MLflow模型注册组件是一个集中的模型存储、一组api和UI,用于协作管理MLflow模型的整个生命周期。它提供了模型沿沿性(MLflow实验和运行生成模型)、模型版本控制、阶段转换(例如从阶段到生产)和注释。
概念
模型注册表引入了一些概念,用于描述和促进MLflow模型的整个生命周期。
Model
MLflow模型是从使用模型flavor的MLflow .
Registered Model
MLflow模型可以注册到模型注册中心。一个注册的模型有一个唯一的名称,包含版本、关联的过渡阶段、模型沿沿性和其他元数据。
Model Version
每个注册的模型可以有一个或多个版本。当一个新模型被添加到模型注册表中时,它将作为版本1被添加。每个注册到相同模型名称的新模型都会增加版本号。
Model Stage
每个不同的模型版本可以在任何给定的时间分配一个阶段。MLflow为常用的用例(如登台、生产或存档)提供了预定义的阶段。您可以将模型版本从一个阶段过渡到另一个阶段。
Annotations and Descriptions
您可以使用Markdown单独注释顶层模型和每个版本,包括描述和任何对团队有用的相关信息,如算法描述、使用的数据集或方法。
模型注册工作流程
如果运行您自己的MLflow服务器,则必须使用数据库支持的后端存储,以便通过UI或API访问模型注册表。更多信息请参阅这里。
在将模型添加到模型注册表之前,您必须使用对应模型风格的log_model方法来记录它。一旦模型被记录下来,您就可以通过UI或API在模型注册表中添加、修改、更新、转换或删除模型。
UI工作流
- 从MLflow运行详细信息页中,在Artifacts部分中选择一个已记录的MLflow模型。
- 点击注册模型按钮。

- 在模型名称字段中,如果您要添加一个新的模型,请指定一个惟一的名称来标识模型。如果您要向现有模型注册一个新版本,请从下拉列表中选择现有的模型名称。
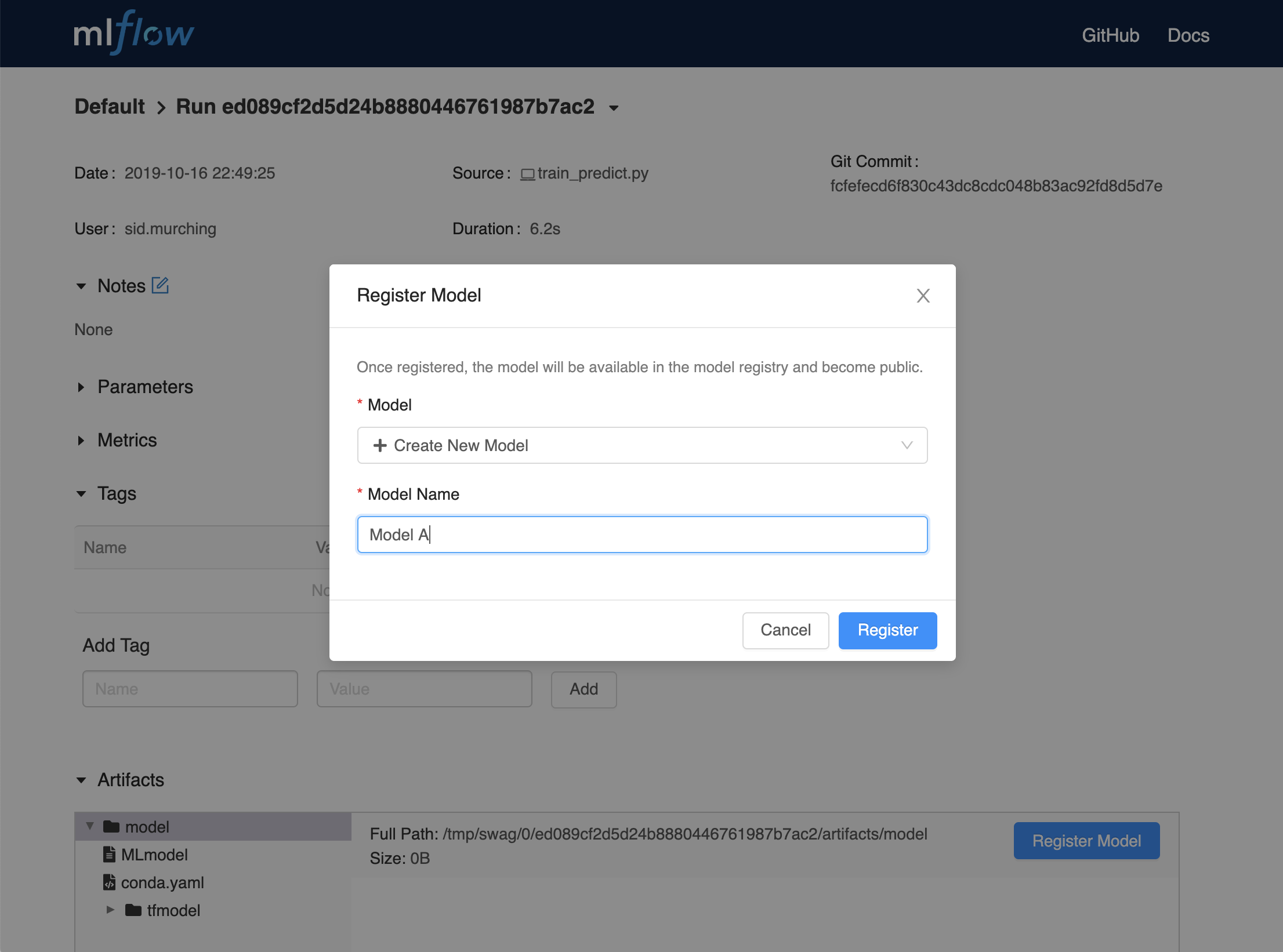
使用模型注册
- 导航到Registered Models页面并查看模型属性。
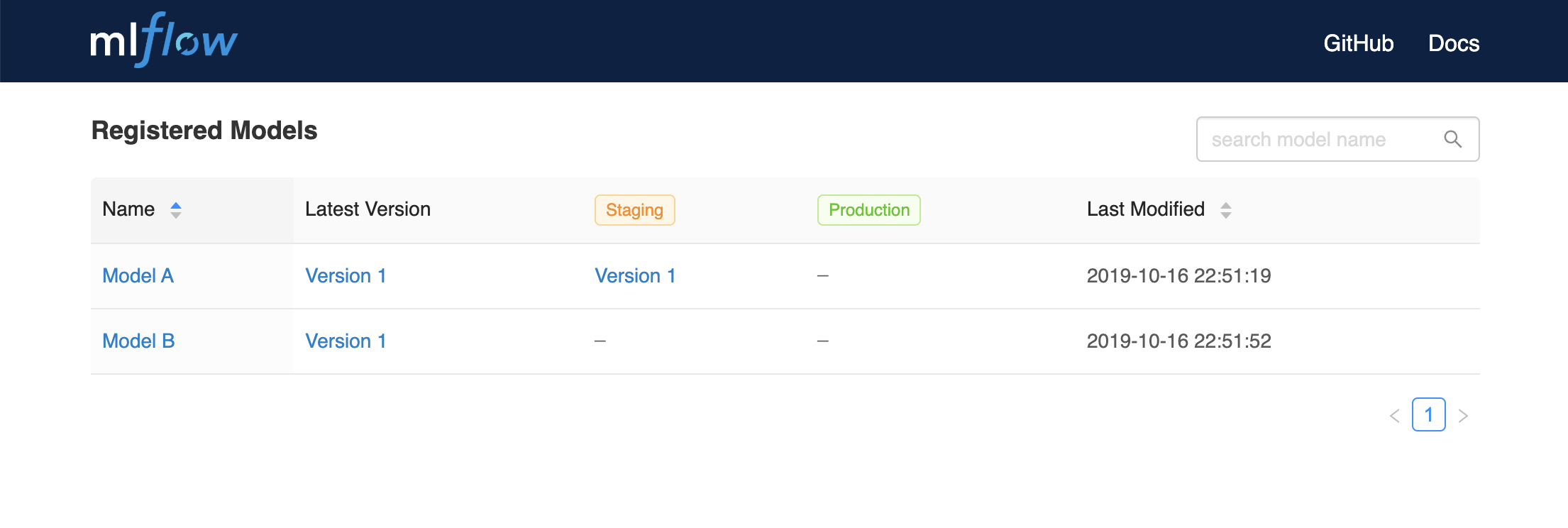
