- 爬虫简介
- HTTP协议
- F12调试页面简介
- URL构成
- url中#(hash)的含义
- HTML的基本结构
- 正则表达式
- 链接">XPath表达式链接
- Urllib
- 第二种方式发送付费ip
def money_proxy_use():
use_name=’abcname’
pwd=’123456’
proxy_money=’123.158.63.135:8800’
password_manager=urllib.request.HTTPPasswordMgrWithDefaultRealm()
password_manager.add_password(None,proxy_money,user_name,pwd) - Fiddler软件抓包使用
- 链接">requests模块爬虫编写链接
- https://search.51job.com/list/020000,000000,0000,00,9,99,java,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=">https://search.51job.com/list/020000,000000,0000,00,9,99,java,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=
- https://search.51job.com/list/020000,000000,0000,00,9,99,java,2,2.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=">https://search.51job.com/list/020000,000000,0000,00,9,99,java,2,2.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=
- https://search.51job.com/list/020000,000000,0000,00,9,99,java,2,3.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=">https://search.51job.com/list/020000,000000,0000,00,9,99,java,2,3.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=
- https://search.51job.com/list/020000,000000,0000,00,9,99,java,2,3.html *分析网页">https://search.51job.com/list/020000,000000,0000,00,9,99,java,2,3.html *分析网页
- 要求用requests模块
- 正则表达式
- 实现翻页
- 输出结果
爬虫简介
网络爬虫是一种互联网信息的自动化采集程序,使用代码模拟用户,批量发送网络请求获取数据。主要作用是代替人工对互联网中的数据进行自动采集和整理,以快速地、批量地获取目标数据
网络爬虫可以做的:
- 批量采集某个领域的招聘数据,对某个行业的招聘情况进行分析
- 批量采集某个行业的电商数据,以分析出具体热销商品,进行商业决策
- 采集目标客户数据,以进行后续营销
- 批量爬取腾讯动漫的漫画,以实现脱网本地集中浏览
- 开发一款火车票抢票程序,以实现自动抢票
网络爬虫程序在将网页爬下类之后,其中一个关键的步骤就是需要对我们关注的目标信息进行提取,而表达式一般就是用于信息筛选提取的工具
爬虫工作原理:
1.确认抓取目标url是哪个
2.使用python代码发送请求获取数据
3.解析获取的数据
4.数据持久化
HTTP协议
HTTP协议:全称是Hyper Text Transfer Protocol,中文意思是超文本传输协议,是一种发布和接收HTML页面的方法。服务器端口号是80端口
HTTPS协议:是HTTP协议是加密版本,在HTTP下加入了SSL层。服务器端口号是443端口
在浏览器中发送一个http请求的过程:
1. 当用户浏览器的地址栏中输入一个URL并按回车键后,浏览器会向HTTP服务器发送HTTP请求。HTTP请求主要分为‘Get’和‘Post’方法
2.当我们在浏览器输入URLhttp://www.baidu.com的时候,浏览器发送一个Request请求去获取http://www.baidu.com的html文件,服务器把Response文件对象发送回给浏览器。
3.浏览器分析Responese中的HTML,发现其中引用了很多其他文件,比如images,CSS,JS文件。浏览器会自动,再次发送Requests去获取图片,CSS文件,或者JS文件
4.当所有的文件都下载成功后,网页根据 HTML语法结构,完整的显示出来了
F12调试页面简介
http的请求方式:
get:1.便捷
缺点:不安全,明文。参数长度受限
post:安全,长度不受限制,上传文件
发送网络请求(需要带一定的数据给服务器,不带也可以)
返回数据
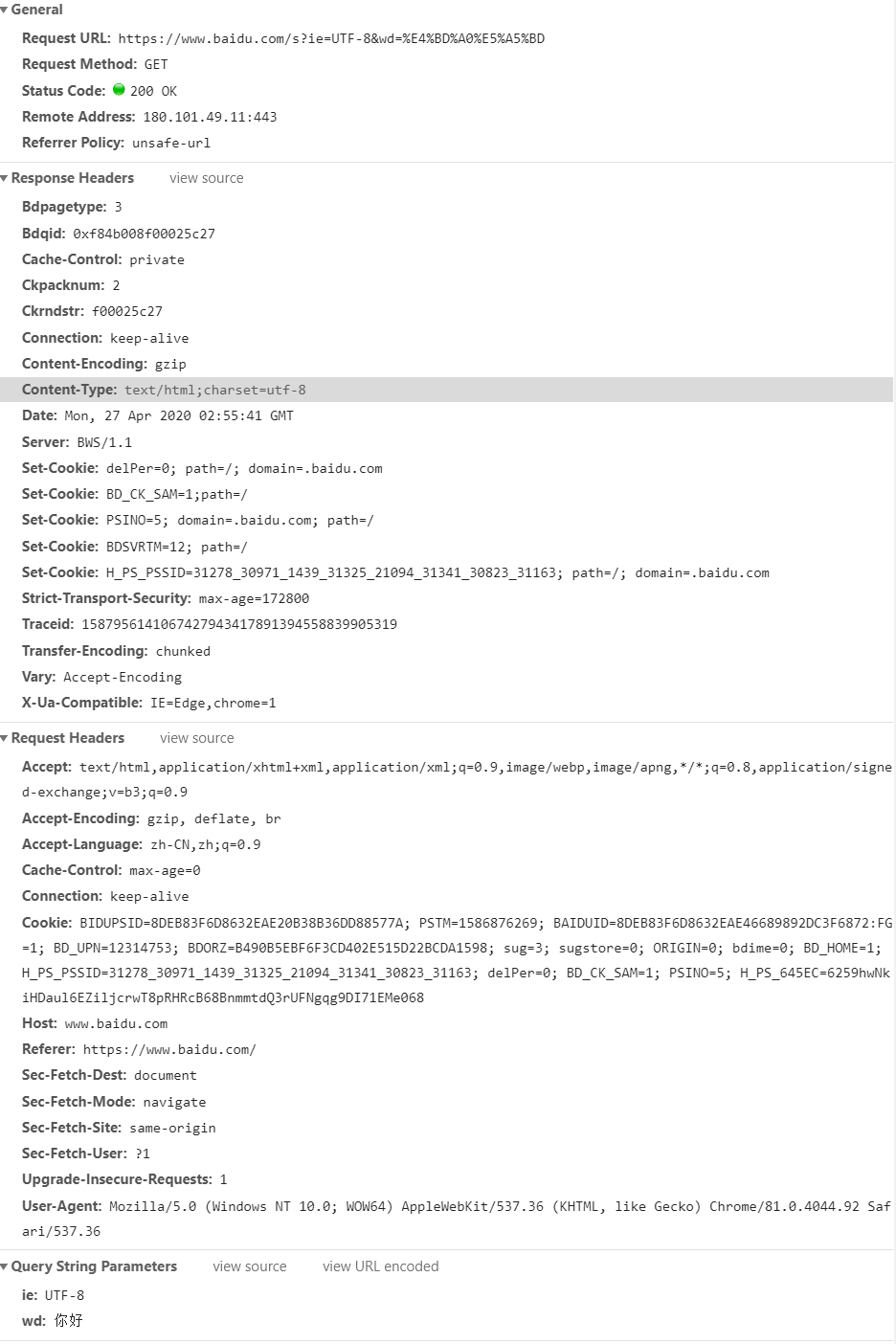
- Request URL代表我们请求网址
- Request Method 请求方式
- Status Code 状态码
- Remote Address远程地址 一般可以通过此转到当前页面
- Referrer Policy referer参数是http请求头header里的一个关键参数,表示的意思是链接的来源地址,比如在页面引入图片、JS 等资源,或者跳转链接,一般不修改策略,都会带上Referer。Referrer Policy是W3C官方提出的一个候选策略,主要用来规范Referrer
官网:https://www.w3.org/TR/referrer-policy/
状态:
“no-referrer”,
“no-referrer-when-downgrade”,
“same-origin”,
“origin”,
“strict-origin”,
“origin-when-cross-origin”,
“strict-origin-when-cross-origin”,
“unsafe-url
URL构成
就以下面这个URL为例,介绍下普通URL的各部分组成
http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name
从上面的URL可以看出,一个完整的URL包括以下几部分:
URL:协议://域名:端口/路径/文件名?查询参数(a=1&b=2)#哈希值(c=3&d=4)
1.协议部分:该URL的协议部分为“http:”,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等本例中使用的是HTTP协议。在”HTTP”后面的“//”为分隔符
2.域名部分:该URL的域名部分为“www.aspxfans.com”。一个URL中,也可以使用IP地址作为域名使用
3.端口部分:跟在域名后面的是端口,域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口
4.虚拟目录部分:从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。本例中的虚拟目录是“/news/”
5.文件名部分:从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。本例中的文件名是“index.asp”。文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名
6.锚部分:从“#”开始到最后,都是锚部分。本例中的锚部分是“name”。锚部分也不是一个URL必须的部分,定义网页中具体位置
7.参数部分:从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。本例中的参数部分为“boardID=5&ID=24618&page=1”。参数可以允许有多个参数,参数与参数之间用“&”作为分隔符。
