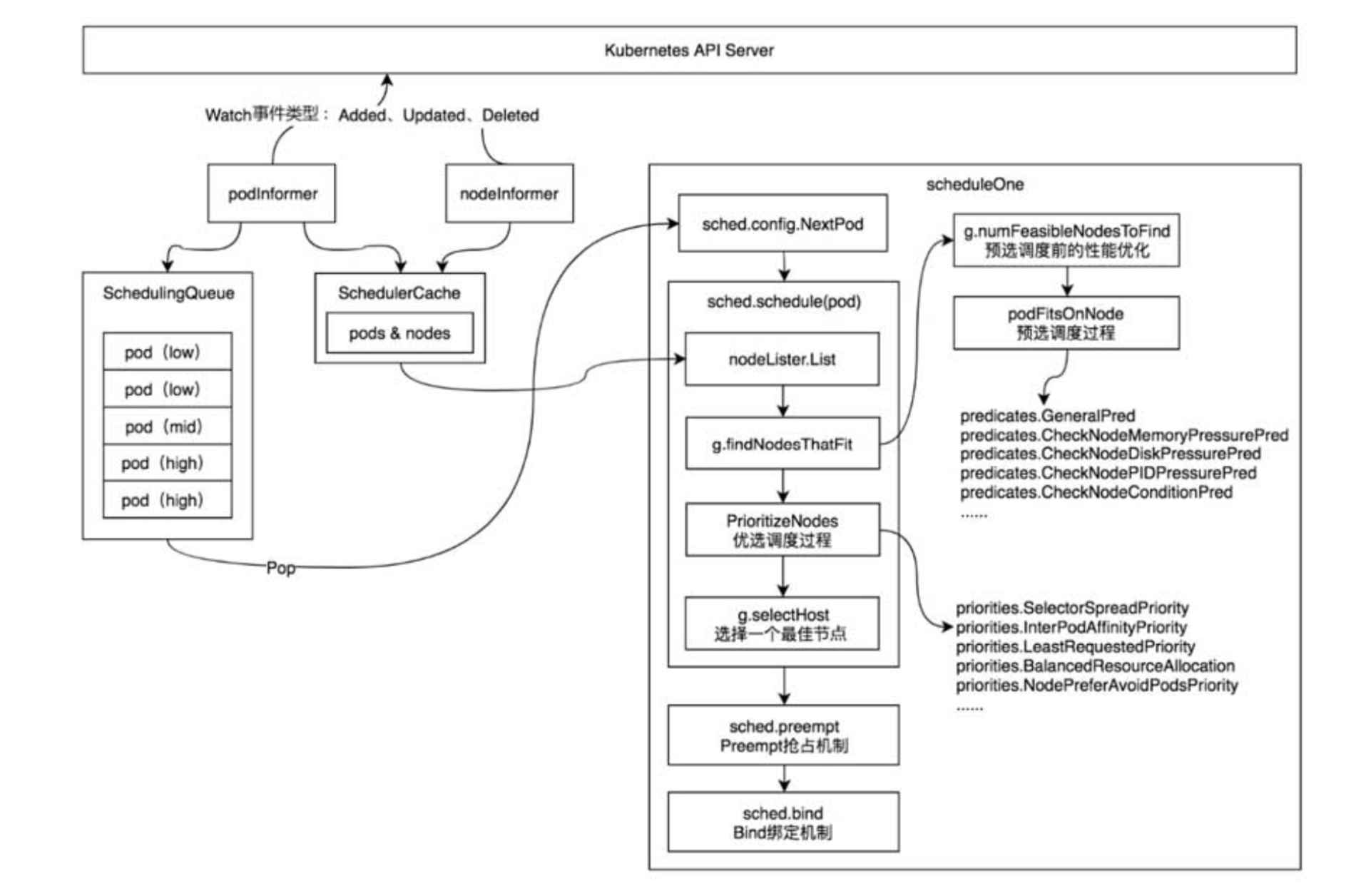
kubernetes 中所有组件的启动流程都是类似的,首先会解析命令行参数、添加默认值,kube-scheduler 的默认参数在 k8s.io/kubernetes/pkg/scheduler/apis/config/v1alpha1/defaults.go 中定义的。然后会执行 run 方法启动主逻辑,下面直接看 kube-scheduler 的主逻辑 run 方法执行过程。
Run() 方法主要做了以下工作:
- 初始化 scheduler 对象
- 启动 kube-scheduler server,kube-scheduler 监听 10251 和 10259 端口,10251 端口不需要认证,可以获取 healthz metrics 等信息,10259 为安全端口,需要认证
- 启动所有的 informer
执行 sched.Run() 方法,执行主调度逻辑
func Run(cc schedulerserverconfig.CompletedConfig, stopCh <-chan struct{}, registryOptions ...Option) error {......// 1、初始化 scheduler 对象sched, err := scheduler.New(......)if err != nil {return err}// 2、启动事件广播if cc.Broadcaster != nil && cc.EventClient != nil {cc.Broadcaster.StartRecordingToSink(stopCh)}if cc.LeaderElectionBroadcaster != nil && cc.CoreEventClient != nil {cc.LeaderElectionBroadcaster.StartRecordingToSink(&corev1.EventSinkImpl{Interface: cc.CoreEventClient.Events("")})}......// 3、启动 http serverif cc.InsecureServing != nil {separateMetrics := cc.InsecureMetricsServing != nilhandler := buildHandlerChain(newHealthzHandler(&cc.ComponentConfig, separateMetrics, checks...), nil, nil)if err := cc.InsecureServing.Serve(handler, 0, stopCh); err != nil {return fmt.Errorf("failed to start healthz server: %v", err)}}......// 4、启动所有 informergo cc.PodInformer.Informer().Run(stopCh)cc.InformerFactory.Start(stopCh)cc.InformerFactory.WaitForCacheSync(stopCh)run := func(ctx context.Context) {sched.Run()<-ctx.Done()}ctx, cancel := context.WithCancel(context.TODO()) // TODO once Run() accepts a context, it should be used heredefer cancel()go func() {select {case <-stopCh:cancel()case <-ctx.Done():}}()// 5、选举 leaderif cc.LeaderElection != nil {......}// 6、执行 sched.Run() 方法run(ctx)return fmt.Errorf("finished without leader elect")}
下面看一下 scheduler.New() 方法是如何初始化 scheduler 结构体的,该方法主要的功能是初始化默认的调度算法以及默认的调度器 GenericScheduler。
创建 scheduler 配置文件
- 根据默认的 DefaultProvider 初始化 schedulerAlgorithmSource 然后加载默认的预选及优选算法,然后初始化 GenericScheduler