- 转到run detail页面的Artifacts部分,单击模型,然后单击右上方的模型版本,以查看您刚刚创建的版本。

每个模型都有一个显示活动版本的概览页面。
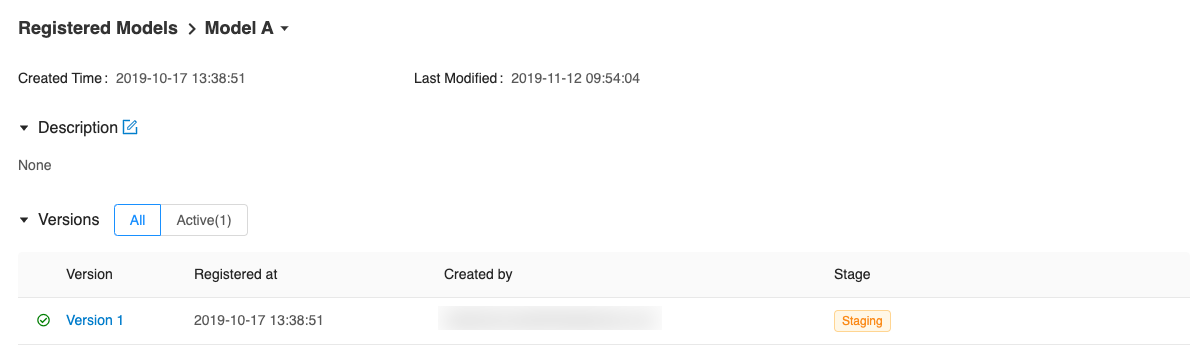
单击具体版本,进入版本详情界面。
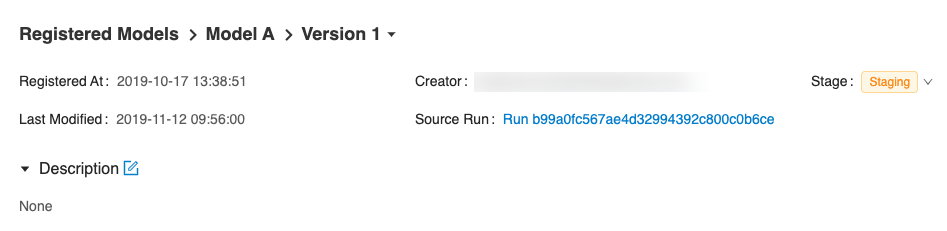
在版本详情页面,您可以看到模型版本详情和模型版本的当前阶段。单击右上角的Stage下拉菜单,将模型版本转换为其他有效阶段之一。

API的工作流程
另一种与模型注册器交互的方法是使用MLflow模型样式或MLflow客户端跟踪API接口。特别地,您可以在MLflow实验运行期间或在所有实验运行之后注册模型。
向模型注册表添加MLflow模型
有三种编程方法可以将模型添加到注册中心。首先,您可以使用mlflow.
from random import random, randintfrom sklearn.ensemble import RandomForestRegressorimport mlflowimport mlflow.sklearnwith mlflow.start_run(run_name="YOUR_RUN_NAME") as run:params = {"n_estimators": 5, "random_state": 42}sk_learn_rfr = RandomForestRegressor(**params)# Log parameters and metrics using the MLflow APIsmlflow.log_params(params)mlflow.log_param("param_1", randint(0, 100))mlflow.log_metrics({"metric_1": random(), "metric_2": random() + 1})# Log the sklearn model and register as version 1mlflow.sklearn.log_model(sk_model=sk_learn_rfr,artifact_path="sklearn-model",registered_model_name="sk-learn-random-forest-reg-model")