在浏览器中请求一个url,浏览器会对这个url进行一个编码,除英文字母和部分符号外,其他的全部使用百分号+十六进制码值进行编码
url中#(hash)的含义
hash 属性是一个可读可写的字符串,该字符串是 URL 的锚部分(从 # 号开始的部分)
1 #的涵义
#代表网页中的一个位置。其右面的字符,就是该位置的标识符。比如,
http://www.example.com/index.html#print
就代表网页index.html的print位置。浏览器读取这个URL后,会自动将print位置滚动至可视区域。(单页应用)
为网页位置指定标识符,有两个方法。一是使用锚点,比如,二是使用id属性,比如
。
2 HTTP请求不包括#
#是用来指导浏览器动作的,对服务器端完全无用。所以,HTTP请求中不包括#。
比如,访问下面的网址,
http://www.example.com/index.html#print浏览器实际发出的请求是这样的:
GET /index.html HTTP/1.1
Host: www.example.com
可以看到,只是请求index.html,根本没有”#print”的部分。
3 #后的字符
在第一个#后面出现的任何字符,都会被浏览器解读为位置标识符。这意味着,这些字符都不会被发送到服务器端。
比如,下面URL的原意是指定一个颜色值:
http://www.example.com/?color=#fff但是,浏览器实际发出的请求是:
GET /?color= HTTP/1.1
Host: www.example.com
可以看到,”#fff”被省略了。只有将#转码为%23,浏览器才会将其作为实义字符处理。也就是说,上面的网址应该被写成:
http://example.com/?color=%23fff4 改变#不触发网页重载
单单改变#后的部分,浏览器只会滚动到相应位置,不会重新加载网页。
比如,从
http://www.example.com/index.html#location1改成
http://www.example.com/index.html#location2浏览器不会重新向服务器请求index.html。
5 改变#会改变浏览器的访问历史
每一次改变#后的部分,都会在浏览器的访问历史中增加一个记录,使用”后退”按钮,就可以回到上一个位置。
这对于ajax应用程序特别有用,可以用不同的#值,表示不同的访问状态,然后向用户给出可以访问某个状态的链接。
值得注意的是,上述规则对IE 6和IE 7不成立,它们不会因为#的改变而增加历史记录。
6 window.location.hash读取#值
window.location.hash这个属性可读可写。读取时,可以用来判断网页状态是否改变;写入时,则会在不重载网页的前提下,创造一条访问历史记录。
7 onhashchange事件
这是一个HTML 5新增的事件,当#值发生变化时,就会触发这个事件。IE8+、Firefox 3.6+、Chrome 5+、Safari 4.0+支持该事件。
它的使用方法有三种:
window.onhashchange = func;
window.addEventListener(“hashchange”, func, false);
对于不支持onhashchange的浏览器,可以用setInterval监控location.hash的变化。
8 Google抓取#的机制
默认情况下,Google的网络蜘蛛忽视URL的#部分。
但是,Google还规定,如果你希望Ajax生成的内容被浏览引擎读取,那么URL中可以使用”#!”,Google会自动将其后面的内容转成查询字符串
escaped_fragment的值。
比如,Google发现新版twitter的URL如下:
http://twitter.com/#!/username就会自动抓取另一个URL:
http://twitter.com/?escaped_fragment=/username通过这种机制,Google就可以索引动态的Ajax内容
请求头常见参数:
在http协议中,向服务器发送一个请求,数据分为三部分,第一个是把数据放在url中,第二个把数据放在body中(在post请求中),第三个就是把数据放在head中,这里介绍在爬虫中常用的一些请求参数:
1.User-Agent:浏览器名称,用户代理。在请求一个网页时候,服务器通过这个参数就可以知道这个请求是由那种浏览器发送的。如果我们是通过爬虫发送请求,那么我们的User-Agent就是Python,这对于那些反爬虫机制的网站可以轻易判断此请求是爬虫,因此经常设定此值为一些浏览器值来伪装爬虫
2.Refer :表明当前这个请求是从哪个url过来的,这个一般也可以用来做反爬虫技术。如果不是从指定页面过来的,那么就不做相关响应
3.Cookie:http 协议是无状态的。也就是同一个人发送了两此请求,服务器没有能力知道这两个请求是否来自同一个人。因此这时候就用cookie来做标识。一般如果想做登录后才能访问的网站,那么就需要发送cookie信息了
常见的响应状态码:
- 200:请求正常,服务器正常的返回数据。(不一定是真的数据,有可能网站反爬虫传假数据)
- 301:永久重定向,比如在访问www.jingdong.com的时候会重新定向到www.jd.com
- 302:临时重定向,比如在访问一个需要登录的页面时,而此时没有登录,那就会重定向到登录页面
- 400:请求的url在服务器上找不到,换句话说是请求url错误
- 403:服务器拒绝访问,权限不够
- 500:服务器内部错误,可能是服务器出现bug
HTML的基本结构
一、html的基本结构
1、什么是标签:
html标签组成是html文档的最基本元素,一般是成对出现,由开始标签和与其对应的结束标签构成. 如,,,,等,此外,还有一些标签是单独出现的,如![Python网络爬虫 - 图2]() ,等,标签可以相互嵌套使用。
,等,标签可以相互嵌套使用。
由于html语言是一门弱类型语言,对格式的要求不是非常严格,因此所有标签是不区分大小写的,但是,一般在实际开发中,大家都统一使用小写。
2、html文档的基本结构 
如上图,每一个html文档的基本结构为:
第一层:
<!DOCTTYPE>———!文档类型,它的目的是要告诉标准通用标记语言解析器,它应该使用什么样的文档类型定义(DTD)来解析文档,在html5文档中,一般写为<!DOCTTYPE html> ;值得注意的是,<!DOCTTYPE>不属于html标签。
———-html标签,是html文档的根标签,所有的网页标签都放在这对标签中,是所有html标签的祖先容器。
第二层:
———-头部标签,代表着html文档的头信息,是所有头部元素的容器,内部一般包含:
<script><style><meta><link>这些头部元素。<br /><body></body>———-网页主体标签,其内部主要包含着构成网页内容的一些元素,如<p></p>,<span></span>,<div></div>,<table></table>等。这些元素都会在网页的内容部分显示。</p>
<p><strong>3、标签的属性</strong><br />就如人有这身高、体重、年龄等这些属性一样,html标签也有自己的属性,如字体颜色,宽,高,背景等。这些属性一般通过键值对的形式卸载标签中,是标签的一部分,并且每种标签的属性都不完全像同,有的标签有着自己特有的属性。如下图所示:<br /><img src="https://cdn.nlark.com/yuque/0/2020/png/275341/1587093949864-113e72ee-4e43-43a6-bf58-9cd335e80698.png#align=left&display=inline&height=45&margin=%5Bobject%20Object%5D&originHeight=45&originWidth=1080&size=0&status=done&style=none&width=1080" alt=""><br /><img src="https://cdn.nlark.com/yuque/0/2020/png/275341/1587093956419-3a09e21b-fba2-478a-b96c-8a5431912680.png#align=left&display=inline&height=55&margin=%5Bobject%20Object%5D&originHeight=55&originWidth=514&size=0&status=done&style=none&width=514" alt=""></p>
