2021-10-28
7-1 开始
日志
- 系统没有日志等于人没有眼睛 - 抓瞎
- 比如看使用的情况,通过日志才能看到问题,看qps
- 第一,访问日志 access log (server 端最重要的日志)
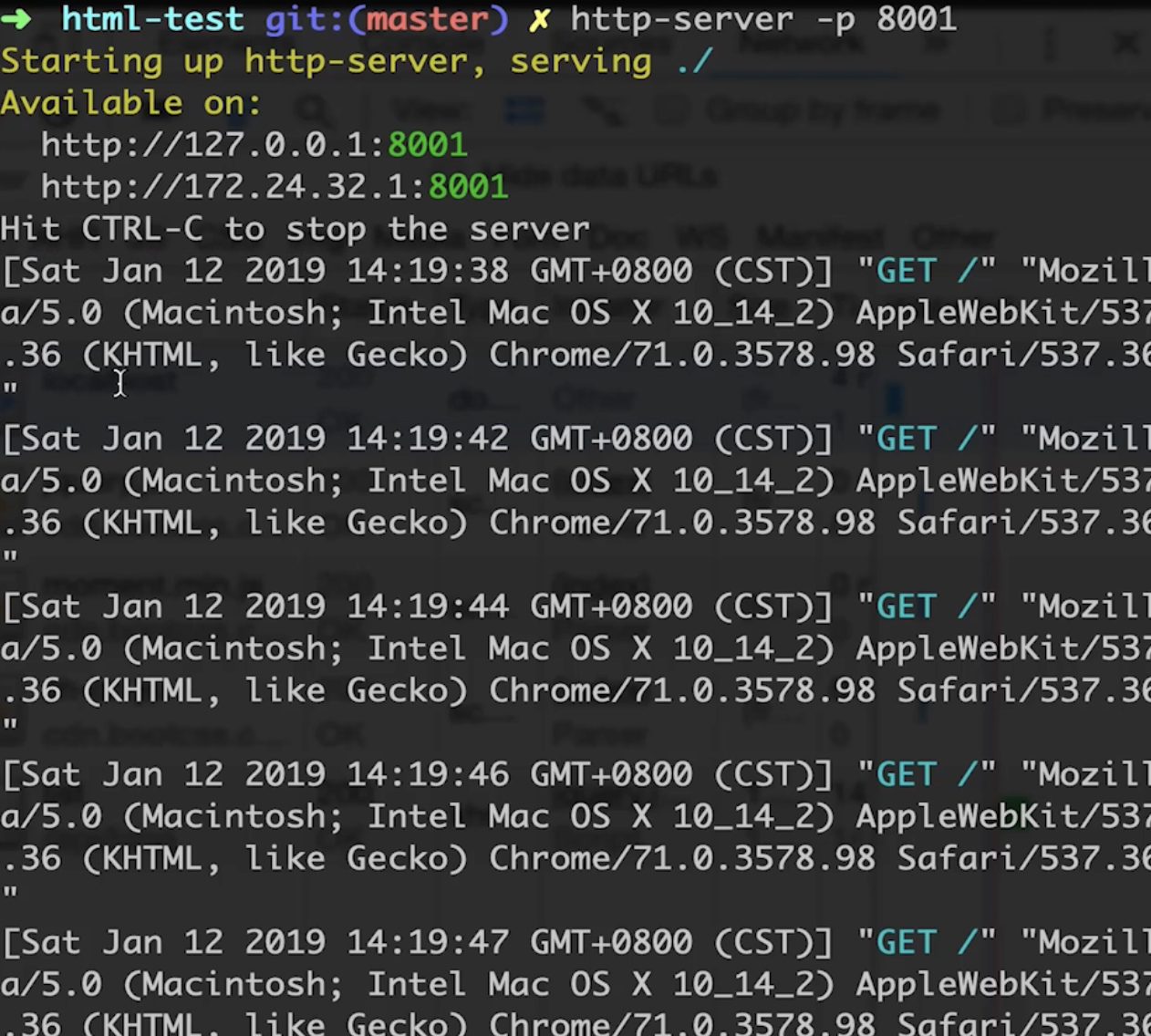
- 类似于通过 http-server 访问的时候出现的那些内容
- 这里就可以看出每次请求它的请求方式是什么,浏览器的UA,计算机的系统等等信息,后续还能扩展,比如此次访问的时间,chrome浏览器的占比
- 第二:自定义日志(包括自定义事件,错误记录等)——业务上的日志
课程重点:
1.如何记录日志 2.记录好的日志如何拆分和分析日志
目录
- nodejs 文件操作,nodejs stream
- 因为上线之后日志要放到文件中来保存,放在控制台中不方便查看
- 为了节约 CPU 和内存,要把日志记录放到 stream 中来做
- 日志功能开发和使用
- 日志文件拆分和日志内容分析
- 按照每天一个文件或者每小时一个文件来拆分
nodejs 文件操作
- 日志要存储到文件中
- 为何不存储到 mysql 中?
- mysql 是表结构,不太方便。对性能要求不高
- 为何不存储到 redis 中?
