- Java
- 信创
- 计算机网络
- 信息安全
- 操作系统
- Linux
- 中间件
- WebLogic中应用种类
- WebLogic的应用发布方式和布置方式
- WebLogic Domain的概念和组成
- Nginx中的模块分类及常见核心模块
- Nginx负载均衡中常用的server配置参数
- Apache、Nginx等WEB服务器的特点
- Nginx负载均衡中常见的算法及原理
- Apache默认的配置路径
- Apache
和 之间区别 - Apache Web 服务器不同的日志文件
- 为什么使用 Redis 作为缓存
- Redis 的常用数据结构
- 缓存穿透、缓存雪崩的概念和解决办法
- zookeeper的部署方式
- zookeeper常用的命令
- Zookeeper 下 Server工作状态
- Zookeeper 四种类型的数据节点 Znode
- 消息队列的应用场景、传输模式
- 常见消息中间件有哪些及对比优缺点
- Kafka 判断一个节点是否还活着的条件
- Kafka 与传统 MQ 消息系统之间区别
- kafka 的 ack 的三种机制
- 架构
- 数据库
Java
JVM 主要组成和作用
- 类加载器(class loader ):加载类文件到内存,只要符合文件结构即可,不执行
- 解释器(exection engine):解释命令,交由操作系统执行
- 本地接口(native interface):融合不同的语言为java所用
- 运行数据区(runtimedata area): 程序都在这里被加载,才开始运行
- 栈内存(stack):java程序的内存运行区域,随着线程创建产生,随着线程结束而释放。遵循“先进后出”的原则。
- 堆内存(heap):JVM实例只有一个堆内存,大小可以调节,类加载器读取了类文件之后,把类,方法和常变量都放在堆内存当中。有永久存储区(jdk自身携带的class,interface元数据),新生区,老年代。
- 方法区(method area):被所有线程共享,保存所有字段和字节方法码,构造函数,接口代码也在此定义。
- 程序计数器(PC Register):每个线程都有一个程序计数器,就是指针,指向方法区当中的字节方法码,由执行引擎读取下一条命令。
类加载过程?
类加载过程即是指JVM虚拟机把.class文件中类信息加载进内存,并进行解析生成对应的class对象的过程。
类加载的过程主要分为三个部分:
- 加载:加载指的是把class字节码文件从各个来源通过类加载器装载入内存中
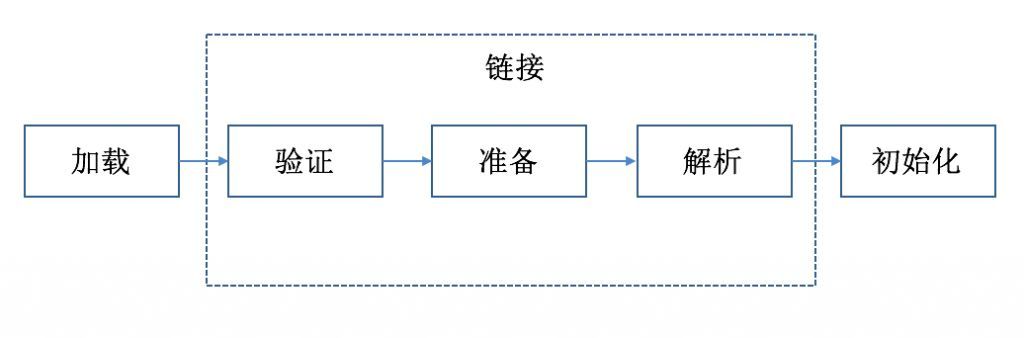
- 链接
- 初始化:对静态变量和静态代码块执行初始化工作。
而链接又可以细分为三个小部分:
- 验证:检查加载的 class 文件的正确性;
- 准备:给类中的静态变量分配内存空间;
- 解析:将常量池内的符号引用替换为直接引用的过程。
类加载器有哪些?
- 引导类加载器(Bootstrap):负责加载核心Java库
- 扩展类加载器(Extensions):加载 Java的扩展库
- 系统类加载器(Apps):加载Java 应用的类
常用的JVM调优参数
JDK 自带了很多监控工具,都位于 JDK 的 bin 目录下,其中最常用的是 jconsole 和 jvisualvm 这两款视图监控工具。
- -Xms:s为starting的意思,表示堆内存起始大小
- -Xmx:x为max,表示堆的最大的内存
- -Xmn:n为new的意思,表示新生代的大小
- -Xss:表示每个线程虚拟机堆栈的大小
- -XX:SurvivorRator = 8 :表示堆内存的新生代,老年代和永久代的比例为8:1:1
- -XX:MaxTenuringThreshold =3145728:表示当new的对象如果超过3M就进入老生代
- -XX:+DisableExplicirGC :表示是否打开GC日志(+表示是,-表示否)
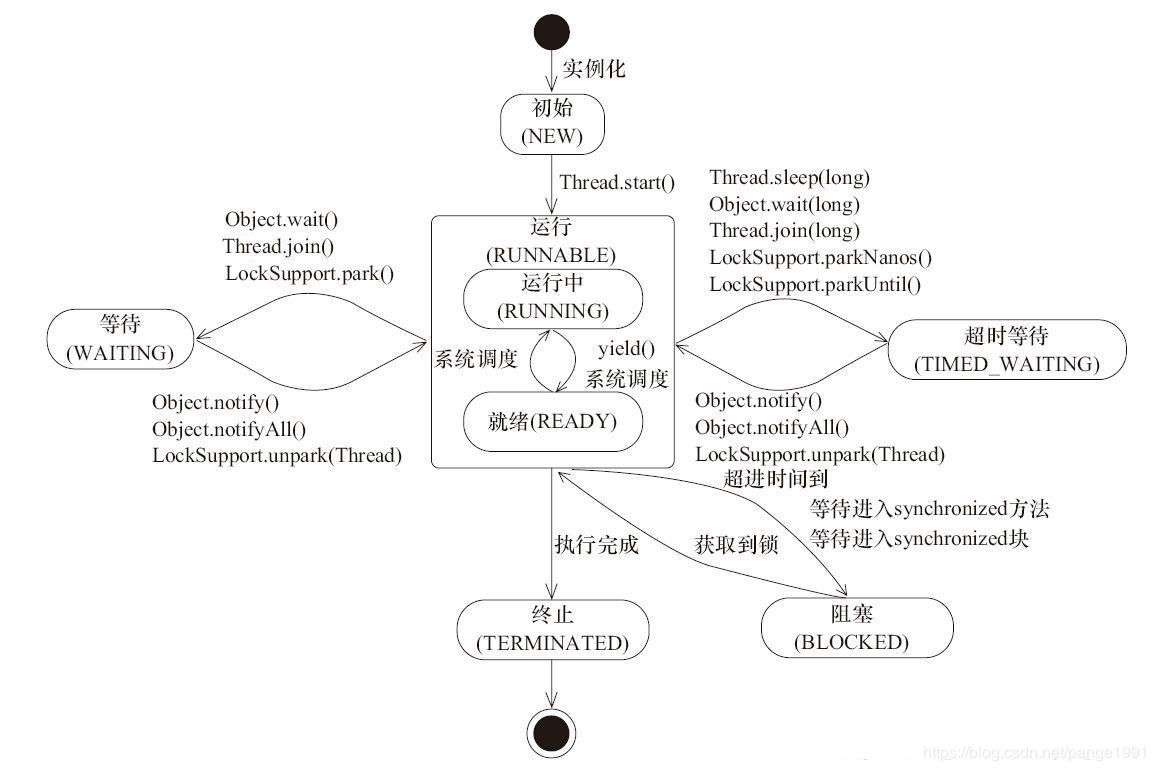
Java中线程的状态
- 初始(new):新创建了一个线程对象,但还没有调用start方法。
- 运行(runnable):其他线程调用了该线程对象的start方法,该状态的线程就位于线程池当中,等待被线程调度选中,获取CPU使用权,此时在ready状态,获得CPU时间片之后运行开始就处于running状态。
- 阻塞(blocked):表示线程阻塞于锁。
- 等待(waiting):等待其他线程做出一些特定的动作或者指令。
- 超时等待(timed_waiting):在指定的时间后自行返回。
- 终止(terminated):线程执行完毕。
如何跳出java中的循环
- break:结束整个循环体
- continue:结束单次循环
-
线程池中常用的参数
coolPoolSize:线程池中活跃的线程数
- maximumPoolSize:线程池当中允许存在的最大线程的数量
- keepAliveTime:线程池当中除了核心线程之外的线程(多余线程 = 最大线程数 - 核心线程数)的最大存活时间
- unit:多余线程存活的时间单位
- workQueue:任务队列,线程池执行任务的时候,会将任务提交给该队列,队列满了,线程池就会拒绝策略。
- threadFactory:创建线程池的工厂
handler:拒绝策略,当线程池无空闲线程,且任务队列慢了,线程池就会使用handler处理器来处理新提交的任务。
java常见的MVC
Model(模型) - 模型代表一个存取数据的对象或 JAVA POJO。它也可以带有逻辑,在数据变化时更新控制器。
- View(视图) - 视图代表模型包含的数据的可视化。
- Controller(控制器) - 控制器作用于模型和视图上。它控制数据流向模型对象,并在数据变化时更新视图。它使视图与模型分离开。
JAVA当中的MVC框架有struts1、struts2,springMVC。
cookie,session,error,excetion
http协议是无状态的,也就是说就算客户端是第二次访问服务器,服务器还是把此次访当做一个新的访问进行处理,因为服务端并不知道客户端之前是否访问过。而cookie和session则就是为了弥补这一缺陷出现的一种机制。
cookie是服务端给客户端的数据,用来记录客户端访问服务端的状态,由个数和大小限制,本质就是一个大小不超过4KB的字符串。