如果注册的名称为ModelVersion的模型不存在,则该方法注册一个新模型,创建版本1,并返回ModelVersion MLflow对象。如果注册的模型名称已经存在,该方法将创建一个新的模型版本并返回version对象。
第二种方法是使用mlflow.register_model()方法,在您的所有实验运行完成并决定了哪个模型最适合添加到注册表之后。对于这个方法,您将需要run_id作为runs:URI参数的一部分。
result = mlflow.register_model("runs:/d16076a3ec534311817565e6527539c0/artifacts/sklearn-model","sk-learn-random-forest-reg")
如果注册的名称为ModelVersion的模型不存在,则该方法注册一个新模型,创建版本1,并返回ModelVersion MLflow对象。如果注册的模型名称已经存在,该方法将创建一个新的模型版本并返回version对象。
最后,您可以使用create_registered_model()来创建一个新的注册模型。如果模型名称存在,则此方法将抛出MlflowException,因为创建新注册的模型需要唯一的名称。
from mlflow.tracking import MlflowClientclient = MlflowClient()client.create_registered_model("sk-learn-random-forest-reg-model")
虽然上面的方法创建了一个没有关联版本的空注册模型,但下面的方法创建了模型的新版本。
client = MlflowClient()result = client.create_model_version(name="sk-learn-random-forest-reg-model",source="mlruns/0/d16076a3ec534311817565e6527539c0/artifacts/sklearn-model",run_id="d16076a3ec534311817565e6527539c0")
从模型注册中心获取MLflow模型
注册了MLflow模型后,可以使用MLflow .