- 文件太大,不需要那么急
7-2 nodejs 文件操作
读文件
新建文件夹 file-test,然后新建文件 test1.js
写入代码:
const fs = require('fs')const path = require('path')// 分别为文件处理和路径处理的方法// 处理路径为当前目录(__dirname) 再加 data.txtconst fileName = path.resolve(__dirname, 'data.txt')// 读取文件内容fs.readFile(fileName, (err, data) => {if (err) {console.error(err)return}// data 原生是二进制类型,toString 将其转换为对象格式console.log(data.toString());})
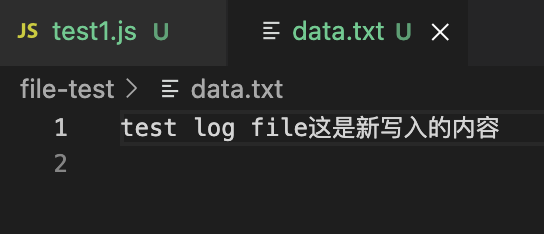
然后新建 data.txt 用来处理日志文件
随便写入一些内容,比如 test log file
然后运行一下
成功了!
但是这样是不合理的,因为如果 data 内容过大的话,运行时会消耗大量的 CPU 和内存,并且也占不了太大,因为 nodejs 占比有限
写文件
// 写入文件const content = '这是新写入的内容\n'const opt = {flag: 'a' // 追加写入,覆盖用 'w'}// writeFile 传入三个参数:文件路径,内容和方式,最后有回调函数fs.writeFile(fileName, content, opt, (err) => {if (err) {console.error(err)}console.log('success')})
试一下,成功了
写入也有问题,执行 writeFile 会很耗费性能,比如写入的内容非常的大的话,也很困难
判断文件是否存在
// 判断文件是否存在fs.exists(fileName, (exist) => {console.log('exist', exist);})
