顺序表
1.将两个有序表合并为一个新的有序顺序表,并由函数返回顺序表
算法思想:按照顺序不断取下两个顺序表表头较小的结点存入新的顺序表,然后看哪个表有剩余,将剩下的部分加到新的顺序表后面。
bool Merge(SqList A,SqList B,SqList &C){if(A.length+B.length>C.length)//表长超过return false;int i=0,j=0,k=0;while(i<A.length&&j<B.length){//循环两两比较if(A.data[i]<=B.data[i])C.data[k++]=A.data[i++];elseC.data[k++]=B.data[j++];}while(i<A.length)C.data[k++]=A.data[i++];while(j<B.length)C.data[k++]=B.data[j++];C.length=k;return true;}
2.搜索整个顺序表,查找并删除最小值元素并记录其位置,搜索结束后用最后一个元素填补空出的原最小值位置
bool Delete_Min(SqList &L,ElemType &value){if(L.length==0)return false;value=L.data[0];int pos=0;//假设0号元素值最小for(int i=1;i<L.length;i++){if(L.data[i]<value){value=L.data[i];pos=i;}}L.data[pos]=L.data[L.length-1];L.length--;return true;}
3.设将 n(n>1)个整数存放在一维数组 R 中。试着设计一个在时间复杂度和空间复杂度都尽可能高效的算法,将 R 中保存的序列循环左移 p ( 0<p<n ) 个位置, 即将 R 中 的 数 据 由 ( x0,x1, … ,xn-1 ) 变换为( xp, xp+1,…,xn-1,x0,x1,…,xp-1)。要求:
(1) 给出算法的基本设计思想;
(2) 根据算法设计思想,采用 C 或 C++语言描述,关键之处给出注释
(3) 说明你所设计算法的时间复杂度和空间复杂度
void Reverse(int R[],int left,int right){//将数组原地逆置int i=left,j=right;while(i<j){int temp=R[i];R[i]=R[j];R[j]=temp;i++;//i右移一个位置j--;//j左移一个位置}}void LeftShift(int R[],int n,int p){//将长度为n的数组R的数据循环左移p个位置if(p>0&&p<n){Reverse(R[],0,n-1);//将数组全部逆置Reverse(R[],0,n-p-1);//将前n-p个数据逆置Reverse(R[],n-p,n-1);}}
4.顺序结构La和Lb,元素按非递减顺序排列.试给出一个高效算法,将Lb元素合并到La中,并使合并后的La依旧保持非递减顺序排列,要求:最大限度避免移动元素
void Merge_AB(SqList &La,SqList Lb){int k=La.length+Lb.length-1;//合并后的La的最大下标int i=La.length-1,j=Lb.length-1;//La,Lb从后往前进行遍历while(i>=0&&j>=0){if(La.data[i]>=Lb.data[j]){La.data[k]=La.data[i];k--;i--;}else{La.data[k]=Lb.data[j];k--;j--;}}while(j>=0){La.data[k]=Lb.data[j];k--;j--;}La.length=La.length+Lb.length;return La;}
5.一个长度为N的整型数组A[1….N],给定整数X,请设计一个时间复杂度不超过O(nlog2n)的算法,查找出这个数组中所有两两之和等于X的整数对(每个元素只输出一次)
//先利用快排将数组元素进行排序int Partition(int A[],int low,int high){int pivot=A[low];while(low<high){while(low<high&&A[high]>=pivot)--high;A[low]=A[high];while(low<high&&A[ow]<pivot)++low;A[high]=A[low];}A[low]=pivot;return low;}void QuickSort(int A[],int low,int high){while(low<high){int pivotpos=Partition(A,low,high);QuickSort(A,0,pivotpos-1);QuickSort(A,pivotpos+1,high);}}void Find_sum_e(int A[].int N,int e){int i=0,j=N-1;QuickSort(A,0.N-1);while(i<j){int sum=A[i]+A[j];if(sum>e)j--;else if(sum<e)i++;else{printf("%d %d\n",A[i],A[j]);i++;j--;}}}
链表
1.将两个递增的有序链表合并为一个递增的有序链表。要求结果链表仍使用原来两个链表的存储空间,不另外占用其他的存储空间。表中不允许有重复的数据
void MergeList(LinkList &La,LinkList &Lb,LinkList &Lc){LNode *pa,*pb,*pc;pa=La->next;pb=Lb->next;pc=La;Lc=pc;while(pa&&pb){if(pa->data<pb->data){pc->next=pa;pc=pa;pa=pa->next;}else if(pa->data>pb->data){pc->next=pb;pc=pb;pb=pb->next;}else{q=pb->next;free(pb);pb=q;}}if(pa)pc->next=pa;elsepc->next=pb;free(Lb);}
2. 试编写在带头结点的单链表 L中删除一个最小值结点的高效算法(假设最小值结点是唯一的)。
LinkList Del_Min(LinkList &L){LNode *pre=L,*p=pre->next;LNode *minpre=pre,*minp=p;while(p!=NULL){if(p->data<min->data){minp=p;minpre=pre;}pre=p;p=p->next;}minpre->next=minp->next;free(minp);return L;}
