- 为了避免每次加载表记录是一条一条的加载,将多条表记录作为一个数据页进行加载
- 感觉也是因为 时间局限性 和 空间局限性
- 时间局限性: 有良好时间局限性的程序,被引用过的存储器位置可能会在接下来的时间中多次被引用
- 空间局限性: 有良好空间局限性的程序,一个存储器被引用过一次,那么接下来的时间中临近的存储器将被引用
- 感觉也是因为 时间局限性 和 空间局限性
表空间
- 加载数据页是从表空间中加载的
- 逻辑上的表对应一个物理层面上的表空间
- 磁盘上以
xxx.ibd文件存储
- 磁盘上以
一个表空间有很多组
extent(表空间)每个表空间第一组 extent 的第一个 extent 的前三个数据页是固定的
- FSP_HDR: 存放表空间和这一组 extent 的一些属性
- IBUF_BITMAP: 存放这一组数据页和所有 insert buffer 的一些信息
- INODE: 存放一些特殊的信息
- 每个表除了第一组 extent 外的每一组 extent 的第一个 extent 的前两个数据页也是存放特殊信息的
- XDES: 存放该组 extent 的相关属性
数据页的组成
- 空的数据页如果被加载进缓存页时
- 数据行为空,空闲空间最大
- 当进行更新时,缓存页的数据行会增加
- 直到空闲空间耗尽
单行的物理数据存储格式
数据页物理数据的行格式存储
数据页的每一行数据,是根据 行格式 进行存储,比如 COMPACT 格式
create table table_name (xxx) ROW_FORMAT=COMPACT;alter table table_name ROW_FORMAT=COMPACT;
会变成类似下面的格式
变长字段的长度列表, null 值列表, 数据头,colmn01的值 [, column0x的值]
多行数据的字段会存放在一起
变长字段的长度列表
引入变长字段的长度列表,里面存储的是变长字段的16进制长度
- 字段正序存放,变长字段长度列表倒序存储
[0x02, 0x03] abc ab
- 字段正序存放,变长字段长度列表倒序存储
读取的时候会从数据头拿到已知表的结构,然后根据表的结构进行读取,当读到变长字段时,再根据变长字段的长度列表知道接下来的变长字段有多长
null 值列表
- 存储设置了可null字段的值,每一个可null字段由 bit 来存储
- 要求 8bit 一个单位,不够前面补0
- 当对应的字段为 null 时,对应的 bit 为 1
- 同样也是倒序存储
- 注意,变长字段为null时,对应 bit 为 1,并且变长字段的长度列表不会存储
数据头
- 40bit
- 2 bit 预留位
- 1 bit
delete_mask标识该行数据是否被删除 - 1bit
min_rec_mask标记 B+树里每一层的非叶子节点里面的最小值 - 4bit
n_owned记录数 - 13bit
heap_no当前改行数据在记录堆里的位置 - 3bit
record_type该行数据的类型- 0 普通、
- 1 B+树非叶子节点
- 2 最小值数据
- 3 最大值数据
- 16bit
next_record下一条数据的指针实际数据存储格式
- 字符串会按照字符集编码将字符进行编码
- 每行的实际数据前,有一些额外字段
DB_ROW_ID行的唯一标识,是数据库内部搞的标识,不是主键id- 如果没有提供主键,会
额外加一个ROW_ID作为主键
- 如果没有提供主键,会
DB_TRX_ID事务id,标识是哪个事务更新DB_ROLL_PTR回滚指针,用于事务回滚
行溢出
- 当某一行数据太长,超过数据页的长度 (默认16kb),会在真实数据后补个 20字节 的指针,指向下一个数据页
- 即同一行数据可以包含多个数据页
随机读写和顺序读写
加载数据页/刷回数据页的时候,是通过随机读写的方式进行的
// 类似这样dataFile.setStartPosition(102414515);dataFile.setEndPosition(102415454);dataFile.readOrWrite()
- 指标
- IOPS: 每秒随机读写量
- 响应延迟: 随机读写后的耗时
- 写 redo log 的时候,是顺序读写的
- 速度跟内存一样
- 指标
- 顺序读写吞吐量
- 顺序读写响应延迟
流程
linux 存储系统
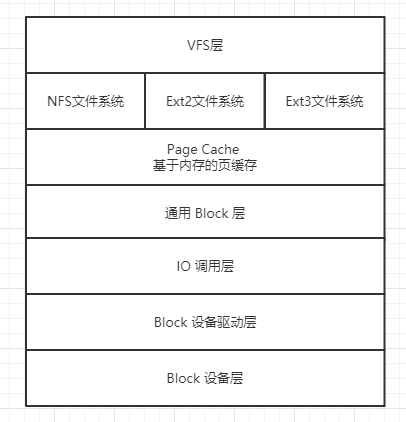
应用发起一次读写请求时,会通过 vfs 会通过讲需要对哪个目录的哪个文件进行的磁盘 IO 操作 ,调用合适的文件系统来处理
- 文件系统首先会从 Page Cache(一般 os cache 就是了) 来查找是否有对应的数据
- 如果没有,将 IO 操作发给 通用 Block 层,该层会将 IO 操作转化为 Block IO 操作
- Block IO 操作会发给 IO 调用层,该层默认用 CFQ 公平调度算法来进行 IO 操作的调度
- 建议设置成 deadline 算法,避免能快速完成的 IO 操作饥饿等待
- IO 调度完成之后,会发给 Block 设备驱动层,由它将 Block IO 操作发给真正的存储硬件
- 存储硬件一般采用 RAID (磁盘冗余阵列) 进行部署,避免磁盘故障造成数据丢失
- 操作完成后,响应结果原路返回到应用

若有收获,就点个赞吧
0 人点赞
