静态调度
静态调度,是指根据容器请求的资源进行装箱调度,而不考虑节点的实际负载。
举个例子:worker节点(ecs宿主机) 配置为4c,4g。 现在我们在这台ecs上去调度pod,pod大小为1c1g(这里先忽略request和limit的概念)。那么实际上是可以调度4个。 即使每一个pod实际上的cpu使用量、内存使用量连0.1都不到。
集群资源构成
以cpu资源为例,一个大规模Kubernetes集群的资源组成结构大致如下: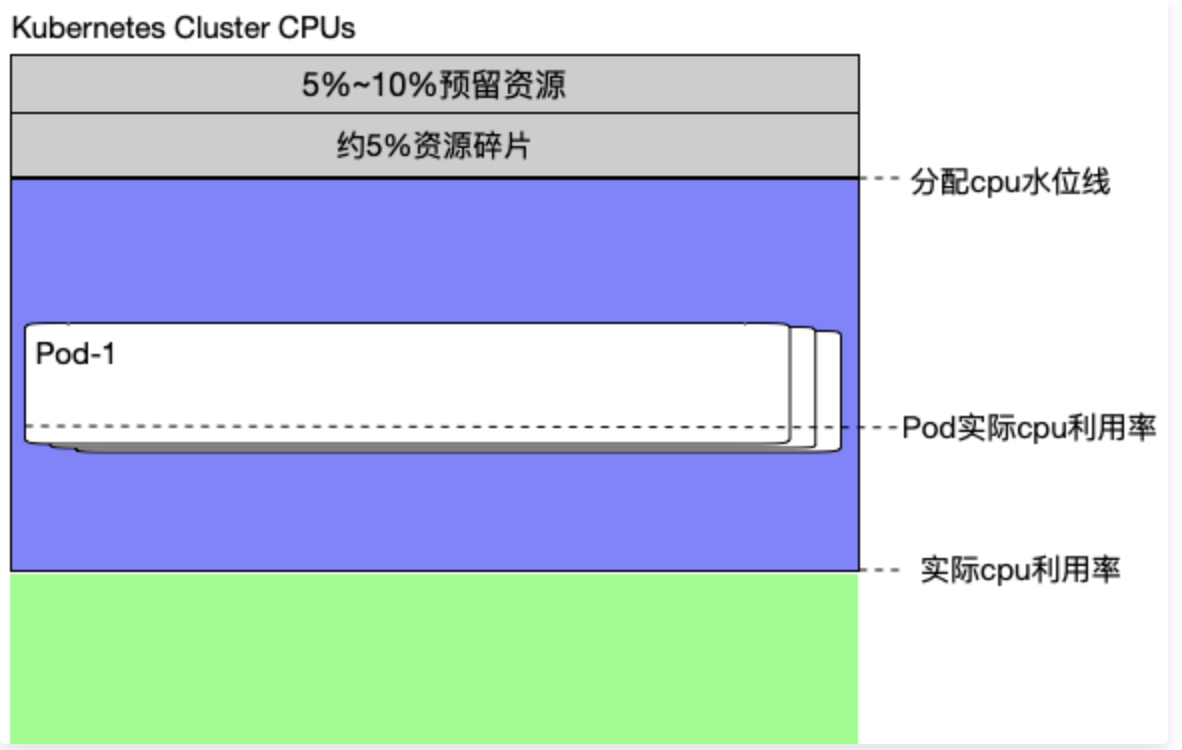
- 预留资源:就是每个节点给kube组件、system进程预留的资源,从而保证当节点出现满负荷时也能保证Kube和System进程有足够的资源。 可以通过kubelet的参数进行配置,例如:—system-reserved, —kube-reserved, —eviction-hard等。
- 资源碎片:每台宿主机上都难免会有多多少少的资源碎片。例如某个ecs上剩余1c 1g,而容器规格又是1c,2g或是2c 2g,都难以matc这部分资源。就会产生资源碎片。 按照常理来讲,每台ecs的配置越高,机器越少,资源碎片的占比越小。
- cpu水位线:指的是真正为pod/业务容器分配的cpu数量。当这个分配水位线达到node的allocatable时,将无法在往该node上调度容器。但是这里有一个问题,就是业务同学在设置容器配置大小的时候,往往都是主观性的,倾向性的(他们希望越大越好,这样自己的业务就大概率不会出现问题),这就导致分配水位线已经到到了很高的状态,但是实际利用率却很低,就像图中的状态一样。
提升资源利用率方案
这个方案大致分为几个方面。可以理解为由点到面的一种思路,一种是提升单个pod的资源利用率、第二种就是提升node的资源利用率、最后一种提升整个集群的资源利用率。
pod资源压缩
https://help.aliyun.com/document_detail/173702.html?spm=a2c4g.11186623.6.930.3eb51e4c0VJvWz
可以研究下阿里云提供的一个组件,Vertical Pod Autoscaler,动态的纵向修改pod资源配置。
node资源超卖
从上面集群资源构成部分我们可以看到,节点的资源利用率很低,但是水位线却很高,已经达到了上限,导致pod无法调度到该节点上。
那么我们能否通过动态调整allocatable的值来让计算节点的可分配资源变得”虚高”,骗过k8s的调度器,让它以为该节点可分配资源很大,让尽可能多的pod调度到该节点上呢?