exists 已被废弃
2021-11-1
7-3 stream 介绍
IO 操作的性能瓶颈
- IO 包括 网络IO 和 文件IO
- 上节课只是介绍了文件IO的问题
- 因为在线看电影等的话,不可能下载文件的时候把文件所有内容都下载,需要网络IO来缓存下载
- 相比于 CPU 计算和内存读写,IO的突出特点就是:慢
- 本身的特点没办法避免,不可能让它和 CPU 一样快
- 如何在有限的硬件资源下提高 IO 的操作效率
Stream
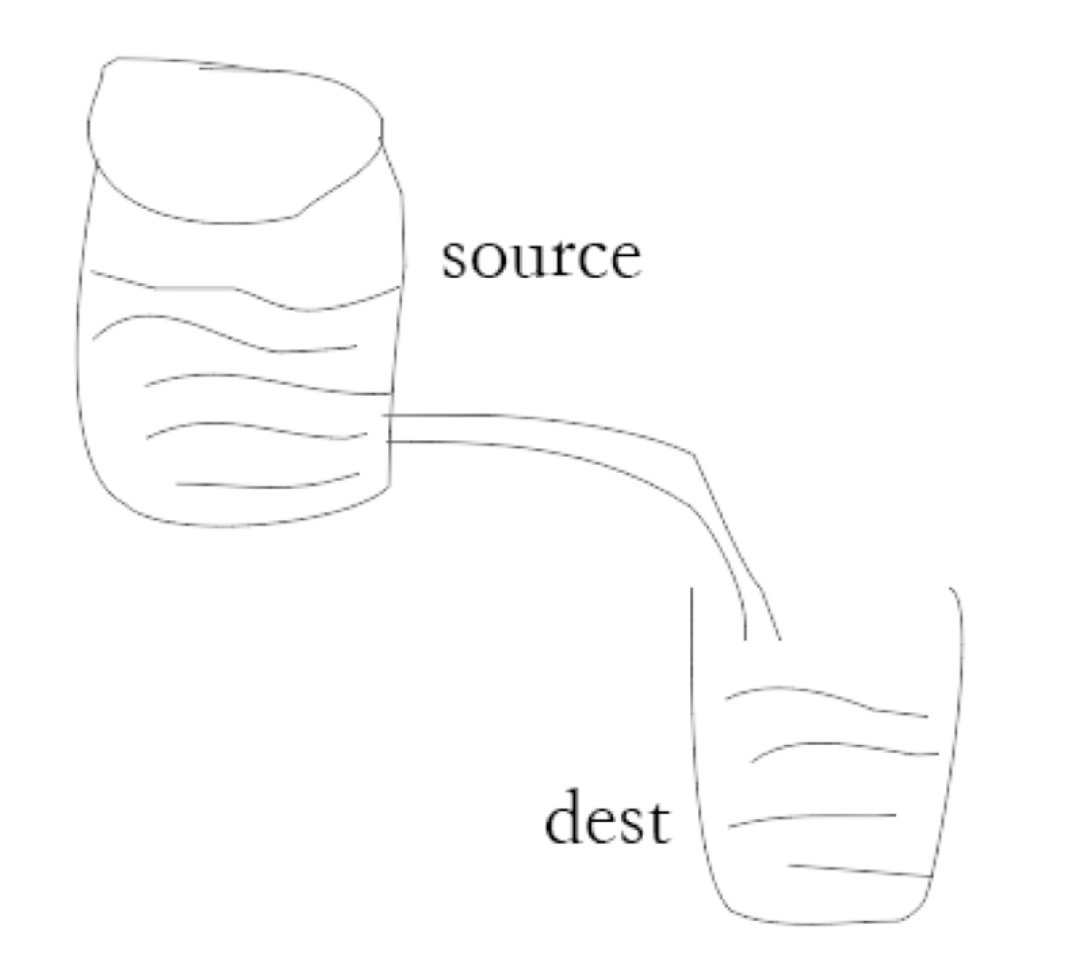
如果把读取内容比作从一个水桶倒水到另一个水桶中的话,那么之前操作的时候,就相当于将水桶的水一股脑全部倒入另一个水桶中,并且倒完才使用。
但是这样意味着性能强劲,但是事实不能这样
因此应该像鱼缸换水一样,拿一个管子慢慢换水。
这样可以节约硬件资源
代码中是这样操作
之前的网络IO 客户端向用户端传递数据的时候,就是用到了这种 stream 的方式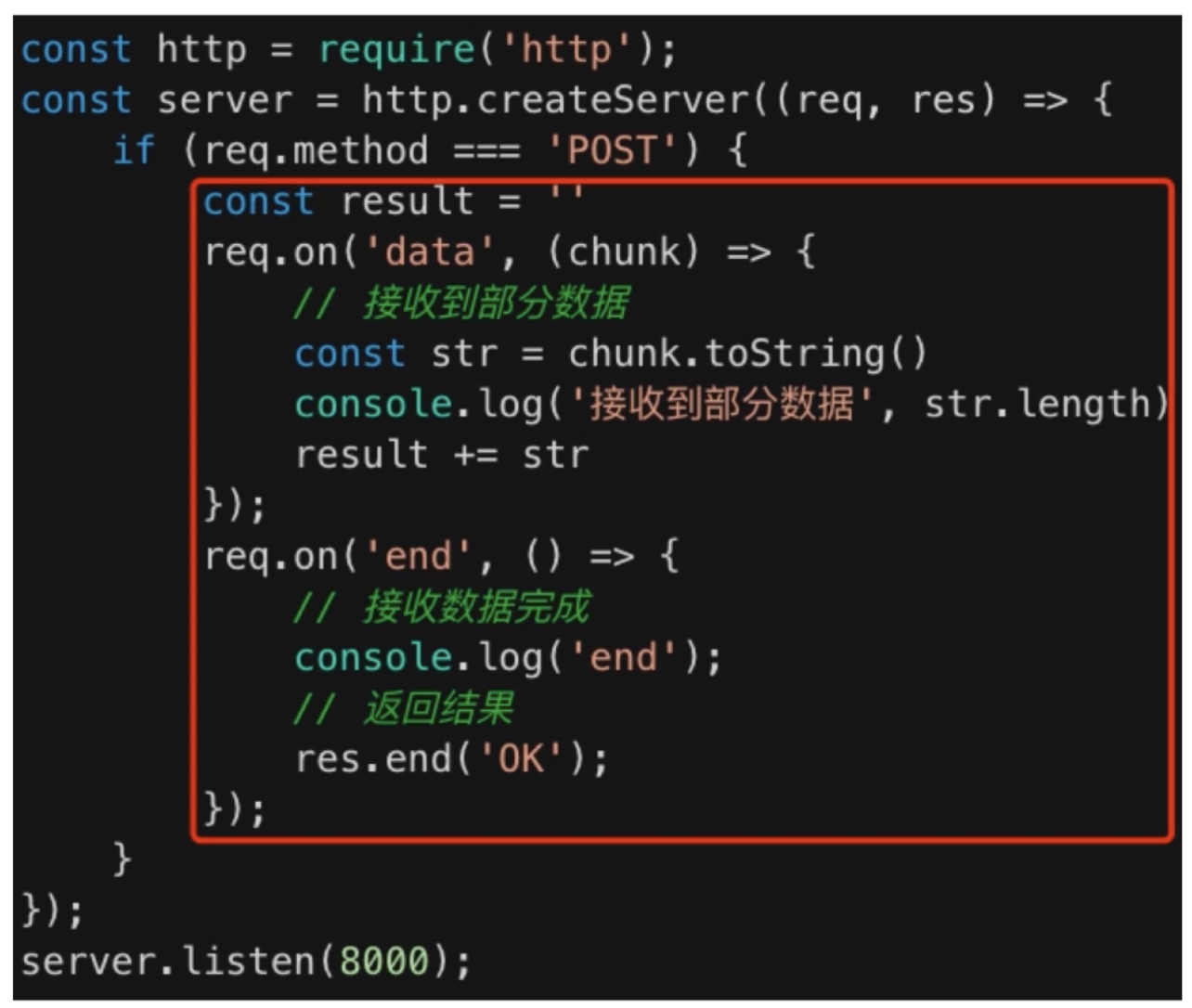
一个网络io的请求
目的:将输入的内容立马返回,使用 pipe 方法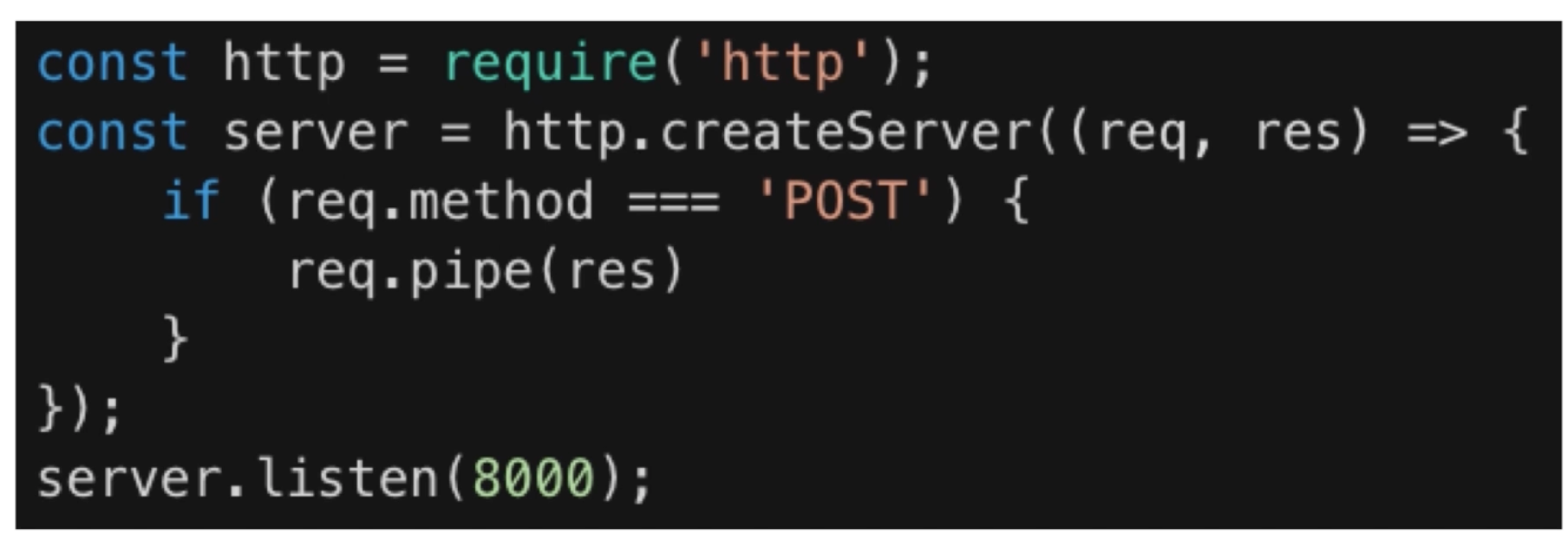
2021-11-4
7-4 stream演示(1)
新建一个文件夹来演示 stream 流: stream-test
然后新建一个 test1.js
测试标准输入,输出
// 标准输入输出process.stdin.pipe(process.stdout)
输入什么就输出什么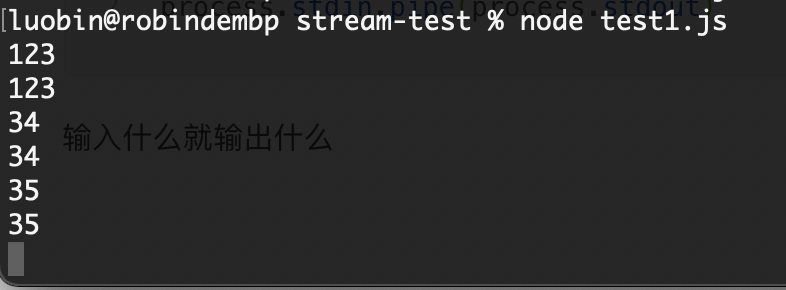
也就是说,通过标准输入去输入,一旦输入结束他就会流动到标准输出里去。
相当于两个水桶接到一起去了
测试网络 IO 请求的 stream 流
继续在 test1.js 中写:
const http = require('http')const server = http.createServer((req, res) => {if (req.method === 'POST') {req.pipe(res) // 最主要}})server.listen(8000)
node 运行完之后,打开 postman 测试一下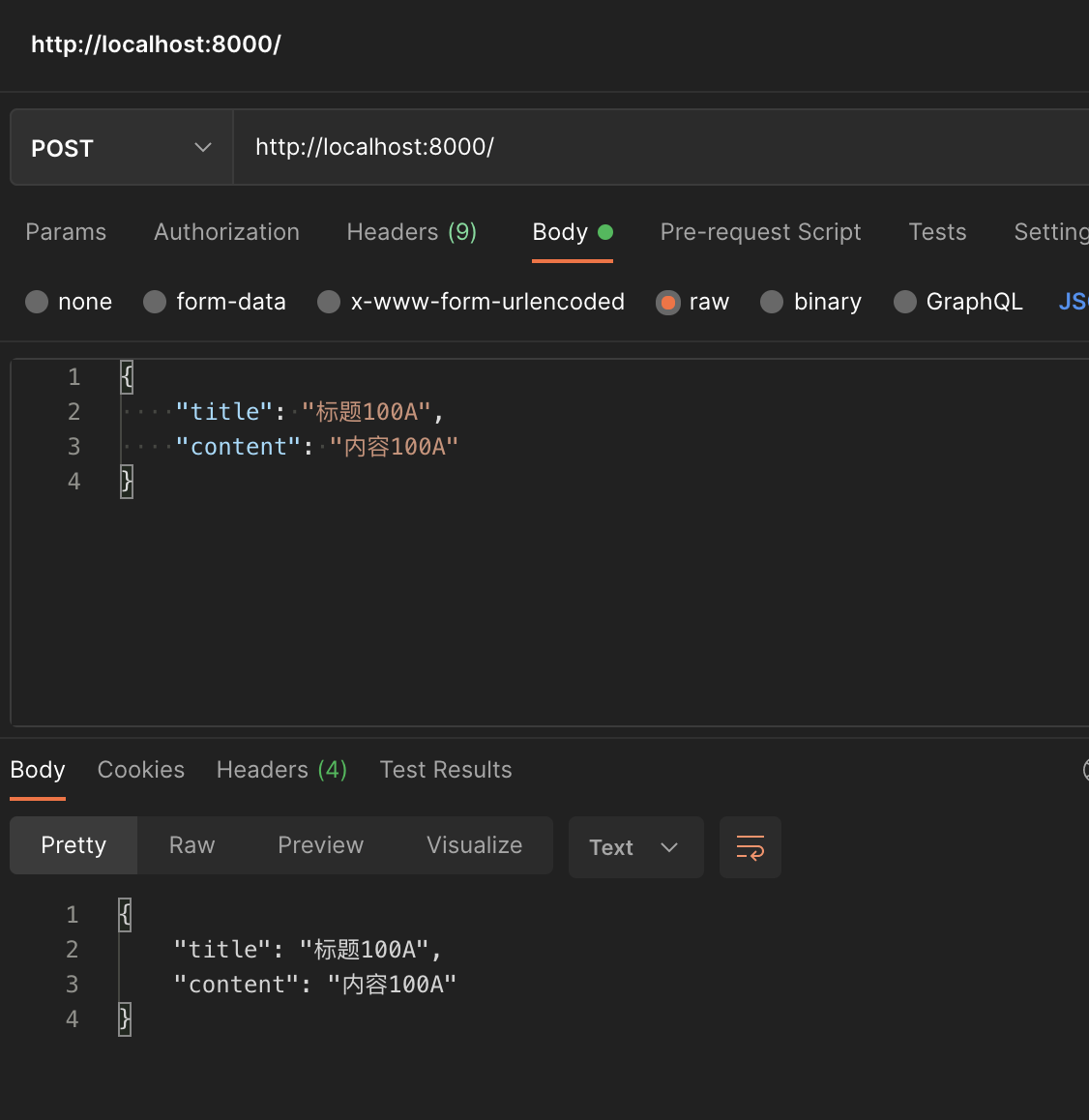
简单测试之后发现,数据就传输过来了,但是我们这里内容很少,如果数据很多,就会像水流一样传过来
就像之前学习中的那样,传递 postData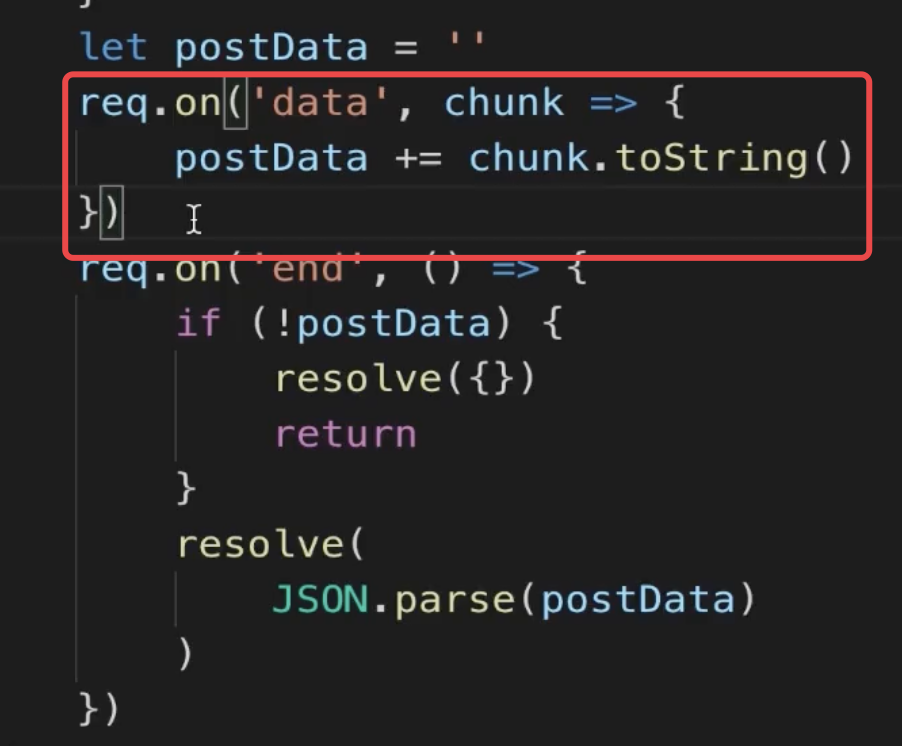
这样可以优化 CPU 内存和网络带宽
stream 操作文件
这里采用拷贝文件的例子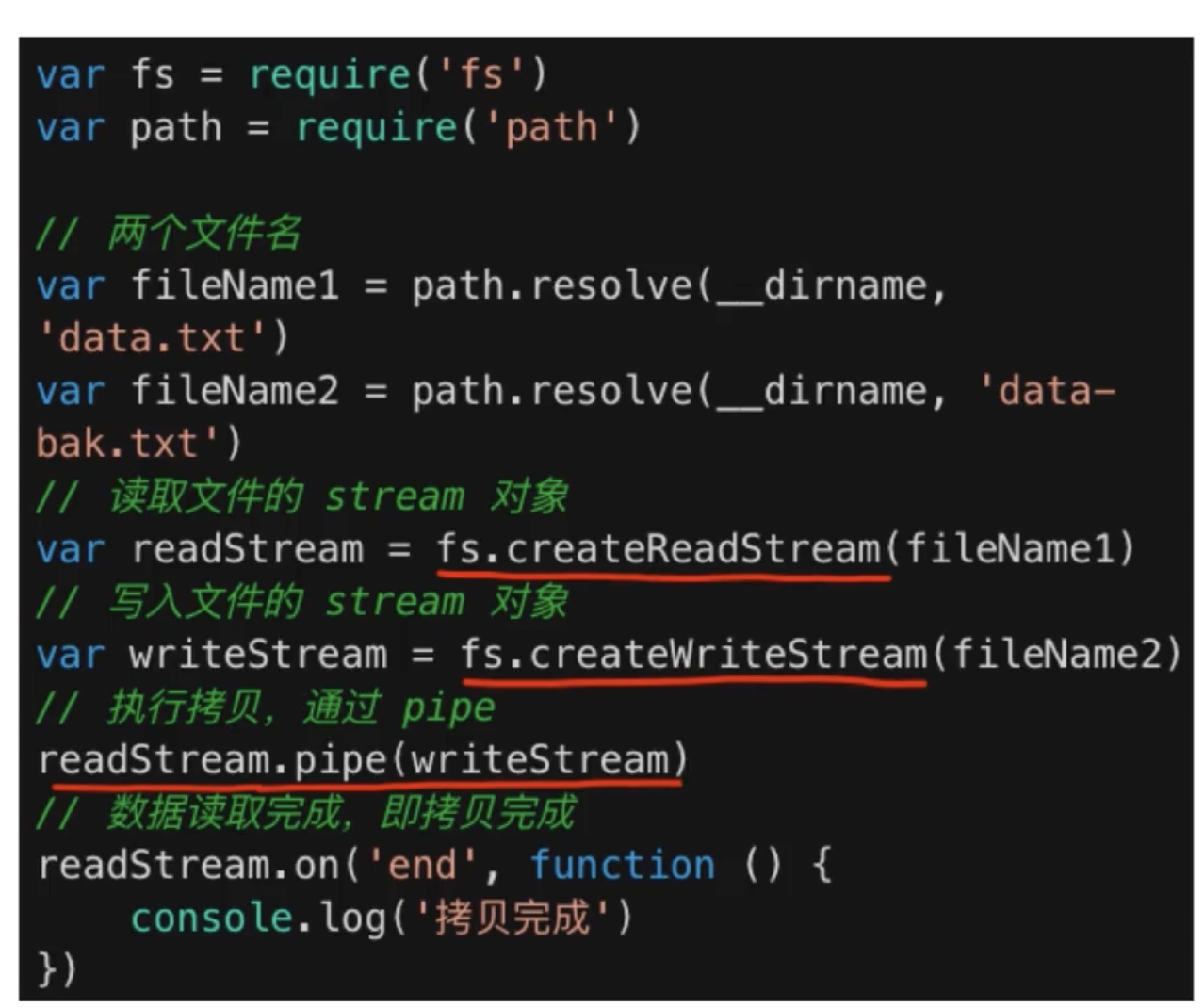
读取文件内容的例子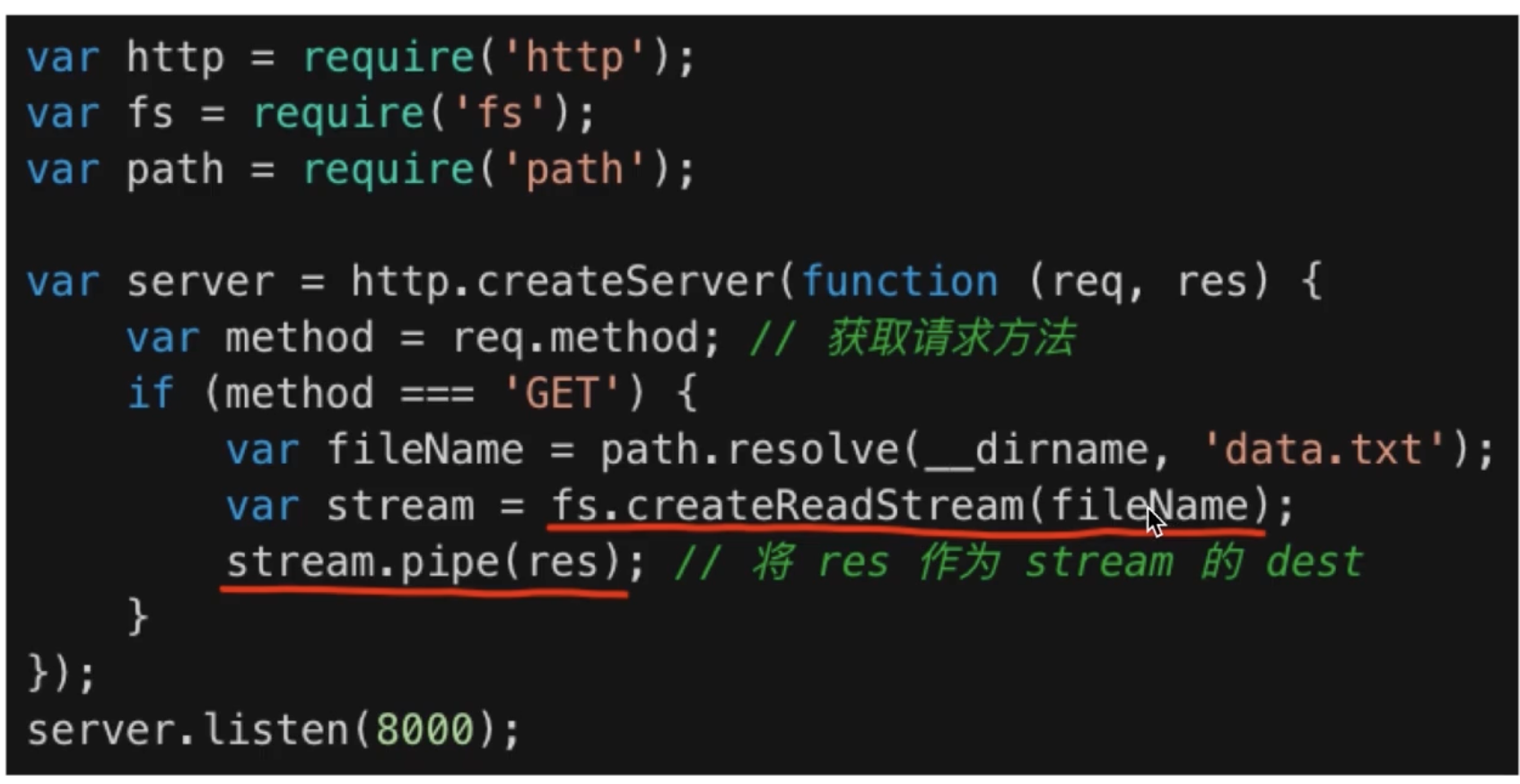
7-5 stream演示(2)
复制文件
首先新建两个文件,data.txt(用来复制的) 和 data-bak.txt(用来粘贴的) 
然后随便在data.txt 中写入一些内容
然后写代码
// 复制文件const fs = require('fs')const path = require('path')const tobeCopyedFile = path.resolve(__dirname, 'data.txt')const CopyedFile = path.resolve(__dirname, 'data-bak.txt')// 分别新建两个输入输出流const readStream = fs.createReadStream(tobeCopyedFile)const writeStream = fs.createWriteStream(CopyedFile)// 然后倒水readStream.pipe(writeStream)// 处理拷贝完成readStream.on('end', () => {console.log('copy success');})

