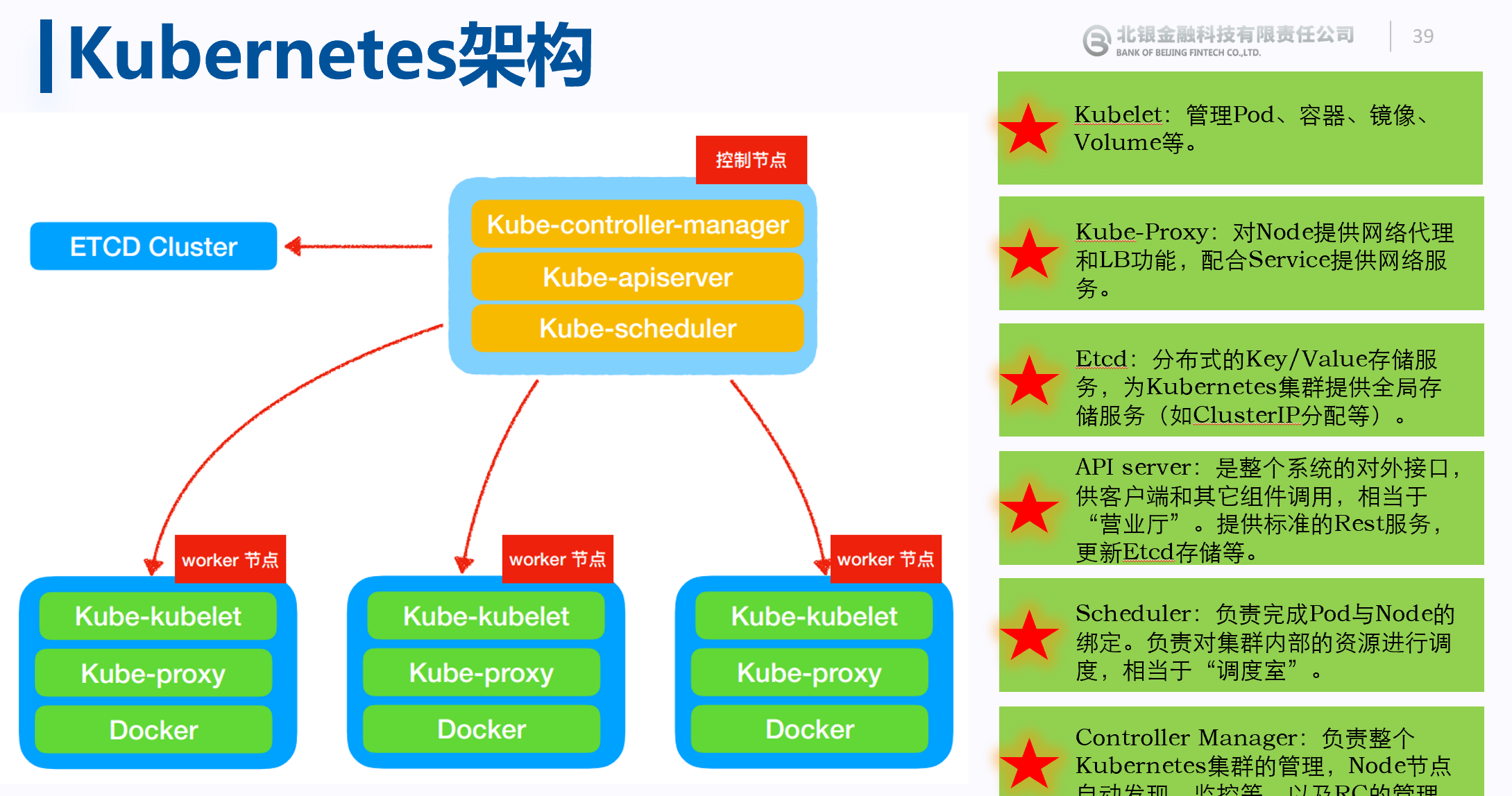
Master组件
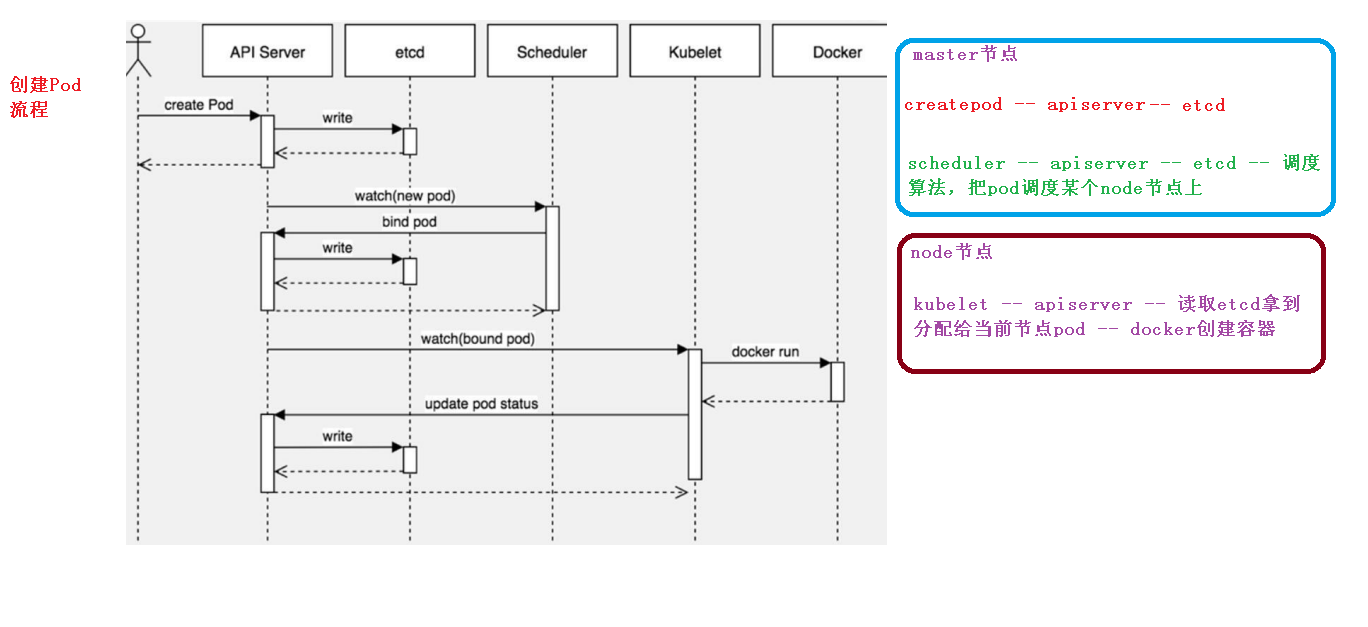
1、API Server:集群统一入口。
提供资源对象的唯一操作入口,其他组件必须通过其操作资源数据。
API Server负责接收K8S所有请求(来自UI界面或者CLI命令行工具),然后,API Server根据用户的具体请求,去通知其他组件干活。 整个Kubernetes集群的所有交互都是以API server为核心的
2、Controller Manager : 集群内部的管理控制中心,实现k8s集群的故障检测和恢复的自动化工作。
处理集群中常规后台任务,一个资源对应一个控制器
3、Scheduler: 集群中的调度器,负责Pod在集群节点中的调度分配
4、**etcd:保存集群数据**
Worker组件
1、Kubelet
维护容器的生命周期。负责本Node节点上的Pod的创建、修改、监控、删除等,同时定时同步本Node的状态信息到API Server
是Worker Node的监视器,以及与Master Node的通讯器。它会定期向Worker Node汇报自己Node上运行的服务的状态,并接受来自Master Node的指示采取调整措施。
2、kube-proxy是一个简单的网络代理和负载均衡器,它的作用主要是负责Service的实现:实现从Pod到Service,以及从NodePort向Service的访问。
运行在每个Node上的kube-proxy进程其实就是一个智能的软件负载均衡器,负责把对Service的请求转发到后端的某个Pod实例上,并在内部实现服务的负载均衡与会话保持机制
组件关系
https://mp.weixin.qq.com/s/o8-rtCnUaL0Mv8TIoEURAA
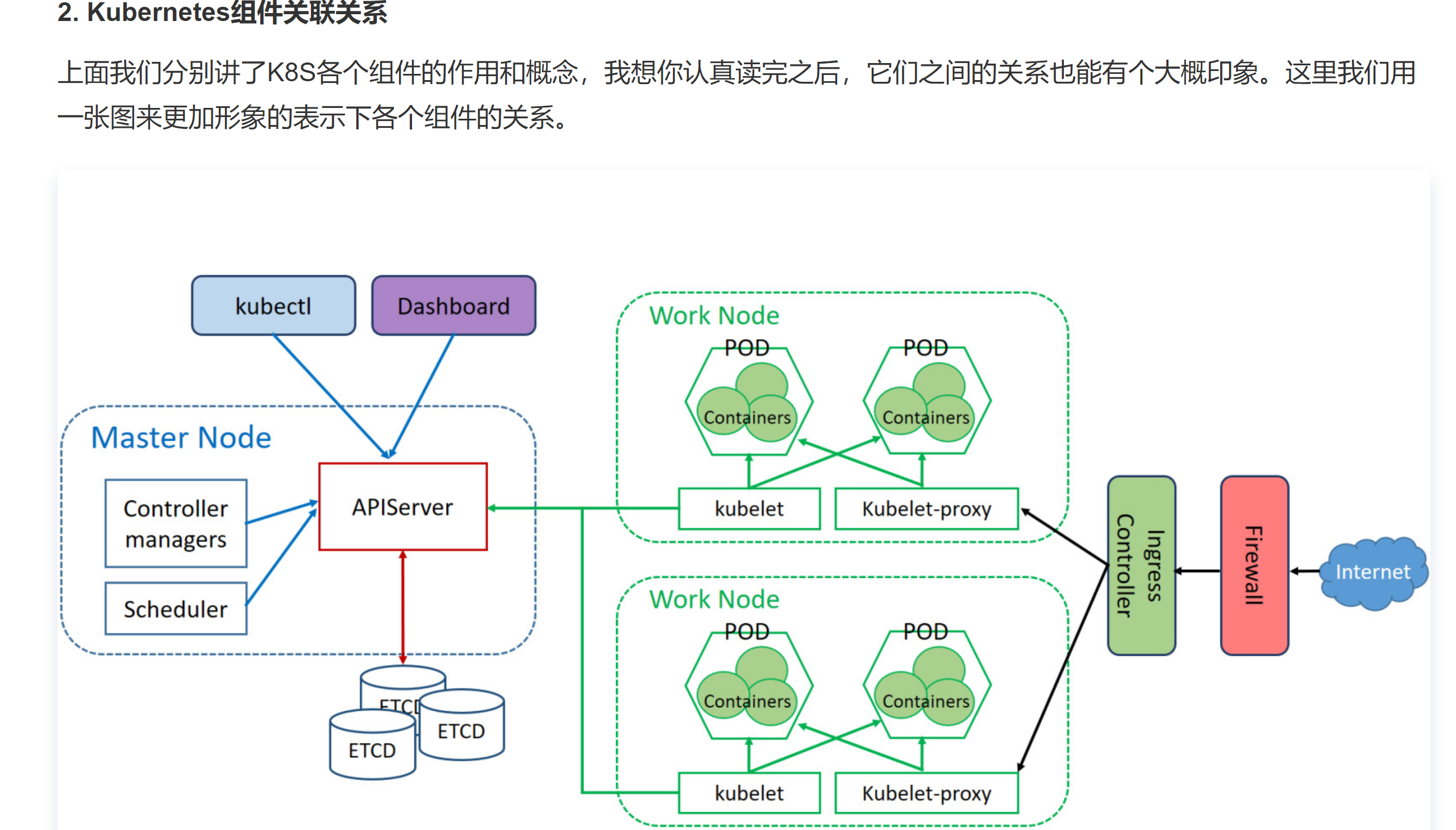
1). 首先外网进入到K8S集群要通过一道防火墙;
2). 紧接着是Ingress Controller,它负责执行ingress的转发规则,让请求转发到对应的Service上(图里直接到kubelet-proxy),Service的实现靠的是kubelet-proxy;
3). 接着kubelet-proxy把流量分发在对应的Pod上;
4). 每个work node里面都运行着关键的kubelet服务,它负责与master节点的沟通,把work节点的资源使用情况、容器状态同步给APIServer;
5). Master节点的APIServer是很重要的服务,图中我们可以看到控制器、调度、ETCD等都需要跟APIServer交互。由此可见,我们在运维K8S集群的时候,APIServer服务的稳定性要加固保障,做好HA高可用。
详见https://cloud.tencent.com/developer/article/1429218
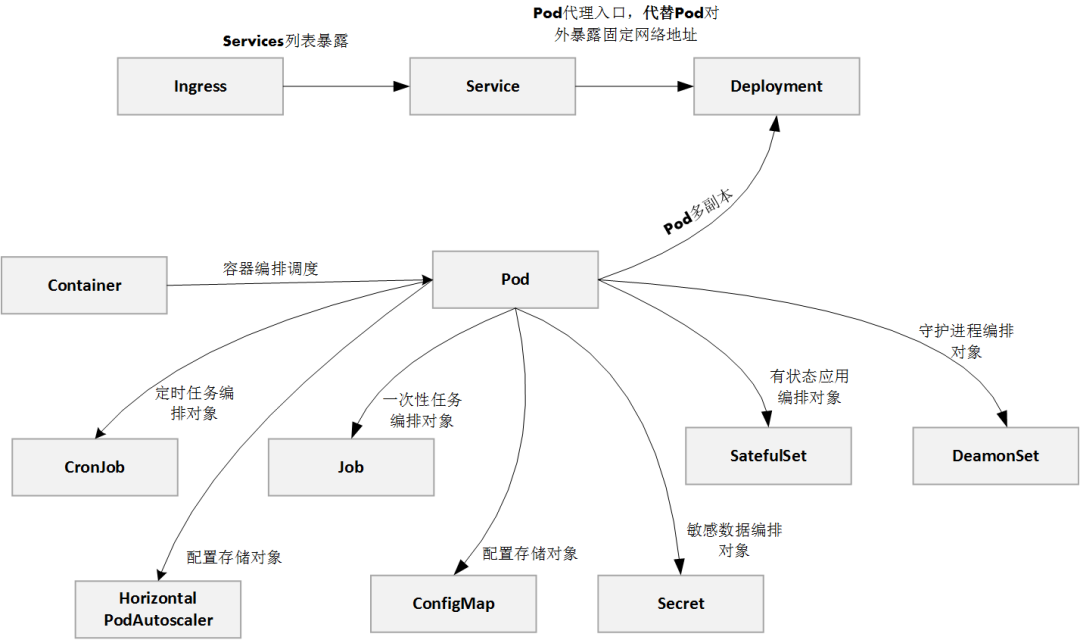