若启动参数提供了 policy config 则使用其覆盖默认的预选及优选算法并初始化 GenericScheduler,不过该参数现已被弃用
func New(......) (*Scheduler, error) { ...... // 1、创建 scheduler 的配置文件 configurator := factory.NewConfigFactory(&factory.ConfigFactoryArgs{ ...... }) var config *factory.Config source := schedulerAlgorithmSource // 2、加载默认的调度算法 switch { case source.Provider != nil: // 使用默认的 ”DefaultProvider“ 初始化 config sc, err := configurator.CreateFromProvider(*source.Provider) if err != nil { return nil, fmt.Errorf("couldn't create scheduler using provider %q: %v", *source.Provider, err) } config = sc case source.Policy != nil: // 通过启动时指定的 policy source 加载 config ...... config = sc default: return nil, fmt.Errorf("unsupported algorithm source: %v", source) } // Additional tweaks to the config produced by the configurator. config.Recorder = recorder config.DisablePreemption = options.disablePreemption config.StopEverything = stopCh // 3.创建 scheduler 对象 sched := NewFromConfig(config) ...... return sched, nil }下面是 pod informer 的启动逻辑,只监听 status.phase 不为 succeeded 以及 failed 状态的 pod,即非 terminating 的 pod。
func NewPodInformer(client clientset.Interface, resyncPeriod time.Duration) coreinformers.PodInformer { selector := fields.ParseSelectorOrDie( "status.phase!=" + string(v1.PodSucceeded) + ",status.phase!=" + string(v1.PodFailed)) lw := cache.NewListWatchFromClient(client.CoreV1().RESTClient(), string(v1.ResourcePods), metav1.NamespaceAll, selector) return &podInformer{ informer: cache.NewSharedIndexInformer(lw, &v1.Pod{}, resyncPeriod, cache.Indexers{cache.NamespaceIndex: cache.MetaNamespaceIndexFunc}), } }然后继续看 Run() 方法中最后执行的 sched.Run() 调度循环逻辑,若 informer 中的 cache 同步完成后会启动一个循环逻辑执行 sched.scheduleOne 方法。