监听每一次读取的数据
readStream 除了像上边一样监视 end 外,也可以监视 data
每次读取的内容就是 chunk
chunk.toString 后就是每次一点点的数据内容
// 监听每一次读取的数据readStream.on('data', (chunk)=> {console.log(chunk.toString());})
结合文件操作和 io 操作
// 结合文件 IO 操作 http 操作const fs = require('fs')const path = require('path')const http = require('http')const tobeCopyedFile = path.resolve(__dirname, 'data.txt')const server = http.createServer((req, res) => {if (req.method === 'GET') {const readStream = fs.createReadStream(tobeCopyedFile)readStream.pipe(res)}})server.listen(8000)
然后运行一下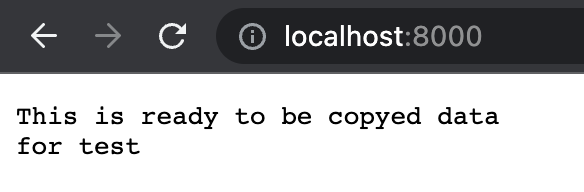
2021-11-6
7-6 写日志
回到 blog-1 的文件中
创建 logs 文件夹,目录为 blog-1/logs
在logs文件夹下创建三个文件,分别为 access.log、event.log、error.log
这三个文件分别存储运行成功的log,自定义事件的log以及错误事件的log
然后新建 utils 文件夹,创建 log.js 用来操纵写日志的 js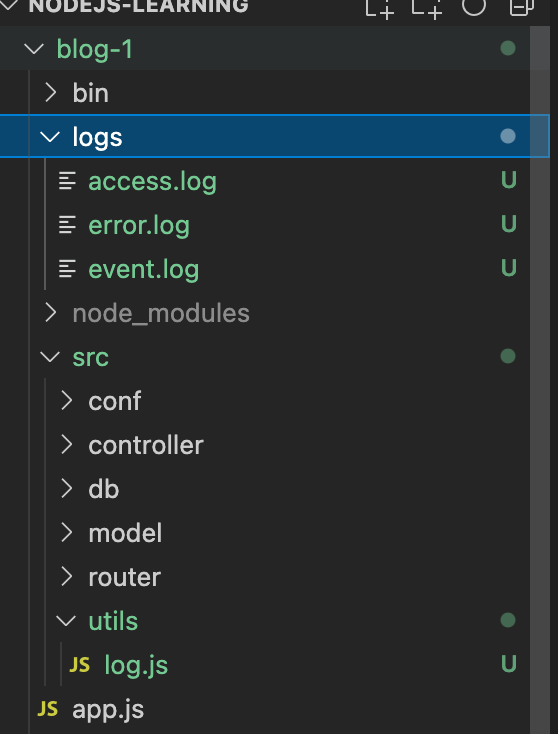
log.js
写入操作正确的和错误的代码