session是保存在服务端,用来识别cookie当中的标识,根据cookie中的标识明确操作对象。本质是一种数据接口,可能是字符串,也可能是对象,通常这种数据都会保存在redis数据库当中。
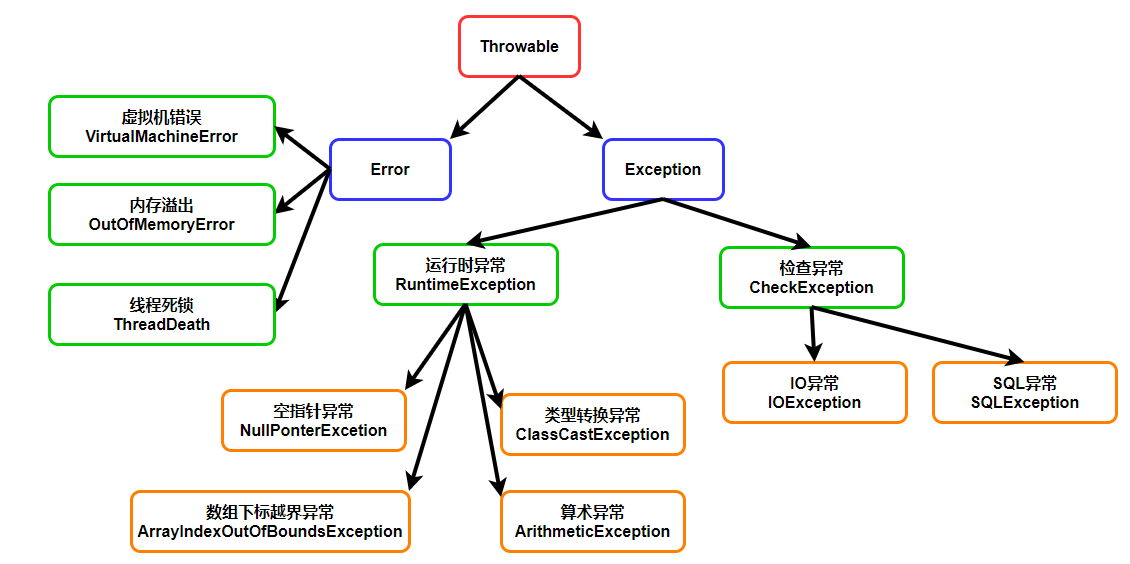
- Error叫做错误,一般是很少接触,它指的是虚拟机错误(VirtualMachineError)、线程死锁(ThreadDeath)等等,最好不要有这种错误出现,因为一旦出现,程序就崩溃了,因为Error是硬伤,是应用应用程序的控制和处理能力之外的。
- Exception叫做异常,通常指的是编码,环境,用户操作输入出现问题。它有很多的子类,比如RuntimeException(运行时异常或者非检查异常)、其他异常(也称检查异常)
信创
- 信创cpu厂商和产品:
- 华为海思;鲲鹏
- 中国长城:飞腾
- 龙芯中科:龙芯
- 信创服务器:
- 华为
- 联想
- 浪潮
- 新华三
- 中科曙光
- 信创数据库:
- 达梦数据库
- 人大金仓
- 南大通用
- 信创操作系统:
- 深度科技:深度操作系统
- 麒麟软件:优麒麟操作系统
- 天津麒麟:银河麒麟操作系统
信创中间件:
费用:https需要ca申请证书,免费证书较少,一般都要收费
- 协议:http使用的是超文本传输协议,信息是明文传输,而https使用的是具有安全性的ssl/tls加密传输协议
- 连接方式端口:http使用的是80端口,https使用的443端口
- 安全性:http是无状态连接,https是ssl/tls+http构建的加密传输,身份认证的网络协议,比http安全
TCP/IP协议的三次握手和四次挥手
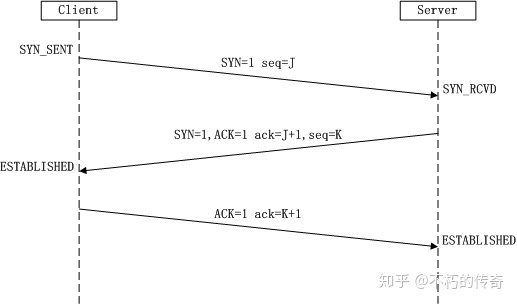
- 第一次握手:Client将标志位SYN置为1,随机产生一个值seq=J,并将该数据包发送给Server,Client进入SYN_SENT状态,等待Server确认。
- 第二次握手:Server收到数据包后由标志位SYN=1知道Client请求建立连接,Server将标志位SYN和ACK都置为1,ack=J+1,随机产生一个值seq=K,并将该数据包发送给Client以确认连接请求,Server进入SYN_RCVD状态。
- 第三次握手:Client收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给Server,Server检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了。
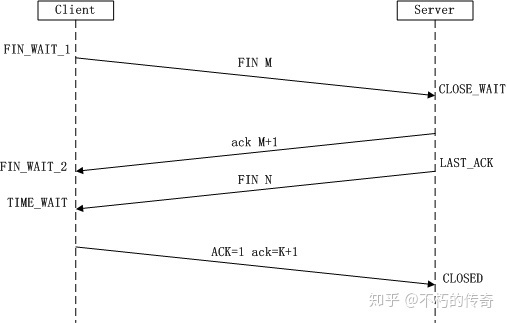
- 第一次挥手:Client发送一个FIN,用来关闭Client到Server的数据传送,Client进入FIN_WAIT_1状态。
- 第二次挥手:Server收到FIN后,发送一个ACK给Client,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号),Server进入CLOSE_WAIT状态。
- 第三次挥手:Server发送一个FIN,用来关闭Server到Client的数据传送,Server进入LAST_ACK状态。
- 第四次挥手:Client收到FIN后,Client进入TIME_WAIT状态,接着发送一个ACK给Server,确认序号为收到序号+1,Server进入CLOSED状态,完成四次挥手。
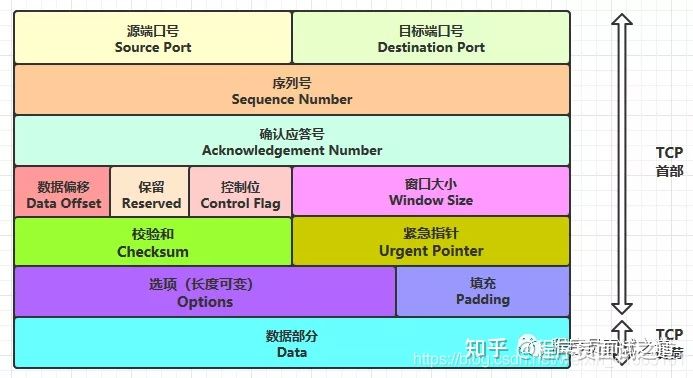
什么是TCP/IP和UDP,协议特点和格式
- TCP/IP即传输控制/网络协议,是面向连接的协议,发送数据前要先建立连接(发送方和接收方的成对的两个之间必须建 立连接),TCP提供可靠的服务,也就是说,通过TCP连接传输的数据不会丢失,没有重复,并且按顺序到达
- 协议特点:
- TCP是面向连接的协议,发送数据前要先建立连接,TCP提供可靠的服务,也就是说,通过TCP连接传输的数据不会丢失,没有重复,并且按顺序到达;
- TCP只支持点对点通信,TCP是面向字节流的,面向字节流是指发送数据时以字节为单位,一个数据包可以拆分成若干组进行发送
- TCP首部开销(20字节)
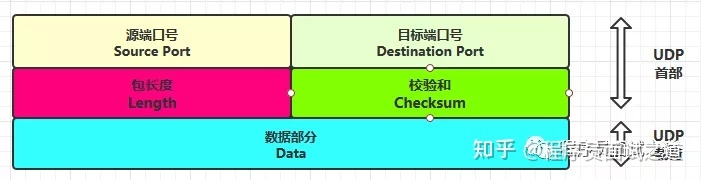
- 协议特点:
- UDP它是属于TCP/IP协议族中的一种。是无连接的协议,发送数据前不需要建立连接,是没有可靠性的协议。因为不需要建立连接所以可以在在网络上以任何可能的路径传输,因此能否到达目的地,到达目的地的时间以及内容的正确性都是不能被保证的。
- 协议特点:
- UDP是无连接的协议,发送数据前不需要建立连接,是没有可靠性;
- UDP支持一对一、一对多、多对一、多对多;
- UDP是面向报文的; UDP一个报文只能一次发完。
- UDP首部开销(8字节)
- 协议特点:
SSL概念和特性
SSL(Secure Sockets Layer 安全套接层协议),及其继任者传输层安全(Transport Layer Security,TLS)是为网络通信提供安全及数据完整性的一种安全协议。TLS与SSL在传输层与应用层之间对网络连接进行加密。
SSL协议提供的安全通道有以下三个特性:
机密性:SSL协议使用密钥加密通信数据。
可靠性:服务器和客户都会被认证,客户的认证是可选的。
完整性:SSL协议会对传送的数据进行完整性检查。
SSL/TLS协议概念以及注意解决的问题
https://www.modb.pro/db/141817
IPV4的地址格式和特点
IPv4使用32位(4字节)地址,因此理论上整个地址空间中有2^32^(约43亿)个地址,引用一个IPv4地址的时候一般以点分十进制的xxx.xxx.xxx.xxx来表示,其中每3位代表一个8位的二进制数。8位的二进制数可表示最大的值为2^8^-1,因此转换成点分十进制后,每段IP地址的取值范围在0~255之间。IPv4 地址使用二进制的表示形式为 00001010 00000001 00000001 00000010,采用点分十进制表示法表示为 10.1.1.2。
IPv4地址设计之初就考虑到了层次特点,于是规定将IP地址分割为网络ID和主机ID两部分,网络ID用来确定不同类型的网络里面有的网络数量,而主机ID用来确定每个网络里面的IP地址数。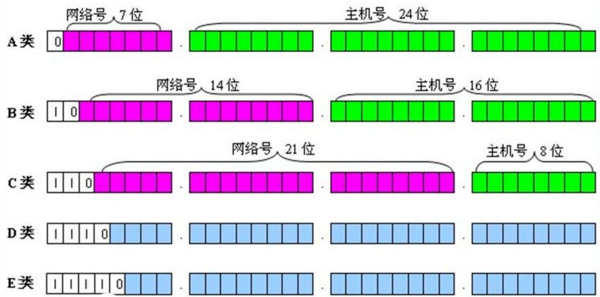