实现资源超卖思路
基于node的监控数据,动态的、周期性的调整node资源的超卖比例。举个例子:当某个node持续3天负载很低,但是分配水位线已经非常高了,那我们就可以将这个node的超卖比例调大,也就是node的allocatable值调大,让k8s调度器以为这个node还有很多资源可以用阿里分配pod。
- 超卖比例:可以设置到node资源的Annotation注解中,比如cpu超卖对应Annotation stke.platform/cpu-oversale-ratio
- when?/ who?设置超卖比例:这里我们可以自己写一个服务,基于监控数据,动态的、周期性的去修改node资源的Annotation注解,即超卖比例。
- 修改allocatable。有了Annotation,那就可以根据Annotation设置的超卖比例动态的去修改node的allocatable值,来达到资源超卖的目的。
修改node的allocatable
针对如何修改node的allocatable值这里需要详细说一下。先看一下allocatable到底是什么。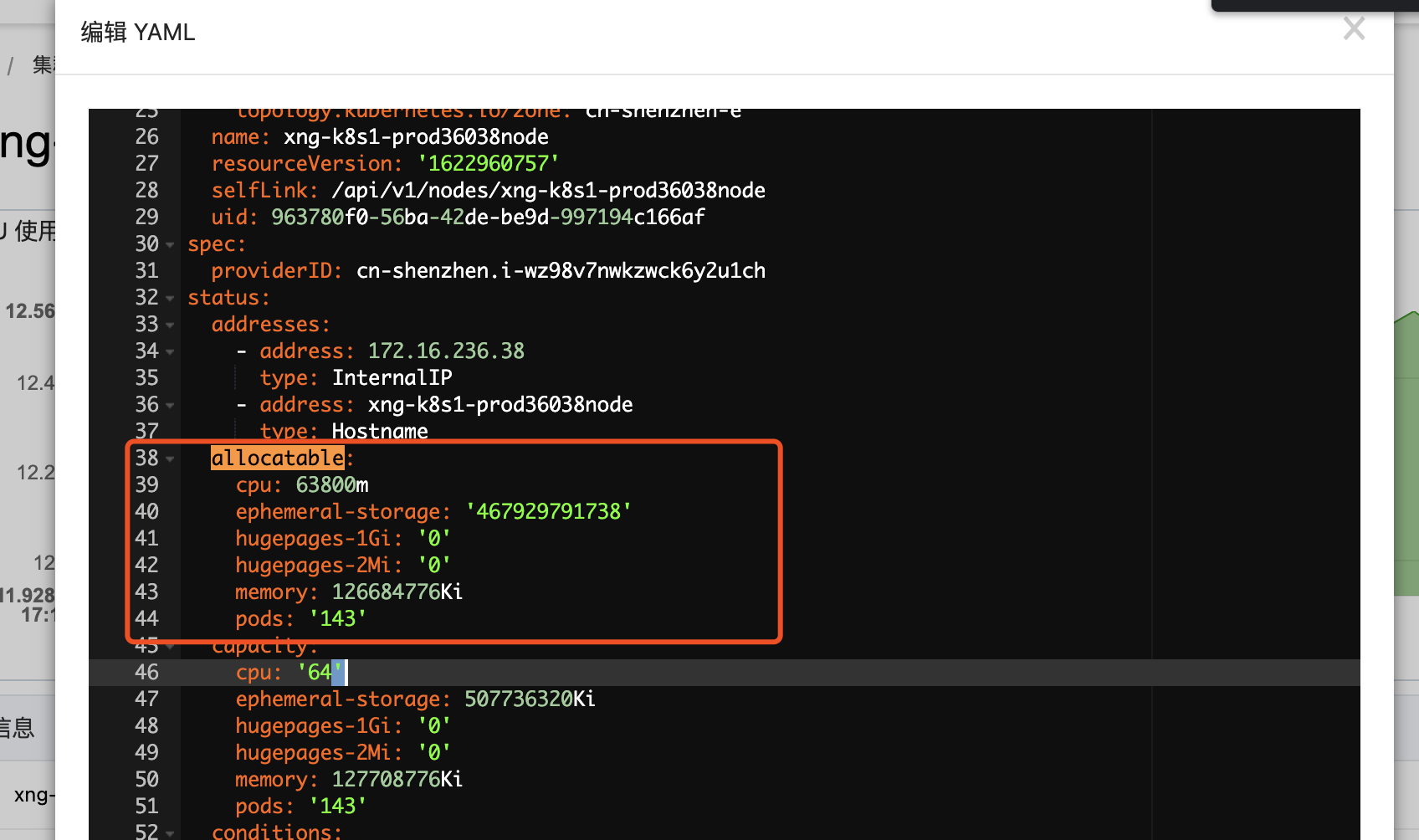
allocatable字段属于Status字段,不能直接通过kubectl edit命令来直接修改。因为Status字段和Spec字段不同,Spec是用户设置的期望数据,而Status是实时数据(Node节点通过不断向apiServer发送心跳来更新自己的实时状态,最终存在etcd中)。
修改status字段的值有一种方式就是通过k8s提供的restful api来修改。通过patch或者put方法来调用k8s的RESTful API,实现Stauts字段的修改。 但是这里有个问题,node每隔10s就会向api-server发送一次心跳,将带有Status字段的真实信息发送给ApiServer,并更新到etcd中。无论你怎么通过patch/put方法去修改Node的Status字段,计算节点都会定时通过发送心跳将真实的Status数据覆盖你修改的数据,也就是说我们无法通过直接调用RESTful API修改Node对象中的Status数据。