Pod及其管理
Pod基本概念
- 又称“容器组”,是K8s的最小调度单位,
- 一个Pod中可以有多个Container
- 这些Container都共享一个网卡,命名空间,共享一套TCP/IP端口和地址
- pod的生命周期短暂。
Pod存在的意义
Kubernetes 引入 Pod 主要基于下面两个目的:
1.可管理性。
有些容器天生就是需要紧密联系,一起工作。Pod 提供了比容器更高层次的抽象,将它们封装到一个部署单元中。Kubernetes 以 Pod 为最小单位进行调度、扩展、共享资源、管理生命周期。
2.通信和资源共享。(网络与存储)
Pod 中的所有容器使用同一个网络 namespace,即相同的 IP 地址和 Port 空间。
它们可以直接用 localhost 通信,**不同容器要注意不要有端口冲突即可**
同样的,这些容器可以共享存储,当 Kubernetes 挂载 volume 到 Pod,本质上是将 volume 挂载到 Pod 中的每一个容器。
容器的本质是进程。 在一个真正的操作系统里,进程并不是“孤苦伶仃”地独自运行的,而是以进程组的方式,“有原则地”组织在一起。
在 Borg 项目的开发和实践过程中,Google 公司的工程师们发现,他们部署的应用,往往都存在着类似于“进程和进程组”的关系。更具体地说,就是这些应用之间有着密切的协作关系,使得它们必须部署在同一台机器上。
例子:如果没有Pod。调度方面会出现问题。
以前面的 rsyslogd 为例子。已知 rsyslogd 由三个进程组成:一个 imklog 模块,一个 imuxsock 模块,一个 rsyslogd 自己的 main 函数主进程。这三个进程一定要运行在同一台机器上,否则,它们之间基于 Socket 的通信和文件交换,都会出现问题。
现在,我要把 rsyslogd 这个应用给容器化,由于受限于容器的“单进程模型”,这三个模块必须被分别制作成三个不同的容器。而在这三个容器运行的时候,它们设置的内存配额都是 1 GB。
顺序调度,如果机器资源不足,那么会出现“必须调度到同一个机器上”和“机器资源不足以支持三个容器”的悖论。
但是,到了 Kubernetes 项目里,这样的问题就迎刃而解了:Pod 是 Kubernetes 里的原子调度单位。这就意味着,Kubernetes 项目的调度器,是统一按照 Pod 而非容器的资源需求进行计算的。
补充:
容器的“单进程模型”,并不是指容器里只能运行“一个”进程,而是指容器没有管理多个进程的能力。这是因为容器里 PID=1 的进程就是应用本身,其他的进程都是这个 PID=1 进程的子进程。可是,用户编写的应用,并不能够像正常操作系统里的 init 进程或者 systemd 那样拥有进程管理的功能。比如,你的应用是一个 Java Web 程序(PID=1),然后你执行 docker exec 在后台启动了一个 Nginx 进程(PID=3)。可是,当这个 Nginx 进程异常退出的时候,你该怎么知道呢?这个进程退出后的垃圾收集工作,又应该由谁去做呢?
