JAVA特别篇—HashMap
总览
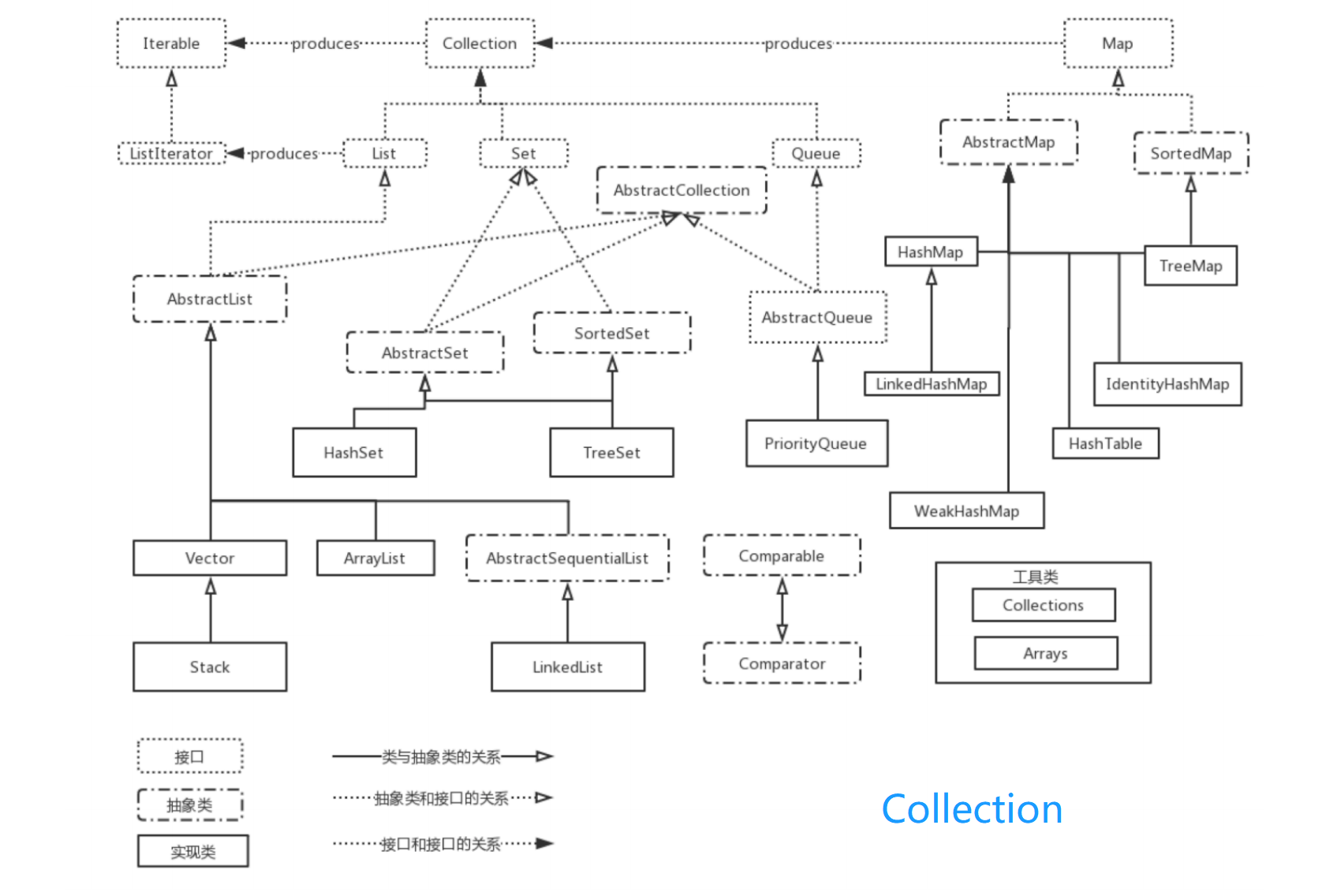
分类
- 集合
- Map(KV,Node数组,K唯一)
- HashMap
- LinkedHashMap
- TreeMap
- HashTable
- JUC:CurrentHashMap
- Collection
- List(有序可重复)
- ArrayList
- LinkedArrayList
- Vector
- JUC: CopyOnWriteArrayList
- Set(无序不可重复)
- HashSet
- TreeSet
- LinkedHashSet
- List(有序可重复)
- Map(KV,Node数组,K唯一)
Map和它的实现类
- hashMap
底层hash表实现,通过元素的hashcode确定存储位置,查询速度快,但遍历顺序不确定。hashMap只允许一个key为null但是可以多个value为null。 非线程安全的,多线程会出现不一致问题,可通过Collections的synchronizedMap()方法对HashMap进行包装,让hashMap具有线程安全的能力,或者使用ConcurrentHashMap. JDK1.8之前,底层通过hash表和链表实现,发生hash冲突时,同一位置形成链表,数据多时,查询会变成链表的遍历效率低。JDK1.8底层变成hash表和链表、红黑树实现,当链表中的元素个数超过8,转换为红黑树,避免遍历,优化了查询效率。
- HashTable
底层和JDK1.7的hashMap类似,但是K和V都不能为null,线程安全,每个方法都有synchronized关键字,可多线程使用
- TreeMap
底层二叉树,添加时排序,要求元素必须实现Comparable接口重写compareTo()方法,或创建treeMap时实现Comparator接口。
- LinkedHashMap
hashMap的一个子类,保存了插入顺序。
- 泛型和泛型擦除
泛型:可对类型进行抽象,让支持不同类型而重用,例如容器类ArrayList
,通过泛型可存储不同数据类型,并且泛型后市具体类型,避免了类型转换的麻烦。 泛型擦除:java的泛型是通过编译时实现的,生成的java字节码中是不存在泛型信息的,所以泛型信息,在编译器编译时会去除。所以List的泛型信息对JVM是不可见的,在他眼里都是Object类型。
- 泛型和泛型擦除
泛型:可对类型进行抽象,让支持不同类型而重用,例如容器类ArrayList
List和他的实现类
- 接口和实现类
List接口是Collection接口的子类接口。List接口的实现类都是有序可重复的。
- ArrayList
底层Object[]={}数组实现,特点是索引查找,支持随机访问,缺点增删慢。适合随机访问不适合插入删除。
- 初始为0,添加元素就变为10,超过后扩容,*1.5,(new = old+ old >> 1)复制到新数组
- LinkedList
- 初始为0,添加元素就变为10,超过后扩容,*1.5,(new = old+ old >> 1)复制到新数组
底层链表,适合动态增删,随机访问和遍历效率低。另外实现了Deque接口,所以拥有操作头元素、尾元素的方法,可用作栈和队列使用。
- Vector
底层数组,方法都加了同步锁,可多线程访问,效率低。
Set和他的实现类
- 无序不重复,存取顺序不同。
- 如何保证不重复
- HashSet(线程安全)
底层包装了HashMap去实现,HashSet采用HashCode算法来存取集合中的元素,因此具有较好的读取和查找性能。private static final Object PRESENT = new Object();//匹配Map中后面的对象的一个虚拟值。add()返回了map的put()方法,根据key的hashCode()决定value的位置,若key哈希值相同,存储位置相同,若key的equals相同,value覆盖,key不会覆盖。HashSet的add为false,添加失败。所以添加一个重复元素,不会覆盖原来的元素。 先hashcode()后equals()。
- 如何保证不重复
private transient HashMap<E,Object> map;// 用来匹配Map中后面的对象的一个虚拟值private static final Object PRESENT = new Object();/*** 将元素e添加到HashSet中,也就是将元素e作为Key放入HashMap中** @param e 要添加到HashSet中的元素* @return true 如果不包含该元素*/public boolean add(E e) {return map.put(e, PRESENT)==null;}//map的put方法public V put(K key, V value) {// 倒数第二个参数false:表示允许旧值替换// 最后一个参数true:表示HashMap不处于创建模式return