<p><strong>4、html注释</strong><br />在实际开发中,我们需要在html文档中做一些标记,方便日后对代码的维护及修改,也方便其他程序员了解我们的代码。而在html文档中,注释的格式为:</p>
<!--这是注释的内容-->
<p>我们可以理解为,html中,标签元素是给计算机读的,为注释是给程序员看的。<br />————————————————<br />版权声明:本文为CSDN博主「weixin_38166633」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。<br />原文链接:<a rel="nofollow" href="https://blog.csdn.net/weixin_38166633/java/article/details/73692476">https://blog.csdn.net/weixin_38166633/java/article/details/73692476</a></p>
<p>常用的请求方法:<br />在Http协议中,定义了八种请求方法,这里介绍两种常用的请求方法:<br />1.get请求:一般情况下,只从服务器获取数据下来,并不会对服务器资源产生任何影响的时候用get请求<br />2.post请求:向服务器发送数据(登录)、上传文件等,会对服务器资源产生任何影响的时候会使用post请求。<br />按常理出牌,有可能一个应该使用get方法的请求就一定要改成post请求,这个要视情况而定。</p>
<p><a name="kOtcY"></a></p>
<h1 id="7200tj"><a name="7200tj" class="reference-link"></a><span class="header-link octicon octicon-link"></span>正则表达式</h1><p>正则表达式是一种功能强大的表达式,并且非常好用.<br />全局匹配函数使用格式: <strong> re.compile(正则表达式).findall(源字符串)</strong></p>
<table>
<thead>
<tr>
<th><strong>普通字符</strong></th>
<th><strong>正常匹配</strong></th>
</tr>
</thead>
<tbody>
<tr>
<td><strong>\n</strong></td>
<td><strong>匹配换行符</strong></td>
</tr>
<tr>
<td><strong>\t</strong></td>
<td><strong>匹配制表符</strong></td>
</tr>
<tr>
<td><strong>\w</strong></td>
<td><strong>匹配字母、数字、下划线</strong></td>
</tr>
<tr>
<td><strong>\W</strong></td>
<td><strong>匹配除字母、数字、下划线</strong></td>
</tr>
<tr>
<td><strong>\d</strong></td>
<td><strong>匹配十进制数字</strong></td>
</tr>
<tr>
<td><strong>\D</strong></td>
<td><strong>匹配除十进制数字</strong></td>
</tr>
<tr>
<td><strong>\s</strong></td>
<td><strong>匹配空白字符</strong></td>
</tr>
<tr>
<td><strong>\S</strong></td>
<td><strong>匹配除空白字符</strong></td>
</tr>
<tr>
<td><strong>[ab89x]</strong></td>
<td><strong>匹配‘ab89x’中的任意一个</strong></td>
</tr>
<tr>
<td><strong>[^ab89x]</strong></td>
<td><strong>匹配除‘ab89x’以外的任意一个字符</strong></td>
</tr>
<tr>
<td><strong>.</strong></td>
<td><strong>匹配除换行符外任意一个字符</strong></td>
</tr>
<tr>
<td><strong>^</strong></td>
<td><strong>匹配开始位置</strong></td>
</tr>
<tr>
<td><strong>$</strong></td>
<td><strong>匹配结束位置</strong></td>
</tr>
<tr>
<td><strong>*</strong></td>
<td><strong>前一个字符出现0\1\多次</strong></td>
</tr>
<tr>
<td><strong>?</strong></td>
<td><strong>前一个字符出现0\1次</strong></td>
</tr>
<tr>
<td><strong>+</strong></td>
<td><strong>前一个字符出现1\多次</strong></td>
</tr>
<tr>
<td><strong>{n}</strong></td>
<td><strong>前一个字符恰好出现n次</strong></td>
</tr>
<tr>
<td><strong>{n,}</strong></td>
<td><strong>前一个字符至少n次</strong></td>
</tr>
<tr>
<td><strong>{n,m}</strong></td>
<td><strong>前一个字符至少n,至多m次</strong></td>
</tr>
<tr>
<td><strong>| (竖线)</strong></td>
<td><strong>模式选择符或</strong></td>
</tr>
<tr>
<td><strong>()</strong></td>
<td><strong>模式单元,想提取什么就用小括号括起来</strong></td>
</tr>
<tr>
<td></td>
</tr>
</tbody>
</table>
<p>实例1:<br />源字符串:’aliyunedu’<br />正则表达式:’yu’<br />匹配结果:[‘yu’]</p>
<hr>
<p>源字符串:’’’aliyun<br /> edu’’’<br />正则表达式:’yun\n’ #\n换行符<br />匹配结果:[‘yun\n’]</p>
<hr>
<p>源字符串:’aliyu89787nedu’<br />正则表达式:’\w\d\w\d\d\w’<br />匹配结果:[‘u89787’]</p>
<hr>
<p>源字符串:’aliyu89787nedu’<br />正则表达式:’\w\d\w\d\d\w’<br />匹配结果:[‘u89787’]</p>
<p>实例2<br />源字符串:’aliyu89787nedu’<br />正则表达式:’ali…’ #…按顺序取除换行符外任意三个字符<br />匹配结果:[‘aliyu8’]</p>
<hr>
<p>源字符串:’aliyu89787nedu’<br />正则表达式:’^li…’ #l要是开始位置才能匹配,显然不是所有返回空值<br />匹配结果:[]</p>
<hr>
<p>源字符串:’aliyu89787nedu’<br />正则表达式:’7ne…$’ #最后一位如果取的不是源字符串最后位置则返回空值<br />匹配结果:[‘7nedu’]</p>
<hr>
<p>源字符串:’aliyu89787nedu’<br />正则表达式:’li.*’<br />匹配结果:[‘liyu89787nedu’] #默认贪婪,尽可能多的进行匹配</p>