Pod生命周期和重启策略
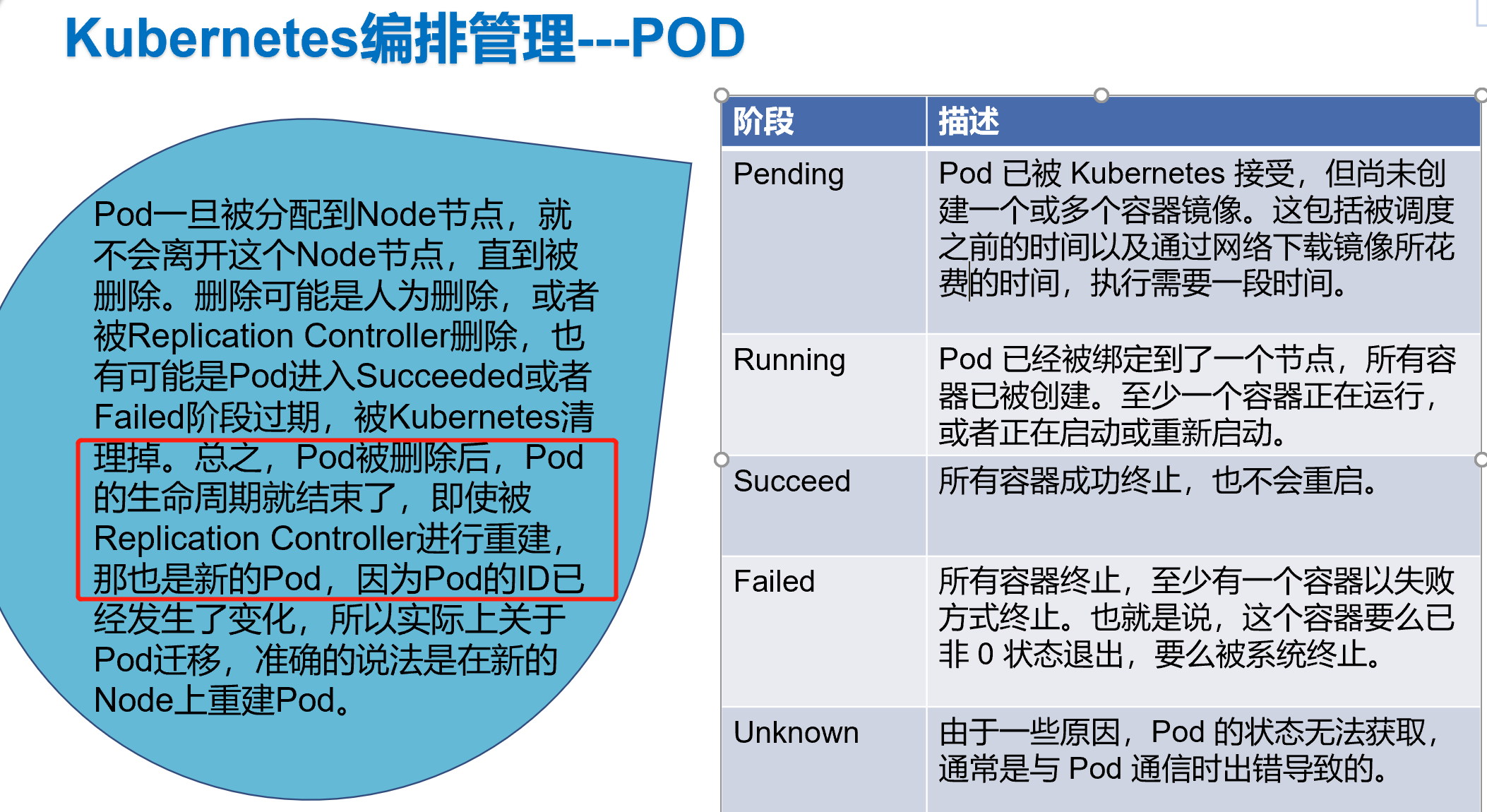
更进一步地,Pod 对象的 Status 字段,还可以再细分出一组 Conditions。这些细分状态的值包括:PodScheduled、Ready、Initialized,以及 Unschedulable。它们主要用于描述造成当前 Status 的具体原因是什么。
比如,Pod 当前的 Status 是 Pending,对应的 Condition 是 Unschedulable,这就意味着它的调度出现了问题。
而其中,Ready 这个细分状态非常值得我们关注:它意味着 Pod 不仅已经正常启动(Running 状态),而且已经可以对外提供服务了。这两者之间(Running 和 Ready)是有区别的,你不妨仔细思考一下。
Pod的重启策略包括Always、OnFailure和Never,默认值为Always。
◎ Always:当容器失效时,由kubelet自动重启该容器。
◎ OnFailure:当容器终止运行且退出码不为0时,由kubelet自动重启该容器。
◎ Never:不论容器运行状态如何,kubelet都不会重启该容器。
在实际使用时,我们需要根据应用运行的特性,合理设置这三种恢复策略。
比如,一个 Pod,它只计算 1+1=2,计算完成输出结果后退出,变成 Succeeded 状态。这时,你如果再用 restartPolicy=Always 强制重启这个 Pod 的容器,就没有任何意义了。
而如果你要关心这个容器退出后的上下文环境,比如容器退出后的日志、文件和目录,就需要将 restartPolicy 设置为 Never。因为一旦容器被自动重新创建,这些内容就有可能丢失掉了(被垃圾回收了
Kubernetes 的官方文档,把 restartPolicy 和 Pod 里容器的状态,以及 Pod 状态的对应关系,总结了非常复杂的一大堆情况。实际上,你根本不需要死记硬背这些对应关系,只要记住如下两个基本的设计原理即可:
1、只要 Pod 的 restartPolicy 指定的策略允许重启 异常的容器(比如:Always),那么这个 Pod 就会保持 Running 状态,并进行容器重启。否则,Pod 就会进入 Failed 状态 。
2、对于包含多个容器的 Pod,只有它里面所有的容器都进入异常状态后,Pod 才会进入 Failed 状态。在此之前,Pod 都是 Running 状态。此时,Pod 的 READY 字段会显示正常容器的个数
所以,假如一个 Pod 里只有一个容器,然后这个容器异常退出了。那么,只有当 restartPolicy=Never 时,这个 Pod 才会进入 Failed 状态。而其他情况下,由于 Kubernetes 都可以重启这个容器,所以 Pod 的状态保持 Running 不变。
而如果这个 Pod 有多个容器,仅有一个容器异常退出,它就始终保持 Running 状态,哪怕即使 restartPolicy=Never。只有当所有容器也异常退出之后,这个 Pod 才会进入 Failed 状态。
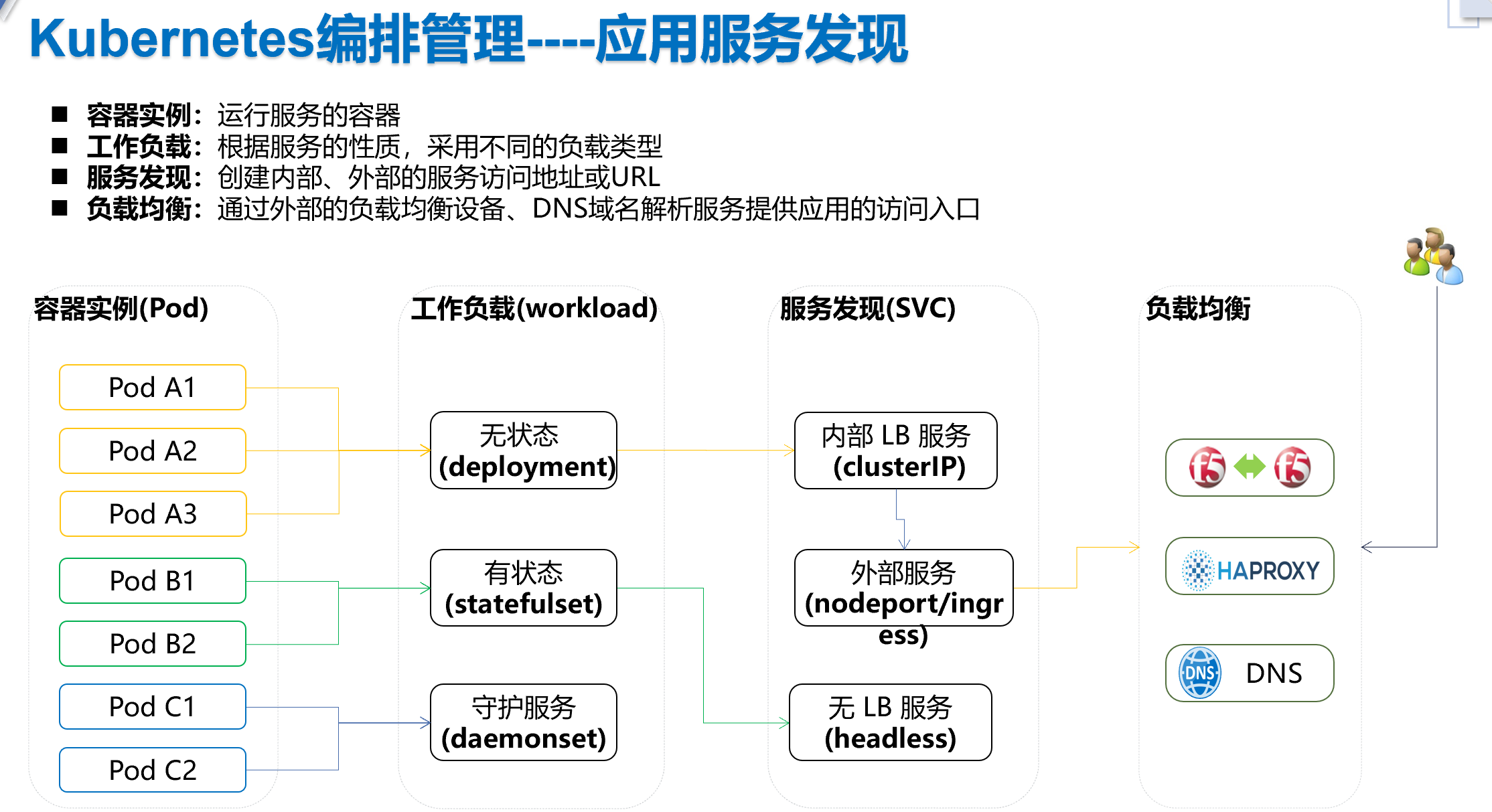
工作负载(控制器)
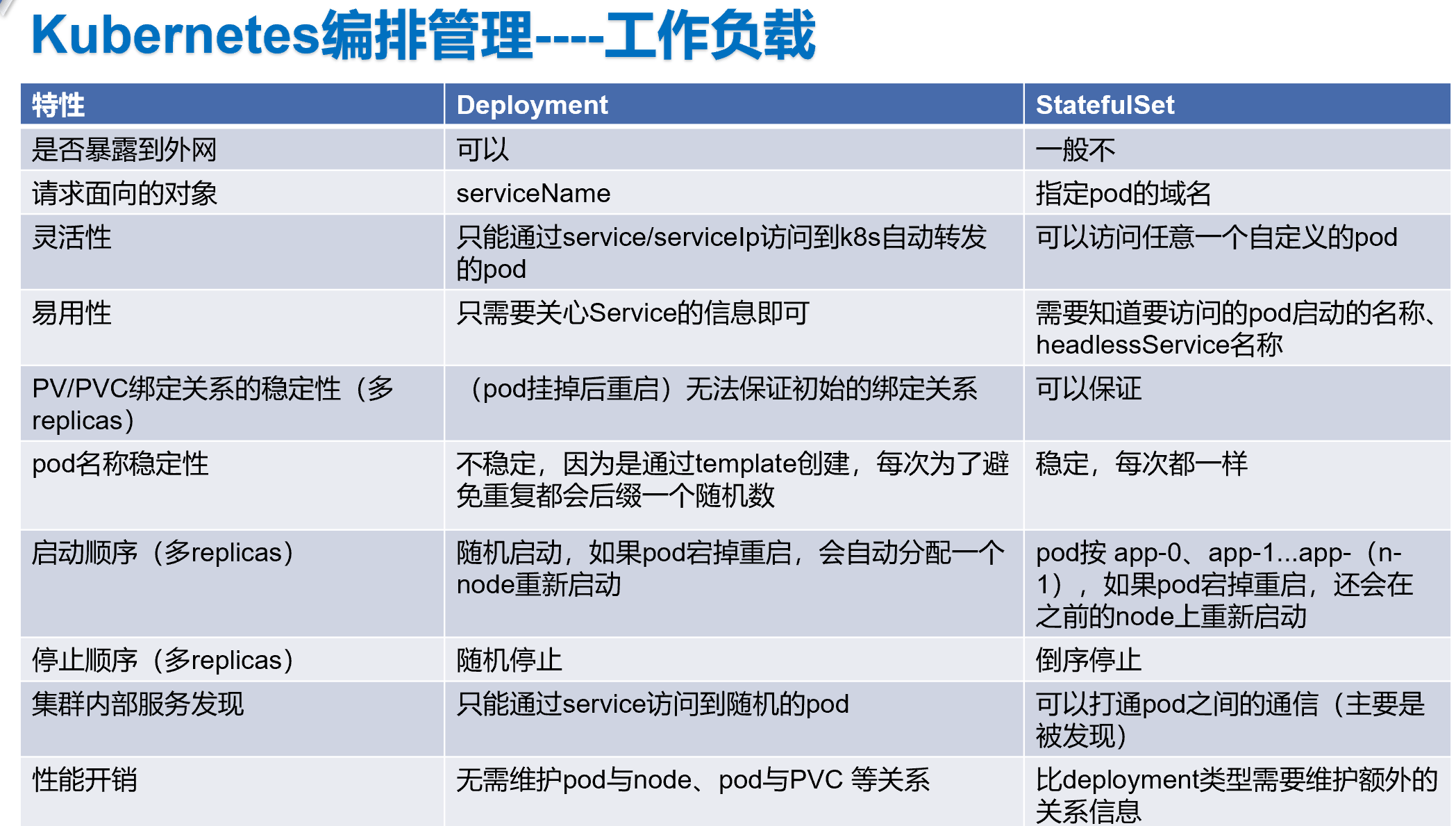
Deployment
Kubernetes 通常不会直接创建 Pod,而是通过 Controller 来完成对一组Pod副本的创建、调度及全生命周期的自动控制任务。
单Pod模式,与控制器replicas=1模式的区别
【张磊《深入剖析Kubernetes》】在实际使用 Kubernetes 的过程中,相比于编写一个单独的 Pod 的 YAML 文件,我一定会推荐你使用一个 replicas=1 的 Deployment。请问,这两者有什么区别呢?
【答案】推荐使用replica=1而不使用单独pod的主要原因是pod所在的节点出故障的时候 pod可以调度到健康的节点上,单独的pod只能在节点健康的情况下由kubelet保证pod的健康状况。
但一定要强调的是,Pod 的恢复过程,永远都是发生在当前节点上,而不会跑到别的节点上去。事实上,一旦一个 Pod 与一个节点(Node)绑定,除非这个绑定发生了变化(pod.spec.node 字段被修改),否则它永远都不会离开这个节点。这也就意味着,如果这个宿主机宕机了,这个 Pod 也不会主动迁移到其他节点上去。
像 Deployment 这种控制器的设计原理,就是我们前面提到过的,“用一种对象管理另一种对象”的“艺术”。
其中,这个控制器对象本身,负责定义被管理对象的期望状态。比如,Deployment 里的 replicas=2 这个字段。
而被控制对象的定义,则来自于一个“模板”。比如,Deployment 里的 template 字段。
像这样使用一种 API 对象(Deployment)管理另一种 API 对象(Pod)的方法,在 Kubernetes 中,叫作“控制器”模式(controller pattern)。
类似 Deployment 这样的一个控制器,实际上都是由上半部分的控制器定义(包括期望状态),加上下半部分的被控制对象的模板组成的。

创建YAML文件
apiVersion: apps/v1kind: Deploymentmetadata:name: nginx-deploymentspec:selector:matchLabels:app: nginxreplicas: 2template:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:1.8ports:- containerPort: 80volumeMounts:- mountPath: "/usr/share/nginx/html"name: nginx-volvolumes:- name: nginx-volemptyDir: {}
在 Metadata 中,还有一个与 Labels 格式、层级完全相同的字段叫 Annotations,它专门用来携带 key-value 格式的内部信息。所谓内部信息,指的是对这些信息感兴趣的,是 Kubernetes 组件本身,而不是用户。所以大多数 Annotations,都是在 Kubernetes 运行过程中,被自动加在这个 API 对象上。