putVal(hash(key), key, value, false, true);}//putVal()final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K, V>[] tab;Node<K, V> p;int n, i;//如果哈希表为空,调用resize()创建一个哈希表,并用变量n记录哈希表长度if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;/*** 如果指定参数hash在表中没有对应的桶,即为没有碰撞* Hash函数,(n - 1) & hash 计算key将被放置的槽位* (n - 1) & hash 本质上是hash % n,位运算更快*/if ((p = tab[i = (n - 1) & hash]) == null)//直接将键值对插入到map中即可tab[i] = newNode(hash, key, value, null);else {// 桶中已经存在元素Node<K, V> e;K k;// 比较桶中第一个元素(数组中的结点)的hash值相等,key相等if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))// 将第一个元素赋值给e,用e来记录e = p;// 当前桶中无该键值对,且桶是红黑树结构,按照红黑树结构插入else if (p instanceof TreeNode)e = ((TreeNode<K, V>) p).putTreeVal(this, tab, hash, key, value);// 当前桶中无该键值对,且桶是链表结构,按照链表结构插入到尾部else {for (int binCount = 0; ; ++binCount) {// 遍历到链表尾部if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);// 检查链表长度是否达到阈值,达到将该槽位节点组织形式转为红黑树if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}// 链表节点的<key, value>与put操作<key, value>相同时,不做重复操作,跳出循环if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}// 找到或新建一个key和hashCode与插入元素相等的键值对,进行put操作if (e != null) { // existing mapping for key// 记录e的valueV oldValue = e.value;/*** onlyIfAbsent为false或旧值为null时,允许替换旧值* 否则无需替换*/if (!onlyIfAbsent || oldValue == null)e.value = value;// 访问后回调afterNodeAccess(e);// 返回旧值return oldValue;}}// 更新结构化修改信息++modCount;// 键值对数目超过阈值时,进行rehashif (++size > threshold)resize();// 插入后回调afterNodeInsertion(evict);return null;}
- TreeSet
底层是二叉树的红黑树,插入时排序,可从Set中获取有序序列,前提是:元素必须实现Comparable接口,重写compareTo()方法。或者创建treeset时传入自定义的Comparator对象,否则运行时抛出java.lang.ClassCastException异常当插入元素时,会遍历元素(当然不是顺序遍历),并调用compareTo()根据返回的结果,决定插入位置,进而包装了顺序。
TreeSet的add() 返回的是TreeMap()的put()
public V put(K key, V value) { Entry<K,V> t = root; if (t == null) { compare(key, key); // type (and possibly null) check root = new Entry<>(key, value, null); size = 1; modCount++; return null; } int cmp; Entry<K,V> parent; // split comparator and comparable paths Comparator<? super K> cpr = comparator; if (cpr != null) { do { parent = t; cmp = cpr.compare(key, t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); } else { if (key == null) throw new NullPointerException(); @SuppressWarnings("unchecked") Comparable<? super