- A类:
- A类地址的最高位固定为0,即A类网络的理论总数应为2^7^为128个,但实际上可使用的只有126个,因为网络ID为0或127都是不可用的。
- A类地址中主机ID共24位,可用主机ID数为2^24^为16777216个,但有两个是保留的,所以一共可用的ID数是16777214个。其中主机ID全为0的是网络地址;主机ID全为1的是广播地址
- A类网络可构建的网络数量最少,但每个网络中拥有的地址数量是最多的,也就是可以构建的网络规模是最大的。
- 其子网掩码为固定的255.0.0.0
- B类:
- B类网络总数为16384个。而主机ID一共有65536个,同样的,主机ID全为0或全为1均为保留地址,所以实际可用地址数位65534个。
- 其子网掩码为固定的255.255.0.0。
- C类:
- C类网络总数为2^21^=2097152个。而主机ID只有8位,同样要保留全为0或1的地址,所以主机ID一共只有2^8^-2=254个。
- 其子网掩码为固定的255.255.255.0。
- D类:
- 组播地址,地址范围为224.0.0.0~239.255.255.255。
- E类:
- IANA保留地址:地址范围为240.0.0.0~247.255.255.255。
Ipv4主要特点:
(1)IPv4地址空间少于40亿个,实际可以使用的更少。
(2)IPv4不区分网络终端主机和终端设备,每台电脑都可以作为主机和路由器。路由协议管理路由表记录,常用的路由协议有路由信息协议、开放最短路径协议、边界网关协议等。
(3)IPv4独立于特定的网络硬件,可以运行在局域网、广域网、互联网中。网络地址分配方案唯一,设备有唯一的地址。
(4)IPv4缺乏对安全性的支持,无法实现网络实名制。网络中节点配置很复杂,不能满足用户“即插即用”的需求。
IPV4和IPV6的区别
IPv4和IPv6用于用户标识和Internet上不同设备之间的通信。IPv4是32位IP地址,而IPv6是128位IP地址。IPv4是数字地址,用点分隔。IPv6是一个字母数字地址,用冒号分隔。
我们分别详细介绍了IPv4和IPv6类型。现在,我们可以比较这些类型,并找出这两种协议之间的主要区别。我们列举了IPv4和IPv6之间的八个主要区别。
1.地址类型。IPv4具有三种不同类型的地址:多播,广播和单播。IPv6还具有三种不同类型的地址:任意广播,单播和多播。
2.数据包大小。对于IPv4,最小数据包大小为576字节。对于IPv6,最小数据包大小为1208字节。
3.header区域字段数。IPv4具有12个标头字段,而IPv6支持8个标头字段。
4.可选字段。IPv4具有可选字段,而IPv6没有。但是,IPv6具有扩展header,可以在将来扩展协议而不会影响主包结构。
5.配置。在IPv4中,新装的系统必须配置好才能与其他系统通信。在IPv6中,配置是可选的,它允许根据所需功能进行选择。
6.安全性。在IPv4中,安全性主要取决于网站和应用程序。它不是针对安全性而开发的IP协议。而IPv6集成了Internet协议安全标准(IPSec)。IPv6的网络安全不像IPv4是可选项,IPv6里的网络安全项是强制性的。
7.与移动设备的兼容性。IPv4不适合移动网络,因为正如我们前面提到的,它使用点分十进制表示法,而IPv6使用冒号,是移动设备的更好选择。
8.主要功能。IPv6允许直接寻址,因为存在大量可能的地址。但是,IPv4已经广泛传播并得到许多设备的支持,这使其更易于使用。
IPV6的特点
一、IPv6具有更大的地址空间。IPv4中规定IP地址长度为32,最大地址个数为2^32;而IPv6中IP地址的长度为128,即最大地址个数为2^128。与32位地址空间相比,其地址空间增加了2^128-2^32个。
二、IPv6使用更小的路由表。IPv6的地址分配一开始就遵循聚类的原则,这使得路由器能在路由表中用一条记录表示一片子网,大大减小了路由器中路由表的长度,提高了路由器转发数据包的速度。
三、IPv6增加了增强的组播支持以及对流的控制,这使得网络上的多媒体应用有了长足发展的机会,为服务质量控制提供了良好的网络平台。
四、IPv6加入了对自动配置的支持。这是对DHCP协议的改进和扩展,使得网络(尤其是局域网)的管理更加方便和快捷。
五、IPv6具有更高的安全性。在使用IPv6网络中用户可以对网络层的数据进行加密并对IP报文进行校验,在IPV6中的加密与鉴别选项提供了分组的保密性与完整性。极大的增强了网络的安全性。
六、允许扩充。如果新的技术或应用需要时,IPV6允许协议进行扩充。
七、更好的头部格式。IPV6使用新的头部格式,其选项与基本头部分开,如果需要,可将选项插入到基本头部与上层数据之间。这就简化和加速了路由选择过程,因为大多数的选项不需要由路由选择。
八、新的选项。IPV6有一些新的选项来实现附加的功能。
IPV6的表示方法
IPv6的3种表示方法:
一、冒分十六进制表示法
格式为X:X:X:X:X:X:X:X,其中每个X表示地址中的16b,以十六进制表示,例如:
ABCD:EF01:2345:6789:ABCD:EF01:2345:6789
二、0位压缩表示法
在某些情况下,一个IPv6地址中间可能包含很长的一段0,可以把连续的一段0压缩为“::”。但为保证地址解析的唯一性,地址中”::”只能出现一次。
三、内嵌IPv4地址表示法
为了实现IPv4-IPv6互通,IPv4地址会嵌入IPv6地址中,此时地址常表示为:X:X:X:X:X:X:d.d.d.d,前96b采用冒分十六进制表示,而最后32b地址则使用IPv4的点分十进制表示,例如::192.168.0.1与::FFFF:192.168.0.1就是两个典型的例子,注意在前96b中,压缩0位的方法依旧适用。
基本网络连通性检查
https://www.dounaite.com/article/62584d52ae87fd3f7960e678.html
信息安全
对称加密的流程和算法特点
对称加密算法 是应用较早的加密算法,又称为 共享密钥加密算法。在 对称加密算法 中,使用的密钥只有一个,发送 和 接收 双方都使用这个密钥对数据进行 加密 和 解密。这就要求加密和解密方事先都必须知道加密的密钥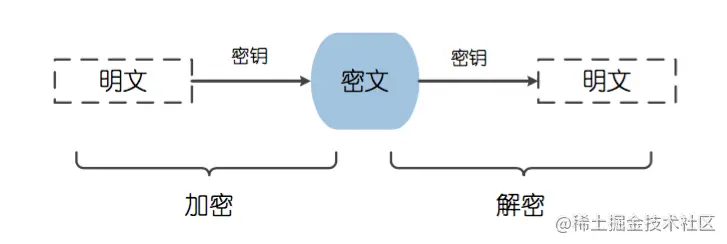
对称加密算法的特点是
- 算法公开、计算量小、加密速度快、加密效率高。