快速创建kubectl create deployment <app> --image=... --dry-run -o yaml > xxx.yamlkubectl apply -f xxx.yaml
Deployment与ReplicaSet的关系: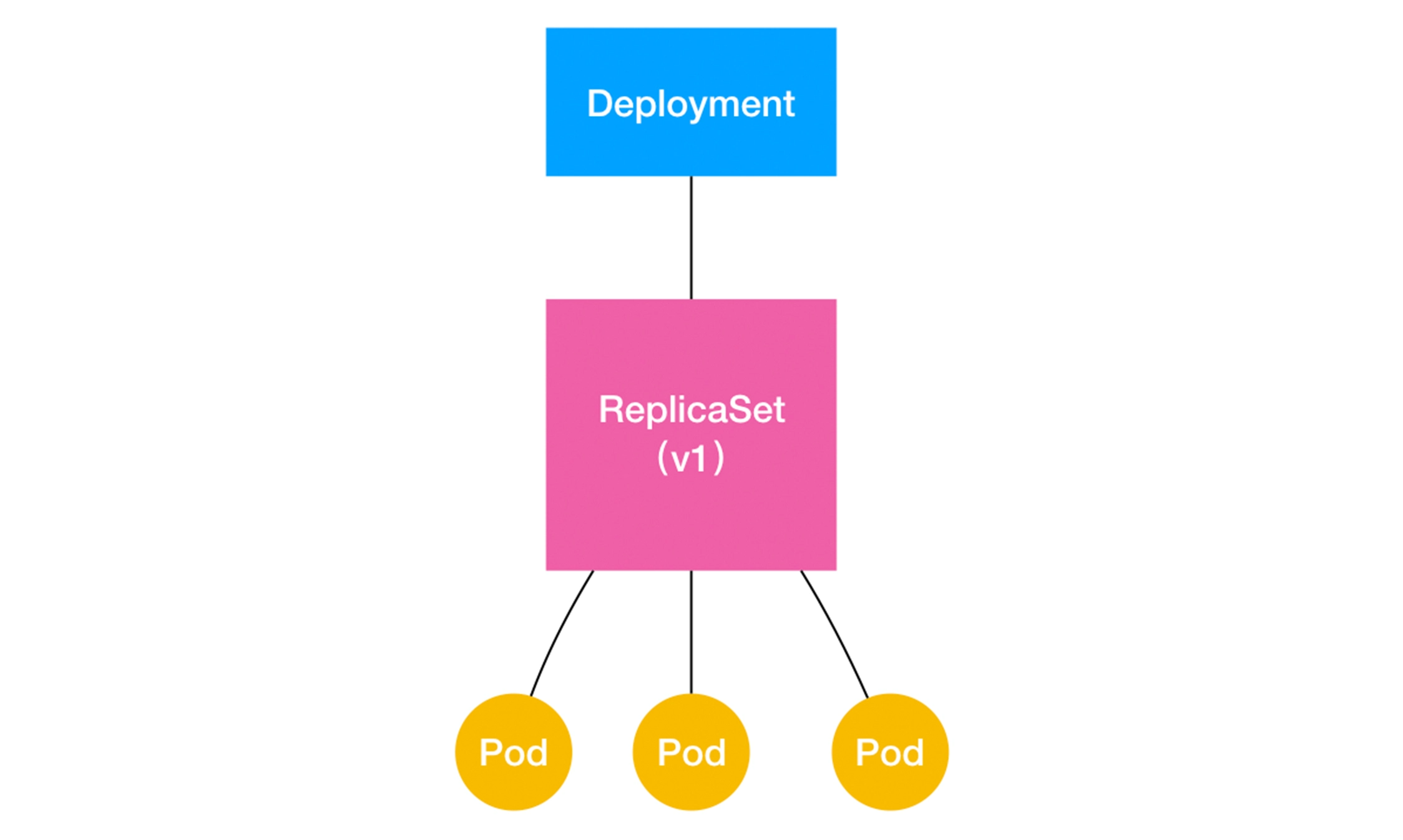
通过这张图,我们就很清楚地看到,一个定义了 replicas=3 的 Deployment,与它的 ReplicaSet,以及 Pod 的关系,实际上是一种“层层控制”的关系。其中,ReplicaSet 负责通过“控制器模式”,保证系统中 Pod 的个数永远等于指定的个数(比如,3 个)。
这也正是 Deployment 只允许容器的 restartPolicy=Always 的主要原因:只有在容器能保证自己始终是 Running 状态的前提下,ReplicaSet 调整 Pod 的个数才有意义。
水平扩缩
Deployment 通过“控制器模式”,来操作 ReplicaSet 的个数和属性,进而实现“水平扩展 / 收缩”和“滚动更新”这两个编排动作。
其中,“水平扩展 / 收缩”非常容易实现,Deployment Controller 只需要修改它所控制的 ReplicaSet 的 Pod 副本个数就可以了。
滚动更新
$ kubectl get deploymentsNAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGEnginx-deployment 3 0 0 0 1s
在返回结果中,我们可以看到四个状态字段,它们的含义如下所示。
1、DESIRED:用户期望的 Pod 副本个数(spec.replicas 的值);
2、CURRENT:当前处于 Running 状态的 Pod 的个数;
3、UP-TO-DATE:当前处于最新版本的 Pod 的个数,所谓最新版本指的是 Pod 的 Spec 部分与 Deployment 里 Pod 模板里定义的完全一致;
4、AVAILABLE:当前已经可用的 Pod 的个数,即:既是 Running 状态,又是最新版本,并且已经处于 Ready(健康检查正确)状态的 Pod 的个数。
可以看到,只有这个 AVAILABLE 字段,描述的才是用户所期望的最终状态。
实时查看变化:
$ kubectl rollout status deployment/nginx-deploymentWaiting for rollout to finish: 2 out of 3 new replicas have been updated...deployment.apps/nginx-deployment successfully rolled out
$ kubectl get deploymentsNAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGEnginx-deployment 3 3 3 3 20s#这个 ReplicaSet 的名字,则是由 Deployment 的名字和一个随机字符串共同组成。$ kubectl get rsNAME DESIRED CURRENT READY AGEnginx-deployment-3167673210 3 3 3 20s
kubectl edit deployment/xxx
直接使用 kubectl edit 指令编辑 Etcd 里的 API 对象。
$ kubectl edit deployment/nginx-deployment...spec:containers:- name: nginximage: nginx:1.9.1 # 1.7.9 -> 1.9.1ports:- containerPort: 80...deployment.extensions/nginx-deployment edited
查看Events,看到这个“滚动更新”的流程
$ kubectl describe deployment nginx-deployment...Events:Type Reason Age From Message---- ------ ---- ---- -------...Normal ScalingReplicaSet 24s deployment-controller Scaled up replica set nginx-deployment-1764197365 to 1Normal ScalingReplicaSet 22s deployment-controller Scaled down replica set nginx-deployment-3167673210 to 2Normal ScalingReplicaSet 22s deployment-controller Scaled up replica set nginx-deployment-1764197365 to 2Normal ScalingReplicaSet 19s deployment-controller Scaled down replica set nginx-deployment-3167673210 to 1Normal ScalingReplicaSet 19s deployment-controller Scaled up replica set nginx-deployment-1764197365 to 3Normal ScalingReplicaSet 14s deployment-controller Scaled down replica set nginx-deployment-3167673210 to 0在 Age=24 s 的位置,Deployment Controller开始将这个新的 ReplicaSet 所控制的 Pod 副本数从 0 个变成 1 个,即:“水平扩展”出一个副本。紧接着,在 Age=22 s 的位置,Deployment Controller 又将旧的 ReplicaSet(hash=3167673210)所控制的旧 Pod 副本数减少一个,即:“水平收缩”成两个副本。如此交替进行#这个“滚动更新”过程完成之后,你可以查看一下新、旧两个 ReplicaSet 的最终状态$ kubectl get rsNAME DESIRED CURRENT READY AGEnginx-deployment-1764197365 3 3 3 6snginx-deployment-3167673210 0 0 0 30s