<hr>
<p>源字符串:’aliiiiyu89787nedu’<br />正则表达式:’li?’ <br />匹配结果:[‘li’]</p>
<hr>
<p>源字符串:’aliiiiyu897li87nliielidu’<br />正则表达式:’li{1,2}’ #{1,2}只修饰前面一个字符i,搜索li或lii<br />匹配结果:[‘[‘lii’, ‘li’, ‘li’, ‘lii’]’]</p>
<hr>
<p>源字符串:’aliiiiyu89787nedu’<br />正则表达式:’^al(i…)’ <br />匹配结果:[‘iiii’]</p>
<hr>
<p>贪婪模式:尽可能多地匹配<br />懒惰模式:尽可能少匹配,精确模式<br />懒惰模式:<br /><em>?<br />+?<br />实例3<br />源字符串:’poytphonyhjskjsa’<br />正则表达式:’p.</em>y’ <br />匹配结果:[‘poytphony’]</p>
<hr>
<p>源字符串:’poytphonyhjskjsa’<br />正则表达式:’p.<em>?y’ <br />匹配结果:[‘poy’,’phony’]<br /><strong><br />模式修正符:在不改变正则表达式的情况下通过模式修正符使匹配结果发生更改<br /></strong>re.S <strong> 让.也可以匹配多行<br /></strong>re.I *</em> (#ignore的首字母) 让匹配忽略大小写</p>
<p>实例4<br />源字符串:’Python’<br />正则表达式;’pyt’<br />匹配方式:re.compile(‘pyt’).findall(‘Python’)<br />匹配结果:[]</p>
<hr>
<p>源字符串:’Python’<br />正则表达式;’pyt’<br />匹配方式:re.compile(‘pyt’).findall(‘Python’)<br />匹配结果:[‘Pyt’]</p>
<hr>
<p>源字符串:’Python’<br />正则表达式;’pyt’<br />匹配方式:re.compile(‘pyt’).findall(‘Python’)<br />匹配结果:[]</p>
<hr>
<p>源字符串:string=’’’我是阿里云大学<br />欢迎来学习<br />Python网络爬虫课程<br />‘’’<br />正则表达式:pat=’阿里.*?Python’<br />匹配方式:re.compile(pat,re.S).findall(string)<br />匹配结果:[‘阿里云大学\n欢迎来学习\nPython’]</p>
<p>除了正则表达式,还有一些非常好用的信息筛选工具,比如XPath表达式,Beautiful Soup等
<a name="Pugo0"></a></p>
<h1 id="9l5ghz"><a name="9l5ghz" class="reference-link"></a><span class="header-link octicon octicon-link"></span>XPath表达式<a rel="nofollow" href="https://www.runoob.com/xpath/xpath-intro.html">链接</a></h1><ul>
<li><strong>/ </strong>逐层提取</li><li><strong>text() </strong>提取标签下面</li><li><strong>//标签名</strong> <strong>提取所有名为</strong>的标签</li><li>//标签名[@属性=’属性值’] 提取属性为XX的标签</li><li><a href="#">@属性名</a> 代表取某个属性值
<a name="ja4M5"></a><h2 id="95ngxn"><a name="95ngxn" class="reference-link"></a><span class="header-link octicon octicon-link"></span> </h2><a name="BBLyf"></a><h1 id="d9bjpk"><a name="d9bjpk" class="reference-link"></a><span class="header-link octicon octicon-link"></span>Urllib</h1>1.get传参<br />(1)汉字报错,解释器ascii没有汉字 url汉字转码<br />(2)字典传参</li></ul>
<pre><code>import urllib.parse
import string
import urllib.request
def get_params()#创建参数字典形式
url='http://www.baidu.com/s?wd='
params={
'wd'='中午'
'key'='li'
'value'='li'
}
str_params=urllib.parse.urlencode(params)#字典传参
print(str_params)
final_url=url+str_params
</code></pre><p>(2)将有中文的url转译成计算机可以识别的url<br />网址包含汉字,ascii是没有汉字的;url转译,将包含汉字的网址进行转译。<br /><strong>import urllib.parse</strong><br /><strong>import string </strong><br /><strong>new_url=urllib.parse.quote(url,safe=string.printable)</strong><br />**<br />def money_proxy_use():<br />#第一种嵌入付费代理ip方式比免费ip多一个用户名和密码和@ <br />money_proxy={‘http’:’username:pwd@192.168.12.11:8080’}<br />proxy_handler=urllib.request.ProxyHandler(money_proxy)<br />opener=urllib.request.build_opener(proxy_handler)<br />opener.open(‘<a rel="nofollow" href="http://www.baidu.com">http://www.baidu.com</a>‘)<br />money_proxy_use()</p>
<h1 id="4yyv3x"><a name="4yyv3x" class="reference-link"></a><span class="header-link octicon octicon-link"></span>第二种方式发送付费ip<br />def money_proxy_use():<br />use_name=’abcname’<br />pwd=’123456’<br />proxy_money=’123.158.63.135:8800’<br />password_manager=urllib.request.HTTPPasswordMgrWithDefaultRealm()<br />password_manager.add_password(None,proxy_money,user_name,pwd)</h1><p><a name="Ks8hR"></a></p>
<h2 id="ak3m1s"><a name="ak3m1s" class="reference-link"></a><span class="header-link octicon octicon-link"></span>Urllib项目实战</h2><p><strong>urllib.requeset.urlopen(‘<a rel="nofollow" href="http://www.jd.com').read().decode('utf-8','ignore">http://www.jd.com').read().decode('utf-8','ignore</a>‘)</strong><br />调用requeset模块的方法urlopen将网页对象下载到内存中,然后读取数据,解码(以utf-8解码,忽略细节问题<strong>)</strong></p>