- 不足之处是,交易双方都使用同样钥匙,安全性得不到保证。
-
常见的对称加密算法有哪些
常见的 对称加密 算法主要有
DES:分组密码,以 64 位为 分组对数据 加密,它的 密钥长度 是 56 位
- 3DES:是基于 DES 的 对称算法,对 一块数据 用 三个不同的密钥 进行 三次加密,强度更高。
- AES:密码学中的 高级加密标准,AES 本身就是为了取代 DES 的,AES 具有更好的 安全性、效率 和 灵活性。
非对称加密的流程和算法特点
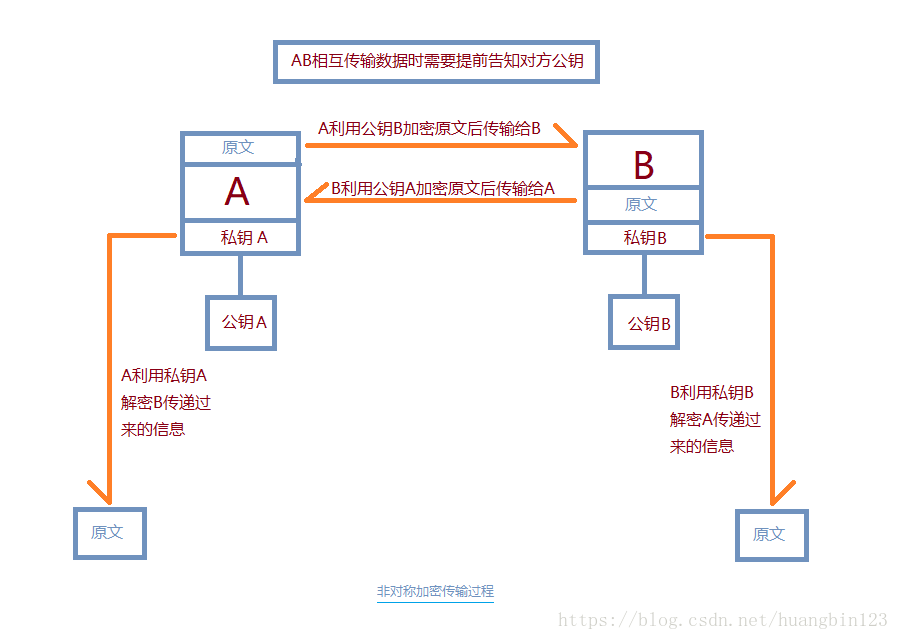
非对称加密算法,又称为 公开密钥加密算法。它需要两个密钥,一个称为 公开密钥 (public key),即 公钥,另一个称为 私有密钥 (private key),即 私钥。因为 加密 和 解密 使用的是两个不同的密钥,所以这种算法称为 非对称加密算法。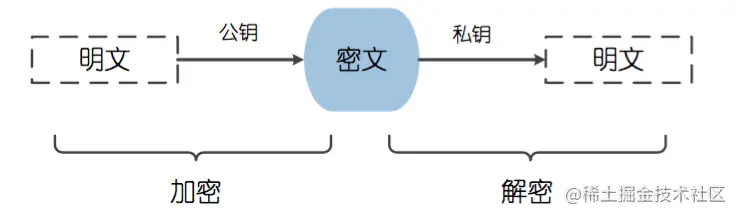
非对称加密算法的特点是:
数字签名的特征
- 数字签名与纸质签名一样具有法律效力
- 数字签名是不能随意篡改的,接受者可以通过计算和验证签名判断文件无效
数字签名需要身份认证,具有保密行,数字签名是依靠公钥加密技术来实现的,每个人都有一对秘钥,公钥自由发布,私钥秘密保存。
数字签名签名和验签的过程
数字签名,简单来说就是通过提供 可鉴别 的 数字信息 验证 自身身份 的一种方式。一套 数字签名 通常定义两种 互补 的运算,一个用于 签名,另一个用于 验证。分别由 发送者 持有能够 代表自己身份 的 私钥 (私钥不可泄露),由 接受者 持有与私钥对应的 公钥 ,能够在 接受 到来自发送者信息时用于 验证 其身份。
换句话说:非对称加密当中不是公钥和私钥都能用来加密和解密,准确的说:公钥加密,私钥解密
- 私钥签名,公钥验签
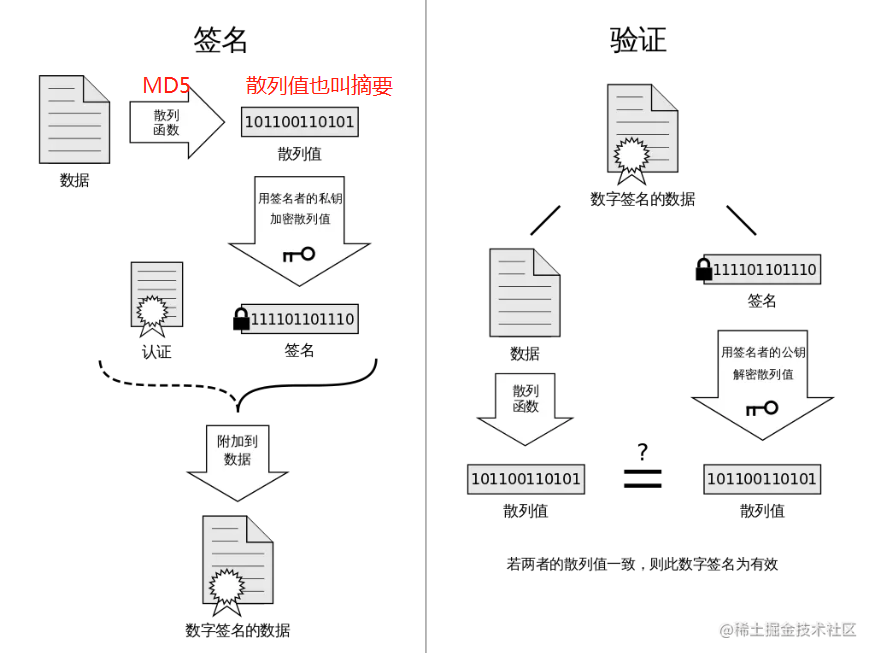
关于对称加密-> 非对称加密 -> 数字签名,可参照:https://segmentfault.com/a/1190000024523772
CA的作用
数字证书的作用就是证明某个人的公钥就是某个人的公钥。而CA(证书颁发机构)证书的颁布机构、有效期、公钥、持有者(subject)等信息用 CA 的私钥进行签名。
并且将签名结果和这些信息放在一起,这就叫做「数字证书」。
A就可以去 CA 申请一个证书,然后将自己的证书发给 B,那么B如何验证这个证书确实是 A的呢?当然是使用 CA 的公钥进行验签。
国密算法有哪些以及各种算法的应用场景
- SM1:
- 分组加密算法
- 采用该算法已经研制了系列芯片、智能IC卡、智能密码钥匙、加密卡、加密机等安全产品,广泛应用于电子政务、电子商务及国民经济的各个应用领域(包括国家政务通、警务通等重要领域)。
- SM2:
- 非对称加密算法
- 可以满足电子认证服务系统等应用需求
- SM3:
- 密码杂凑算法
- 适用于数字签名和验证、消息认证码的生成与验证以及随机数的生成,可以满足电子认证服务系统等应用需求,
- SM4:
- 分组加密算法
- 用于替代DES/AES等国际算法。
操作系统
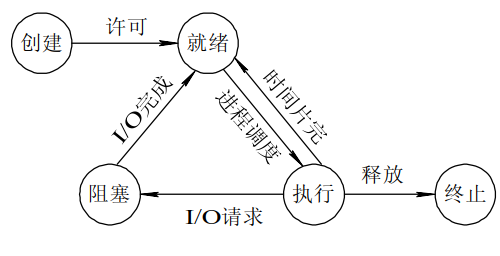
进程的几种状态
进程可以分为五个状态,分别是:
- 创建状态:应用程序从系统启动,进入创建状态,获取资源创建进程管理块
- 就绪状态:进程已经准备好,但是还未获得处理器资源,无法运行
- 运行状态:获取处理器资源,被系统调度,开始进入运行状态
- 阻塞状态:运行状态期间,如果进行了阻塞的操作,如耗时的I/O操作,此时进程暂时无法操作就进入到了阻塞状态,
- 终止状态:进程结束或者被系统终止,进入终止状态
进程与线程
- 进程是对运行时程序的封装,是系统进行资源调度和分配的的基本单位,实现了操作系统的并发
- 线程是进程的子任务,是CPU调度和分派的基本单位,用于保证程序的实时性,实现进程内部的并发
两者的区别:
- 对应关系:一个线程只能属于一个进程,而一个进程可以有多个线程。
- 内存关系:进程再执行过程中拥有独立的内存单元,而多个线程共享进程的内存
- 最小单位:进程是资源分配的最小单位,线程是cpu调度的最小单位
- 开销:进程切换的开销远大于线程切换的开销
互相影响:进程之间不会互相影响,线程一个线程挂掉会倒置整个进程挂掉
进程间的通信方式有哪些
管道:
- 匿名管道PIPE:半双工的,只能用于具有亲缘关系的进程之间的通信
- 命名管道FIFO:可以在无关的进程之间交换数据
- 系统IPC
- 消息队列:是消息的链接表,存放在内核中。对消息队列有读权限得进程则可以从消息队列中读取信息;
- 共享内存: 多个进程可以访问同一块内存空间,不同进程可以及时看到对方进程中对共享内存中数据得更新。
- 套接字socket:
- 可用于不同主机之间的进程通信。
Linux
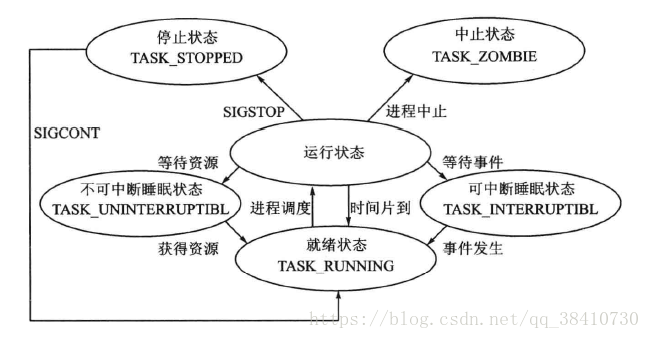
Linux下的进程状态
linux文件查找
- 查找当前目录和子目录下所有文件和文件夹: find .
- 在/testLinux目录下查找以.txt结尾的文件名:find /tmp/cg/testLinux -name “*.txt”
查找文件名名以file1开头(与 -a,或 -o , 非!)file2开头的文件
在文件所在目录下面使用命令:vim test.sh
- 默认进入的是命令模式,按i进入编辑模式,进入编辑
编辑完成按esc退出,同时输入:wq就是保存并退出,输入:q!就是不保存退出。
linux文件权限
chmod [可选项]
chmod 600 file:只有拥有者有读写权限
- chmod 700 file:只有拥有者有读写执行权限
- chmod 666 file:所有用户都有读写权限
- chmod 777 file:所有用户都有读写执行权限
linux定时任务
Linux是使用Crontab命令来执行定时任务,配置文件为/etc/crontab文件
用户所建立的crontab文件中,前四行是配置行,后面每一行都代表一项任务,格式如下:
minute hour day month week commond