3. 在带头结点的单链表 L 中,删除所有值为 x 的结点,并释放其空间,假设值为 x 的结点不唯一,试编写算法实现上述操作。
LinkList Del_x(LinkList &L,ElemType x){LNode *p=L->next,*pre=L;while(p!=NULL){if(p->data==x){q=p;p=p->next;pre->next=p;free(q);}else{pre=p;p=p->next;}}return L;}//采用尾插法建立单链表void Del_x(LinkList &L,ElemType x){LNode *p=L->next,*r=L,*q;while(p!=NULL){if(p->data!=x){r->next=p;r=p;p=p->next;}else{q=p;p=p->next;free(q);}}r->next=NULL;}
4. 试编写算法将带头结点的单链表就地逆置,所谓“就地”是辅助空间复杂度为 O(1)。
//头插法LinkList Reverse(LinkList &L){LNode *p,*r;//p为工作指针,r为p的后继,防止断链p=L->next;L->next=NULL;while(p!=NULL){r=p->next;p->next=L->next;L->next=p;p=r;}return L;}
5. 将一个带头结点的单链表 A 分解为两个带头结点的单链表 A 和 B,使得 A 表中含有原标中序号为奇数的元素,而 B 表中含有原表中序号为偶数的元素,
且保持其相对顺序不变。
LinkList DisCreat(LinkList &A){i=0;B=(LinkList*)malloc(sizeof(LNode));B->next=NULL;LNode *ra=A,*rb=B;//ra,rb分别指向A,B表的尾结点p=A->next;A->next=NULL;while(p!=NULL){i++;if(i%2==0){rb->next=p;rb=p;}else{ra->next=p;ra=p;}p=p->next;}ra->next=NULL;rb->next=NULL;return B;}
6. 设 C = {a1,b1,a2,b2,…,an,bn}为线性表,采用头结点的 hc 单链表存放, 设计一个就地算法,将其拆分为两个单链表,使得 A = {a1,
a2,…,an},B = {bn,…, b2,b1}。
LinkList DisCreat(LinkList &A){LinkList B=(LinkList)malloc(sizeof(LNode));B->next=NULL;LNode *p=A->next.*q;LNode *ra=A;while(p!=NULL){ra->next=p;ra=p;p=p->next;q=p->next;p->next=B->next;//头插后,*p将断链B->next=p;p=q;}ra->next=NULL;return B;}
7. 设计算法将一个带头结点的单链表A 分解为两个具有相同结构的链表 B 和 C,其中 B 表的结点为 A 表中小于零的结点,而 C 表中的结点为 A 表中值大于零的结点(链表 A 中的元素为非零整数,要求 B、C 表利用 A 表的结点)。
void Decompose(LinkList &A){B=(LinkList)malloc(sizeof(LNode));C=(LinkList)malloc(sizeof(LNode));B->next=NULL;C->next=NULL;p=A->next;while(p!=NULL){r=p->next;if(p->data<0){p->next=B->next;B->next=p;}else{p->next=C->next;C->next=p;}p=r;}}
8. 设计一个算法,通过一趟遍历确定长度为 n 的单链表中值最大的结点,返回该结点的数据域。
ElemType Max(LinkList L){if(L->next==NULL)return NULL;pmax=L->next;p=pmax->next;while(p!=NULL){if(p->data>pmax->data){pmax=p;}p=p->next;}return pmax->data;}
9. 设计一个算法,删除递增有序表中值大于 mink 且小于 maxk(mink 和 maxk是给定的两个参数,其值可以和表中的元素相同,也可以不同)的所有元素
void Del_mink_maxk(LinkList &L,int mink,int maxk){p=L->next;while(p&&p->data<=mink){pre=p;p=p->next;}while(p&&p->data<maxk)p=p->next;q=pre->next;pre->next=p;while(q!=p){s=q->next;free(q);q=s;}}
10. 在一个递增有序的线性表中,有数值相同的元素存在。若存储方式为单链表,设计算法去掉数值相同的元素,使表中不再具有重复的元素。
void Del_Same(LinkList &L){LNode *p=L->next,*q;if(p==NULL)return;while(p->next!=NULL){q=p->next;if(p->data==q->data){p->next=q->next;free(q);}elsep=p->next;}}
双指针策略思想(重点):
【2009 年统考】11. 已知一个带有表头结点的单链表,结点结构为:

假设该链表只给出了头指针 list。在不改变链表的前提下,请设计一个尽可能高效的算法,查找链表中 倒数第 k 个位置上的结点( k 为正整数)。若查找成功,算法输出该结点的 data 域的值,并返回 1;否则,只返回 0。要求:
(1) 描述算法的基本设计思想;
(2) 描述算法的详细实现步骤;
(3) 根据设计思想和实现步骤,采用程序设计语言描述算法(使用 C、C++语言实现),关键之处请给出简要注释。
(1) 【算法思想】
定义指针 p 和 q,初始化指针时均指向单链表的首元结点。首先将 p 沿链表移动 到第 k 个结点,而 q 指针保持不变,这样当 p 移动到第 k+1 个结点时,p 和 q 所指结点的间隔距离为 k。然后 p 和 q 同时向下移动,当 p 为 NULL 时,q 所指向的结点就是该链表倒数第 k 个结点。
(2) 【算法步骤】
①设定计数器 i = 0,用指针 p 和 q 指向首元结点
②从首元结点开始依顺着链表 link 依次向下遍历链表,若 p 为 NULL,则转向步骤⑤。
③若 i 小于 k,则 i+1;否则,q 指向下一个结点。
④p 指向下一个结点,转步骤②。
⑤若 i == k,则查找成功,输出该结点的 data 域的值,返回 1;否则,查找失败, 返回 0.