但是这里有个问题,node每隔10s就会向api-server发送一次心跳,将带有Status字段的真实信息发送给ApiServer,并更新到etcd中。无论你怎么通过patch/put方法去修改Node的Status字段,计算节点都会定时通过发送心跳将真实的Status数据覆盖你修改的数据,也就是说我们无法通过直接调用RESTful API修改Node对象中的Status数据。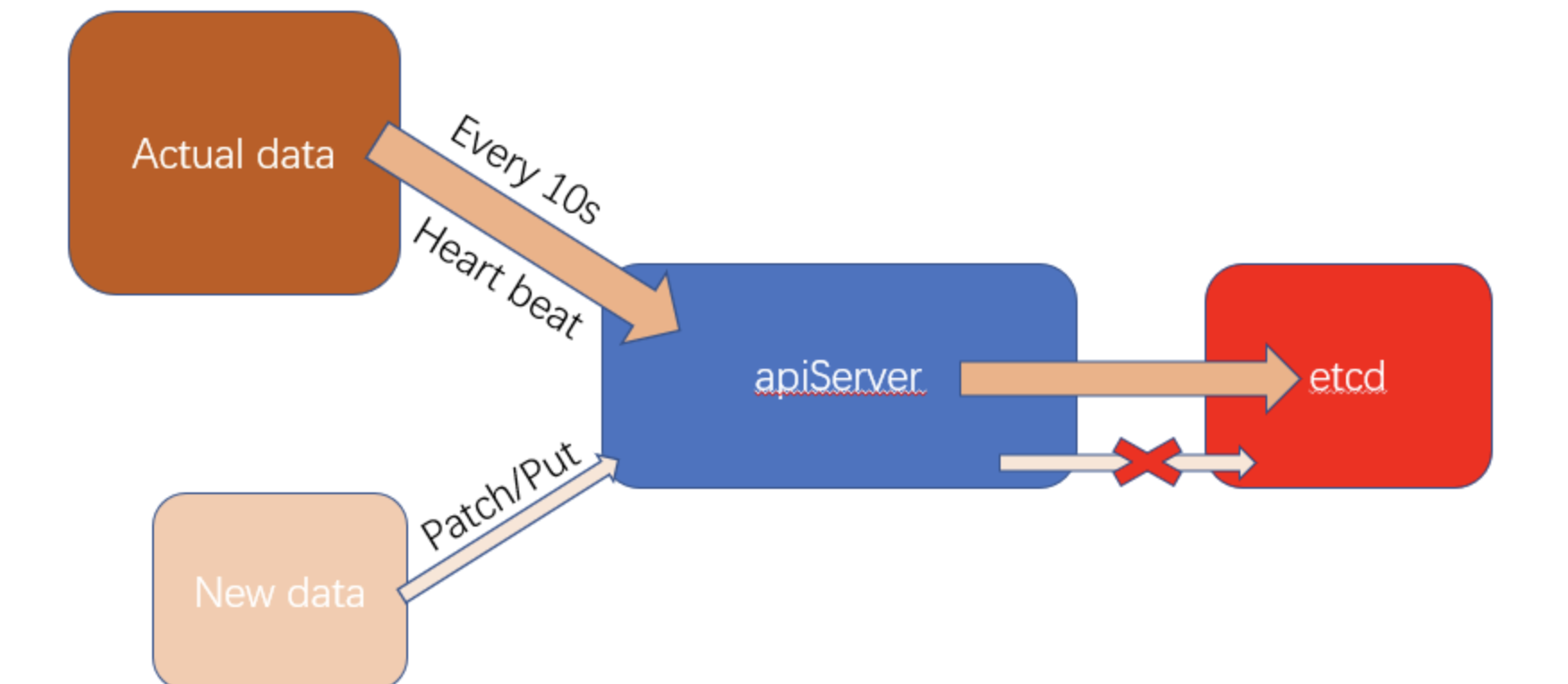
MutatingAdmissionWebhook
k8s在ApiServer中就提供了Admission Controller(准入控制器)的机制,其中包括了MutatingAdmissionWebhook,通过这个webhook,所有和集群中所有和ApiSever交互的请求都被发送到一个指定的接口中,我们只要提供一个这样的接口,就可以获取到Node往ApiServer发送心跳的Staus数据了。然后将这个数据进行我们的自定义修改,再往后传给etcd,就能让etcd以为我们修改过的Status数据就是节点的真实Status,最终实现资源的超卖。
MutatingAdmissionWebhook配置事例 ```yaml apiVersion: admissionregistration.k8s.io/v1beta1 kind: MutatingWebhookConfiguration metadata: creationTimestamp: null name: mutating-webhook-oversale webhooks: clientConfig: caBundle: … service:
name: webhook-oversale-servicenamespace: oversalepath: /mutate
failurePolicy: Ignore name: oversale rules:
- apiGroups:
- * apiVersions:
- v1 operations:
- UPDATE resources:
- nodes/status ```
clientConfig.service
- name: 指的是我们自定义的webhook服务的Service名
- namespace:服务的命名空间
- path:最终执行逻辑的借口路径
- rules:
- operations:监听apiServer的操作类型
- resources:监听apiServer的资源和子资源类型
Node资源超卖,表面上看起来很简单,但实际上要考虑的细节还很多:
- 当节点资源超卖后,Kubernetes对应的Cgroup动态调整机制是否能继续正常工作?
- Node status更新太频繁,每次status update都会触发webhook,大规模集群容易对apiserver造成性能问题,怎么解决?
- 节点资源超卖对Kubelet Eviction的配置是否也有超配效果,还是仍然按照实际Node配置和负载进行evict? 如果对Evict有影响,又该如解决?
- 超卖比例从大往小调低时,存在节点上 Sum(pods’ request resource) > node’s allocatable情况出现,这里是否有风险,该如何处理?
- 监控系统对Node的监控与Node Allocatable&Capacity Resource有关,超卖后,意味着监控系统对Node的监控不再正确,需要做一定程度的修正,如何让监控系统也能动态的感知超卖比例进行数据和视图的修正?
- Node Allocatable和Capacity分别该如何超卖?超卖对节点预留资源的影响是如何的?
