清音-如何对用户行为数据动态采集与分析
关键结构
测试环境 => 协商缓存
线上环境 => 强缓存
系统关键架构:左边对外,右边对内
数据采集
自动挂载:进入、离开、滚屏
手动挂载:点击、自定义
scroll 上报需要判断一定位置,避免无效上报
进入页面生成串联ID:a 标签 href = ‘xxx?utm=项目ID.页面ID.区块ID.坑位index.串联ID’
线上监控,埋点只是其中一环:行为采集,异常监控,性能监控
Q:串联 ID 的生成规则?串联 ID 叠加问题
Q:监控是否会影响端的性能
A:收集上报的数据量少,非全埋点上报
Q:app 内嵌 H5,H5 页面上报问题
A:采用 onload、unonload 采集,H5 采集 touch 事件
Q:是否存在非代码侵入的数据采集
A:建议采用代码侵入方式埋点,搭配搭建系统来埋点
凯伟-如何结合组件设计前端监控策略
痛点
业务痛点:会场效果如何?如何调优?调优是否高效?调优经验是否可复用?
开发痛点:相似组件开发多个,怎么证明那个组件效果好
埋点方案
埋点 => 采集 => 计算 => 分析
定位模型:站点、页面、组件、组件内部链接级别
监控模型
组件的优胜劣汰:丰富标签、效能统计(曝光、转化、加载、渲染、应用次数、失败次数)
Q:组件渲染成功与失败是怎么上报的
A:与搭建系统相关,跟进最终显示是否符合预期判断是否成功,失败的话上报系统
霸天-如何面向场景做监控数据分析
功能实现-spm超级位置模块标准
是什么:⽤来描述和追踪⻚⾯,模块,位置,标准的spm为 a.b.c.d.logId,5层编码结构组成,a为站点,b为⻚⾯,c为模块,d为位置
⽤来做什么:定位⻚⾯上的具体位置,确定不同区块的交互价值
如何管理:通过系统申请管理a,b位置,⾃定义c,d位置
与清音的串联 ID 相似
Allan-如何对PC/H5/小程序实现错误监控(多端)
背景
多端共存,平台/技术割裂,如何实现多端统一监控
多端:PC、H5、小程序、安卓、IOS
选择:为什么自己研发
- 使用第三方解决方案开销大、成本高
- 第三方解决方案不能完全满足需求,可拓展性差
- 自研优势:稳定性、一致性、扩展性、安全性和成本
实现:技术解析
错误收集与上报
错误捕获机制

AOP:面向切面编程;跨域脚本错误和 Vue 错误捕获可以用到,劫持再触发
环境收集
需要收集的信息:业务信息、设备信息、网络信息、SDK信息
收集方案:主动上报 => hybrid 接口获取 => UA 获取
行为收集
用户行为、浏览器行为、控制台打印行为
数据上报
使用 1 x 1 像素的 gif 图片
小结
SDK 一句话总结:监听/劫持原始方法,获取需要上报的数据,在错误发生时触发函数使用 gif 上报
数据清洗
- 获取数据:设置阈值削峰,错误超过 200 条只记录数量,不再入库
- 数据预处理:修正数据,忽略非法数据
- 数据聚合
- 聚合目的:优化存储性能,优化查询性能
- 聚合维度:业务名 + 错误类型 + 错误信息
Q:ES 为什么不能代替 mySql
A:ES 拿到的数据未做处理,索引方式是倒排索引,性能上有优势查询大量数据;而 mySql 是正排索引
能翔-如何基于错误日志进行分析和告警
错误聚合清洗
初级聚合:全内容散列聚合度低
解决方案:错误名 + 错误堆栈 + 系统类版本行号/方法链路去除 => 散列聚合 MD5
亚瑟-如何基于数据与堆栈映射定位问题
监控难点
- 难点:错误定位,堆栈映射,数据分析
- 信息缺失:信息无法全量获取,上下文缺失;代码混淆,堆栈无法直接使用
- 引起异常的因素多:环境因素、业务因素、复杂交互
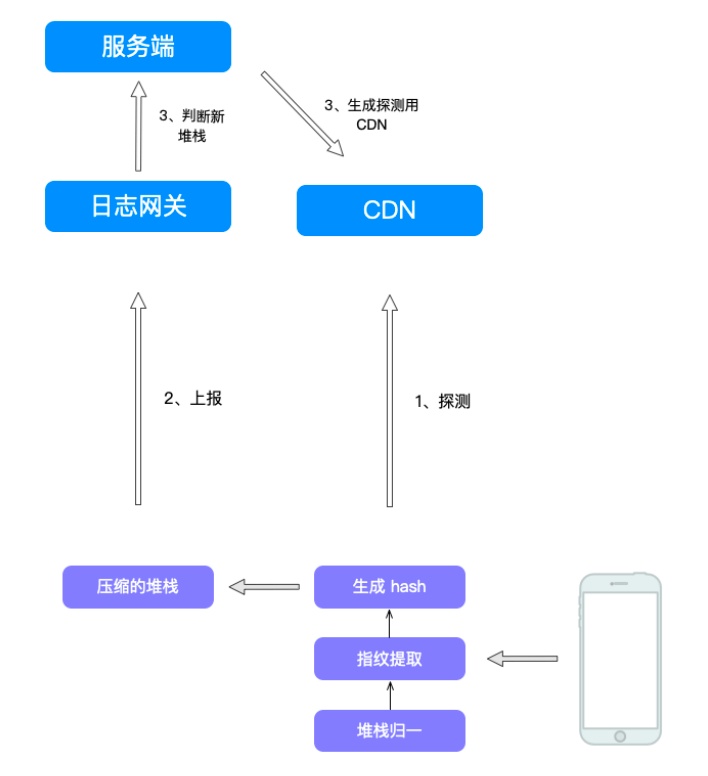
堆栈上报
- 全量堆栈上报问题
- 堆栈文本量大 + 重复上报无意义
- 影响性能,浪费带宽 + 浪费数据存储和计算资源
- 上报优化:堆栈压缩 + 防重复机制
堆栈探测流程(判断重复堆栈)
Q:souceMap
A:两个工具配合映射
烛象-如何设计前端实时分析与告警系统
小结
- 一份日志被两个系统所消费:一个清洗入库,另一个计算分析告警。保证实时性
- 监控
- 不止于前端,而是用户终端日志
Q:怎么过滤宿主干扰
A:宿主干扰通过过滤 .html 文件实现
QA:cef 框架开发钉钉桌面端,C++ 结合 webview
Q:单页应用如何处理上报 spmId
A:路由 session 中进行处理

若有收获,就点个赞吧
0 人点赞