获取特定的模型版本
要获取特定的模型版本,只需将该版本号作为模型URI的一部分提供。
import mlflow.pyfuncmodel_name = "sk-learn-random-forest-reg-model"model_version = 1model = mlflow.pyfunc.load_model(model_uri=f"models:/{model_name}/{model_version}")model.predict(data)
在特定阶段获取最新的模型版本
要按阶段获取模型版本,只需将模型阶段作为模型URI的一部分提供,它将在该阶段获取模型的最新版本。
model_name = "sk-learn-random-forest-reg-model"stage = 'Staging'model = mlflow.pyfunc.load_model(model_uri=f"models:/{model_name}/{stage}")model.predict(data)
从模型注册中心提供MLflow模型
注册了MLflow模型之后,就可以将模型作为主机上的服务来使用了。
#!/usr/bin/env sh# Set environment variable for the tracking URL where the Model Registry residesexport MLFLOW_TRACKING_URI=http://localhost:5000# Serve the production model from the model registrymlflow models serve -m "models:/sk-learn-random-forest-reg-model/Production"
添加或更新MLflow模型描述
在模型生命周期开发的任何时刻,您都可以使用update_model_version()更新模型版本的描述。
client = MlflowClient()client.update_model_version(name="sk-learn-random-forest-reg-model",version=1,description="This model version is a scikit-learn random forest containing 100 decision trees")
重命名MLflow模型
除了添加或更新模型的特定版本的描述外,您还可以使用rename_registered_model()重命名已存在的注册模型。
client = MlflowClient()client.rename_registered_model(name="sk-learn-random-forest-reg-model",new_name="sk-learn-random-forest-reg-model-100")
转换MLflow模型的不同阶段
在模型的生命周期中,模型不断演化——从开发到登台再到生产。您可以将已注册的模型转换到阶段之一:分段、生产或存档。
client = MlflowClient()client.transition_model_version_stage(name="sk-learn-random-forest-reg-model",version=3,stage="Production")
列出和搜索MLflow模型
您可以使用一个简单的方法获取注册中心中所有已注册模型的列表。
from pprint import pprintclient = MlflowClient()for rm in client.list_registered_models():pprint(dict(rm), indent=4)
输出为:
{ 'creation_timestamp': 1582671933216,'description': None,'last_updated_timestamp': 1582671960712,'latest_versions': [<ModelVersion: creation_timestamp=1582671933246, current_stage='Production', description='A random forest model containing 100 decision trees trained in scikit-learn', last_updated_timestamp=1582671960712, name='sk-learn-random-forest-reg-model', run_id='ae2cc01346de45f79a44a320aab1797b', source='./mlruns/0/ae2cc01346de45f79a44a320aab1797b/artifacts/sklearn-model', status='READY', status_message=None, user_id=None, version=1>,<ModelVersion: creation_timestamp=1582671960628, current_stage='None', description=None, last_updated_timestamp=1582671960628, name='sk-learn-random-forest-reg-model', run_id='d994f18d09c64c148e62a785052e6723', source='./mlruns/0/d994f18d09c64c148e62a785052e6723/artifacts/sklearn-model', status='READY', status_message=None, user_id=None, version=2>],'name': 'sk-learn-random-forest-reg-model'}
由于有数百个模型,仔细查看从这个调用返回的结果可能会很麻烦。更有效的方法是搜索特定的模型名称,并使用search_model_versions()方法列出其版本细节,并提供一个过滤器字符串,如“name=’sk-learn-random-forest-reg-model’”。
client = MlflowClient()for mv in client.search_model_versions("name='sk-learn-random-forest-reg-model'"):pprint(dict(mv), indent=4)
输出为
{ 'creation_timestamp': 1582671933246,'current_stage': 'Production','description': 'A random forest model containing 100 decision trees ''trained in scikit-learn','last_updated_timestamp': 1582671960712,'name': 'sk-learn-random-forest-reg-model','run_id': 'ae2cc01346de45f79a44a320aab1797b','source': './mlruns/0/ae2cc01346de45f79a44a320aab1797b/artifacts/sklearn-model','status': 'READY','status_message': None,'user_id': None,'version': 1}{ 'creation_timestamp': 1582671960628,'current_stage': 'None','description': None,'last_updated_timestamp': 1582671960628,'name': 'sk-learn-random-forest-reg-model','run_id': 'd994f18d09c64c148e62a785052e6723','source': './mlruns/0/d994f18d09c64c148e62a785052e6723/artifacts/sklearn-model','status': 'READY','status_message': None,'user_id': None,'version': 2 }
归档MLflow模型
您可以将模型版本从生产阶段移到存档阶段。稍后,如果不需要该存档模型,您可以删除它。
# Archive models version 3 from Production into Archivedclient = MlflowClient()client.transition_model_version_stage(name="sk-learn-random-forest-reg-model",version=3,stage="Archived")
删除MLflow模型
删除已注册的模型或模型版本是不可撤销的,所以请谨慎使用。
您可以删除一个已注册模型的特定版本,也可以删除一个已注册模型及其所有版本。
# Delete versions 1,2, and 3 of the modelclient = MlflowClient()versions=[1, 2, 3]for version in versions:client.delete_model_version(name="sk-learn-random-forest-reg-model", version=version)# Delete a registered model along with all its versionsclient.delete_registered_model(name="sk-learn-random-forest-reg-model")

若有收获,就点个赞吧
0 人点赞