const fs = require('fs')const path = require('path')// 写所有的日志function writeLog(writeSteam, log) {writeSteam.write(log + '\n') // 关键代码}// 生成 write stream(第二个水桶)function createWriteStream(fileName, flags) {// 找到真正的日志文件的地址const fullFileName = path.join(__dirname, '../', '../', 'logs', fileName)const writeSteam = fs.createWriteStream(fullFileName, {// 给它添加一个标识符flags})return writeSteam}// 写访问成功的日志const accessWriteStream = createWriteStream('access.log', 'a')function access(log) {writeLog(accessWriteStream,log)}module.exports = {access}
然后去使用起来
来到 app.js 中,将 access 和 error 方法引入进来
然后在 serverHandle 方法中引入 access 并且写入一些基本的内容
const serverHandle = (req, res) => {// 记录 access logconst basicContent = `${req.method} -- ${req.url} -- ${req.headers['user-agent']} -- ${Date.now()}`access(basicContent)...}
然后刷新页面,发现写日志成功了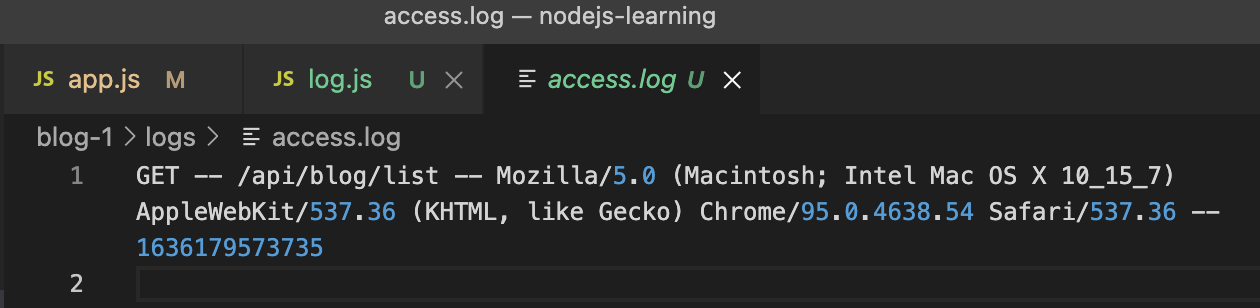
error.log 和 event.log 在后面会讲
7-7 拆分日志
- 日志内容会慢慢累积,放在一个文件中不好处理