将一个集群中正在运行的多个 Pod 版本,交替地逐一升级的过程,就是“滚动更新”
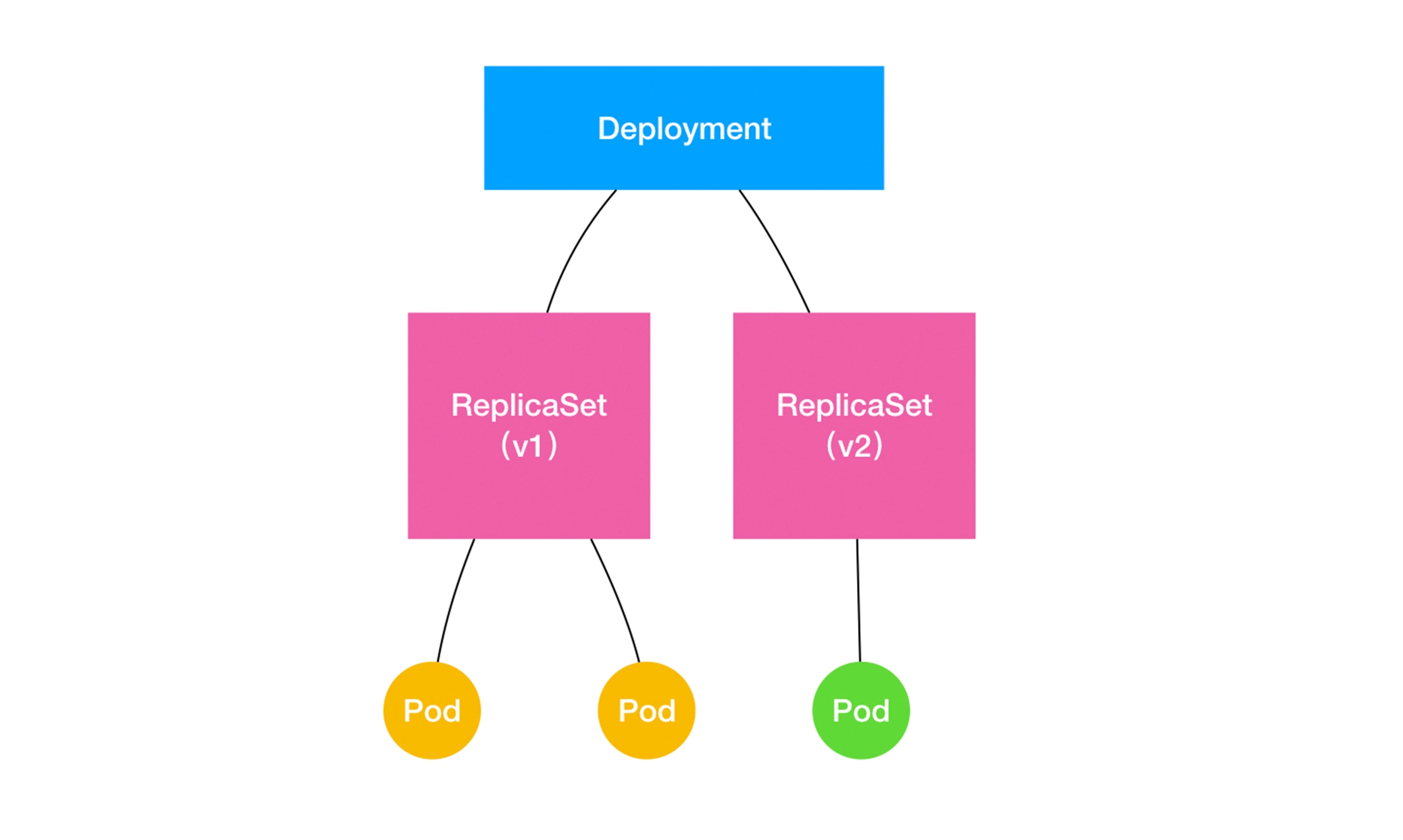
Deployment 实际上是一个两层控制器。首先,它通过 ReplicaSet 的个数来描述应用的版本;然后,它再通过 ReplicaSet 的属性(比如 replicas 的值),来保证 Pod 的副本数量。
备注:Deployment 控制 ReplicaSet(版本),ReplicaSet 控制 Pod(副本数)。这个两层控制关系一定要牢记。
回滚-undo
如果新升级的镜像有问题,可以进行回滚操作。
#回滚到上一个版本$ kubectl rollout undo deployment/nginx-deploymentdeployment.extensions/nginx-deployment#如何回滚到更早之前的版本?#1、首先kubectl rollout history查看每次 Deployment 变更对应的版本$ kubectl rollout history deployment/nginx-deploymentdeployments "nginx-deployment"REVISION CHANGE-CAUSE1 kubectl create -f nginx-deployment.yaml --record2 kubectl edit deployment/nginx-deployment3 kubectl set image deployment/nginx-deployment nginx=nginx:1.91#2、指定要回滚到的版本$ kubectl rollout undo deployment/nginx-deployment --to-revision=2deployment.extensions/nginx-deployment
StatefulSet
对于ZooKeeper、Elasticsearch、MongoDB、Kafka等有状态集群,虽然集群
中的每个Worker节点看起来都是相同的,但每个Worker节点都必须有明确的、不变的唯一ID(主机名或IP
地址),这些节点的启动和停止次序通常有严格的顺序。此外,由于集群需要持久化保存状态数据,所以
集群中的Worker节点对应的Pod不管在哪个Node上恢复,都需要挂载原来的Volume,因此这些Pod还需要捆
绑具体的PV。针对这种复杂的需求,Kubernetes提供了StatefulSet这种特殊的副本控制器来解决问题
它有如下特性。
◎ StatefulSet里的每个Pod都有稳定、唯一的网络标识,可以用来发现集群内的其他成员。假设
StatefulSet的名称为kafka,那么第1个Pod叫kafka-0,第2个叫kafka-1,以此类推。
◎ StatefulSet控制的Pod副本的启停顺序是受控的,操作第n个Pod时,前n-1个Pod已经是运行且准备
好的状态。
◎ StatefulSet里的Pod采用稳定的持久化存储卷,通过PV或PVC来实现,删除Pod时默认不会删除与
StatefulSet相关的存储卷(为了保证数据的安全)。
StatefulSet除了要与PV卷捆绑使用以存储Pod的状态数据,还要与Headless Service配合使用,即在每个
StatefulSet定义中都要声明它属于哪个Headless Service。
其他类型
DaemonSet
在每个Node上调度并且仅仅创建一个Pod副本。这种调度通常用于系统监控相关的Pod,比如主机
上的日志采集、主机性能采集等进程需要被部署到集群中的每个节点,并且只能部署一个副本,这就是
DaemonSet这种特殊Pod副本控制器所解决的问题

Pod调度
pod创建过程
NodeSelector
Kubernetes Master上的Scheduler服务(kube-scheduler进程)负责实现Pod的调度,整个调度过程通过执行一系列复杂的算法,最终为每个Pod都计算出一个最佳的目标节点,这一过程是自动完成的,通常我们无法知道Pod最终会被调度到哪个节点上。在实际情况下,也可能需要将Pod调度到指定的一些Node上,可以通过Node的标签(Label)和Pod的nodeSelector属性相匹配,来达到上述目的
例如:
首先给node打标签:kubectl label node <node_name> <key=value>
查看:kubectl get nodes <node_name> --show-labels
在工作负载的yaml文件中对pod进行设置:spec.nodeSelector: <key>:<value>
亲和性Affinity
NodeAffinity:Node亲和性调度
◎RequiredDuringSchedulingIgnoredDuringExecution:必须满足指定的规则才可以调度Pod到Node上
(功能与nodeSelector很像,但是使用的是不同的语法),相当于硬限制。
◎PreferredDuringSchedulingIgnoredDuringExecution:强调优先满足指定规则,调度器会尝试调度Pod
到Node上,但并不强求,相当于软限制。多个优先级规则还可以设置权重(weight)值,以定义执行的先
后顺序。
NodeAffinity规则设置的注意事项如下。
◎ 如果同时定义了nodeSelector和nodeAffinity,那么必须两个条件都得到满足,Pod才能最终运行在
指定的Node上。
◎ 如果nodeAffinity指定了多个nodeSelectorTerms,那么其中一个能够匹配成功即可。
◎ 如果在nodeSelectorTerms中有多个matchExpressions,则一个节点必须满足所有matchExpressions才
