前言
刚入职的时候,我觉得最大的挑战不是公司五花八门的技术名词,或者写代码,而是design。因为code是可以学习的,各种名词缩写公司也会给你时间去适应,但是系统设计,如果没有真实的生产经验,无论说什么,其实都是纸上谈兵。
**其实作为新人入职,公司也不会让你马上就去架构一个系统,但是作为组里的一员,一定会参与到各种各样的设计讨论和会议中。而当参加这种讨论的时候,你知道怎么去提出质疑吗?怎么样和对方argue吗?如果想尽快升职,尽快可以自己独立开发项目,这种会议,从刚入职开始,就不要一言不发,什么都说不上来。今天的内容就是帮助你解决这个问题。
解决这个问题,我们首先要知道什么是一个好的设计。我的回答就是:
一个好的设计,一定是高性能,高可用,和安全的。
性能的四个指标
响应时间:指应用系统从发出请求开始,到收到最后响应数据所需要的时间。响应时间是系统最重要的性能指标,最直接地反映了系统的快慢。
并发数:指系统同时处理的请求数,这个数字反映了系统的负载特性。比如对于一个互联网应用来说,并发数就是同时提交请求的用户数目。
**吞吐量:指单位时间内系统处理请求的数量,体现的是系统的处理能力。我们一般用TPS 是每秒事务数,或者 QPS,每秒的查询数来表示。吞吐量、响应时间和并发数这三个指标之间是有关联性的,响应时间越快,并发数越大,吞吐量也就越高。
系统指标:服务器或者操作系统性能的一些指标数据,比如内存和CPU的使用情况、磁盘和网络 I/O 等等。在程序部署之后,监控系统去监控这些系统指标,一旦资源利用率超过我们设置的最大额度的时候,就会发出警报。
有关性能的问题:
- 预计负载多少?最大承载压力多少?
- TPS/QPS是多少?响应时间是多少?
- 需要多少CPU/Memory才能达到预期性能?
建设性意见:
- 缓存:通过缓存可以减少数据库的负载压力。
- 集群:通过负载均衡的手段,将多种应用服务器构建成一个集群,共同提供服务,以提高系统整体的处理能力。
- 消息队列:可以使系统不同应用和服务之间异步调用,不仅可以使请求发起方尽快的拿到响应,还有如果某个时段访问量特别高,可以相当于一个buffer,避免对系统过高的负载压力。
高可用的设计
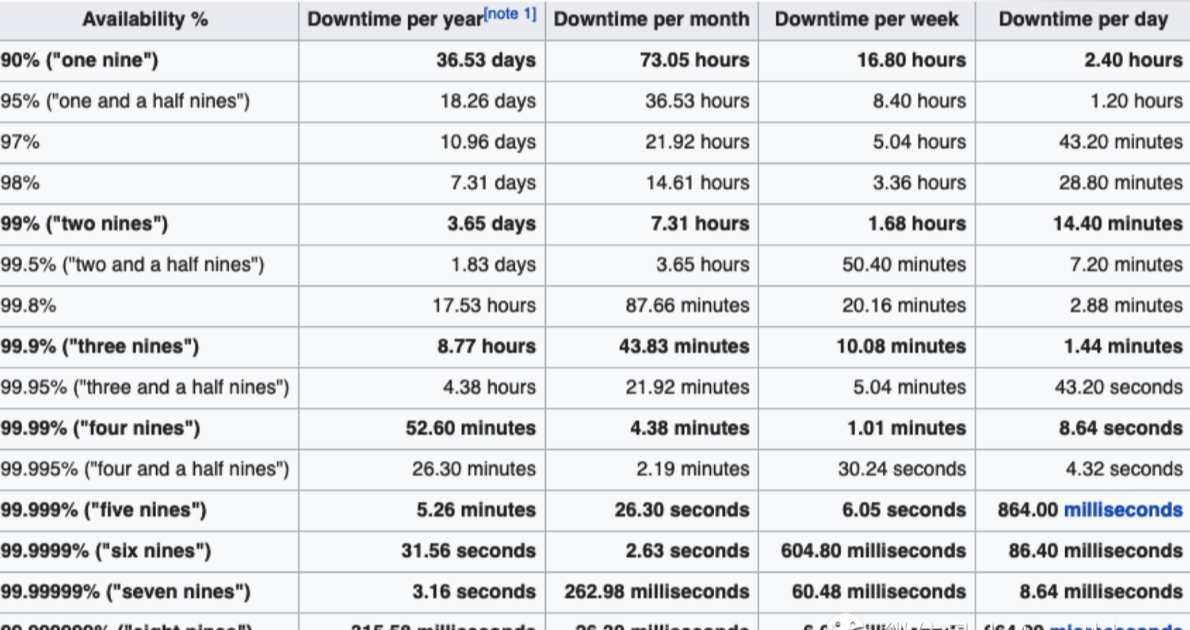
可用性的指标业界常用几个9来表示。下面是我在wikipedia上复制过来的表格。一般来说,2个9表示系统基本可用,3个9是较高可用,4个9 就可以算是高可用,5个9指极高的可用性。
**故障级别:
一级故障:网站整体不可用
二级故障:网站访问不顺畅,核心功能不可用
三级故障:核心功能少数用户不可用
四级或以上故障
可用性的优化:
1. 负载均衡
2. 数据库的主从模式和主主模式
3. 限流
4. 日志
5. 监控和警报
开会灵魂五问:
负载均衡(load balancer)用了吗?
会不会出现单点故障(Single point of failure) ?
数据库怎么复制?(主从,主主)
高并发怎么办?限流(Rate limiter)了吗?
如何写日志,做监控,发警报?
安全的设计
**安全类的话题专业性比较强,一般需要专业的安全行业知识,我这里只浅显地跟大家列举三种安全类问题。
- 网络攻击
**常见的防护手段是在代码中加强请求消息的过滤和SQL参数绑定,以及加验证模块和防火墙。
**
- 信息加密
**常见的加密方法有one way hashing,对称或者非对称加密。
**
- 信息过滤和反垃圾
**常用的技术手段是贝叶斯分类算法和布隆过滤器。大家可以看我的第四讲专题讲解布隆过滤器。
开会灵魂三问:
敏感数据加密了吗?
有验证模块吗?
服务之间是SSL/TLS吗?
**

若有收获,就点个赞吧
0 人点赞