总结:
我们可以自己写一个服务(或是找一下有没有可靠的开源服务),部署到k8s集群中。这个服务要实现的功能就是提供一个借口,用于api-server来进行webhook调用,逻辑大概就是根据node的Annotation设置的各种资源的超卖比例,来修改node中status.allocatable的值,Patch到APIServer。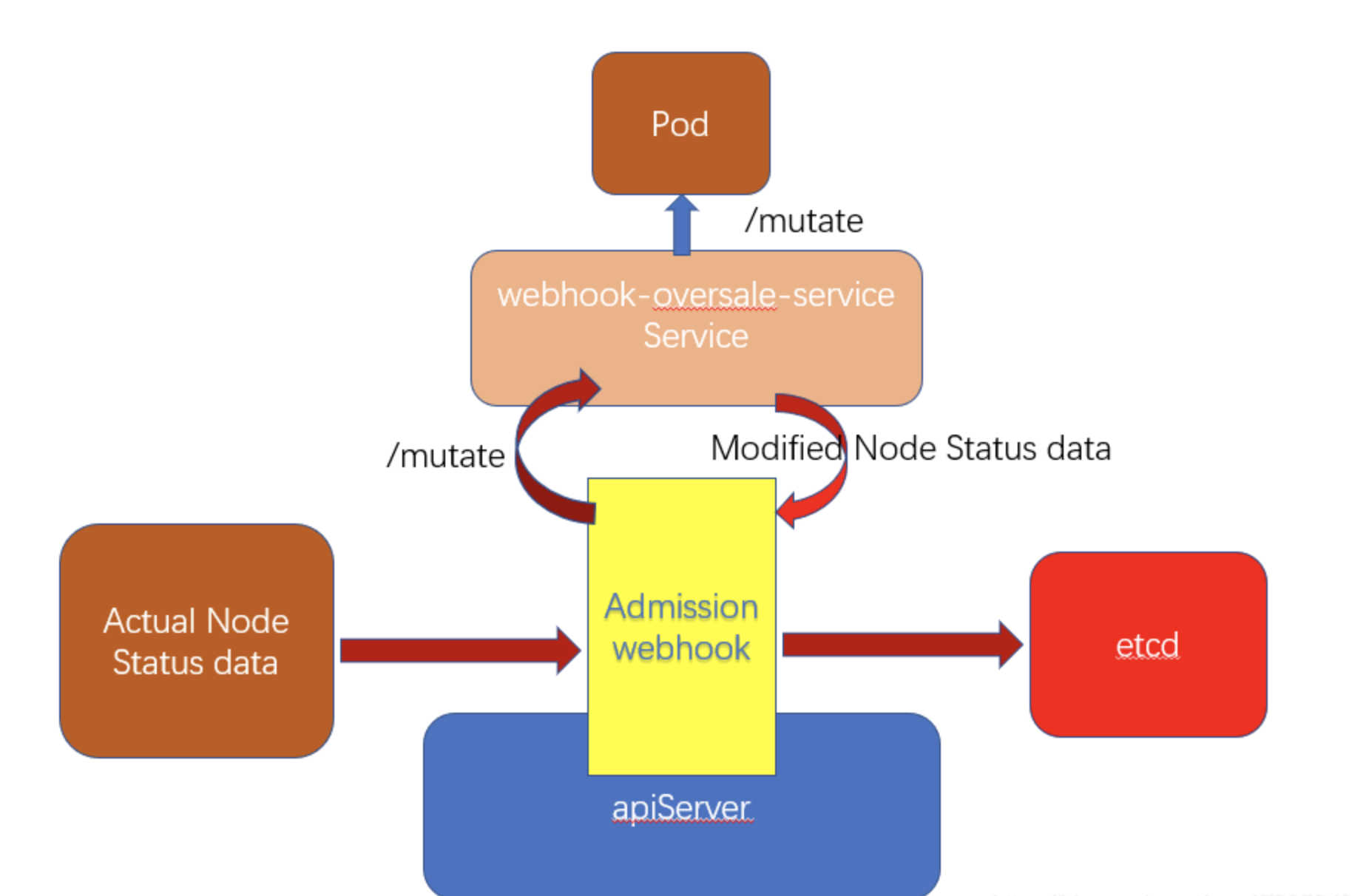
混合部署
- 将服务分为几类
- 计算型服务(高cpu消耗)
- 高内存消耗型
- io密集型
- 混合部署:利用k8s的pod亲和性等特性,将不同类型的服务部署到同一个节点上。
优点:好处就是充分理由资源
缺点:现有服务的类型单一,短期内难以实现。

若有收获,就点个赞吧
0 人点赞