能运行该Pod。
PodAffinity:Pod亲和与互斥调度策略
根据在节点上正在运行的Pod的标签而不是节点的标签进行判断和调度,要求对节点和Pod两个条
件进行匹配。这种规则可以描述为:如果在具有标签X的Node上运行了一个或者多个符合条件Y的Pod,那
么Pod应该(如果是互斥的情况,那么就变成拒绝)运行在这个Node上。
首先创建参照目标Pod
创建一个名为pod-flag的Pod,带有标签security=S1和app=nginx,后面的例子将使用pod-flag作为
Pod亲和与互斥的目标Pod:
lables:security: "S1"app: "nginx"
然后 创建第2个Pod来说明Pod的亲和性调度
affinity:podAffinity:requiredDuringSechedulingIgnoreDuringExecution:- labelSelector:matchExpressions:- key: securityoperation: Invalues:- S1topologyKey: kubernetes.io/hostname
污点Taint
污点与污点容忍:Taint和toleration
Taint:Node中的设置。使得一般情况下,pod被拒绝调度到当前主机上(除非pod进行toleraion设置)。
污点值:
NoSechedule:一定不被调度(pod没有声明toteration时)
PreferNoSchedule:尽量避免调度pod(pod没有声明toteration时)
NoExecute:一定不会调度,并且 会驱逐Node上已有的Pod(多用于节点故障、下线)
命令:
查看某节点的污点设置情况:kubectl **describe node** <node_name> | **grep Taint **
设置污点:kubectl **taint nodes <node_name> key=value:[NoSechedule]**
删除污点:kubectl taint nodes <node_name> **key:[NoSechedule]-**
Toleration:Pod中的设置。设置后,pod有机会(“忍受”node中的“污点”taint从而有可能)(而非必定会)调度到有taint的主机上。
使用场景:
- 独占节点:如果想要拿出一部分节点专门给一些特定应用使用,则可以为节点添加这样的Taint
- 具有特殊硬件设备的节点
在集群里可能有一小部分节点安装了特殊的硬件设备(如GPU芯片),用户自然会希望把不需要占用
这类硬件的Pod排除在外,以确保对这类硬件有需求的Pod能够被顺利调度到这些节点。
- 定义Pod驱逐行为,以应对节点故障
《Kubernetes 污点与容忍详解》
https://mp.weixin.qq.com/s/vUSk5ROk9xaxSmxchjjbrg
资源管理
为了避免系统挂掉,该Node会选择“清理”某些Pod来释放资源,此时每个Pod都可能成为牺牲品。但有
些Pod担负着更重要的职责,比其他Pod更重要,比如与数据存储相关的、与登录相关的、与查询余额相关
的,即使系统资源严重不足,也需要保障这些Pod的存活,Kubernetes中该保障机制的核心如下。
◎ 通过资源限额来确保不同的Pod只能占用指定的资源。
◎ 允许集群的资源被超额分配,以提高集群的资源利用率。
◎ 为Pod划分等级,确保不同等级的Pod有不同的服务质量(QoS),资源不足时,低等级的Pod会被
清理,以确保高等级的Pod稳定运行。
CPU与Memory是被Pod使用的,因此在配置Pod时可以通过参数CPU Request及Memory Request为其中
的每个容器指定所需使用的CPU与Memory量,Kubernetes会根据Request的值去查找有足够资源的Node来调
度此Pod,如果没有,则调度失败。
spec.containers[].resources.limits.cpuspec.containers[].resources.limits.memoryspec.containers[].resources.requests.cpuspec.containers[].resources.requests.memory
对于Memory这种不可压缩资源来说,它的Limit设置
就是一个问题了,如果设置得小了,当进程在业务繁忙期试图请求超过Limit限制的Memory时,此进程就会
被Kubernetes杀掉。
健康检查
Kubernetes 对 Pod 的健康状态可以通过两类探针来检查:LivenessProbe 和ReadinessProbe,kubelet定期
执行这两类探针来诊断容器的健康状况。
(1)LivenessProbe探针:用于判断容器是否存活(Running状态),如果LivenessProbe探针探测到容器
不健康,则kubelet将杀掉该容器,并根据容器的重启策略做相应的处理。如果一个容器不包含
LivenessProbe探针,那么kubelet认为该容器的LivenessProbe探针返回的值永远是Success。
(2)ReadinessProbe探针:用于判断容器服务是否可用(Ready状态),达到Ready状态的Pod才可以接
收请求。如果在运行过程中Ready状态变为False,则系统自动将其从Service的后端Endpoint列表中隔离出去,这样就能保证客户端在访问Service时不会被转发到服务不可用的Pod实例上。
LivenessProbe和ReadinessProbe均可配置以下三种实现方式。
(1)ExecAction:在容器内部执行一个命令,如果该命令的返回码为0,则表明容器健康
(2)TCPSocketAction:通过容器的IP地址和端口号执行TCP检查,如果能够建立TCP连接,则表明容
器健康。在下面的例子中,通过与容器内的localhost:80建立TCP连接进行健康检查
livenessProbe:tcpSocket:port: 80initialDelaySeconds: 30timeoutSeconds: 1
(3)HTTPGetAction:通过容器的IP地址、端口号及路径调用HTTP Get方法,如果响应的状态码大于