SHELL=/bin/bashPATH=/sbin:/bin:/usr/sbin:/usr/binMAILTO=root# For details see man 4 crontabs# Example of job definition:# .---------------- minute (0 - 59)# | .------------- hour (0 - 23)# | | .---------- day of month (1 - 31)# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat# | | | | |# * * * * * user-name command to be execute#每天 每隔5,10,15,20,30分钟执行一次定时任务*/5 * * * * root /data0/myshell/collect5m.sh#*/10 * * * * root /data0/myshell/collect10m.sh#*/15 * * * * root /data0/myshell/collect15m.sh#*/20 * * * * root /data0/myshell/collect20m.sh#*/30 * * * * root /data0/myshell/collect30m.sh
启动服务:
/bin/systemctl start crond.serveice
linux进程查看
- ps aux
-
linux网络及端口查看
查看网络连接情况:netstat -an|grep tcp
- 查看端口状态:
- 用于查看某一端口的占用情况:lsof -i:端口号,例如 lsof -i:8000
- 查看指定的端口号的进程情况:netstat -tunlp | grep 端口号,例如netstat -tunlp | grep 8000
中间件
WebLogic中应用种类
1、WebLogic中应用可分三种,分别对应不同的描述文件及扩展名或目录结构:
(1).JAR: 是EJB的压缩包(有3个描述文件ejb-jar.xml,WEBLOGIC.0-ejb-jar.xml,WEBLOGIC.0-cmp-rdbms-jar.xml)
(2).WAR: 是只包含JSP和SERVLET的WEB APPLICATION压缩包(有2个描述文件web.xml,weblogic.xml)
(3)*.EAR: 是包含EJB和WEB APPLICATION 的J2EE Enterprise Application压缩包(有1 个描述文件,application.xml)
注意:它们不能混用,如WEB APPLICATOIN不能打包成.EAR文件
WebLogic的应用发布方式和布置方式
2、WebLogic的应用用两种发布方式:
(1)以目录形式存放在WEBLOGIC的APPLICATIONS目录下,适用于开发阶段
(2)以一个压缩包形式存放在WEBLOGIC的APPLICATIONS目录下,适用于运行阶段,可用JAR 打包,如D: est >jar cf testwar.war *
把TEST目录下的所有文件打包成一个testwar.war文件。
3、WebLogic应用的布置方式有2种
(1)静态布置:即把应用在CONFIG.XML中登记,可通过WEBLOGIC的控制台进行添加,WEBLOGIC会自动把该应用对应的压缩包拷到APPLICAITONS目录下,如果对该应用修改,需要重新布置才行。
(2)动态布置:没有在config.xml中登记,可直接把压缩包或目录拷到APPLICATIONS目录下,WebLogic会自动检测到. WebLogic每次启动时会自动对APPLICATIONS目录下没有进行静态布置的应用,进行动态布置。
WebLogic Domain的概念和组成
域(domain)是weblogic服务的一个基本管理单元。它是由一个或多个weblogic服务实例、逻辑相关的资源和服务组成,被作为一个统一的单元管理起来。
一个基本domain的结果是由一个管理服务(AdministrationServer)和可选的管理服务(Managed Server)+管理服务集群组成
Nginx中的模块分类及常见核心模块
- 核心模块:Nginx 服务器正常运行必不可少的模块,提供错误日志记录 、配置文件解析 、事件
驱动机制 、进程管理等核心功能
- 标准HTTP模块:提供 HTTP 协议解析相关的功能,比如: 端口配置 、 网页编码设置 、 HTTP响应头设置 等等
- 可选HTTP模块:主要用于扩展标准的 HTTP 功能,让 Nginx 能处理一些特殊的服务,比如: Flash多媒体传输 、解析 GeoIP 请求、 网络传输压缩 、 安全协议 SSL 支持等
- 邮件服务模块:实现反向代理功能,包括TCP协议代理
- 第三方模块:是为了扩展 Nginx 服务器应用,完成开发者自定义功能,比如: Json 支持、 Lua 支持等
常见核心模块:
- user:进程运行使用的用户和组
- pid:指定存储nginx主进程号的文件路径
- include:包含进来的其他配置文件
- worker_proccess: worker进程的数量,小于等于cpu核心数,设置为auto为当前主机cpu核心数量
- worker_cpu_affinity:配置cpu,减少造成cpu时间损耗
- worker_priority:指定worker进程的nice值,范围是[-20,20]
- worker_rlimit_nofile:进程能打开的最大文件数
- daemon:是否以守护进程的方式运行Nginx
- error_log:配置错误日志路径和日志文件名
-
Nginx负载均衡中常用的server配置参数
upstream配置:对配置的上游服务器按照默认的轮询方式进行请求。
- weight权重配置:配置权重用于合理分配请求数量。
- ip_hash:每一个请求按照请求的ip的hash结果分配。
- fair配置:按照上游服务器的响应时间来分配请求,响应时间短的优先分配
- url_hash:按照访问的url的hash结果来分配请求,使每一个url定向到同一个上游服务器
- down:表示当前server不参与负载均衡
- max_fails:最大失败的请求数
fail_timeout:超过最大失败请求数,暂停请求此服务器的时间
Apache、Nginx等WEB服务器的特点
Nginx特点:
- 轻量级,采用C进行编写,同样的web服务器,会占用更少的内存和资源
- 抗并发,nginx以epollandkqueue作为开发模型,处理请求是异步非阻塞的,负载能力比apache要高很多。