- 按时间划分日志文件,如2021-11-6.access.log
- 实现方式:Linux 的 crontab 命令,即定时任务
- 运维去做,只需简单了解
crontab
- 设置定时任务的格式:*command
- (分别是分钟、小时、日、月、星期几)command 为运行脚本 .sh 文件
- 将 access.log 拷贝并重命名为 2021-11-06.access.log(当前日期的命名)
- 清空 access.log 文件,继续累积日志
操作
首先进入 logs 然后把它的绝对路径拷贝一下
/Users/luobin/Downloads/nodejs-learning/blog-1/logs
然后在 utils 中书写一个 copy.sh 的 shell 脚本,用来书写 crontab 内容
首先进入 logs 中去
然后重命名 access.log 为当前日期的 access.log
最后使用 echo 指令将 access.log 清空
#!/bin/shcd /Users/luobin/Downloads/nodejs-learning/blog-1/logscp access.log $(dat +%Y-%m-%d).access.logecho "" > access.log
然后运行一下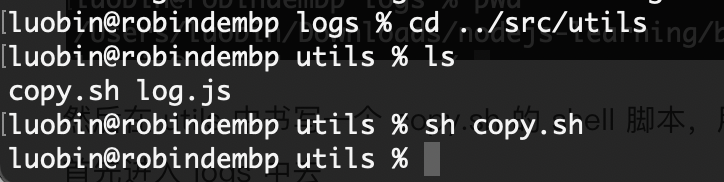
发现 access.log 清空了,并且生成了正确的按时间来的日志名字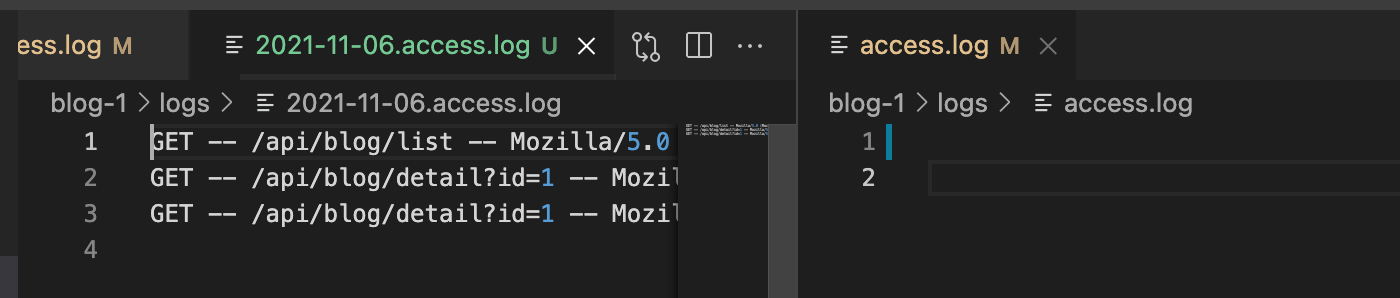
7-8 分析日志介绍
记录一下脚本的 pwd
/Users/luobin/Downloads/nodejs-learning/blog-1/src/utils
使用 crontab
在 blog-1 下 使用 crontab -e 写入下面这个脚本
使用 crontab -l 就可以看到当前本机添加了哪些脚本
日志分析
- 如针对 access.log 日志,分析 chrome 的占比
- 日志是按行存储的,一行就是一条日志
- 使用 nodejs 的 readline (基于 stream ,效率高)
7-9 readline演示
启动服务后,换几个服务器运行一下
在 utils 中新建一个 readline.js
然后写占比代码
const fs = require('fs')const path = require('path')const readline = require('readline')// 文件名const fileName = path.join(__dirname, '../', '../', 'logs', 'access.log')// 创建 readStreamconst readStream = fs.createReadStream(fileName)// 创建 readlineconst readlineObject = readline.createInterface({input: readStream})let chromeNum = 0let totalNum = 0// 逐行读取// 每一行数据读完之后会触发readlineObject.on('line', (lineData) => {if (!lineData) {return}// 记录总行数totalNum++const arr = lineData.split(' -- ')if (arr[2] && arr[2].includes('Chrome')) {// 累加 chrome 的数量chromeNum++}})// 监听读取完成readlineObject.on('close', () => {console.log('Chrome 读取占比', chromeNum / totalNum)})

成功!
7-10 总结
- 日志对于 server 端的重要性,相当于人的眼睛
- IO 性能瓶颈,使用 stream 操作
- 使用 crontab 来拆分日志,使用 readline 来分析日志内容

若有收获,就点个赞吧
0 人点赞