func (sched *Scheduler) Run() { if !sched.config.WaitForCacheSync() { return } go wait.Until(sched.scheduleOne, 0, sched.config.StopEverything) }func NewPodInformer(client clientset.Interface, resyncPeriod time.Duration) coreinformers.PodInformer { selector := fields.ParseSelectorOrDie( "status.phase!=" + string(v1.PodSucceeded) + ",status.phase!=" + string(v1.PodFailed)) lw := cache.NewListWatchFromClient(client.CoreV1().RESTClient(), string(v1.ResourcePods), metav1.NamespaceAll, selector) return &podInformer{ informer: cache.NewSharedIndexInformer(lw, &v1.Pod{}, resyncPeriod, cache.Indexers{cache.NamespaceIndex: cache.MetaNamespaceIndexFunc}), } }scheduleOne() 每次对一个 pod 进行调度,主要有以下步骤:
从 scheduler 调度队列中取出一个 pod,如果该 pod 处于删除状态则跳过
- 执行调度逻辑 sched.schedule() 返回通过预算及优选算法过滤后选出的最佳 node
- 如果过滤算法没有选出合适的 node,则返回 core.FitError
- 若没有合适的 node 会判断是否启用了抢占策略,若启用了则执行抢占机制
- 判断是否需要 VolumeScheduling 特性
- 执行 reserve plugin
- pod 对应的 spec.NodeName 写上 scheduler 最终选择的 node,更新 scheduler cache
- 请求 apiserver 异步处理最终的绑定操作,写入到 etcd
- 执行 permit plugin
- 执行 prebind plugin
- 执行 postbind plugin
k8s.io/kubernetes/pkg/scheduler/scheduler.go:515
func (sched *Scheduler) scheduleOne() {
fwk := sched.Framework
pod := sched.NextPod()
if pod == nil {
return
}
// 1.判断 pod 是否处于删除状态
if pod.DeletionTimestamp != nil {
......
}
// 2.执行调度策略选择 node
start := time.Now()
pluginContext := framework.NewPluginContext()
scheduleResult, err := sched.schedule(pod, pluginContext)
if err != nil {
if fitError, ok := err.(*core.FitError); ok {
// 3.若启用抢占机制则执行
if sched.DisablePreemption {
......
} else {
preemptionStartTime := time.Now()
sched.preempt(pluginContext, fwk, pod, fitError)
......
}
......
metrics.PodScheduleFailures.Inc()
} else {
klog.Errorf("error selecting node for pod: %v", err)
metrics.PodScheduleErrors.Inc()
}
return
}
......
assumedPod := pod.DeepCopy()
// 4.判断是否需要 VolumeScheduling 特性
allBound, err := sched.assumeVolumes(assumedPod, scheduleResult.SuggestedHost)
if err != nil {
klog.Errorf("error assuming volumes: %v", err)
metrics.PodScheduleErrors.Inc()
return
}
// 5.执行 "reserve" plugins
if sts := fwk.RunReservePlugins(pluginContext, assumedPod, scheduleResult.SuggestedHost); !sts.IsSuccess() {
.....