- 可以配置nginx的upstream实现nginx的反向代理。
- nginx作为负载均衡服务器,支持7层负载均衡
- nginx处理静态文件好,静态处理性能比apache高三倍以上。
- 支持高并发连接,每秒最多的并发连接请求理论可以达到50000个。
- nginx配置简洁,正则配置让很多事情变得简单,而且改完配置能使用-t测试配置有没有问题。
- nginx的设计高度模块化,编写模块相对简单。
- 一个进程死掉时,会影响到多个用户的使用,稳定性差。
Apache特点:
轮询(round robin):轮询,将请求按序分配到各个后端RS服务器,不考虑后端服务器的性能、负载能力等,它是Nginx 的默认负载均衡算法
# 范例upstream backserver {server 192.168.250.8;server 192.168.250.18;}
加权轮询(weight round robin):根据权重加权轮询,默认为1,实现类似于LVS中的WRR,WLC等.默认时和rr效果一样.
# 范例upstream backserver {server 192.168.250.18 weight=1;server 192.168.250.28 weight=3;}
源地址hash(ip_hash):源地址hash调度方法,基于客户端remote_addr(源地址IPv4的前24位或整个IPv6地址)做hash计算,以实现会话保持。
# 范例upstream backserver {ip_hash;server 192.168.250.18;server 192.168.250.28;}
Apache默认的配置路径
Apache
和 之间区别 Directory指令仅适用于文件系统对象(例如 /var/www/mypage、C:\www\mypage),而Location指令仅适用于 URL(站点域名之后的部分,例如 www.mypage.com/mylocation)。
Apache Web 服务器不同的日志文件
为什么使用 Redis 作为缓存
基于内存存储,读写性能优良
- redis的过期策略为「定期删除」+「惰性删除」两者配合
- redis支持的数据类型更加丰富
-
Redis 的常用数据结构
缓存穿透、缓存雪崩的概念和解决办法
缓存穿透
- 概念:缓存和数据库都没有的数据,被大量请求,比如订单号不可能为-1,但是用户请求了大量订单号为-1的数据,由于数据不存在,缓存就也不会存在该数据,所有的请求都会直接穿透到数据库。
- 解决方法:
- 接口增加业务层级的Filter,进行合法校验,这可以有效拦截大部分不合法的请求。
- 针对数据库与缓存都没有的数据,对空的结果进行缓存,但是过期时间设置得较短,一般五分钟内。而这种数据,如果数据库有写入,或者更新,必须同时刷新缓存,否则会导致不一致的问题存在。
- 缓存雪崩:
- 概念:缓存雪崩是指缓存中有大量的数据,在同一个时间点,或者较短的时间段内,全部过期了,这个时候请求过来,缓存没有数据,都会请求数据库,则数据库的压力就会突增,扛不住就会宕机。
- 解决方法:
- 如果是热点数据,那么可以考虑设置永远不过期。
- 缓存的过期时间除非比较严格,要不考虑设置一个波动随机值,将热点数据打散分不到不同的机房中,也可以有效减少这种情况。
- 也可以考虑双缓存的方式,数据库数据同步到缓存A和B,A设置过期时间,B不设置过期时间,如果A为空的时候去读B,同时异步去更新缓存,但是更新的时候需要同时更新两个缓存。
zookeeper的部署方式
- 单机部署:一般用来检验Zookeeper基础功能,熟悉ZK各种基础操作及特性;
- 伪集群部署:在单台机器上部署集群,方便在本地验证集群模式下的各种功能;
- 集群部署:一般在生产环境使用,具备一致性、分区容错性;
zookeeper常用的命令
1 远程连接: .\zkCli.cmd -timeout 5000 -r -server ip:2181 (不带参数,则默认连接localhost:2181)
2 创建节点:create [-s] [-e] [-c] [-t ttl] path [data] [acl]
-s 顺序创建 -e 临时节点 path 创建的路径 data 存放的数据 ack 设置权限
3 获取节点下的子节点: ls path 例如 ls /
4 获取节点数据: get path 例如 get /kan
5 修改节点中数据: set [-s] [-v version] path data
6 删除某节点,如果当前节点存在子节点则不允许删除:delete [-v version] path
7 删除当前节点及其子节点 : rmr path 递归删除
8 删除所有节点: delete all pathZookeeper 下 Server工作状态
1、LOOKING:寻找 Leader 状态。当服务器处于该状态时,它会认为当前集群中没有 Leader,因此需要进入 Leader 选举状态。
2、FOLLOWING:跟随者状态。表明当前服务器角色是 Follower。
3、LEADING:领导者状态。表明当前服务器角色是 Leader。
4、OBSERVING:观察者状态。表明当前服务器角色是 Observer。Zookeeper 四种类型的数据节点 Znode
1、PERSISTENT-持久节点
除非手动删除,否则节点一直存在于 Zookeeper 上
2、EPHEMERAL-临时节点
临时节点的生命周期与客户端会话绑定,一旦客户端会话失效(客户端与
zookeeper 连接断开不一定会话失效),那么这个客户端创建的所有临时节点都
会被移除。
3、PERSISTENT_SEQUENTIAL-持久顺序节点
基本特性同持久节点,只是增加了顺序属性,节点名后边会追加一个由父节点维
护的自增整型数字。
4、EPHEMERAL_SEQUENTIAL-临时顺序节点
基本特性同临时节点,增加了顺序属性,节点名后边会追加一个由父节点维护的自增整型数字。
消息队列的应用场景、传输模式
消息队列主要有两种模式:点对点(Point to Point)模式和发布-订阅(Publisher-Subscriber)模式。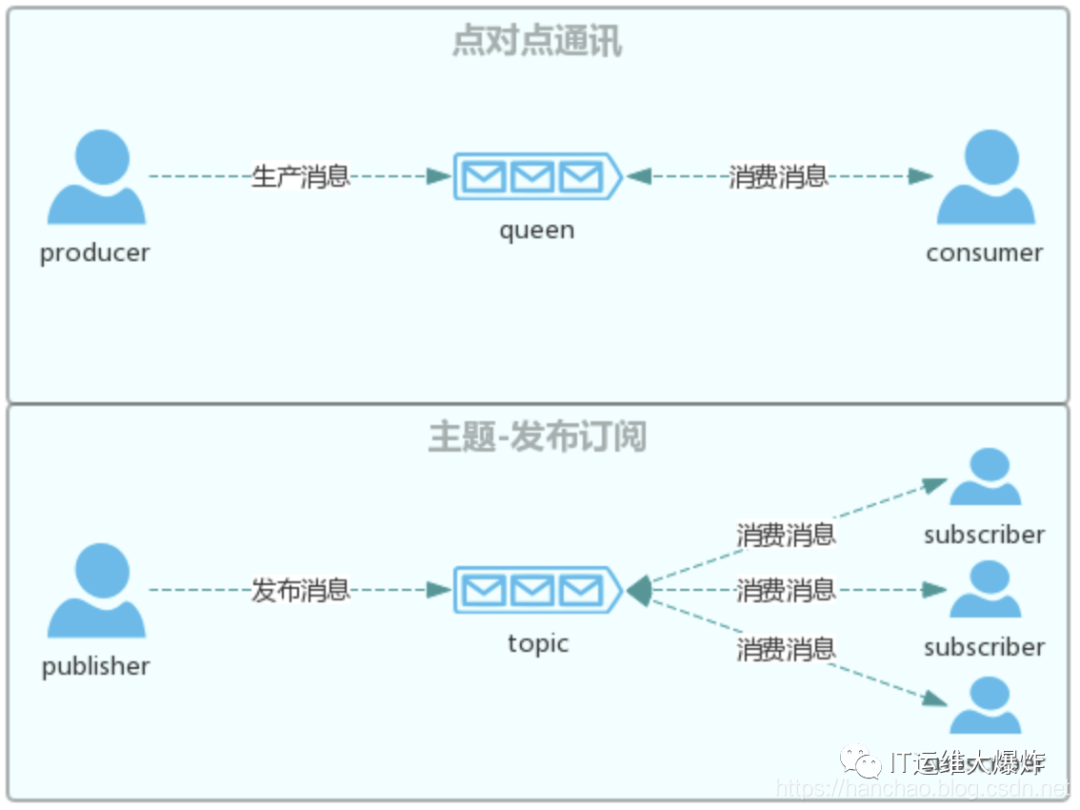
点对点模式:
参与者:消息发送者被称为生产者(Producer),消息容器被称之为队列(queue)、消息接收者被称之为消费者(Consumer)。每个消息只有一个消费者,一旦被消费,则从队列中移除。为了让队列移除消息,消费者在消费之后,应该给予队列应答(ACK)。