K> k = (Comparable<? super K>) key; do { parent = t; cmp = k.compareTo(t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); } Entry<K,V> e = new Entry<>(key, value, parent); if (cmp < 0) parent.left = e; else parent.right = e; fixAfterInsertion(e); size++; modCount++; return null; }- LinkedHashSet,底层使用LinkedhashMap,用map的key唯一性保证不重复。 - 区别1、TreeSet是二叉树实现的,元素是自动排序的,不允许放入null 2、HashCode是哈希表实现的,数据无序,可放入null,但只能放入一个。
- 总的来说向Set添加元素时,首先比较HashCode编码,进而比较equals方法,若都返回true则数据相同,不插入,若都返回false插入数据,若哈希值相同equals不同则插入哈希桶(一个哈希值位置可顺延存多个值)。
- TreeSet排序-红黑树
红黑树规则左小右大。 既然可排序那么必定有排序规则。1、自定义比较规则2、指定排序规则。
- 方式一:元素自身具备比较性自身具备比较需要元素实现Comparable接口,重写compareTo方法,也就是让元素自身具备比较性,这种方式叫元素的自然排序也叫默认排序。
/** * @author Skiray * @date 2021/5/25 16:41 */ public class Person implements Comparable{ private Integer age; private String name; public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } @Override public String toString() { return "Person{" + "age=" + age + ", name='" + name + '\'' + '}'; } @Override public int compareTo(Object o) { Person p = (Person) o; System.out.println(this + "compareTo:" + p); if (this.age > p.age){ return 1; } if (this.age < p.age){ return -1; } //次级比较条件 return this.name.compareTo(p.name); } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Person person = (Person) o; return age.equals(person.age) && name.equals(person.name); } @Override public int hashCode() { return Objects.hash(age, name); } }- 方式二:容器具备比较性当元素自身不具备比较性,或者自身具备的比较性不是所需要的。那么此时可让容器自身具备。需定义一个类实现接口Comparator,重写compare方法,并将该接口的子类实例对象座位参数传递给TreeMap集合的构造方法。 当Comparable和Comparator同时存在,以Comparator为主。 注意:重写compareTo或compare方法,必须明确比较的注意条件相等时比较的次要条件。
class pp implements Comparator{
@Override
public int compare(Object o1, Object o2) {
Person p1 = (Person) o1;
Person p2 = (Person) o2;
System.out.println(p1 + "comparator" + p2);
if (p1.getAge() > p2.getAge()){
return 1;
}
if (p1.getAge() < p2.getAge()){
return -1;
}
return compare(p1.getName(),p2.getName());
}}
- 如何保持唯一性
- Comparable
- compareTo(Object o) 元素自身具备比较性
- Comparator
- compare(Object o1,Object o2) 给容器传入比较器
- 看到Array,就要想角标
- 看到Link,就要想first/last
- 看到Hash,就要想hashCode、equals
- 看到Tree,就要两个接口—Comparable-Comparator。

若有收获,就点个赞吧
0 人点赞