}
// 6.为 pod 设置 NodeName 字段,更新 scheduler 缓存
err = sched.assume(assumedPod, scheduleResult.SuggestedHost)
if err != nil {
......
}
// 7.异步请求 apiserver
go func() {
// Bind volumes first before Pod
if !allBound {
err := sched.bindVolumes(assumedPod)
if err != nil {
......
return
}
}
// 8.执行 "permit" plugins
permitStatus := fwk.RunPermitPlugins(pluginContext, assumedPod, scheduleResult.SuggestedHost)
if !permitStatus.IsSuccess() {
......
}
// 9.执行 "prebind" plugins
preBindStatus := fwk.RunPreBindPlugins(pluginContext, assumedPod, scheduleResult.SuggestedHost)
if !preBindStatus.IsSuccess() {
......
}
err := sched.bind(assumedPod, scheduleResult.SuggestedHost, pluginContext)
......
if err != nil {
......
} else {
......
// 10.执行 "postbind" plugins
fwk.RunPostBindPlugins(pluginContext, assumedPod, scheduleResult.SuggestedHost)
}
}()
}
scheduleOne() 中通过调用 sched.schedule() 来执行预选与优选算法处理:
func (sched *Scheduler) schedule(pod *v1.Pod, pluginContext *framework.PluginContext) (core.ScheduleResult, error) {
result, err := sched.Algorithm.Schedule(pod, pluginContext)
if err != nil {
......
}
return result, err
}
sched.Algorithm 是一个 interface,主要包含四个方法,GenericScheduler 是其具体的实现:
k8s.io/kubernetes/pkg/scheduler/core/generic_scheduler.go:131
type ScheduleAlgorithm interface {
Schedule(*v1.Pod, *framework.PluginContext) (scheduleResult ScheduleResult, err error)
Preempt(*framework.PluginContext, *v1.Pod, error) (selectedNode *v1.Node, preemptedPods []*v1.Pod, cleanupNominatedPods []*v1.Pod, err error)
Predicates() map[string]predicates.FitPredicate
Prioritizers() []priorities.PriorityConfig
}
- Schedule():正常调度逻辑,包含预算与优选算法的执行
- Preempt():抢占策略,在 pod 调度发生失败的时候尝试抢占低优先级的 pod,函数返回发生抢占的 node,被 抢占的 pods 列表,nominated node name 需要被移除的 pods 列表以及 error
- Predicates():predicates 算法列表
- Prioritizers():prioritizers 算法列表
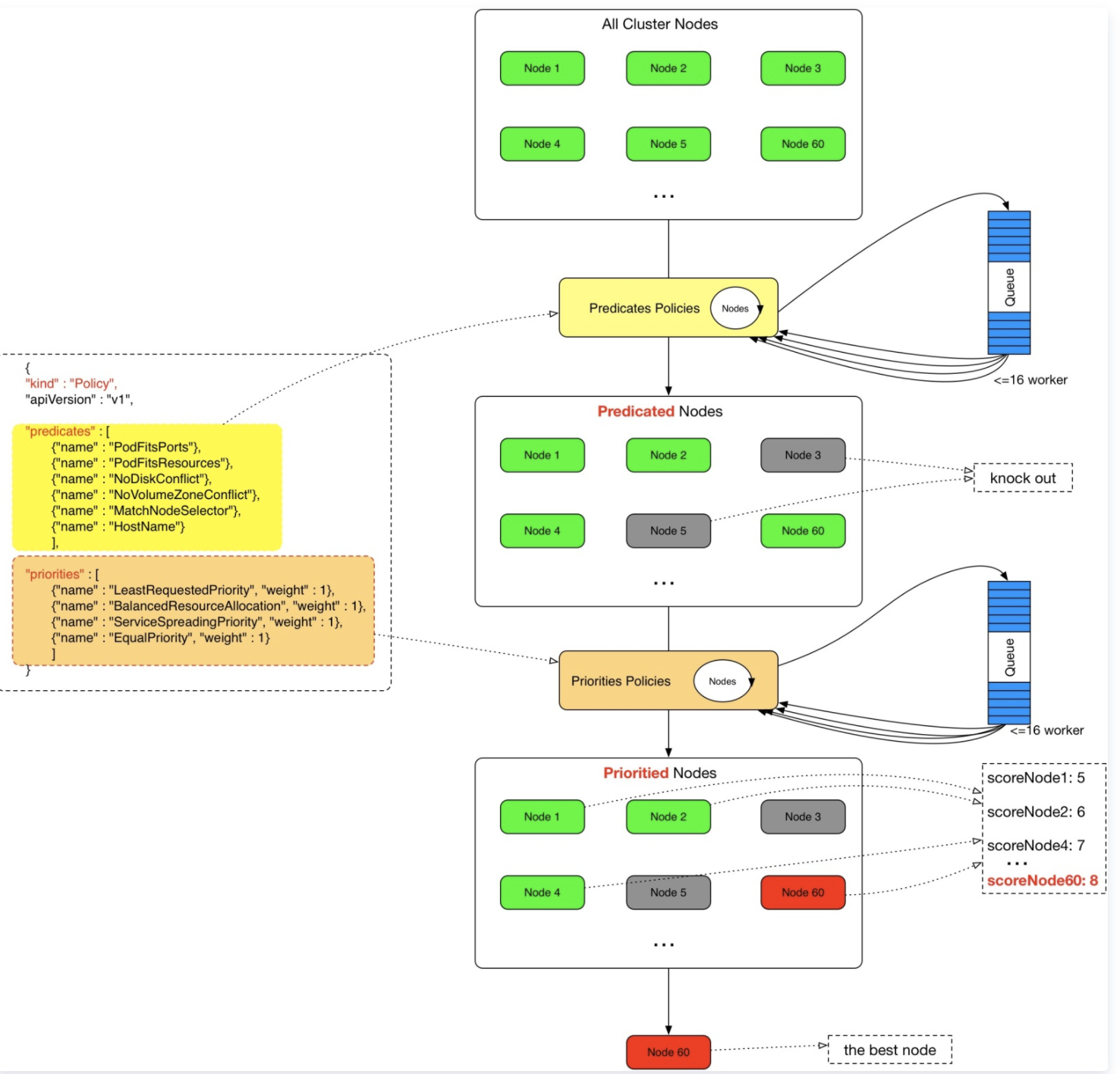
