input.xml
<?xml version="1.0"?><actors xmlns:fictional="http://characters.example.com"xmlns="http://people.example.com"><actor><name>John Cleese</name><fictional:character>Lancelot</fictional:character><fictional:character>Archie Leach</fictional:character></actor><actor><name>Eric Idle</name><fictional:character>Sir Robin</fictional:character><fictional:character>Gunther</fictional:character><fictional:character>Commander Clement</fictional:character></actor></actors>
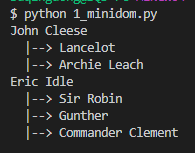
1 xml.dom.minidom(推荐*)
from xml.dom import minidomtree = minidom.parse('input.xml')actors = tree.getElementsByTagName('actor')for actor in actors:name = actor.getElementsByTagName('name')[0].firstChild.nodeValueprint namefor character in actor.getElementsByTagName('fictional:character'):print ' |-->', character.firstChild.nodeValue
2 bs4(不推荐)
需要全部读入,适用于文件不太大
import bs4with open('input.xml') as f:try:soup = bs4.BeautifulSoup(f.read(), 'lxml') # use lxml parser, faster then defaultexcept:soup = bs4.BeautifulSoup(f.read(), 'html.parser') # default parser# 不能用soup.select('fictional:character')for actor in soup.find_all('actor'):print actor.find_all('name')[0].textfor character in actor.find_all('fictional:character'):print ' |-->', character.text
3 xml.etree.ElementTree/cElementTree(推荐**)
try:import xml.etree.cElementTree as ET # cElementTree is fasterexcept ImportError:import xml.etree.ElementTree as ETinfile = 'ns.xml'tree = ET.parse(infile)root = tree.getroot()# 该文件中含有两个命名空间:# 特定的fictional xmlns:fictional="http://characters.example.com"# 默认的 xmlns="http://people.example.com"# 寻找元素时,不带fictional的元素即为默认的# 下面自己设置了命名空间的映射,其中foo, bar可随意起名ns = {'foo': 'http://people.example.com','bar': 