设置大小
- 其实是缓冲页的大小(概念见下方)
- 默认 128MB
- 32g内存可以设置 2g 内存
- 单位字节
[server]innodb_buffer_pool_size=2147483648
- 单位字节
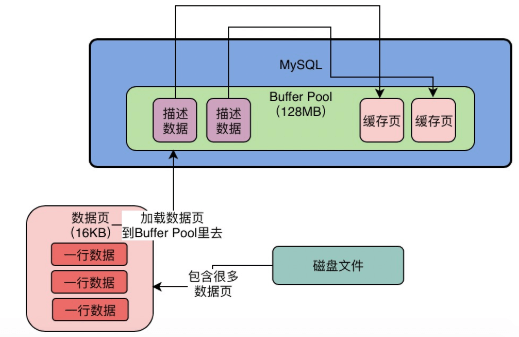
数据页
- MySQL 将磁盘中的数据抽象为数据页
- 数据页中包含多行数据
- 默认 16kb
Buffer Pool 加载数据页
- Buffer Pool 会加载数据页为缓冲页,所以 Buffer Pool 中的缓冲页和磁盘的数据页的大小是对应的,即都是 16kb
Buffer Pool 结构
- 每个缓冲页都有一个对应的描述信息
- 记录对应缓冲页所属的表空间、编号、在 Buffer Pool 中的地址和其他信息
- 这些数据如何存放?
- 这批描述信息会放在 Buffer Pool 的前面,然后才是一批对应的缓冲页
- 这些描述信息会占据的内存大概为缓冲页的 5%
- 如果 Buffer Pool 为默认大小,所以描述信息会有 800kb 的样子
- Buffer Pool 实际会占据128MB + 800kb 的大小
如何初始化?
- MySQL 启动的时候,向 os 申请
innodb_buffer_pool_size+ 5% 额外大小(缓冲页所需的消息信息) 的空间作为 Buffer Pool 的内存空间 - 然后按照 16kb 的缓冲页大小 + 800kb 对应的详细信息块 在 Buffer Pool 中将缓冲页和对应的详细信息进行一一划分
- 缓冲页的内容是空的
如何判断哪些缓冲页是空的?
- MySQL 会维护一个 free 链表 ,是一个双向链表,它的节点是存储那些空闲缓冲页的详细信息块的地址
- 所以初始化 MySQL 的时候,所有 详细信息块会存储在 free 链表中
- 并且有一个额外节点,指向 free 链表的头节点和尾节点,内容为 free 链表中存在的详细信息块的个数
free 链表占据的空间?
- 其实 free 链表就是 基于 Buffer Pool 中的 详细信息块作为节点 来实现的
- 就在详细信息块中使用
free_pre+free_next两个指针来实现双向链表 - 如果有一个详细信息块对应的缓冲页需要被使用,那么将于该详细信息块相关的另外两块信息块的指针进行修改即可,并且修改额外节点的个数
- 就在详细信息块中使用
- 所以 free 链表占据的空间 只有一个不属于 Buffer Pool 的额外节点,大概 20kb
如何判断哪些数据页被加载进了 Buffer Pool?
- MySQl 会有一个 数据页缓存哈希表
- k:v -> 表空间号+数据页号: 缓冲页地址
- 如果没有找到,说明当前数据页没有被加载进 Buffer Pool 的缓冲页中
数据加载过程版本1
- 先根据 表空间号+数据页号 从 数据页缓存哈希表中查找是否有对应的缓冲页
- 有,说明 Buffer Pool 有对应的缓冲页,通过哈希表获得的值就可以拿到该缓冲页的地址
- 没有,说明 Buffer Pool 没有对应的缓冲页
- 先从 free 链表 中拿一个详细信息块,将相关的描述信息写入、修改与之相关的其他节点的指针(
free_pre+free_next)、修改额外节点的内容、从该块中拿到缓冲页的地址,然后加载数据页到缓冲页中、最后写入数据页缓存哈希表中
- 先从 free 链表 中拿一个详细信息块,将相关的描述信息写入、修改与之相关的其他节点的指针(
如何判断哪些缓冲页是脏数据?