kube-scheduler 提供的默认调度为 DefaultProvider,DefaultProvider 配置的 predicates 和 priorities policies 在 k8s.io/kubernetes/pkg/scheduler/algorithmprovider/defaults/defaults.go 中定义,算法具体实现是在 k8s.io/kubernetes/pkg/scheduler/algorithm/predicates/ 和k8s.io/kubernetes/pkg/scheduler/algorithm/priorities/ 中,默认的算法如下所示:
pkg/scheduler/algorithmprovider/defaults/defaults.go
func defaultPredicates() sets.String {
return sets.NewString(
predicates.NoVolumeZoneConflictPred,
predicates.MaxEBSVolumeCountPred,
predicates.MaxGCEPDVolumeCountPred,
predicates.MaxAzureDiskVolumeCountPred,
predicates.MaxCSIVolumeCountPred,
predicates.MatchInterPodAffinityPred,
predicates.NoDiskConflictPred,
predicates.GeneralPred,
predicates.CheckNodeMemoryPressurePred,
predicates.CheckNodeDiskPressurePred,
predicates.CheckNodePIDPressurePred,
predicates.CheckNodeConditionPred,
predicates.PodToleratesNodeTaintsPred,
predicates.CheckVolumeBindingPred,
)
}
func defaultPriorities() sets.String {
return sets.NewString(
priorities.SelectorSpreadPriority,
priorities.InterPodAffinityPriority,
priorities.LeastRequestedPriority,
priorities.BalancedResourceAllocation,
priorities.NodePreferAvoidPodsPriority,
priorities.NodeAffinityPriority,
priorities.TaintTolerationPriority,
priorities.ImageLocalityPriority,
)
}
下面继续看 sched.Algorithm.Schedule() 调用具体调度算法的过程:
- 检查 pod pvc 信息
- 执行 prefilter plugins
- 获取 scheduler cache 的快照,每次调度 pod 时都会获取一次快照
- 执行 g.findNodesThatFit() 预选算法
- 执行 postfilter plugin
- 若 node 为 0 直接返回失败的 error,若 node 数为1 直接返回该 node
- 执行 g.priorityMetaProducer() 获取 metaPrioritiesInterface,计算 pod 的metadata,检查该 node 上是否有相同 meta 的 pod
- 执行 PrioritizeNodes() 算法
- 执行 g.selectHost() 通过得分选择一个最佳的 node
k8s.io/kubernetes/pkg/scheduler/core/generic_scheduler.go:186
func (g *genericScheduler) Schedule(pod *v1.Pod, pluginContext *framework.PluginContext) (result ScheduleResult, err error) {
......