发布-订阅模式:
参与者:消息发送者被称为发布者(Publisher),消息容器被称之为话题(topic)、消息接收者被称之为订阅者(Consumer)。每个消息可有多个订阅者,即使被消费,依然在队列中存在。为了能消费指定话题的消息,订阅者需要订阅该topic;如果不在需要消费其消息,则取消订阅该topic。
应用场景:
- 消息通讯:微信发消息、QQ聊天群等。
- 异步处理:会员注册之后的短信通知、网站站内信等
- 应用解耦:操作涉及到多个服务的时候,如果有个服务挂掉,应给不影响操作的进行
-
常见消息中间件有哪些及对比优缺点
使用较多的消息队列有: ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ
社区活跃度:RabbitMQ > activeM > ZeroMQ
- 持久化消息的支持:ZeroMQ不支持,其他两者都支持
- 综合技术的实现:RabbitMQ/Kafka > activeM > ZeroMQ
- 高并发:RabbitMQ最高,因为实现语言就是天生具有高并发的erlang语言
综合来讲RabbitMQ比较好:
- 低延时,高并发
- 管理界面好看,功能强大
-
Kafka 判断一个节点是否还活着的条件
(1)节点必须可以维护和 ZooKeeper 的连接,Zookeeper 通过心跳机制检查每
个节点的连接
(2)如果节点是个 follower,他必须能及时的同步 leader 的写操作,延时不能太
久Kafka 与传统 MQ 消息系统之间区别
(1).Kafka 持久化日志,这些日志可以被重复读取和无限期保留
(2).Kafka 是一个分布式系统:它以集群的方式运行,可以灵活伸缩,在内部通过
复制数据提升容错能力和高可用性
(3).Kafka 支持实时的流式处理kafka 的 ack 的三种机制
0:生产者不会等待broker 的ack,这个延迟最低但是存储的保证最弱当server 挂掉的时候就会丢数据。
- 1:服务端会等待ack 值leader 副本确认接收到消息后发送ack 但是如果leader挂掉后他不确保是否复制完成新leader 也会导致数据丢失。
- -1(all):服务端会等所有的follower 的副本受到数据后才会受到leader 发出的ack,这样数据不会丢失
架构
RPC、RESTful概念
- REST代表表现层状态转移:在设计API时,使用路径定位资源,方法定义操作,通过Content-Type和Accept来协商资源的类型。
- RPC代表远程过程调用:前端传递一个方法名和参数给后端,后端执行对应的方法,并给该方法传递对应的参数,最后将执行的结果传递给前端。
分布式与微服务的区别
分布式服务顾名思义服务是分散部署在不同的机器上的,系统应用部署在超过一台服务器或虚拟机上,且各分开部署的部分彼此通过各种通讯协议交互信息,就可算作分布式部署。
微服务就是将一个软件的功能进行拆分,比如某个功能经常使用或经常不使用,可以将该功能单独的设计为一个微服务。通过RPC(远程接口调用,一般通过网络进行调用不是部署在同一台机器的)对该功能进行调用(该句的内容包含了分布式的内容)。微服务之间可以使用不同的语言进行书写。只要按照约定的规范发送请求和接收数据。
生产环境下的微服务肯定是分布式部署的,分布式部署的应用不一定是微服务架构的,比如集群部署,它是把相同应用复制到不同服务器上,但是逻辑功能上还是单体应用。分布式:分散压力。微服务:分散能力。
参照:https://www.huaweicloud.com/zhishi/edit-582325.html
常见限流方法
在开发高并发系统时,有三把利器用来保护系统:缓存、降级和限流。那么何为限流呢?顾名思义,限流就是限制流量,就像你宽带包了1个G的流量,用完了就没了。通过限流,我们可以很好地控制系统的qps,从而达到保护系统的目的:
限流顾名思义,就是对请求或并发数进行限制;通过对一个时间窗口内的请求量进行限制来保障系统的正常运行。如果我们的服务资源有限、处理能力有限,就需要对调用我们服务的上游请求进行限制,以防止自身服务由于资源耗尽而停止服务
在限流中有两个概念需要了解。
- 阈值:在一个单位时间内允许的请求量。如 QPS 限制为10,说明 1 秒内最多接受 10 次请求。
拒绝策略:超过阈值的请求的拒绝策略,常见的拒绝策略有直接拒绝、排队等待等。
计数器算法:是一种简单方便的限流算法。主要通过一个支持原子操作的计数器来累计 1 秒内的请求次数,当 1 秒内计数达到限流阈值时触发拒绝策略。
- 滑动窗口算法:滑动窗口算法是对固定窗口算法的改进,主要解决临界突变的问题
- 滑动日志算法:基本逻辑就是记录下所有的请求时间点,新请求到来时先判断最近指定时间范围内的请求数量是否超过指定阈值,由此来确定是否达到限流
SOA和微服务架构之间的主要区别
首先SOA和微服务架构是一个层面的东西,而对于ESB和微服务网关是一个层面的东西,一个谈到是架构风格和方法,一个谈的是实现工具或组件。
1.SOA(Service Oriented Architecture)“面向服务的架构”:他是一种设计方法,其中包含多个服务, 服务之间通过相互依赖最终提供一系列的功能。一个服务通常以独立的形式存在与操作系统进程中。各个服务之间通过网络调用。
2.微服务架构:其实和 SOA 架构类似,微服务是在 SOA 上做的升华,微服务架构强调的一个重点是“业务需要彻底的组件化和服务化”,原有的单个业务系统会拆分为多个可以独立开发、设计、运行的小应用。这些小应用之间通过服务完成交互和集成。
微服务架构 = 80%的SOA服务架构思想 + 100%的组件化架构思想 + 80%的领域建模思想
微服务架构的优点和缺点,特点
优点:
- 易于开发和维护:一项服务只关注一项特定的业务功能,业务清晰,代码量少。开发维护单项微服务相当简单。整个应用程序由一些微型服务构建,因此整个应用程序处于可控状态。
- 单一服务启动快:单一服务代码少,启动快。
- 局部修改易于部署:单个应用程序只要有修改,就必须重新部署整个应用程序,微服务解决了这个问题。一般来说,修改某个微型服务,只需重新配置该服务。
- 技术堆栈不受限制:微服务结构可结合业务和团队特点,合理选择技术堆栈。例如,一些服务可以使用关系数据库Mysql,一些服务可以使用非关系数据库redis。甚至可以根据需服务可以使用JAVA开发,一些微服务可以使用Node.js开发。