<pre><code class="lang-python">import urllib
import urllib.request
data=urllib.request.urlopen('http://www.jd.com').read().decode('utf-8','ignore')
len(data)
print(len(data))
import re
pat='<title>(.*?)</title>' #正则表达式
result=re.compile(pat,re.S).findall(data)
print(result)
get=urllib.request.urlretrieve('http://www.jd.com',filename=r'E:\Python Crawler for study\jd.html')
print(get)
</code></pre>
<p><strong>urllib.requeset.urlretrive(‘网站名’,filename=r’文件夹路径\自定义.html’) #\会有转义作用,因此路径前加r阻止转义</strong><br />将网页下载到本地文件夹内</p>
<p><strong>post</strong><br />urllib.request.openurl(url,data=’服务器接收的数据’)<br /><strong>爬虫伪装浏览器</strong><br />F12 >network >选中网址域名>Headers(消息头)>Request Headers(请求头)>找到User Agent(用户代理)</p>
<pre><code class="lang-python">import urllib #导入自带包
import urllib.request #导入自带模块
opener=urllib.request.build_opener() #实例化opener
UA=('User-Agent',' Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0')
#网页中User Agent数据赋值给自定义变量UA
opener.addheaders=[UA] #将UA变量赋值给请求头,即伪装成浏览器
urllib.request.install_opener(opener) #安装为全局
data=urllib.request.urlopen('http://www.qiushibaike.com').read().decode('utf-8','ignore')
print(len(data))
</code></pre>
<p><a rel="nofollow" href="https://baike.baidu.com/item/%E6%B5%8F%E8%A7%88%E5%99%A8">浏览器</a>的 UA 字串<br />标准格式为: <a rel="nofollow" href="https://baike.baidu.com/item/%E6%B5%8F%E8%A7%88%E5%99%A8">浏览器</a>标识 (<a rel="nofollow" href="https://baike.baidu.com/item/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F">操作系统</a>标识; 加密等级标识; <a rel="nofollow" href="https://baike.baidu.com/item/%E6%B5%8F%E8%A7%88%E5%99%A8">浏览器</a>语言) 渲染引擎标识 版本信息<br /><strong>创建用户代理池</strong></p>
<pre><code class="lang-python">import random
import urllib.request
uapools=['Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 Edge/16.16299']
#uapools变量赋值不同浏览器的用户代理,作为列表保存
def UA(): #定义用户代理生成函数
opener=urllib.request.build_opener()
thisua=random.choice(uapools)
ua=('User-Agent',thisua)
opener.addheaders=[ua] #伪装成不同浏览器用户代理更利于反爬虫
urllib.request.install_opener(opener)
print('当前使用UA为:\n',str(thisua),'\n',(100*'-'))
for x in range(0,10): #爬取十次数据
UA()
data=urllib.request.urlopen('http://www.qiushibaike.com').read().decode('utf-8','ignore')
#获取网页对象存于内存
print(len(data))
</code></pre>
<p>下例爬取糗事百科一到十页段子</p>
<pre><code class="lang-python">import random #导入三个模块
import urllib.request
import re
uapools=['Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 Edge/16.16299'] #创建用户代理池
def UA(): #这是代理用户函数,目的创建爬虫伪装成不同浏览器用户代理
opener=urllib.request.build_opener()
thisua=random.choice(uapools)
ua=('User-Agent',thisua)
opener.addheaders=[ua]
urllib.request.install_opener(opener)
print('当前使用UA为:\n',str(thisua),'\n',(100*'-'))
for i in range(0,10): #爬取十次
UA()
thisurl='https://www.qiushibaike.com/text/page'+str(i+1)+'/'
data=urllib.request.urlopen(thisurl).read().decode('utf-8','ignore')
#pat='<div class="content">.*?<span>(.*?)</span>.*?</div>'错误的正则表达式
pat='<div class="content">\n<span>(.*?)</span>'
result=re.compile(pat,re.S).findall(data) #返回结果为列表
for y in range(0,len(result)): #将列表中字符遍历输出
print(result[y])
print(50*'-')
</code></pre>
<p><a name="eSNbh"></a></p>