// 1.检查 pod pvc
if err := podPassesBasicChecks(pod, g.pvcLister); err != nil {
return result, err
}
// 2.执行 "prefilter" plugins
preFilterStatus := g.framework.RunPreFilterPlugins(pluginContext, pod)
if !preFilterStatus.IsSuccess() {
return result, preFilterStatus.AsError()
}
// 3.获取 node 数量
numNodes := g.cache.NodeTree().NumNodes()
if numNodes == 0 {
return result, ErrNoNodesAvailable
}
// 4.快照 node 信息
if err := g.snapshot(); err != nil {
return result, err
}
// 5.执行预选算法
startPredicateEvalTime := time.Now()
filteredNodes, failedPredicateMap, filteredNodesStatuses, err := g.findNodesThatFit(pluginContext, pod)
if err != nil {
return result, err
}
// 6.执行 "postfilter" plugins
postfilterStatus := g.framework.RunPostFilterPlugins(pluginContext, pod, filteredNodes, filteredNodesStatuses)
if !postfilterStatus.IsSuccess() {
return result, postfilterStatus.AsError()
}
// 7.预选后没有合适的 node 直接返回
if len(filteredNodes) == 0 {
......
}
startPriorityEvalTime := time.Now()
// 8.若只有一个 node 则直接返回该 node
if len(filteredNodes) == 1 {
return ScheduleResult{
SuggestedHost: filteredNodes[0].Name,
EvaluatedNodes: 1 + len(failedPredicateMap),
FeasibleNodes: 1,
}, nil
}
// 9.获取 pod meta 信息,执行优选算法
metaPrioritiesInterface := g.priorityMetaProducer(pod, g.nodeInfoSnapshot.NodeInfoMap)
priorityList, err := PrioritizeNodes(pod, g.nodeInfoSnapshot.NodeInfoMap, metaPrioritiesInterface, g.prioritizers, filteredNodes, g.extenders, g.framework, pluginContext)
if err != nil {
return result, err
}
// 10.根据打分选择最佳的 node
host, err := g.selectHost(priorityList)
trace.Step("Selecting host done")
return ScheduleResult{
SuggestedHost: host,
EvaluatedNodes: len(filteredNodes) + len(failedPredicateMap),
FeasibleNodes: len(filteredNodes),
}, err
}
总结
本文主要对于 kube-scheduler v1.16 的调度流程进行了分析,但其中有大量的细节都暂未提及,包括预选算法以及优选算法的具体实现、优先级与抢占调度的实现、framework 的使用及实现,因篇幅有限,部分内容会在后文继续说明。

若有收获,就点个赞吧
0 人点赞