- 按需收缩:可根据需要实现细粒度的扩展。例如,系统中的某个微服务遇到瓶颈,可以结合微服务的特点,增加内存,升级CPU,增加节点。
缺点:
- 运输要求高:更多的服务意味着更多的运输投入。在单体结构中,只需保证一个应用程序的运行,在微服务中,需要保证几十到几百个服务器的正常运行和合作,这给运行维护带来了巨大的挑战
- 分户式固有的复杂性:使用微服务结构的是分布式系统。对于分布式系统,系统容错,网络延迟带来巨大挑战。
-
微服务的基本理念和原则
它的基本理念是将一个臃肿的系统拆分成若干小的服务组件,组件之间的通讯采用轻量的协议完成。
AKF拆分原则
- 前后端分离
- 无状态服务
- Restful通信风格
分布式事务、CAP定理、BASE理论
知道你是否遇到过这样的情况,去小卖铺买东西,付了钱,但是店主因为处理了一些其他事,居然忘记你付了钱,又叫你重新付。又或者在网上购物明明已经扣款,但是却告诉我没有发生交易。这一系列情况都是因为没有事务导致的。这说明了事务在生活中的一些重要性。
事务提供一种机制将一个活动涉及的所有操作纳入到一个不可分割的执行单元,组成事务的所有操作只有在所有操作均能正常执行的情况下方能提交,只要其中任一操作执行失败,都将导致整个事务的回滚。简单地说,事务提供一种“要么什么都不做,要么做全套(All or Nothing)”机制。
分布式事务就是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上,简单的说,就是一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
CAP定理(CAP theorem),又被称作布鲁尔定理(Brewer’s theorem),它指出对于一个分布式计算系统来说,不可能同时满足以下三点
一致性(Consistency)所有节点访问同一份最新的数据副本
可用性(Availability)每次请求都能获取到非错的响应,但是不保证获取的数据为最新 数据
分区容错性(Partition tolerance)分布式系统在遇到任何网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务,除非整个网络环境都发生了故障
Base 理论是对 CAP 中一致性和可用性权衡的结果,其来源于对大型互联网分布式实践的总结,是基于 CAP 定理逐步演化而来的。其核心思想是:既是无法做到强一致性(Strong consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。
分布式与集群的区别
分布式是指将不同的业务分布在不同的地方。而集群指的是将几台服务器集中在一起,实现同一业务。
分布式中的每一个节点,都可以做集群。而集群并不一定就是分布式的。
举例:就比如新浪网,访问的人多了,他可以做一个群集,前面放一个响应服务器,后面几台服务器完成同一业务,如果有业务访问的时候,响应服务器看哪台服务器的负载不是很重,就将给哪一台去完成。
大白话讲
小饭店原来只有一个厨师,切菜洗菜备料炒菜全干。后来客人多了,厨房一个厨师忙不过来,又请了个厨师,两个厨师都能炒一样的菜,这两个厨师的关系是集群。
为了让厨师专心炒菜,把菜做到极致,又请了个配菜师负责切菜,备菜,备料,厨师和配菜师的关系是分布式,一个配菜师也忙不过来了,又请了个配菜师,两个配菜师关系是集群。
分布式系统设计思路
宏观上来说就是中心化设计和去中心化设计
- 系统分拆-> 子系统分拆:模块化,微服务
- 存储分拆:
- Nosql:其天生就是分布式的,很容易实现数据的分片
- Mysql:分库分表,分布式事务
- 计算分拆:算法的优化
- 任务分拆:把一个长的任务,拆分成几个环节,各个环节并行计算
- 并发:最常见的就是多线程,尽可能提高程序的并发度。
- 缓存:缓存的粒度问题
-
数据库
数据库常用语句
https://www.51cto.com/article/692339.html
数据库连接方式
数据库的四种连接方式分别是:
1、inner join内连接;
- 2、outer join外连接;
- 3、cross join交叉连接;
- 4、natural join自然连接。
参照:https://www.php.cn/mysql-tutorials-425209.html
数据库常用关键字、函数等
https://blog.csdn.net/uziuzi669/article/details/108924070
关系型数据库与非关系型数据库优劣
关系型数据库优缺点是什么?
关系型数据库是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。简单说,关系型数据库是由多张能互相连接的表组成的数据库。
优点
1. 都是使用表结构,格式一致,易于维护。
2. 使用通用的 SQL 语言操作,使用方便,可用于复杂查询。
3. 数据存储在磁盘中,安全。
缺点
1. 读写性能比较差,不能满足海量数据的高效率读写。
2. 不节省空间。因为建立在关系模型上,就要遵循某些规则,比如数据中某字段值即使为空仍要分配空间。
3. 固定的表结构,灵活度较低。
常见的关系型数据库有 Oracle、DB2、PostgreSQL、Microsoft SQL Server、Microsoft Access 和 MySQL 等。
非关系型数据库优缺点是什么?
非关系型数据库又被称为 NoSQL,意为不仅仅是 SQL。通常指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定。
优点
1. 非关系型数据库存储数据的格式可以是 key-value 形式、文档形式、图片形式等。使用灵活,应用场景广泛,而关系型数据库则只支持基础类型。
2. 速度快,效率高。 NoSQL 可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘。
3. 海量数据的维护和处理非常轻松。
4. 非关系型数据库具有扩展简单、高并发、高稳定性、成本低廉的优势。
5. 可以实现数据的分布式处理。
缺点
1. 非关系型数据库暂时不提供 SQL 支持,学习和使用成本较高。
2. 非关系数据库没有事务处理,没有保证数据的完整性和安全性。适合处理海量数据,但是不一定安全。
3. 功能没有关系型数据库完善。

若有收获,就点个赞吧
0 人点赞