<h1 id="9el45h"><a name="9el45h" class="reference-link"></a><span class="header-link octicon octicon-link"></span>Fiddler软件抓包使用</h1><p>FireFox浏览器网络配置,Fiddler相当于代理服务器,其默认<strong>ip是127.0.0.1,端口8888,</strong><br />在浏览器中设置后,所有网页会经过Fiddler访问<br /><img src="https://cdn.nlark.com/yuque/0/2020/png/275341/1586684277715-75001121-bdc1-4622-88b2-ab80aeb9f313.png#align=left&display=inline&height=571&margin=%5Bobject%20Object%5D&name=%E5%9B%BE%E7%89%87.png&originHeight=884&originWidth=976&size=40139&status=done&style=none&width=630" alt="图片.png"><br /><img src="https://cdn.nlark.com/yuque/0/2020/png/275341/1586684764760-f03d82f0-4417-4909-9317-be58ef63f02f.png#align=left&display=inline&height=384&margin=%5Bobject%20Object%5D&name=%E5%9B%BE%E7%89%87.png&originHeight=460&originWidth=678&size=80143&status=done&style=none&width=566" alt="图片.png"><br /> <br />例:分析腾讯视频热带_荒野间谍 第二季第一集评论<br /><img src="https://cdn.nlark.com/yuque/0/2020/png/275341/1586747495540-4f3ee472-b0b4-4178-ae58-da07e1f80d1b.png#align=left&display=inline&height=230&margin=%5Bobject%20Object%5D&name=%E5%9B%BE%E7%89%87.png&originHeight=461&originWidth=1255&size=38498&status=done&style=none&width=627.5" alt="图片.png"><br />在Fiddler输入框内clear抓取的内容,然后点击查看更多评论,软件左边的js脚本,TextView里有评论,<br />可知我们需要的正则表达式为’”content”:”(.*?)”‘,复制多个video.coral.qq.com的网址(多点几次查看更多评论,复制网址观察变化规律,以实现爬虫自动翻页获取评论)进行分析<br /><img src="https://cdn.nlark.com/yuque/0/2020/png/275341/1586748693828-8df76c81-952d-42ec-ad78-081776f2f403.png#align=left&display=inline&height=439&margin=%5Bobject%20Object%5D&name=%E5%9B%BE%E7%89%87.png&originHeight=877&originWidth=1232&size=366702&status=done&style=none&width=616" alt="图片.png"></p>
<blockquote>
<p><a rel="nofollow" href="https://video.coral.qq.com/varticle/5002764604/comment/v2?callback=_varticle5002764604commentv2&orinum=10&oriorder=o&pageflag=1&cursor=0&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1586698721384">https://video.coral.qq.com/varticle/5002764604/comment/v2?callback=_varticle5002764604commentv2&orinum=10&oriorder=o&pageflag=1&cursor=0&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1586698721384</a>
<a rel="nofollow" href="https://video.coral.qq.com/varticle/5002764604/comment/v2?callback=_varticle5002764604commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6650761174562882528&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1586695136083">https://video.coral.qq.com/varticle/5002764604/comment/v2?callback=_varticle5002764604commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6650761174562882528&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1586695136083</a>
<a rel="nofollow" href="https://video.coral.qq.com/varticle/5002764604/comment/v2?callback=_varticle5002764604commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6651119720169856276&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1586695136084">https://video.coral.qq.com/varticle/5002764604/comment/v2?callback=_varticle5002764604commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6651119720169856276&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1586695136084</a></p>
</blockquote>
<p>上面为初始评论页和第二三页网址,可知变化为cursor=后数值变化,将cursor后数值复制在Fiddler内搜索<br /><img src="https://cdn.nlark.com/yuque/0/2020/png/275341/1586749589495-4bb16153-2bd7-4886-9435-5459848e084c.png#align=left&display=inline&height=439&margin=%5Bobject%20Object%5D&name=%E5%9B%BE%E7%89%87.png&originHeight=877&originWidth=1232&size=502688&status=done&style=none&width=616" alt="图片.png"><br />可以发现last<br />后数值即为cursor=后数值,不过当前评论源码内last后是下一条评论cursor=后数值,可以通过此规律实现爬虫迭代加载评论<br />如下代码实现加载百页评论</p>
<pre><code class="lang-python">#import urllib.request
#import re
#cid='0'
#for i in range(0,100):
# url='https://video.coral.qq.com/varticle/5002764604/comment/v2?callback=_varticle5002764604commentv2&orinum=10&oriorder=o&pageflag=1&cursor='+str(cid)+'&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1586698721384'