'http://characters.example.com'}for actor in root.findall('foo:actor', ns):print actor.find('foo:name', ns).textfor character in actor.findall('bar:character', ns):print ' |-->', character.text
4 lxml.etree(推荐*)
import lxml.etree as ETtree = ET.parse('input.xml')root = tree.getroot()ns = root.nsmap # 自动获取namespace映射# print ns# {'fictional': 'http://characters.example.com', None: 'http://people.example.com'}for actor in root.findall('actor', ns):print actor.find('name', ns).textfor character in actor.findall('fictional:character', ns):print ' |-->', character.text
5 xml.parsers.expat(不确定)
据说速度较快,不过用起来比较麻烦,还未测试
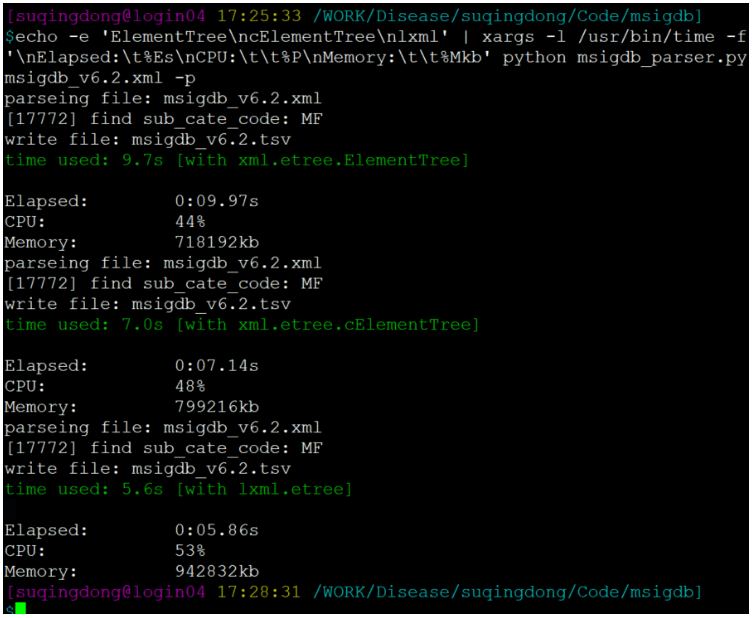
PS: 测试比较
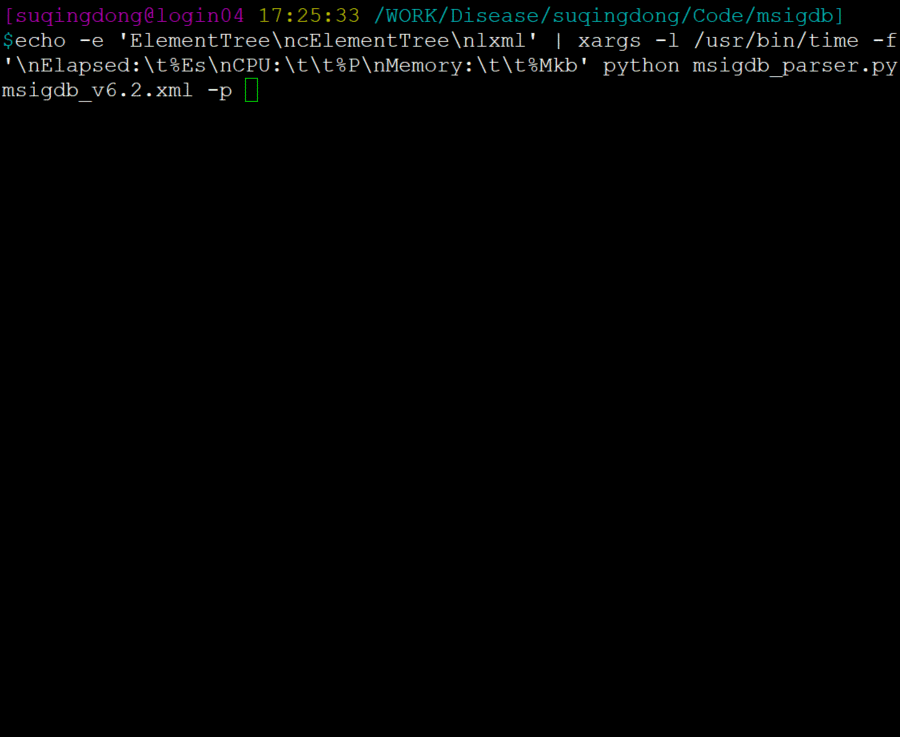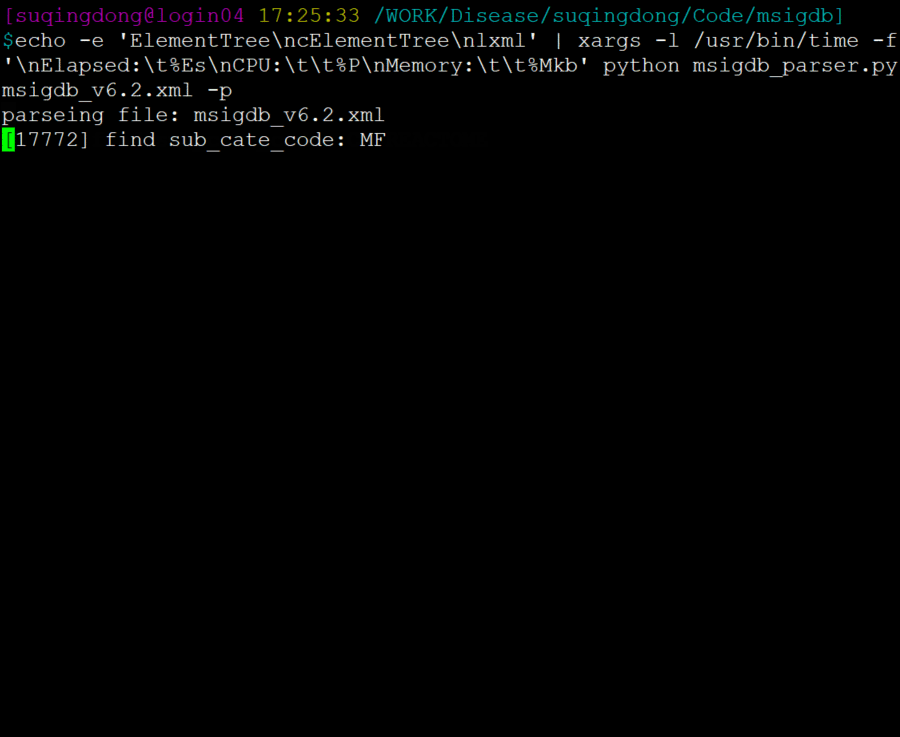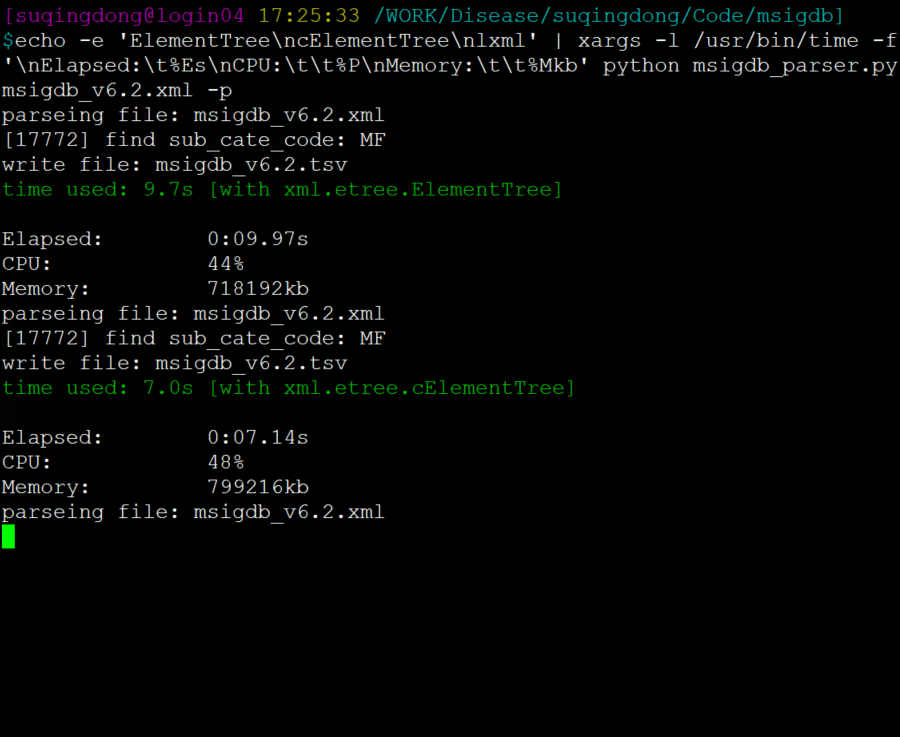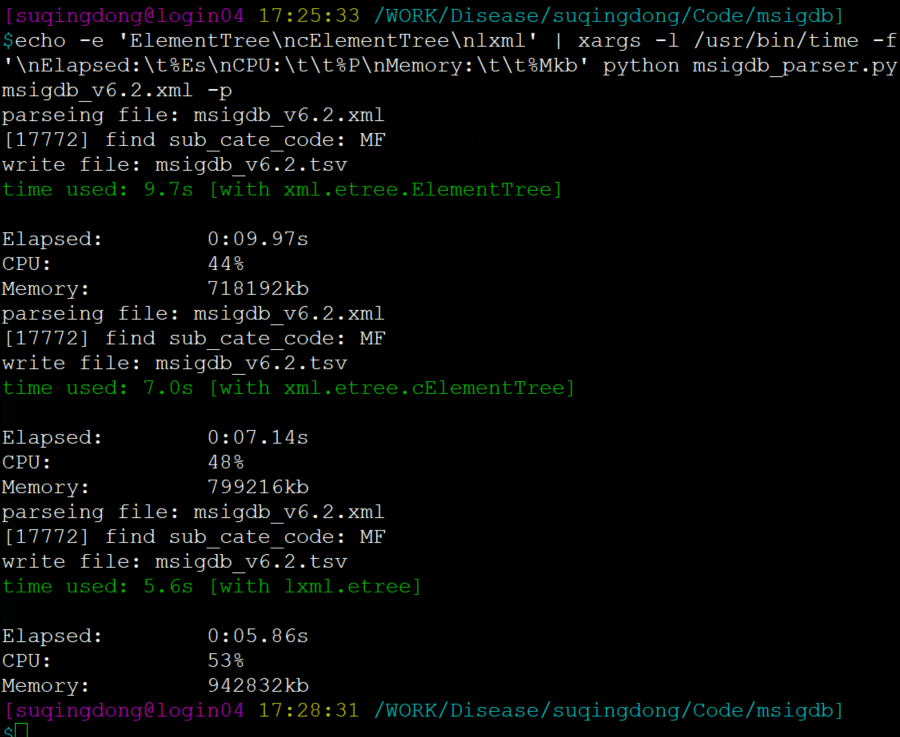

若有收获,就点个赞吧
0 人点赞