- 一些数据页有可能仅仅是因为查询被加载进 Buffer Pool 中
- 那么 Buffer Pool 中对应的缓冲页中的数据不应该会被刷回磁盘
- 和 free 链表一样,也会通过详细信息块使用
flush_pre+flush_next弄一个 flush 链表- 同样有一块额外节点,记录 flush 链表的头节点、尾节点、节点个数
- 当有脏数据产生,即对缓冲页的内容进行了修改,那么会修改对应的详细信息块的对应指针和额外节点的内容
- 所以初始 flush 链表是空的
描述数据块变化伪代码
- 假设一开始有 100个 详细描述信息块
- 他们编号从 block00~block99
初始值 ```java // 详细描述信息块0 DescriptionDataBlock { id = block00; // 初始化为空闲节点,所以是属于 free 链表的一部分 free_pre=null; free_pre=block01;
// 对应缓冲页并不是脏数据 flush_pre=null; flush_next=null;
}
// 详细描述信息块1 DescriptionDataBlock { id = block01;
free_pre=block00;free_pre=block02;flush_pre=null;flush_next=null;
}
// free 链表基础节点 FreeLinkListBaseNode { start=block00; end=block99; // 初始化为满的 count=100; }
// flush 链表基础节点 FlushLinkListBaseNode { start=null; end=null; // 初始是空的 count=0; }
2. 假设要读取一个数据页,此处拿 free 链表的第一个详细信息块对应的缓冲页进行加载1. 会修改该信息块和相关的信息块的 `free_pre` + `free_next`1. 会修改 free 链表的基础节点```java// 详细描述信息块0DescriptionDataBlock {id = block00;// 不是空闲的信息块了,所以不在 free 链表中了// 两个指针都是 nullfree_pre=null;free_pre=null;// 对应缓冲页并不是脏数据flush_pre=null;flush_next=null;}// 详细描述信息块1DescriptionDataBlock {id = block01;// 之前的信息块不在 free 链表中了// 修改 free_pre 为 nullfree_pre=null;free_pre=block02;flush_pre=null;flush_next=null;}// free 链表基础节点FreeLinkListBaseNode {// 修改free 链表头节点start=block01;end=block99;// 减少一个信息块count=99;}
步骤2中缓冲页的数据进行了更新,变成脏数据
- 会修改该信息块和相关的信息块的
flush_pre+flush_next 会修改 flush 链表的基础节点 ```java // 详细描述信息块0 DescriptionDataBlock { id = block00;
free_pre=null; free_pre=null;
// 对应缓冲页内容为脏数据,会加入 flush 链表 // 但是 flush 链表就它一个,所以指针还是都为 null flush_pre=null; flush_next=null; }
- 会修改该信息块和相关的信息块的
// flush 链表基础节点 FlushLinkListBaseNode { // 脏数据的缓冲页的详细信息块加入 flush 链表 // 就一个,所以头节点和尾节点都是指向同一个信息块 start=block00; end=block00; // 个数+1 count=1; }
<a name="V5KQm"></a>## 如果缓存页用完了,咋办- 如果缓冲块用完了,那么会采取 LRU 算法进行淘汰<a name="kCXvU"></a>### 预想的 LRU 链表- 同理基于详细信息块实现了个 LRU 链表- 同样也是有一个额外节点存储头和尾节点,以及个数<a name="W9aG9"></a>#### 流程1. 初始为空,即只有一个额外节点1. 当加载一个数据页到缓存页时,就会在 LRU 链表的**头部**添加该缓存页面的详细信息块- 其实也是变详细信息块的指针和额外节点的内容- 当对缓存块进行查询或者更新时,也要将对应的详细信息块存入 LRU 链表的**头部**3. 当 free 链表为空的时候,会将 LRU 链表的**最后一个节点**的缓存块刷回磁盘<a name="6OkwD"></a>### 一些预加载导致 LRU 链表没那么好实现- 预读会导致指定数据页附近的其他数据页被加载进 Buffer Pool- 从而占据 LRU 链表多余的空间!- 出现预加载的情况1. **预读**->参数设置(连续的访问和高频的访问,都是为了提高并发)- `innodb_read_ahead_threshold`, **默认56**- 如果顺序访问了一个区的数据页超过了这个阈值,就会触发预读,**加载下一个相邻区的所有数据页**- `innodb_random_read_ahead` **默认 OFF**- 如果 Buffer Pool 缓存了一个区的 **13** 个连续的数据页,并且是被频繁访问的,就会触发预读- **加载该区其他的数据页**2. **全表扫描**- 会加载对应表的**所有**数据页- **一般是第一个情况导致预读****<a name="rD51t"></a>### 实际的 LRU 链表- 实际的 LRU 链表是** 冷热数据分离** 的- 在同个 LRU 链表中,拆分为热数据和冷数据- 靠近头节点的是热数据部分,靠近尾节点的是冷数据部分- 所以**额外节点会分别存储冷热数据的头尾指针**- 数据比例是根据 `innodb_old_blocks_pct` 参数控制,默认**37**,即**冷数据占比37%**- 当数据页**第一次**被加载时,会放入**冷数据部分头部**,在 `innodb_old_blocks_time`(默认1000,即1s) 后,如果对应的**缓冲页被再次**访问,就会将其挪到**热数据部分头部**- 所以冷数据部分基本是加载偶尔访问的+预读导致的+全表扫描导致的数据<a name="UebZT"></a>#### 如何移动- 冷数据部分- 在上次访问的 1s **内**再次访问,只会将其放在冷数据部分的头部- 热数据部分- **被优化过**- 只有在热数据部分后面的 3/4 部分的缓存页被访问,才会移动到热数据部分的头部<a name="bgl6t"></a>#### 淘汰策略- **淘汰意味着刷回磁盘**- **但不是立即**1. 