# print('第'+str(i+1)+'页的评论数据')
# data=urllib.request.urlopen(url).read().decode('utf-8','ignore')#网页对象在内存中储存
# pat1='"content":"(.*?)"'
# comment=re.compile(pat1,re.S).findall(data)
# for item in comment:
# print(str(item))
# print(80*'=')
# pat2='"last":"(.*?)"'
# cid=re.compile(pat2,re.S).findall(data)[0] #全局匹配函数获取last后字符值以列表返回
</code></pre>
<p><a name="CPfo0"></a></p>
<h1 id="9j02aw"><a name="9j02aw" class="reference-link"></a><span class="header-link octicon octicon-link"></span>requests模块爬虫编写<a rel="nofollow" href="http://2.python-requests.org/zh_CN/latest/user/quickstart.html">链接</a></h1><p>requests请求方式:get、post、put······<br />参数:params get请求的参数,以<strong>字典方式</strong>存储<br /> headers 伪装浏览器,添加头信息,以<strong>字典方式</strong>存储<br /> proxies 添加代理。以<strong>字典方式</strong>存储<br /> cookies 如果要添加Cookie(Cookie,当用户通过浏览器首次访问一个域名时,访问的web服务器会给客户端发送数据,以保持web服务器与客户端之间的状态保持,这些数据就是cookie,它是Internet站点创建的,为了辨别用户身份而储存在用户本地终端上的数据,cookie大部分都是加密的,cookie存在与缓存中或者硬盘中,在硬盘中的是一些文本文件,当你访问该网站时,就会读取对应的网站的cookie信息,cookie有效地提升了用户体验,一般来说,一旦将cookie保存在计算机上,则只有创建该cookie的网站才能读取它<br />————————————————</p>
<blockquote>
<p>版权声明:本文为CSDN博主「williamgavin」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:<a rel="nofollow" href="https://blog.csdn.net/williamgavin/java/article/details/81390014">https://blog.csdn.net/williamgavin/java/article/details/81390014</a></p>
</blockquote>
<p> data 用于post请求数据存放</p>
<p>text 响应的数据,一般是经过decode后的数据<br />content 响应的数据,二进制类型<br />encoding 当前网页的编码<br />cookies 响应cookie<br />url 当前请求的url<br />status_code 状态码</p>
<p><strong>requests</strong>:返回一个包含服务器资源的Response对象(Response对象:包含返回的所有资源)<br /><strong>get()</strong>:构造一个向服务器请求资源的Requests对象<br /><em>完整使用方法包含3个参数:** Requests.get(url,params=None,</em><em>kwarge)</em>**</p>
<ul>
<li>url::获取页面的url链接</li><li>params:url中的额外参数,字典或字节流格式,可选</li><li>**kwargs:12个控制访问的参数<pre><code class="lang-python">import requests#导入requests
import re #导入正则
hd={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36'}
px={"http":"http://127.0.0.1:8888"}
rst=requests.get('https://www.aliwx.com.cn/',headers=hd,proxies=px) #获取响应,设置消息头,代理网址
title=re.compile('<title>(.*?)</title>',re.S).findall(rst.text) #获取正则过滤后信息,返回列表结果
#print(rst) #打印出<Response [200]>
print(title)
</code></pre>
<a name="frhDd"></a><h3 id="2sv5x8"><a name="2sv5x8" class="reference-link"></a><span class="header-link octicon octicon-link"></span>例requests爬取51job并保存到txt文本</h3>```python<h1 id="6t80d0"><a name="6t80d0" class="reference-link"></a><span class="header-link octicon octicon-link"></span><a rel="nofollow" href="https://search.51job.com/list/020000,000000,0000,00,9,99,java,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=">https://search.51job.com/list/020000,000000,0000,00,9,99,java,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=</a></h1><h1 id="cadnna"><a name="cadnna" class="reference-link"></a><span class="header-link octicon octicon-link"></span><a rel="nofollow" href="https://search.51job.com/list/020000,000000,0000,00,9,99,java,2,2.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=">https://search.51job.com/list/020000,000000,0000,00,9,99,java,2,2.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=</a></h1><h1 id="9907df"><a name="9907df" class="reference-link"></a><span class="header-link octicon octicon-link"></span><a rel="nofollow" href="https://search.51job.com/list/020000,000000,0000,00,9,99,java,2,3.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=">https://search.51job.com/list/020000,000000,0000,00,9,99,java,2,3.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=</a></h1><h1 id="5nxrek"><a name="5nxrek" class="reference-link"></a><span class="header-link octicon octicon-link"></span><a rel="nofollow" href="https://search.51job.com/list/020000,000000,0000,00,9,99,java,2,3.html">https://search.51job.com/list/020000,000000,0000,00,9,99,java,2,3.html</a> *分析网页</h1><h1 id="5t8o93"><a name="5t8o93" class="reference-link"></a><span class="header-link octicon octicon-link"></span>要求用requests模块</h1>import requests
import re
import os </li></ul>
<p>print(‘请输入搜索职位:’)
key=input()
page=1
hd={‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36’}</p>
<p>rsp=requests.get(‘<a rel="nofollow" href="https://search.51job.com/list/020000,000000,0000,00,9,99,'+key+',2,'+str(page)+'.html',headers=hd">https://search.51job.com/list/020000,000000,0000,00,9,99,'+key+',2,'+str(page)+'.html',headers=hd</a>)</p>
<h1 id="fyxjla"><a name="fyxjla" class="reference-link"></a><span class="header-link octicon octicon-link"></span>正则表达式</h1><p>pat_num=’共(.<em>?)条职位’
pat_name=’ <a target=”_blank” title=”(.</em>?)”‘
pat_area=’<span class="t3">(.<em>?)</span>‘
pat_salary=’<span class="t4">(.</em>?)</span>‘
pat_company=’<span class="t2"><a target="_blank" title="(.*?)"'