等于200且小于400,则认为容器健康。
关键指标
initialDelaySeconds:启动容器后进行首次健康检查的等待时间timeoutSeconds:健康检查发送请求后等待响应的超时时间,单位为s。当超时发生时,kubelet会认为容器已经无法提供服务,将会重启该容器。
例子:来自官网
apiVersion: v1kind: Podmetadata:labels:test: livenessname: test-liveness-execspec:containers:- name: livenessimage: busyboxargs:- /bin/sh- -c- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600livenessProbe:exec:command:- cat- /tmp/healthyinitialDelaySeconds: 5periodSeconds: 5
在这个 Pod 中,我们定义了一个有趣的容器。它在启动之后做的第一件事,就是在 /tmp 目录下创建了一个 healthy 文件,以此作为自己已经正常运行的标志。而 30 s 过后,它会把这个文件删除掉。
与此同时,我们定义了一个这样的 livenessProbe(健康检查)。它的类型是 exec,这意味着,它会在容器启动后,在容器里面执行一条我们指定的命令,比如:“cat /tmp/healthy”。这时,如果这个文件存在,这条命令的返回值就是 0,Pod 就会认为这个容器不仅已经启动,而且是健康的。这个健康检查,在容器启动 5 s 后开始执行(initialDelaySeconds: 5),每 5 s 执行一次(periodSeconds: 5)。
Service服务发现
参考:
《学练结合,快速掌握Kubernetes Service》
https://mp.weixin.qq.com/s/VJIwipm5lR62uAPVkiUXWQ
主要功能
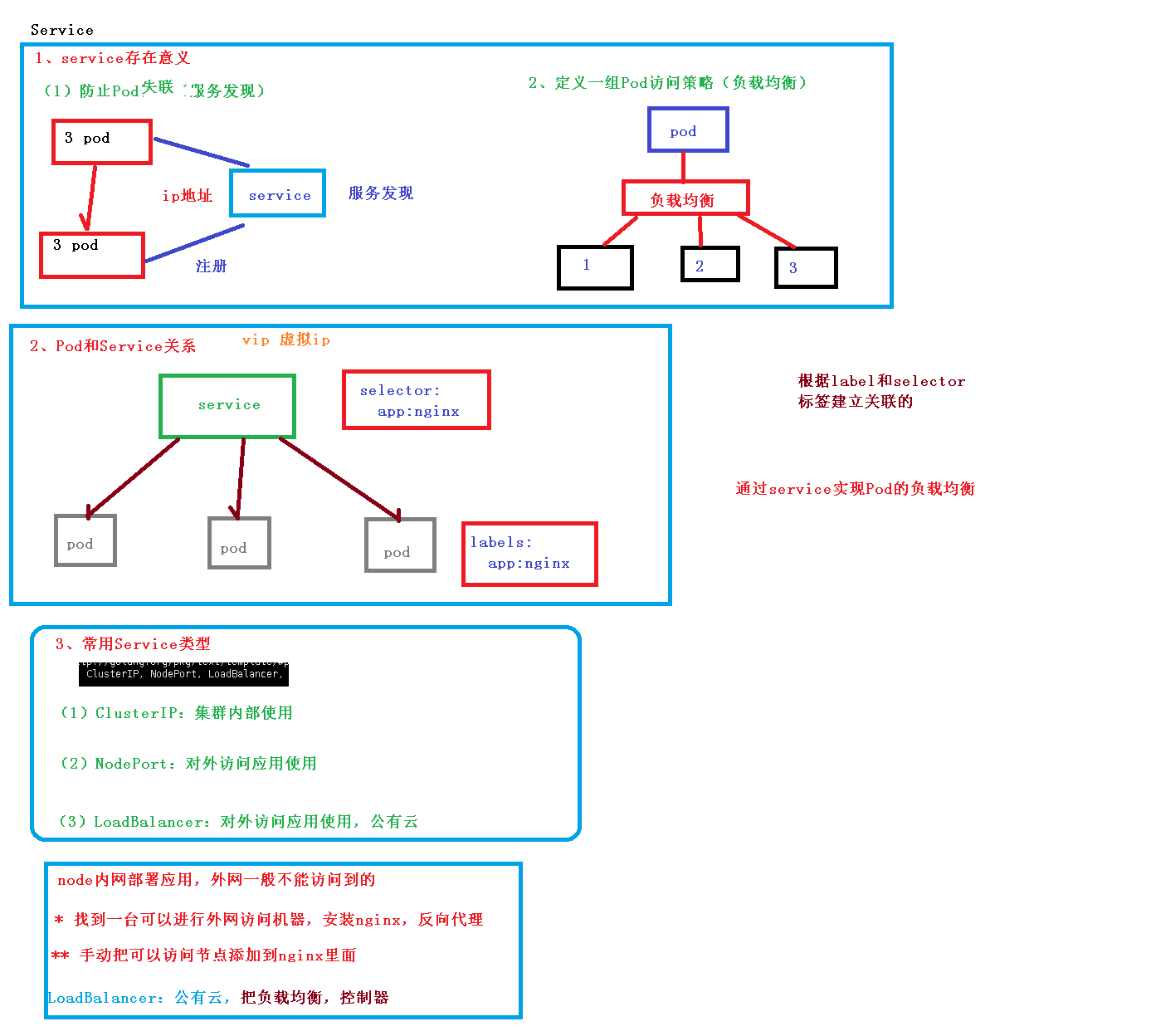
1、服务发现
Pod的Endpoint地址会随着Pod的销毁和重新创建而发生改变,因为新Pod的IP地址与之前旧
Pod的不同。而Service一旦被创建,Kubernetes就会自动(也可手动设置)为它分配一个可用的Cluster IP,而且在Service的整个生命周期内,它的Cluster IP不会发生改变。于是,服务发现这个棘手的问题在Kubernetes的架构里也得以轻松解决:只要用Service的Name与Service的Cluster IP地址做一个DNS域名映射即可完美解决问题。Service通过Label Selector选择提供服务的Pod
2、负载均衡
目前Kubernetes提供了两种负载分发策略:RoundRobin和SessionAffinity
RoundRobin:轮询模式,即轮询将请求转发到后端的各个Pod上。
SessionAffinity:基于客户端IP地址进行会话保持的模式,即第1次将某个客户端发起的请求转发到
后端的某个Pod上,之后从相同的客户端发起的请求都将被转发到后端相同的Pod上。
补充:
Endpoint概念:
Pod的IP加上容器端口(containerPort),组成了一个新的
概念—Endpoint,它代表此Pod里的一个服务进程的对外通信地址。一个Pod也存在具有多个Endpoint的情
况,比如当我们把Tomcat定义为一个Pod时,可以对外暴露管理端口与服务端口这两个Endpoint
**kubectl get endpoints <app-service>**kubectl get ep **<app-service>**

创建方式
1、命令行快速创建
根据已有的pod或deployment来创建服务发现。**kubectl expose**
主要参数:port,
2、YAML文件创建
targetPort属性用来确定提供该服务的容器所暴露(EXPOSE)的端口号,即具体
业务进程在容器内的targetPort上提供TCP/IP接入
port属性则定义了Service的虚端口。如果没有指定targetPort,则默认targetPort与port相同
服务发现类型
ClusterIP
1、ClusterIP是Kubernetes默认的服务类型。如果用户在集群内部创建一个服务,
则在集群内部的其他应用程序可以对这个服务进行访问,但是不具备集群外部访问的能力。
每个Service都被分配了一个全局唯一的虚拟IP地址,这个虚拟IP被称为Cluster IP。
这样一来,每个服务就变成了具备唯一IP地址的通信节点,服务调用就变成了最基础的TCP网络通信问题。
$ nslookup app-service.default.svc.cluster.localServer: 10.96.0.10Address: 10.96.0.10:53Name: app-service.default.svc.cluster.localAddress: 10.108.26.155
NodePort
2、NodePort服务是外部访问服务的最基本方式。
NodePort就是在所有节点或者虚拟机上开放特定的端口,该端口的流量将被转发到对应的服务。
注意:可以使用的范围端口为30000~32767。
NodePort的实现方式是在Kubernetes集群里的每个Node上都为需要外部访问的Service开启一个对应的
TCP监听端口,外部系统只要用任意一个Node的IP地址+具体的NodePort端口号即可访问此服务。
在任意Node上运行netstat命令,就可以看到有NodePort端口被监听netstat -atlp | grep 31002
Headless Service
某些需求:
希望自己控制负载均衡策略;
各个pod间需要通信;
实现方式:Headless,没有服务IP
代码块:clusterIP: None
常见场景:StatefulSet有状态应用。如pod有主从关系
参考有状态应用的部署相关文章。
完整部署过程
1、制作镜像
写代码,打包,编写Dockerfile,制作镜像(Docker环境,或流水线中)docker build -t 镜像名 .