后台线程**定时扫描**,将 LRU 链表冷数据后面的几个节点刷回磁盘1. 被刷的节点会加入 free 链表,移出 flush 链表,移出 LRU 链表2. 后台线程**闲时扫描**,将 flush 链表**全部**刷回磁盘1. 被刷的节点会加入 free 链表,移出 flush 链表,移出 LRU 链表3. LRU 链表的冷热数据部分满了- 冷数据部分: 如果加载一个未访问过的数据页/预读导致/全表扫描导致,会淘汰冷数据的尾节点- 热数据部分: 如果一个冷数据节点晋升为热数据,并且热数据部分满了,那么会淘汰热数据部分的尾节点<a name="bt38n"></a>## 优化 Buffer Pool- 多线程访问 Buffer Pool 时需要加锁,即使 Buffer Pool 是基于内存,但是如果出现了加载数据页和被迫刷回缓冲页,是会出现磁盘IO的,导致性能不足- **在分配 Buffer Pool 数据大于 1G 时,可以将 Buffer Pool 分为几个部分**- 即 Buffer Pool 小于 1G,是只有一个实例的```json[server]innodb_buffer_pool_size=8589934592innodb_buffer_pool_instance=4
- 上述是为 Buffer Pool 设置 8G,分为 4 个实例,每个实例 2G
- 每个 instance 分担一部分详细信息块、缓存页、拥有独立 的 free、flush、LRU 链表
- 就可以并行四个线程进行磁盘IO操作了
基于 Chunk 动态调整 Buffer Pool 大小
- 通过
innodb_buffer_pool_chunk_size参数控制,默认 128MB - 其实 Buffer Pool 的每个 instance 是由若干个 Chunk 组成
- 一个实例的 Chunk 组共享 free、flush、 lru 链表
- 通过 chunk 机制可以 运行期 动态调整 Buffer Pool 大小
crud 出现两次磁盘 io 的情况
- 出现磁盘 io 的情况
- 加载数据页到缓存页
- 缓存页数据刷回磁盘
- 正常情况下,crud 会导致数据页加载到缓存页一次磁盘io操作
- 不能要求后台线程频繁清理 LRU 链表,类似均摊 io 操作了
- 可以增加 Buffer Pool 的大小、实例数,让缓存页尽可能的多
- 尽可能让 crud 访问只执行一次加载数据页到缓存页的 磁盘io 操作在高峰期中完成
- 尽可能让刷缓存页到磁盘的 磁盘io 操作在高峰期后完成
合理何设置 BufferPool
buffer_pool_size = (chunk_size * buffer_pool_instance) * 2^n- 注意后面
2^n表示 2 的倍速
- 注意后面
查看存储引擎信息
show engine innodb status;```shell Total large memory allocated 137297920 # buffer pool 最终总大小 Dictionary memory allocated 111425
Buffer pool size 8192 # buffer pool 一共能容纳多少个缓存页
Free buffers 7736 # free 链表中一共有多少个空闲的缓存页
Database pages 456 # lru 链表有多少个缓存页 Old database pages 0 # 冷数据区域的缓存页数量
Modified db pages 0 # flush 链表中的缓存页数量
Pending reads 0 # 等待从磁盘上加载进缓存页的数量 Pending writes: LRU 0, flush list 0, single page 0 # 即将从 lru 链表/flush链表中刷入磁盘的缓存页数量 Pages made young 0, not young 0 # lru 链表中冷数据区经过 1s 后访问转移到热数据区的缓存页面数量;
# lru 冷数据区里 1s 内还没有进入冷数据区的缓存页的数量
0.00 youngs/s, 0.00 non-youngs/s # 每秒从冷数据区进入热数据区的缓存页数量; 每秒在冷数据区域被访问缺没有进入热数据区的缓存页数量
Pages read 422, created 34, written 36 # 已经读取、创建和写入了多少个缓存页 0.00 reads/s, 0.00 creates/s, 0.00 writes/s # 每秒读取、创建和写入的缓存页数量
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000 # 每 1000 次访问,有多少次直接命中了 buffer pool 里的数据 Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 456, unzip_LRU len: 0 # lru 链表中缓存页的数量 I/O sum[0]:cur[0], unzip sum[0]:cur[0] # sum[最近50s处理的总数] cur[正在处理的数量] ```
- 关注
- buffer pool 使用情况
- free、lru 和 flush 数量
- lru 冷热数据转移情况
- 缓存读写情况
- buffer pool 的千次访问缓存命中率,越高性能越好
- 磁盘 io,越高越差
- buffer pool 使用情况

若有收获,就点个赞吧
0 人点赞