pat_date='<span class="t5">(.*?)</span>‘
decode_data=bytes(rsp.text,rsp.encoding).decode(‘gbk’,’ignore’)</p>
<h1 id="blhsy3"><a name="blhsy3" class="reference-link"></a><span class="header-link octicon octicon-link"></span>实现翻页</h1><p>num=re.compile(pat_num,re.S).findall(decode_data)[0]
all_page=int(num)//50+1
print(str(all_page)+’页========================’)
fileOb = open(‘51job.txt’,mode=’w’, encoding=’utf-8’) #打开一个文件,没有就新建一个,名为51job的文本文件,
for page in range(1,all_page+1): #该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除</p>
<pre><code>#匹配结果(列表形式返回)
rsp=requests.get('https://search.51job.com/list/020000,000000,0000,00,9,99,'+key+',2,'+str(page)+'.html',headers=hd)
decode_data=bytes(rsp.text,rsp.encoding).decode('gbk','ignore')#查看网页charset决定decode解码方式
name=re.compile(pat_name,re.S).findall(decode_data)
area=re.compile(pat_area,re.S).findall(decode_data)
salary=re.compile(pat_salary,re.S).findall(decode_data)
company=re.compile(pat_company,re.S).findall(decode_data)
date=re.compile(pat_date,re.S).findall(decode_data)
#保存到文本
fileOb.write('第'+str(page)+'页职位'+str(name)+'\n'+str(area)+'\n'+str(salary)+'\n'+str(company)+'\n')
</code></pre><h1 id="amf0c1"><a name="amf0c1" class="reference-link"></a><span class="header-link octicon octicon-link"></span>输出结果</h1><pre><code>for i in range(0,len(name)):
print(str(page)+'页==='+str(i+1)+'-----------------------------------------\n'+name[i])
print(area[i+1])
if salary[i+1]:
print(salary[i+1])
else:
print('面谈')
print(company[i])
print('日期:'+date[i+1])
</code></pre><p>fileOb.close() #关闭文本</p>
<pre><code>
<a name="k9g0O"></a>
# Scrapy 爬虫[链接](https://docs.scrapy.org/en/latest/)
常用指令:(前面都加scarpy )<br />startproject 创建爬虫项目<br />genspider -l 查看爬虫项目<br />genspider -t 模板 爬虫文件名 域名 创建爬虫<br />crawl 运行爬虫<br />list 查看有哪些爬虫
例在‘E:\Pythoncode\scrapy练习’中创建项目‘aliwx’<br />[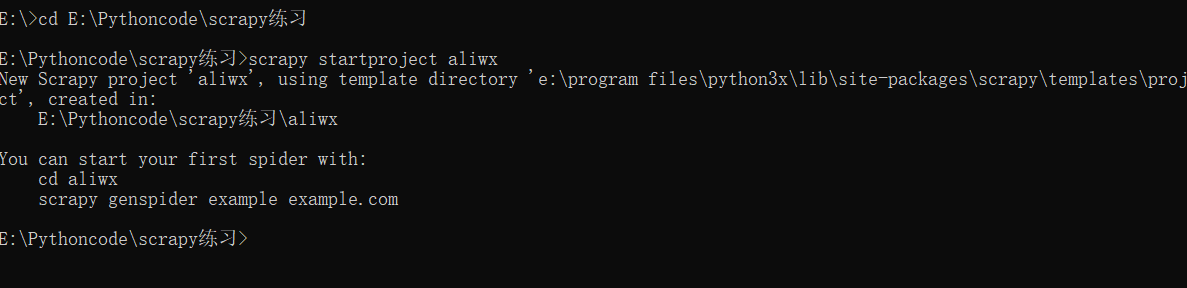](13016611040)
<br />**运行爬虫文件:**<br />**cmd内,进入项目所在位置,输入**<br />**scrapy crawl 爬虫文件名(不带‘’)**
编写一个Scrapy爬虫项目,流程如下:<br />创建爬虫项目<br />编写items<br />创建爬虫文件<br />编写爬虫文件<br />编写pipelines<br />配置settings
创建爬虫文件需先进入项目目录,然后输入指令例如:<br />[](13016611040)<br />然后在items.py文件中设定你需要获取的信息名,如下分别获取name,link,comment
```python
import scrapy
class DangdangSpiderItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
link=scrapy.Field()
comment=scrapy.Field()
pass
</code></pre>