测试:docker run
2、推送镜像
3、部署
创建配置项、PVC;
创建工作负载;
创建服务发现
Helm-Chart
随着容器技术逐渐被企业接受,在Kubernetes上已经能便捷地部署简单的应用了。但对于复杂的应用中
间件,在Kubernetes上进行容器化部署并非易事,通常需要先研究Docker镜像的运行需求、环境变量等内
容,并能为这些容器定制存储、网络等设置,最后设计和编写Deployment、ConfigMap、Service及Ingress等
相关YAML配置文件,再提交给Kubernetes部署。这些复杂的过程将逐步被Helm应用包管理工具实现。
Kubernetes应用包管理工具,Helm以Chart的方式对应用软件进行描述,可以方便地创建、版本化、共享和发布复杂的应用软件。
Chart:一个Helm包,其中包含运行一个应用所需要的工具和资源定义
Release:在Kubernetes集群上运行的一个Chart实例。在同一个集群上,一个Chart可以被安装多次。
Repository:用于存放和共享Chart仓库
简单来说,Helm整个系统的主要任务就是,在仓库中查找需要的Chart,然后将Chart以Release的形式安
装到Kubernetes集群中
概述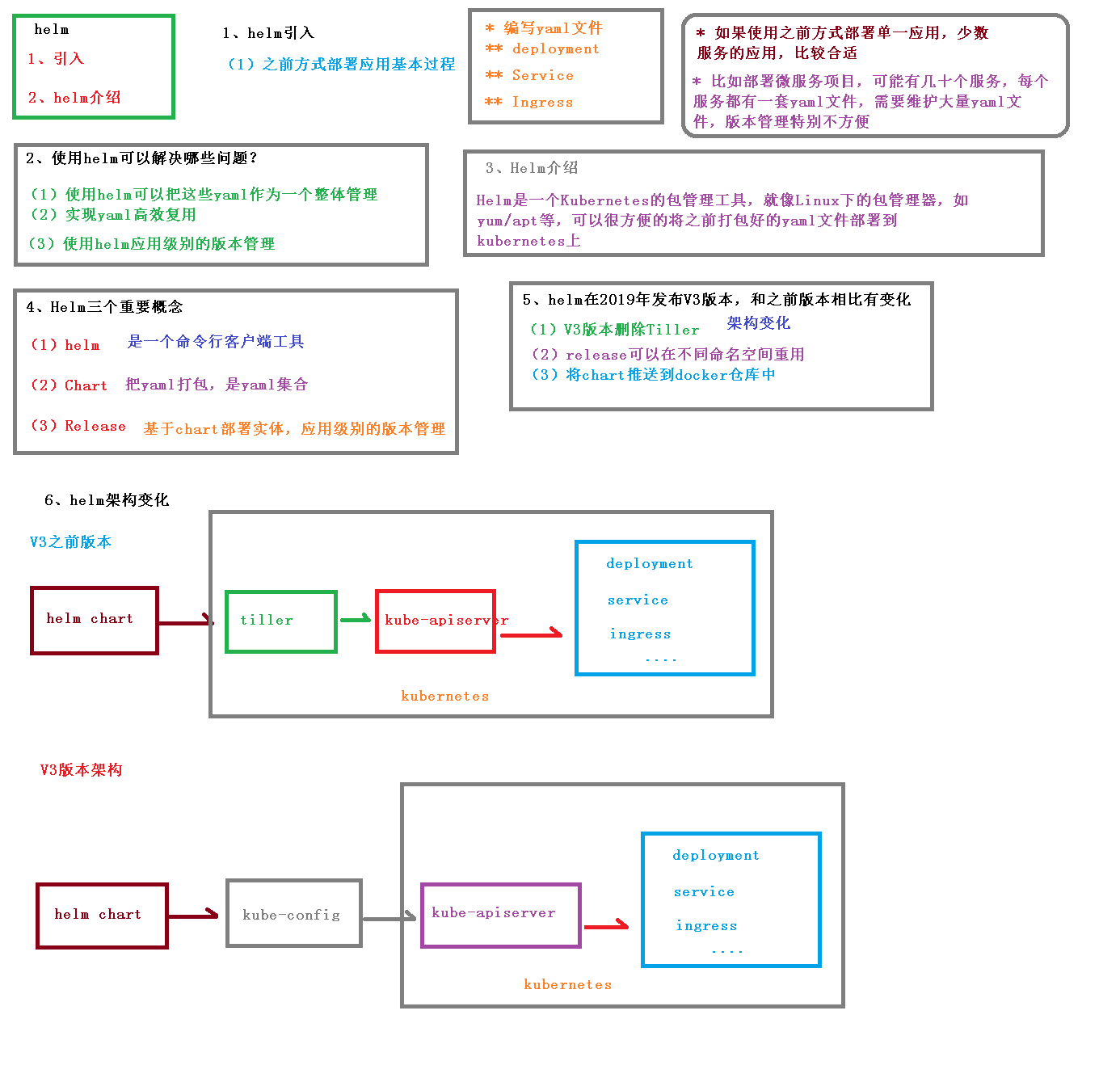
快速部署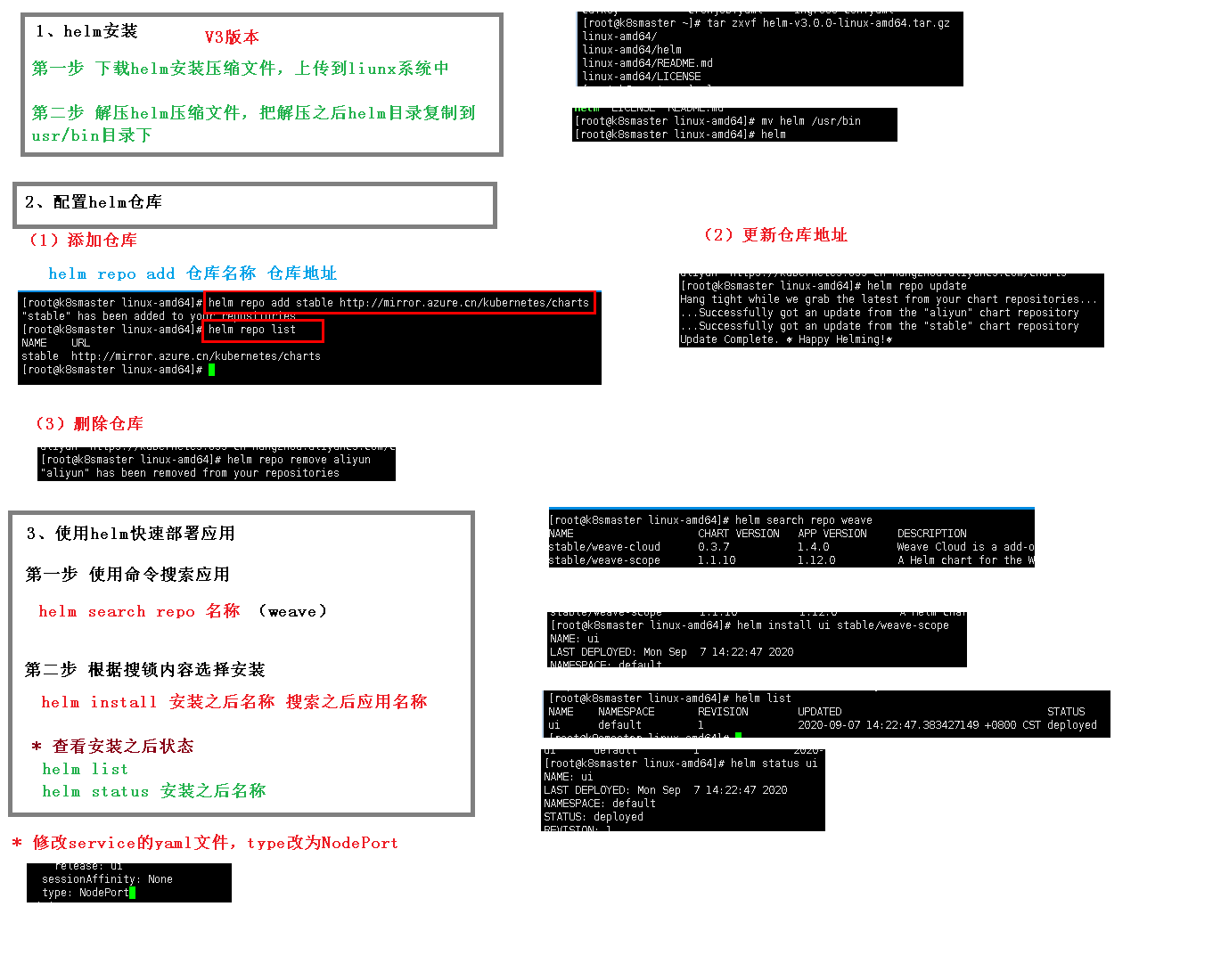


常用命令
基础命令
| 类别 | 含义 | 命令 |
| | —- | —- | —- | —- | | 集群 |
| kubectl cluster-info
kubectl version |
| | | 当前集群名
| kubectl config current-context |
| | | | | | | | | | | | 调度、负载 |
| kubectl get nodes |
| | | 查看节点的资源使用情况 | kubectl top node |
| | | 某些特征的pod | kubectl-n xxx get pod | grep xx
pod,svc,ns,endpoints | -n
-o wide 详情
-o yaml
—show-labels
-l
|
| | 命令行快速创建工作负载 | kubectl create deployment xxx —image = xx >xxx.yaml | —dry-run=client
先不发布,而是将yaml文件输出到命令行中 |
| | 命令行快速创建pod
| kubectl run
|
| | 命令行快速创建pod,并调用/bin/sh执行命令 | kubectl run busybox —image=busybox:1.28.4 — /bin/sh | 常用参数:
—rm 退出pod后就删除
-it 终端
—restart=Never 永不重启
|
| | 进入容器 | kubectl exec -it
— sh:
— bash:
— /bin/bash |
| | 命令行快速将服务暴露出去(创建Service) | kubectl expose deployment_name
| —type=”NodePort”
—port=(要暴露的容器端口)
—name=(Service 对象名字) |
| | | create -f
apply -f
replace -f |
注意辨析 |
| | 扩容缩容 | kubectl scale deployment_name
| —replicas=N
[—current-replicas=M]
(当前副本数等于 M 时)执行扩容或者缩容 |
| | 查看这个Deployment部署的历史记录 | kubectl rollout history deployment xxx |
| | |
| kubectl rollout status sts/
|
| | 应用升级 | kubectl set image deployment xxx =
或
kubectl edit deployment xxx ,然后修改yaml文件 |
| | | | |
| | 网络 |
| nslookup
| | | | |
| | | | |
|
| | 查看pod日志 | kubectl logs [-f ]
-f 实时更新 |
| | | |
| | | | |
| | | | | |
实践积累命令
查看各命名空间的pod数量
kubectl get ns | awk '{print $1}'|sed 1d|while read line; do echo -e "-- $line: \c";kubectl -n $line get pod 2>/dev/null |sed 1d|wc -l;done
命名空间 使用地址池的情况
kubectl get ns | awk '{print $1}'|sed 1d|while read line; do echo -e "-- $line: \c";kubectl get ns $line -o jsonpath='{.metadata.annotations.cni\.projectcalico\.org\/ipv4pools}{"\n"}' ;done
查看所有地址池的情况calicoctl ipam show

若有收获,就点个赞吧
0 人点赞