typedef struct LNode{int data;struct LNode *link;}LNode,*LinkList;int Search_k(LinkList list,int k){int i=0;//计数p=q=list->link;while(p!=NULL){if(i<k)i++;elseq=q->link;//q移动到下一个结点p=p->link;}if(i==k){printf("%d",q->data);return 1;}elsereturn 0;}
12.给定一个链表,判断链表中是否有环。如果有环,返回 1,否则返回 0。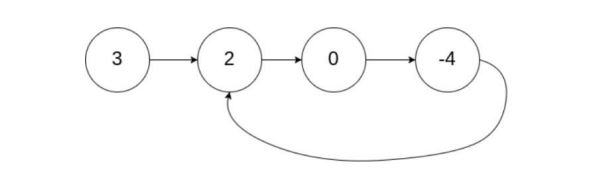
1)给出算法的基本思想
2)根据设计思想,采用 C 或 C++语言描述算法,关键之处给出注释
【算法思想】
快慢指针遍历链表,快指针步距为 2,慢指针步距为 1,如果链表带环,两指针一定会在环中相遇。
1、判断极端条件,如果链表为空,或者链表只有一个结点,一定不会带环,直
接返回 NULL。
2、创建快慢指针,都初始化指向头结点。因为快指针每次都要步进 2 个单位,
所以在判断其自身有效性的同时还要判断其 next 指针的有效性,在循环条件中
将两语句逻辑与并列起来。
初始化慢指针 slow = head,每次向后走一步;
初始化快指针 fast =head->next,每次走两步,每走一步判断一次。 如果存在环,
fast 和 slow 必定会相遇。
typedef struct LNode{int data;struct LNode *next;}LNode,*LinkList;int hasCycle(LinkList L){if(L.length==0||L->next=NULL)return 0;LNode *p=L->next;LNode *q=L;while(p!=q){if(p==NULL||p->next==NULL)return 0;p=p->next->next;q=q->next;}return 1;}
13.请写出在单链表中实现直接插入排序的算法
void Sort(LinkList L){LinkList p,pre,q,p1;p=L->next->next;L->next->next=NULL;while(p){pre=L;q=pre->next;while(q!=NULL&&q->data<p->data){pre=q;q=q->next;}p1=p->next;p->next=pre->next;pre->next=p;p=p1;}}
14.给定一个链表,两两交换其中相邻的结点,并返回交换后的链表。(不能只是单纯的交换值,需要进行实际的结点交换)如:A->B->C->D,应该返回B->A->D->C
LinkList Swap(LinkList L){if(L==NULL||L->next==NULL)return L;LNode *pre=L;LNode *prenext=L->next;LNode *cur=prenext->next;pre->next=cur;prenext->next=pre;L=prenext;//新的头结点while(cur!=NULL&&cur->next!=NULL){prenext=cur->next;//交换时第二个结点元素cur=prenext->next;pre->next->next=cur;prenext->next=pre->next;pre=prenext->next;}return L;}LinkList Swap(LinkList head){LNode *dummy=(LNode*)malloc(sizeof(LNode));dummy->next=head;LNode *first,*second,*current;current=dummy;while(current->next!=NULL&¤t->next->next!=NULL){//初始化双指针first=current->next;second=current->next->next;//交换顺序first->next=second->next;second->next=first;current->next=second;//更新指针current=current->next->next;}return dummy->next;}

若有收获,就点个赞吧
0 人点赞
